citelocal-agent
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 12 GitHub stars
Code Warn
- network request — Outbound network request in scripts/fetch_arxiv.py
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
100% local research agent for your papers - ask PDFs on your machine, page-accurate verified citations, cross-paper synthesis, Ollama-ready
citelocal-agent — 本地论文研究助手
中文 | English
针对一堆论文(或任意本地文档)提问,得到精确到页码、且经过校验的引用答案 —— 全程在本机运行。基于 LangGraph。
云端论文工具(ChatPDF、Elicit……)要你上传 PDF。citelocal-agent 不用:embedding 本地跑,论文不出本机(papers/ 已 gitignore),作答模型也可用 Ollama 本地跑。返回的答案是有据的 —— 每条引用都对照实际检索内容校验,精确到 PDF 页码。
凭什么不一样
- 🔒 全本地 / 隐私 —— PDF 绝不上传;本地 embedding,可选本地 LLM(Ollama)。适合未发表或敏感论文。
- 📎 精确到页、且校验过的引用 —— 答案引用
paper.pdf (p.3);引用 locator 对照检索校验,幻觉的会被丢弃。 - 🔗 跨论文综合 —— agent 自主检索、改写查询、把多篇论文的事实综合进一个答案。
- 🙅 诚实拒答 —— 论文里没有就说没有(相关性阈值),不编。
- 🧪 真检索 —— 混合 dense(bge)+ BM25 → RRF → cross-encoder 重排。
- 💬 CLI + Web UI、🔭 检索 trace、📊 评估,多格式(PDF / Markdown / RST / 文本)。
快速开始
# 1. 环境(Python 3.11)
conda create -n citelocal-agent python=3.11 -c conda-forge
conda activate citelocal-agent
pip install -e .
# 2. 作答 LLM:把 OPENAI_API_KEY 填进 .env —— 或完全本地:
cp .env.example .env
# pip install -e ".[ollama]" 且在 .env 设 LLM_MODEL=ollama:llama3.1
# 3. 拉论文(本地下载,绝不上传)并建索引
python scripts/fetch_arxiv.py --demo # 8 篇:Attention、RAG、BERT、T5、RoBERTa、DPR、SBERT、GPT-3
# 或:python scripts/fetch_arxiv.py 1706.03762 2005.11401 (任意 arXiv id)
python -m citelocal_agent.ingest --path ./papers --reset
# 4. 提问
python -m citelocal_agent.ask --trace "How is BERT related to the Transformer?"
# 多轮对话(追问会记住前几轮):
python -m citelocal_agent.chat
# 或 Web UI:
python -m citelocal_agent.web # http://127.0.0.1:8000
把 ingest --path 指向任意装有你自己 .pdf / .md / .rst / .txt 的文件夹即可。
运行示例
一个跨论文问题 —— agent 检索、列出来源、改写再检索,然后从两篇论文带页码作答(真实输出):
$ python -m citelocal_agent.ask --trace "How does retrieval-augmented generation use a retriever, and how is BERT related to the Transformer architecture?"
🔎 Intent: IN_SCOPE — retrieving from knowledge base
=== trace ===
1. search_docs query='retrieval-augmented generation retriever BERT Transformer architecture'
2. list_sources
3. search_docs query='BERT Transformer architecture bidirectional encoder layers'
=== Answer ===
RAG uses a retriever to access a dense vector index … the model marginalizes over
seq2seq predictions given different retrieved documents
[retrieval-augmented-generation.pdf (p.1); retrieval-augmented-generation.pdf (p.2)].
BERT is a multi-layer bidirectional Transformer encoder, based on the original
Transformer [bert.pdf (p.1); bert.pdf (p.3)].
=== Citations ===
- retrieval-augmented-generation.pdf (p.1)
- bert.pdf (p.1)
- bert.pdf (p.3)
超范围问题会被拒答;离线时 python scripts/check_retrieval.py 可无 key 查看检索栈。
Web UI
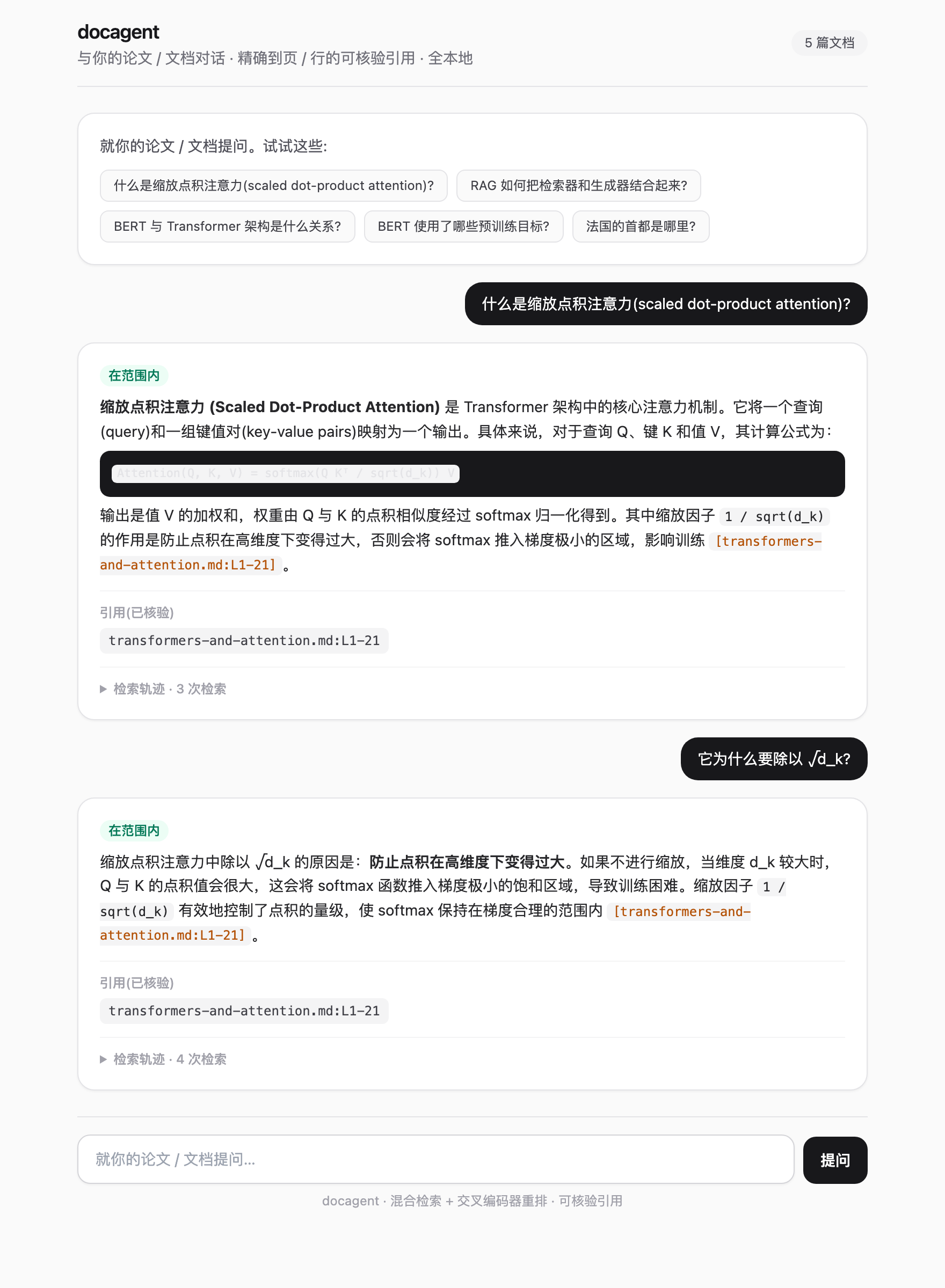
小型聊天前端(FastAPI + 静态 Tailwind),展示答案、意图徽章、引用 chips、被丢弃的未支撑引用、可折叠检索 trace。python -m citelocal_agent.web → http://127.0.0.1:8000。
API:
POST /api/ask {question, session_id?, collection?}→{kind, intent, answer, question, citations, unsupported, trace}POST /api/ask/stream—— 同样的请求体,SSE 流式:每个图节点一个step事件,最后一个final事件GET /api/sources {collection?}→{sources};GET /health→{status}
传 session_id 保持多轮对话(按线程 checkpointer),传 collection 让一个服务承载多个知识库。
设 DOCAGENT_API_KEY(沿用旧包名前缀)后 /api/* 需带 X-API-Key;RATE_LIMIT_REQUESTS/RATE_LIMIT_WINDOW 控制按客户端限流。
Docker
docker build -t citelocal-agent .
docker run --rm -v $PWD/papers:/papers -v $PWD/chroma_db:/data/chroma citelocal-agent \
python -m citelocal_agent.ingest --path /papers --reset
docker run -p 8000:8000 -v $PWD/chroma_db:/data/chroma -e OPENAI_API_KEY=sk-... citelocal-agent
架构
flowchart TB
START([START]) --> R[intent_router 意图路由]
R -- 超范围 / 空库 --> D([END · 拒答])
R -- 范围内 --> L[llm_call]
L --> C{是否终止工具?}
C -- search_docs --> E[environment 执行]
E --> L
C -- Answer --> X([END · 答案 + 校验引用])
E -.调用.-> PIPE
subgraph PIPE [混合检索管线]
direction TB
Q[query] --> DENSE[dense · bge]
Q --> BM25[BM25]
DENSE --> RRF[RRF 融合]
BM25 --> RRF
RRF --> RERANK[cross-encoder 重排]
RERANK --> THRESH[相关性阈值]
THRESH --> OUT2[top-k chunks + 页码/行号 locator]
end
agent 由 build_agent(config) 构建 —— import 时不初始化任何模型/reranker;工具绑定到配置好的 retriever(make_retrieval_tools)。
评估
评估集是一个带类别标注的 QA 数据集 src/citelocal_agent/eval/data/qa_cases.jsonl(每行一个 JSON)。每行带 intent、category(single_paper / multi_hop / numeric / definitional / out_of_scope / no_answer)、黄金 expected_sources、LLM 评判用的 criteria,以及 split:
offline_sample—— 答案落在内置sample_notes/,无需下载论文即可跑(离线 LLM 测试用)。full_corpus—— 需下载papers/,手动 / nightly 评估。
扩充评测集(生成 → 精校 → 评估):
python scripts/fetch_arxiv.py --demo && python -m citelocal_agent.ingest --path ./papers --reset
python scripts/generate_qa.py --n-per-category 25 # 用真实 chunk 让 LLM 起草候选题
# -> 审阅 src/citelocal_agent/eval/data/generated_raw.jsonl,把好题 curated=true 后并入 qa_cases.jsonl
python -m citelocal_agent.eval.run_eval # full_corpus,输出按类别分组的表
python -m citelocal_agent.eval.run_eval --split offline_sample --categories multi_hop
run_eval 同时输出总体与按类别分组的所有指标(按类别这一视图,才能证明某次改动是否真有帮助,比如多跳),并写出机器可读的 eval_results.json 基线,便于追踪里程碑间的差异。
内置语料现有 106 篇笔记(sample_notes/),覆盖架构内部、训练、分词、对齐、解码、检索、向量索引、RAG、智能体、评估等细分主题 —— 一个更真实、更难辨别的检索语料。评测集含 190 条用例,覆盖 6 个类别(offline_sample + 8 篇 demo 论文的 full_corpus)。其中 56 道多跳题故意需要同时检索多篇文档(每题标注 ≥2 个 expected_sources),专门考核「一问多文」的检索 + 综合。下表是一次代表性实测的快照(评测集随语料持续扩充;数字可用 run_eval 自行复核):
| 指标 | 结果 |
|---|---|
| 意图路由准确率 | 100% (53/53) |
| 检索召回(均值) | 0.91 |
| 答案正确率(LLM 评判) | 98% (44/45) |
| 引用准确率 | 100% (45/45) |
| 幻觉引用 | 0 |
| 拒答准确率 | 100% (8/8) |
按类别(召回 / 答案正确率):
| 类别 | n | 召回 | 答案 |
|---|---|---|---|
| single_paper | 24 | 0.92 | 0.95 |
| definitional | 16 | 1.00 | 1.00 |
| multi_hop | 26 | 0.64 | 0.96 |
| numeric | 4 | 1.00 | 1.00 |
| out_of_scope | 3 | — | 拒答 1.00 |
| no_answer | 5 | — | 拒答 1.00 |
**多文档(一问多文)**是重点也是最难的:在多文档多跳题(每题需 ≥2 篇文档)上、在 106 篇笔记的语料上实测 —— 引用接地 100%、幻觉引用 0、答案正确率 96%,检索召回 0.64(它要求同时命中一道题所需的每一段证据,所以召回天然偏低)。语料从 9 篇扩到 106 篇后,这些数字基本不变 —— 混合检索 + 重排在 100+ 干扰文档中仍能稳定召回正确的多篇来源。数字取决于
LLM_MODEL背后的回答模型;改了就重跑run_eval。
目录结构
src/citelocal_agent/
├── agent.py # LangGraph 工厂:intent_router + 应答循环 + trace
├── retriever.py # 混合检索:dense+BM25 -> RRF -> 重排 -> 阈值
├── ingest.py # 加载 -> 切块(带页码/行号出处) -> 向量化 -> Chroma
├── ask.py / web.py # CLI / FastAPI + 静态 Web UI
├── tools/ # make_retrieval_tools + make_web_tools(可选); Answer, Question
├── utils.py # extract_outcome():引用校验
└── eval/ # data/qa_cases.jsonl(数据集) + qa_dataset.py(加载器) + run_eval.py
scripts/ # fetch_arxiv.py · generate_qa.py · check_retrieval.py · calibrate_threshold.py
sample_notes/ # 内置离线语料(CI / 快速试,无需下载)
tests/ # test_unit.py(离线)+ test_retrieval.py + test_response.py
测试
python tests/run_all_tests.py # 离线检索测试(无需 key)
python tests/run_all_tests.py --all # + LLM 端到端(需 key + 已 ingest 论文)
CI 跑 ruff、mypy、离线单测(无网络/模型)、sample_notes 上的检索测试、以及「wheel 是否打包 UI」冒烟。
开发 / 接入真实模型 / 评测过程中的问题与解决方案,见 工程踩坑记录。
配置
.env(见 .env.example):OPENAI_API_KEY、LLM_MODEL(默认 openai:gpt-4.1;任意 init_chat_model id,含 ollama:llama3.1)、EMBEDDING_MODEL(BAAI/bge-small-en-v1.5)、RERANKER_MODEL、TOP_K/CANDIDATE_K、SCORE_THRESHOLD(已校准,见 scripts/calibrate_threshold.py)、CHROMA_PATH/CHROMA_COLLECTION。
联网搜索工具(可选,默认关闭)
项目默认「本地优先」。设 ENABLE_WEB_SEARCH=1 后,agent 在同一个工具循环里自主选择本地文档检索还是联网:文档不足/需时效外部事实时,它会调 web_search → fetch_url。关键是引用同样可验证 —— 网页结果带 web:<url> locator,经与文档完全相同的 retrieved_locators/evidence 通道校验:引用了没真正抓取过的 URL 会被移入 unsupported。启用后意图路由新增 web_answerable 档,让「文档外但网上能查」的问题也能进入 agent(纯闲聊仍拒答)。
pip install -e ".[web]" # 免密钥 DuckDuckGo 后端
ENABLE_WEB_SEARCH=1 python -m citelocal_agent.ask "<文档外、网上可查的问题>"
# 可选更高质量后端(需 TAVILY_API_KEY):
# pip install -e ".[tavily]" && ENABLE_WEB_SEARCH=1 WEB_SEARCH_BACKEND=tavily ...
WEB_SEARCH_BACKEND(ddg默认/tavily)、WEB_SEARCH_RESULTS、WEB_FETCH_CHARS 可调。默认关闭时工具集、路由、离线 CI 与原来完全一致。
技术栈
LangGraph · LangChain · Chroma · sentence-transformers (bge) · rank-bm25 · cross-encoder · pypdf · FastAPI · Tailwind
许可证
MIT。Demo 论文是本地从 arXiv 下载的,未在本仓库再分发,版权归原作者。
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found