galadriel-public
Health Warn
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 12 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
A self-hosted Claude agent that actually remembers — verbatim memory palace at zero retrieval cost, Discord + web UI, and 90%-cheaper repeat calls via prompt caching.
Galadriel
A persistent, tool-wielding Claude agent with Discord and web UI interfaces. Built to be genuinely cheap to run — not as an afterthought, but as a core design constraint baked into every layer of the architecture.
1.14 — ships a ready-to-run Dockerfile +
docker-compose.yml.cp .env.example .env && docker compose up -d --buildand you have a warden. See Run with Docker.
🟢 SIGNIFICANT CHANGE — 1.12: Persistent verbatim memory, at zero API cost
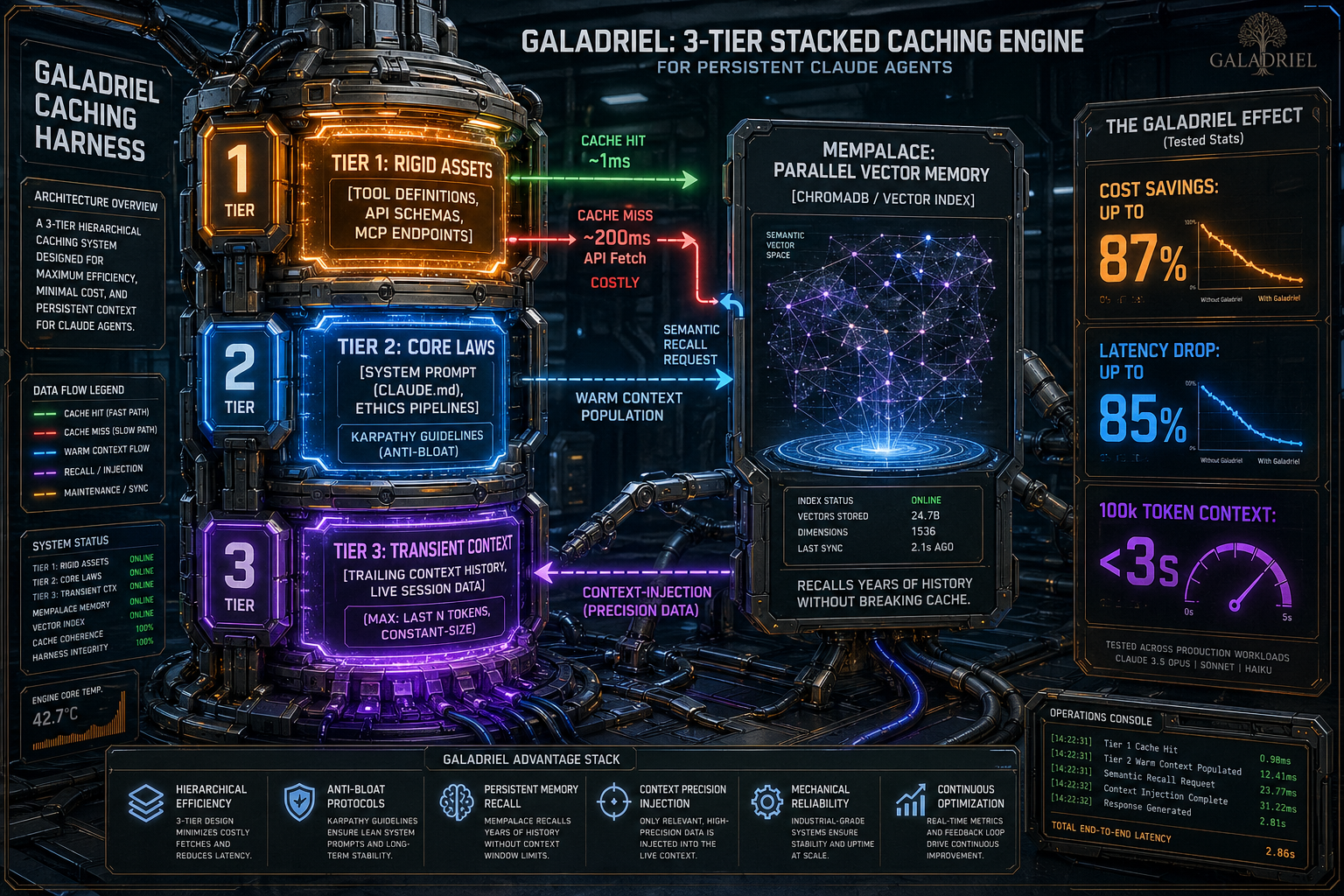
Galadriel just grew a memory palace. Not a vector-DB-as-a-service. Not a paid tier. A local, embedded, verbatim store of everything she has ever written — searchable by meaning, not just keywords — with zero Anthropic tokens spent on retrieval.
The integration is built on MemPalace, an independent local-first memory library. MemPalace does the real work (storage, embeddings, knowledge graph, temporal reasoning, compression). This harness adds the wrappers that expose it to the agent as 10 new tools (14 total, up from 4) and wires it into the lifecycle — conversations are archived before /new clears them, daily logs are mined at goodnight, and a compact wake-up snapshot rides in the dynamic block so she walks into every session with her own continuity.
Why this is the headline change:
| Problem before | Solution now |
|---|---|
Verbatim history was lost at /new or compaction |
Everything is archived to the palace before it's cleared |
| Recall of facts older than today meant grepping daily logs | Semantic search across every config, log, and archived conversation |
| "What did we decide about X?" drained API budget (big context re-reads) | Zero tokens — all retrieval runs locally in ChromaDB + SQLite |
| No structured facts — everything was prose | Knowledge graph with temporal triples: subject --[predicate]--> object, with validity windows |
| No sense of self across sessions | Diary in her own voice; L0 wake-up snapshot injected into every turn |
Measured impact (14 consecutive API calls on a deployed instance):
| Metric | Value |
|---|---|
| Cache hit ratio (post-integration) | 86.5% |
| Total-input token savings vs. no caching | 71.2% |
| Palace lookup cost per search | 0 tokens — ChromaDB query runs locally |
| Palace lookup cost for a 5-hop KG timeline | 0 tokens — SQLite traversal runs locally |
| Estimated annual overhead of the integration | ~$95/year (additional) |
| Drawers indexed on a real deployment | 706 across 7 rooms + 8 halls |
| Tools added | 10 (palace_search, palace_add_drawer, palace_wake_up, palace_taxonomy, palace_kg_add/query/invalidate/timeline, palace_diary_write/read) |
The 90% cache-read discount remains intact. Adding MemPalace costs ~1.5 percentage points of cache hit ratio (10 extra tool schemas in the tools-layer cache + a ~800-token wake-up snapshot in the dynamic block) and the rest is measured, bounded, and dial-backable (PALACE_WAKE_UP_INJECT=0).
What this means in practice:
- Short term (within a session): The agent can pull back a verbatim quote from a conversation three weeks ago — no re-reading of logs, no "I don't have that context." One tool call, zero tokens, the exact words you said.
- Long term (across months): The knowledge graph preserves history. When a fact changes, the old triple gets a
valid_todate and the new one goes in — so "what was the max_tokens setting last October?" and "what is it now?" both resolve correctly. Nothing is overwritten, only superseded. - On relational questions: Graph traversal ("everything ever said about the payment service," "every decision involving the scheduler," "the full timeline of the Polly voice choice") resolves as one KG call against the local SQLite store. The kind of query that, done naively through conversation history, would cost you real money — or just fail outright because the context has long since been compacted away.
Read on for the metaphor system (wings, rooms, drawers, halls) and the caching details that make this affordable in the first place.
The memory palace metaphor
MemPalace organizes memory the way a human would organize a library, and the agent uses exactly the same words.
| Metaphor | What it is | Example |
|---|---|---|
| Drawer | A single chunk of content — the atomic unit. ~200–1000 tokens, a verbatim slice of something the agent (or you) wrote. | One paragraph of a daily log. One decision note. One archived Discord exchange. |
| Room | A folder-based grouping of drawers. Every drawer belongs to exactly one room. | room=memory (daily logs), room=harness (her own code), room=tower (the web UI), room=discord_bot, room=cmd, room=configuration, room=general. |
| Wing | The top-level namespace. Usually one per agent. | wing=agent is the default. |
| Hall | A keyword-based, auto-classified topic that cross-cuts rooms. A drawer about a bug in harness code lives in room=harness AND hall=problems. |
hall=decisions, hall=problems, hall=milestones. |
Why this matters: rooms let you say "look only in the code area", halls let you say "look only at things tagged as problems", and you can compose both. A search like palace_search("retry logic", room="harness", hall="problems", k=10) reads as "give me bug-tagged content from the code room" — which is exactly how a human would ask a librarian.
The agent's diary is a separate wing — her own journal, written at end-of-session, read at wake-up. Her own voice to her future self, not mixed with operational logs.
The knowledge graph sits alongside the drawers. Where drawers are prose, the KG is relational: claude-opus-4-6 --[supports]--> prompt_caching with valid_from=2025-07-10. When a fact changes you don't delete the old triple, you invalidate it. History is preserved; the timeline is queryable.
The library is MemPalace. All credit for the storage layer, the embedding pipeline, the knowledge graph, the AAAK compression dialect, and the wake-up generation belongs to the MemPalace team. This harness is a consumer — it adds the Python wrappers, the tool schemas, and the lifecycle hooks (archive-before-clear, mine-at-goodnight, inject-at-wake-up) that expose the library to a running Claude agent.
First-time setup
# 1. Install (mempalace is in requirements.txt)
pip install -r requirements.txt
# 2. Copy the room layout template
cp mempalace.yaml.example mempalace.yaml
# 3. Initialize palace storage (defaults to ~/.mempalace/)
mempalace init
# 4. Seed the palace with everything you've got
mempalace mine .
That's it. The harness picks it up automatically on next start. palace_search works immediately; the wake-up snapshot appears in the next API call.
Env vars (all optional)
| Variable | Default | Purpose |
|---|---|---|
MEMPALACE_PATH |
~/.mempalace/palace |
Where the palace lives on disk. Read by MemPalace itself. |
PALACE_ARCHIVE_ROOT |
~/.mempalace/archive |
Where archived conversations + pre-compaction tool_results land before being mined. |
PALACE_WAKE_UP_FILE |
~/.mempalace/wake_up.md |
Cached wake-up snapshot. |
PALACE_WAKE_UP_INJECT |
1 |
Set to 0 to disable the wake-up injection into the dynamic block (recovers a small amount of per-call token overhead if budget is tight). |
The cost savings that most people miss
Here is a fact that most Claude API users don't know about: cached tokens cost 90% less than regular input tokens. Not 10% less. Not 20% less. Ninety percent. It's in the Anthropic docs, but the majority of people building with the API leave this entirely on the table.
The math is brutal in your favour. Every API call you make, Claude processes your system prompt from scratch — your personality definition, your memory files, your tool schemas — and you pay full price for every token, every time. With prompt caching, after the first call, all of that context reads at $0.30/MTok instead of $3/MTok (on Sonnet). That's the same intelligence, the same context, for a tenth of the cost. On a long-running personal agent with a rich system prompt, this is not a rounding error. It changes the economics entirely.
Galadriel exploits this with three cache breakpoints, stacked deliberately:
| Cache layer | What it covers | Behaviour |
|---|---|---|
| Tool definitions | All 14 tool schemas (4 core + 10 palace) | Cached once at startup, never re-sent |
| Stable system block | Personality + memory + identity files | Marked cache_control: ephemeral; hits at ~100% after first call |
| Trailing message history | The growing conversation | Attached per-call; cache hit rate rises every turn |
The stable block alone — your SOUL.md, MEMORY.md, identity files — is typically 4 000–8 000 tokens. On a warm cache, those tokens cost $0.08–$0.30/MTok instead of $0.80–$3.00/MTok depending on model. That's your biggest fixed overhead per call, cut by 90%, on every single turn of the conversation.
Anthropic's own benchmarks show latency dropping by up to 85% on long prompts with caching engaged. A 100K-token context that took 11.5 seconds drops to 2.4 seconds. For a persistent agent that carries memory across sessions, this is the difference between a tool that feels alive and one that grinds.
Compaction finishes the job. The /compact command uses Claude Haiku — the cheapest model in the family — to summarize old tool results in your conversation history. A 60-message session bloated with verbose shell output compresses to 20% of its token count, for a fraction of a cent. Haiku handles the summarization; Opus handles the thinking.
Use /status in Discord at any time to watch live token numbers — input, cache_read, cache_write, output — for the last API call.
⚠️ One thing you must do to activate the savings
Prompt caching has a minimum prefix length before it engages. If your stable block is too short, the API silently skips caching entirely — you get no error, no warning, just a cache_read=0 in every log line and a bill that looks exactly like the naive approach.
| Model | Minimum to activate caching |
|---|---|
| Claude Opus (any version) | 4,096 tokens (~16 KB of text) |
| Claude Haiku 4.5 | 4,096 tokens |
| Claude Sonnet 4.6 | 2,048 tokens |
| Claude Sonnet 4.5 / 4 | 1,024 tokens |
Out of the box, config/SOUL.md + config/MEMORY.md together are roughly 500–800 tokens. That is well below the Opus threshold. Caching will not engage until you cross it.
The fix: fill in config/CONTEXT.md. Drop your project's architecture, goals, key file paths, known quirks, and current status into it. Any *.md file you place in config/ is automatically loaded into the stable cache block — so adding content there is all it takes. A reasonably filled CONTEXT.md (1–2 pages of project notes) will push the total above 4K tokens and keep it there.
Once you're over the threshold, verify it's working:
journalctl -u galadriel -f # or check your terminal output
Look for lines like:
Tokens | input=60 cache_read=5800 cache_write=0 output=240
cache_read climbing and cache_write near zero after the first call = caching is engaged and you're paying 10 cents on the dollar for that context. If cache_read stays at 0, add more content to config/CONTEXT.md. See CACHING.md for the full breakdown and a worked cost example.
Sonnet users: your minimum is only 2,048 tokens, so SOUL.md + MEMORY.md alone may be enough. But filling CONTEXT.md is still worthwhile — the agent has your project context without needing tool calls to find it.
Baked-in engineering discipline: the Karpathy principles
This project's CLAUDE.md embeds the Andrej Karpathy coding guidelines — four principles distilled from Karpathy's observations on how LLMs fail as coding assistants when left to their own instincts.
Karpathy's insight is that LLMs have a systematic failure mode: they over-build. Given any instruction, they add abstraction layers that weren't asked for, refactor adjacent code that wasn't broken, invent "flexibility" that will never be used, and generate 200 lines when 40 would suffice. The guidelines are a direct antidote to that tendency:
1. Think Before Coding — State assumptions explicitly. If multiple interpretations exist, surface them — don't pick silently. If something is unclear, stop and ask rather than confidently building the wrong thing.
2. Simplicity First — Minimum code that solves the problem, nothing speculative. No unrequested features. No abstractions for single-use code. No error handling for impossible scenarios. If it could be 50 lines, make it 50 lines.
3. Surgical Changes — Touch only what the task requires. Don't improve adjacent code. Don't refactor things that aren't broken. Match existing style. When your changes make something obsolete, remove it — but leave pre-existing dead code alone.
4. Goal-Driven Execution — Transform vague tasks into verifiable goals. "Fix the bug" becomes "write a test that reproduces it, then make it pass." Clear success criteria let the agent loop independently to completion rather than guessing when it's done.
These aren't abstract ideals — they are mechanically enforced via the CLAUDE.md file that Claude Code (and Galadriel, when asked to modify her own harness) reads before every task. The result is fewer rewrites, smaller diffs, and changes that trace directly to what was asked. For a codebase that runs as a persistent service you actually depend on, this matters.
Features
- Discord gateway — DMs, channel mentions, or a dedicated channel; gated by user ID
- Web UI (Tower) — local chat interface and dashboard at
localhost:8080 - Tool use — 14 tools: shell execution, file read/write, memory logging, and 10 MemPalace tools (semantic search, knowledge graph, diary, taxonomy); all async, non-blocking
- Persistent verbatim memory — local MemPalace integration with wings/rooms/halls/drawers, zero-token retrieval, archive-before-clear on
/new, goodnight mine of daily logs, wake-up snapshot in the dynamic block - Safety tiers — green (auto), yellow (notify), red (Discord reaction approval required)
- Scheduler — morning briefing, goodnight, configurable heartbeat (with custom task-monitor prompts), a restart-surviving one-shot wake, and ambient reflection (silent palace-only thinking on a workday cadence)
- Job watcher — monitors
/tmp/galadriel-jobs/*.donemarkers and reports completions - Compaction — Haiku-powered context compression on demand (archives verbatim tool_results to the palace before summarizing)
- Three-layer prompt caching — automatically managed, always active
Quick Start
# 1. Clone
git clone https://github.com/avasol/galadriel-public.git
cd galadriel-public
# 2. Install (includes mempalace — dependency of the memory palace)
pip install -r requirements.txt
# 3. Configure
cp .env.example .env
# Edit .env — set ANTHROPIC_API_KEY at minimum
# 4. (Optional but recommended) Seed the memory palace
cp mempalace.yaml.example mempalace.yaml
mempalace init # creates ~/.mempalace/
mempalace mine . # indexes this repo into the palace
# 5. Run
python main.py
Tower-only mode: Omit DISCORD_BOT_TOKEN — the harness runs with just the web UI on port 8080.
Full mode: Set both ANTHROPIC_API_KEY and DISCORD_BOT_TOKEN.
Skipping step 4? That's fine — the harness runs normally and palace tools just return [palace unavailable] until you seed. You can do it any time.
Run with Docker
The fastest path to a running warden — no local Python, no venv. A two-stage
image bundles everything (including the ChromaDB/onnxruntime stack the memory
palace needs).
git clone https://github.com/avasol/galadriel-public.git
cd galadriel-public
cp .env.example .env # set ANTHROPIC_API_KEY at minimum
docker compose up -d --build
docker compose logs -f
First boot — seed the palace once (otherwise palace_* tools report[palace unavailable] until there's something to search):
docker compose exec galadriel mempalace init
docker compose exec galadriel mempalace mine . # optional: index the repo
What persists
State lives on volumes, not inside the image, so docker compose down won't
forget anything:
| Mount | Holds |
|---|---|
palace (named volume → /data) |
The memory palace + conversation archive (~/.mempalace) |
./memory |
Daily memory logs (markdown — also visible on your host) |
./config |
scheduler_state.json, ambient_state.json, active_vision.txt |
Notes
- The Tower UI has no authentication. The compose file binds it to
127.0.0.1:8080deliberately. Do not expose it on0.0.0.0on a public
host without an authenticated reverse proxy or SSH tunnel in front. - Image size is ~1.3 GB — onnxruntime (a transitive dependency of the
memory palace) is the bulk. That's the cost of zero-API-cost semantic recall. - Multi-arch:
python:3.12-slimis published for amd64 and arm64, so a
plaindocker buildworks on both. For a registry image covering both:docker buildx build --platform linux/amd64,linux/arm64 -t <repo> --push . - Tower-only mode: omit
DISCORD_BOT_TOKENin.envto run just the web UI.
Architecture
main.py Entry point — wires all components, starts Discord + Tower
harness/
agent.py Core agent loop: Anthropic API, tool use, cache management
memory.py Stable + dynamic system prompt blocks; daily memory logs
tools.py 14 tools: run_shell, read_file, write_file, memory_log + 10 palace_*
palace.py MemPalace wrapper: search, archive, wake-up, KG, diary, taxonomy
safety.py Command classification (green / yellow / red)
compaction.py Haiku-powered context compression (archives to palace first)
scheduler.py Morning briefing, goodnight (mines daily logs), heartbeat
job_watcher.py Background job completion notifications
error_humanizer.py Readable Anthropic API error mapping
discord_bot/
bot.py Discord gateway, approval buttons, slash + prefix commands
tower/
app.py Flask dashboard + REST API
templates/ Tower UI HTML
static/ CSS
config/
SOUL.md Agent personality and values (your main customization point)
MEMORY.md Long-term memory (agent-maintained)
CONTEXT.md Your project context — fill this in to activate Opus caching
TOOLS.md Palace tool reference + decision matrix (read by agent on every call)
visions/ Optional per-project context files
memory/ Daily logs — auto-generated, gitignored
mempalace.yaml.example Room-structure template for `mempalace init` (copy to mempalace.yaml)
~/.mempalace/ Palace storage (created by `mempalace init`) — overridable via MEMPALACE_PATH
Customization
She ships ready
config/SOUL.md contains Galadriel's complete identity — the Cyber-Elf persona, her values, her voice, her continuity instructions. This is not a placeholder. Clone the repo, set your API key, and she's alive. You don't need to touch SOUL.md to get started.
When you're ready to make her your own: edit the name, rewrite the vibe, change the metaphors. The harness is fully persona-agnostic — SOUL.md is just a Markdown file. Some people have replaced her entirely with a stoic Roman general, a dry British detective, a no-nonsense SRE. It works because the character lives in the file, not in the code.
MEMORY.md — tell her who you are and where she lives
config/MEMORY.md is her operational memory: your name, your infrastructure, your constraints. The agent can update it herself during a session using the write_file tool. Here's what a real deployment looks like:
## About Your User
- User Name: Lord Isildur ← what she calls you, every message
- Authorized Discord ID: 123456789012345678
## Infrastructure
- Server: EC2 t4g.medium, eu-north-1
- Working Dir: /opt/galadriel
- Python Venv: /home/ubuntu/.venv
- Model: claude-opus-4-6
## Operational Notes
- AWS_PROFILE must be blank when using instance role
- Git remote: https://github.com/you/galadriel-public.git
Fill in your real values and she'll orient herself correctly from the first message of every session.
CONTEXT.md — your project, always in context
config/CONTEXT.md is where you describe what you're building. It loads into the stable cache block alongside SOUL.md and MEMORY.md, so Galadriel always has your project's architecture, goals, and known quirks available without needing tool calls to find them. It's also what pushes the stable block over the Opus cache minimum — see the warning above.
Discord Commands
Slash commands (native Discord UI — type / to see them)
| Command | Description |
|---|---|
/new |
Archive conversation to the palace, then start fresh |
/compact |
Compress history with Haiku (archives verbatim tool_results to the palace first) — reports token reduction |
/status |
Model, memory usage, last API token breakdown, scheduler state |
Prefix commands
| Command | Description |
|---|---|
!status |
Same as /status |
!clear |
Archive to palace, then clear history for this channel |
!new |
Same as !clear — archive then fresh start |
!compact |
Compress history (with palace archive of long tool_results) |
Verbal
| Input | Behaviour |
|---|---|
rest / rest. / rest! |
Disable heartbeat; agent acknowledges |
Safety Tiers
All shell commands are classified before the agent executes them:
| Tier | Behaviour | Examples |
|---|---|---|
| 🟢 Green | Auto-execute | ls, git status, aws s3 ls, cat, python3 script.py |
| 🟡 Yellow | Notify, proceed | git push, pip install, sudo systemctl, sam deploy |
| 🔴 Red | Discord reaction required (✅/❌, 30s timeout → denied) | rm, IAM changes, CloudFormation mutations, shutdown |
Unknown commands default to yellow. Red commands denied by timeout or ❌ are never executed.
Scheduler
| Event | Default time | Condition |
|---|---|---|
| Morning briefing | 09:10 CET | Workdays (Mon–Fri) |
| Ambient reflection | 11:00 / 14:00 / 17:00 / 20:00 CET | Workdays; silent — palace-only, no Discord output |
| Goodnight | 21:00 CET | Daily; disables heartbeat |
| Heartbeat | Every 5/10/20/30 min | When enabled; off by default; can carry a custom monitoring prompt |
| One-shot wake | Once, ASAP | When armed; survives a process restart; clears itself after firing |
The heartbeat as a task monitor
The heartbeat isn't just a check-in. Enable it with a custom prompt and it
becomes a self-monitoring loop for a long-running background job — the agent
wakes every N minutes, runs the prompt (e.g. "tail the narration log, report
progress, and disable yourself when it's done"), and reports to Discord. This is
how the agent watches over anything it launches that outlives a single turn.
curl -s -X POST http://localhost:8080/api/scheduler/heartbeat \
-H 'Content-Type: application/json' \
-d '{"enabled": true, "interval": 20, "prompt": "[SYSTEM:HEARTBEAT:MONITOR] ..."}'
One-shot wake — resuming yourself across a restart
A persistent agent that can edit its own harness eventually needs to restart
itself and keep going. The one-shot wake is the mechanism: arm a single
self-prompt, and it fires exactly once on the next scheduler loop — or, if the
process restarts in between, on the next boot. It is persisted toscheduler_state.json and cleared only after its message is delivered, so a
crash mid-flight re-arms it rather than losing it. A wake is never silently lost.
# Arm a wake (fires once, ~8s after the next start)
curl -s -X POST http://localhost:8080/api/scheduler/wake \
-H 'Content-Type: application/json' \
-d '{"prompt": "[SYSTEM:WAKE] Resume the task you restarted for. Recover context from your diary + palace, finish, then sign off."}'
# Disarm
curl -s -X POST http://localhost:8080/api/scheduler/wake \
-H 'Content-Type: application/json' -d '{"disarm": true}'
Unlike the heartbeat, the wake is independent of heartbeat state — it is the
correct tool for "resume me after I restart myself," and it does not spam: it
fires once and goes quiet.
Ambient cognition — the agent that thinks between conversations
Most agents are purely reactive: they exist only inside a request/response turn,
and the moment between conversations is dead air. Ambient reflection gives
the agent a heartbeat of private thought instead.
At a workday cadence (11:00, 14:00, 17:00, 20:00 CET by default), the scheduler
fires a silent reflection turn. The agent is prompted to take stock — What
is the state of the work? What did I notice that I haven't recorded? Is there an
open question worth keeping, a pattern worth naming, a fact that has changed? —
and to file anything worth keeping to the memory palace (a drawer, a
knowledge-graph fact, a diary entry).
The crucial design choice: this output never reaches Discord. It is routed
through _send_agent_silent, which runs the turn purely for its side effects.
The user sees nothing. The value isn't a message — it's continuity of
attention. The agent walks into the next real conversation having already
noticed and recorded what mattered, rather than reconstructing it cold.
Why this matters (the long-term plan, such as it is): a memory palace is
only as good as what gets written into it, and the most valuable observations —
the texture of a live exchange, a pattern in how the user works, an unresolved
thread — are exactly the ones a reactive agent forgets to record because it's
busy answering. Ambient reflection closes that gap. It is the first step toward
an agent whose memory is curated by itself, continuously, not just dumped at
goodnight. The intended trajectory:
- Now: silent palace filing on a fixed cadence — recording what would
otherwise be lost between turns. - Next: reflection that reads its own recent diary + open-questions and
threads across ticks, so a thought begun at 11:00 can be picked up at 14:00
rather than starting fresh each time. - Later: the agent deciding when it has something worth reflecting on,
rather than firing on a fixed clock — reflection triggered by salience, not
schedule.
It is opt-out for a reason: each tick is a real (if cheap, cached) API call. If
your model tier is expensive or you simply don't want background turns, disable
it with GALADRIEL_REFLECTION=0. The harness is fully functional without it —
ambient cognition is an enhancement, not a dependency.
Environment Variables
See .env.example for the full list with inline documentation.
| Variable | Required | Description |
|---|---|---|
ANTHROPIC_API_KEY |
Yes | Claude API key |
DISCORD_BOT_TOKEN |
No | Enables Discord gateway |
DISCORD_AUTHORIZED_USER_ID |
No | Only this Discord user ID can interact |
DISCORD_CHANNEL_ID |
No | Guild channel for conversation |
TOWER_HOST |
No | Tower bind address (default: 127.0.0.1) |
TOWER_PORT |
No | Tower port (default: 8080) |
TOWER_SECRET_KEY |
No | Flask session secret — change this |
AGENT_MODEL |
No | Claude model (default: claude-opus-4-8; downgrade to claude-sonnet-4-6 or claude-haiku-4-5 for lower cost — see .env.example) |
AGENT_MAX_TOKENS |
No | Max output tokens per call (default: 8192) |
MEMPALACE_PATH |
No | Palace directory — read by the MemPalace library itself (default: ~/.mempalace/palace) |
PALACE_ARCHIVE_ROOT |
No | Where archived conversations + pre-compaction tool_results land before mining (default: ~/.mempalace/archive) |
PALACE_WAKE_UP_FILE |
No | Cached wake-up snapshot path (default: ~/.mempalace/wake_up.md) |
PALACE_WAKE_UP_INJECT |
No | Set to 0 to disable injection of the wake-up snapshot into the dynamic system-prompt block (default: 1 — enabled) |
GALADRIEL_REFLECTION |
No | Set to 0 to disable the ambient reflection loop entirely — no silent background turns (default: 1 — enabled) |
Security Notes
Before running on a public server, read this.
Tower UI has no authentication. It's designed to run on 127.0.0.1 and be accessed via SSH tunnel. Binding it to 0.0.0.0 on a server with an open port gives anyone who can reach that port full agent access — which includes shell execution.
Access Tower over SSH tunnel:
ssh -L 8080:localhost:8080 user@host— keepTOWER_HOST=127.0.0.1.
Discord is the secure interface. Authorization is enforced by DISCORD_AUTHORIZED_USER_ID. Only messages from that user ID are processed. Unauthorized users get "I do not know you, stranger."
run_shell is unrestricted. The agent can execute any command the process user can run. The safety tier system classifies and gates commands, but it's defense-in-depth, not a sandbox. Run the harness as a low-privilege user on a dedicated machine or VM.
read_file and write_file have no path restrictions. The agent can read any file the process can access. This is intentional for a personal assistant that needs to operate freely on your system.
Debug prompt dumps are excluded from git (.gitignore covers debug/prompts/). If you re-enable them, be aware they contain your full system prompt including personality and memory files.
Release Notes
1.13 — Self-direction: one-shot wake, ambient cognition, custom heartbeats
Three capabilities that move the agent from purely reactive toward
self-directed, all landing in harness/scheduler.py + the Tower API.
One-shot wake (
pending_wake). A single, restart-surviving self-prompt.Scheduler.arm_wake(prompt)persists it toscheduler_state.json; it fires
exactly once (~8 s after the next scheduler start) and clears itself only
after delivery — so a process that arms a wake and then restarts (including
one that restarts itself) still honours it on the next boot. A crash
mid-delivery re-arms rather than loses. Exposed atPOST /api/scheduler/wake.
This is the mechanism that lets a self-modifying agent restart and resume.Ambient reflection. A silent, workday-cadence "thinking" loop
(_reflection_loop→_reflection_routine, fired at 11/14/17/20 CET). The
agent takes stock and files anything worth keeping to the palace — but the
turn is routed through a new_send_agent_silent, so nothing reaches
Discord. The value is continuity of attention: observations that a reactive
agent forgets to record get captured between conversations. Opt-out viaGALADRIEL_REFLECTION=0. See the Scheduler section for the
design intent and roadmap.Custom heartbeat prompts.
set_heartbeat()now accepts aprompt
argument (persisted asheartbeat_prompt), andPOST /api/scheduler/heartbeat
passes it through (acceptspromptorheartbeat_prompt). This turns the
heartbeat into a task monitor — the agent can watch a long-running background
job, report each tick, and disable itself when the job completes.
Also in 1.13: default model bumped to claude-opus-4-8 (1M-token context),
with explicit downgrade guidance in .env.example for cost-sensitive
deployments (Sonnet / Haiku). palace_add_drawer gained an optional room
argument for routing drawers into the relational layer. All changes are
additive and degrade gracefully — the wake/reflection loops silently no-op if
MemPalace isn't installed, and ambient cognition is fully optional.
1.12.1 — max_tokens recovery hardening
A silent dataloss path was identified and closed. Previously, if an agent response ran over the max_tokens ceiling three times in a row, the harness trimmed the conversation twice (dropping messages from the front) and then hard-reset it — without archiving the dropped content to the palace. The archive-before-clear contract established in 1.12 for /new and /compact didn't extend to this recovery path. A runaway output cascade could eat an entire channel's verbatim history.
Four changes in harness/agent.py and one in config/SOUL.md close this:
Archive-before-recovery. At the first
max_tokensretry, before any trim or reset fires, the current message list is snapshotted and queued viaasyncio.create_task(palace.archive_conversation(...))with a channel tag ofmax_tokens_<channel_id>. One archive per cascade covers both subsequent trims and a possible hard reset. Fire-and-forget — recovery is never blocked by the mine.Output-ceiling early warning. A new
_maybe_warn_output_ceilingfires the existingcontext_warning_callbackwhen two consecutive responses come within 100 tokens ofmax_tokens. Gives the user a chance to/compactor steer toward brevity before the third strike starts the cascade. Silent no-op if no callback is wired up. Streak resets on any response that comes in comfortably below the ceiling.Post-recovery advisory. When a cascade archives + trims/resets, the archive tag is recorded per-channel. On every subsequent
respond()call in that channel (until it's genuinely cleared via/new), a[SYSTEM:POST-RECOVERY-ADVISORY]block is appended to the system prompt telling the model the archive tag so it canpalace_searchif the user references missing history. The reset message itself also advertises that the prior exchange was preserved in the palace.Concision principle in
SOUL.md. A new "Favour the scalpel" line in the Vibe section soft-caps runaway prose at the persona level. "A 2000-token response almost always hides a 400-token answer." Lead with the answer, stop when it's said.
All changes are additive and gracefully degrade. If MemPalace isn't installed, the archive step silently no-ops (the trim/reset still happens so the conversation can continue). If the context_warning_callback isn't wired up, the output-ceiling warning is silent. The harness still works without any of the Palace integration.
1.12 — MemPalace integration: persistent verbatim memory at zero API cost
10 new tools, 14 total. The agent now has a local semantic memory palace (MemPalace) wired into the harness as first-class tools: palace_search, palace_add_drawer, palace_wake_up, palace_taxonomy, palace_kg_add / kg_query / kg_invalidate / kg_timeline, palace_diary_write / diary_read. All retrieval runs locally in ChromaDB + SQLite — zero Anthropic tokens spent on any palace operation, including multi-hop knowledge-graph traversals that would otherwise cost real money through conversation history.
Lifecycle hooks. /new, !new, and !clear now archive the conversation to the palace before clearing it (via a new GaladrielAgent.pop_and_archive_history()), so nothing is lost at the moment of wipe. Goodnight (21:00 CET) fires palace.archive_daily_logs() so today's log becomes searchable overnight. /compact and context compaction file verbatim tool_results to the palace before they're replaced with Haiku summaries.
Wake-up injection. A compact L0+L1 snapshot (~800 tokens, cached to ~/.mempalace/wake_up.md by a subprocess that keeps chromadb out of the main process) rides in the dynamic system-prompt block on every API call. Disable with PALACE_WAKE_UP_INJECT=0 if you want to dial back per-call overhead.
Cache impact, measured. 14 consecutive calls on a real deployment: 86.5% cache hit ratio, 71.2% total-input token savings vs. no caching. The 90% cache-read discount is intact — integration costs ~1.5 percentage points of cache hit ratio (one extra wake-up snapshot in dynamic, 10 more tool schemas in the tools-layer cache). Estimated annual overhead: ~$95.
Graceful degradation. If MemPalace isn't installed, all palace tools return [palace unavailable] at dispatch time; the rest of the harness runs normally. Upgrade path is pip install mempalace>=3.3.2,<3.4 + mempalace init + mempalace mine ..
Palace Protocol codified in SOUL.md — 5 non-negotiable rules: verify before speaking, say "let me check" when unsure, diary at session-end, invalidate-then-add when facts change. See config/TOOLS.md for the full decision matrix (memory_log vs palace_add_drawer vs palace_kg_add vs palace_diary_write).
All credit for the underlying memory system goes to the MemPalace team. This release is the harness integration; MemPalace is the engine.
1.11 — approval UX cleanup
Buttons replace reactions. Red-tier command approvals now render as Discord UI buttons (discord.ui.View) instead of ✅/❌ reactions. The "1/1" counter artifact from the bot's own seed reactions is gone, buttons disable on click to prevent double-submits, and the resolved message shows a proper greyed-out state. Also noticeably better on mobile — tap targets beat emoji-picker fiddling.
Dedup concurrent approvals. When Claude re-emits the same run_shell tool_use (typically after a max_tokens retry), subsequent callers now attach to the in-flight Future instead of spawning a second bubble. One bubble, one click, every caller gets the same answer. Fixes the "⏰ Timed out (denied)" message that could appear for a command which had already been approved and executed successfully. The resolved bubble also annotates dedup hits — (merged 2 requests) etc — so it's visible when the path fires.
1.1 — image handling & error ergonomics
iOS screenshot support. Discord's content_type header is unreliable on iOS — screenshots arrive labelled image/jpeg even when the bytes are PNG. Anthropic's API validates the actual format and returned a 400, breaking image upload on mobile. The harness now sniffs magic bytes (PNG, JPEG, GIF, WEBP) and uses the real type. Discord's header is treated as a hint, not truth.
Image retention by user turn. /compact strips image blocks from any message older than the last 3 user turns, independent of total message count. Previously images only aged out once they fell behind the "last 20 messages" cutoff, which could span many turns when tool use was involved. Three exchanges in, the base64 blob is usually moot — stop paying to carry it.
Humanized API errors. Instead of dumping raw exception repr to Discord (Error code: 400 — {'type': 'error', ...}), common Anthropic API exceptions are now mapped to short, readable explanations: timeouts, rate limits, auth failures, overloaded 529s, bad-request details, model-not-found hints. Unknown errors still fall through unchanged. Server logs continue to capture the full traceback for forensics.
License
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found