copilot-bridge
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 8 GitHub stars
Code Warn
- process.env — Environment variable access in scripts/probe-claude-cli.ts
- process.env — Environment variable access in scripts/probe-claude.ts
- network request — Outbound network request in scripts/probe-claude.ts
Permissions Pass
- Permissions — No dangerous permissions requested
This tool acts as a local proxy server that translates standard OpenAI and Anthropic API calls into GitHub Copilot API requests. It allows developers to use their existing Copilot subscriptions with third-party coding assistants like Claude Code, Codex CLI, and Continue.
Security Assessment
Risk Rating: High
The tool requires users to authenticate via a GitHub device login to function, inherently handling sensitive access tokens. Code scans show it makes outbound network requests to GitHub's servers and reads environment variables. While no hardcoded secrets or dangerous local shell execution permissions were detected, the primary security concern stems from the tool's core mechanism: it reverse-engineers the official Copilot API. This violates GitHub's terms of service and triggers anti-abuse detection systems. Using automated or bulk requests through this bridge puts your GitHub account at risk of warnings or temporary suspension.
Quality Assessment
The project is actively maintained, having received updates as recently as today. It uses the permissive MIT license and includes clear documentation, with built-in safeguards like a `--rate-limit` flag to help users throttle traffic. However, community trust and visibility are currently very low, with only 8 stars on GitHub. Because it relies on an unofficial, reverse-engineered protocol, it is highly fragile and may break without warning whenever GitHub updates their backend.
Verdict
Use with extreme caution: the code functions as intended but relies on an unauthorized reverse-engineered API, posing a significant risk of violating GitHub's terms and resulting in the suspension of your Copilot access.
Use GitHub Copilot as a local OpenAI/Anthropic-compatible API for Codex CLI, Claude Code, and Continue.
copilot-bridge


Use GitHub Copilot as a local OpenAI/Anthropic-compatible API, so Codex CLI, Claude Code and Continue can talk to Copilot with minimal configuration.
[!WARNING]
This is a reverse-engineered bridge for the GitHub Copilot API. It is not
supported by GitHub, and may break unexpectedly. Use at your own risk.
[!WARNING]
GitHub Security Notice:
Excessive automated or scripted use of Copilot (including rapid or bulk
requests, such as via automated tools) may trigger GitHub's abuse-detection
systems. You may receive a warning from GitHub Security, and further
anomalous activity could result in temporary suspension of your Copilot
access.GitHub prohibits use of their servers for excessive automated bulk activity
or any activity that places undue burden on their infrastructure.Please review:
Use this bridge responsibly to avoid account restrictions. The
--rate-limit <seconds>flag is provided to help throttle upstream traffic.
Demo
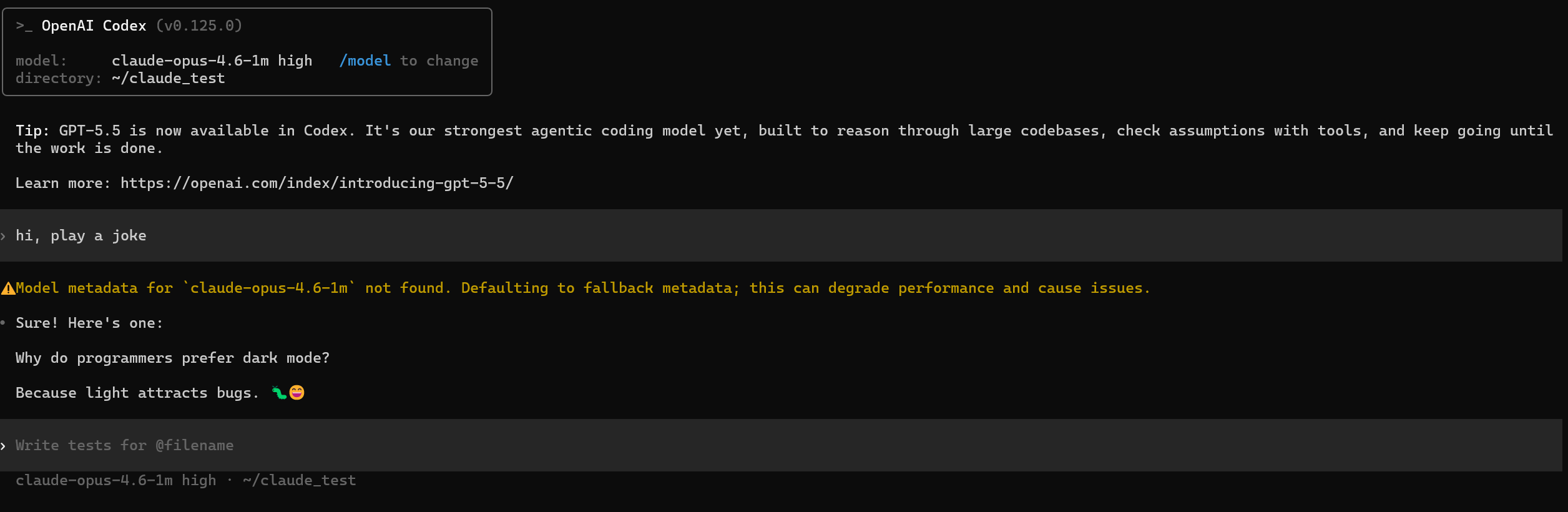
Codex CLI
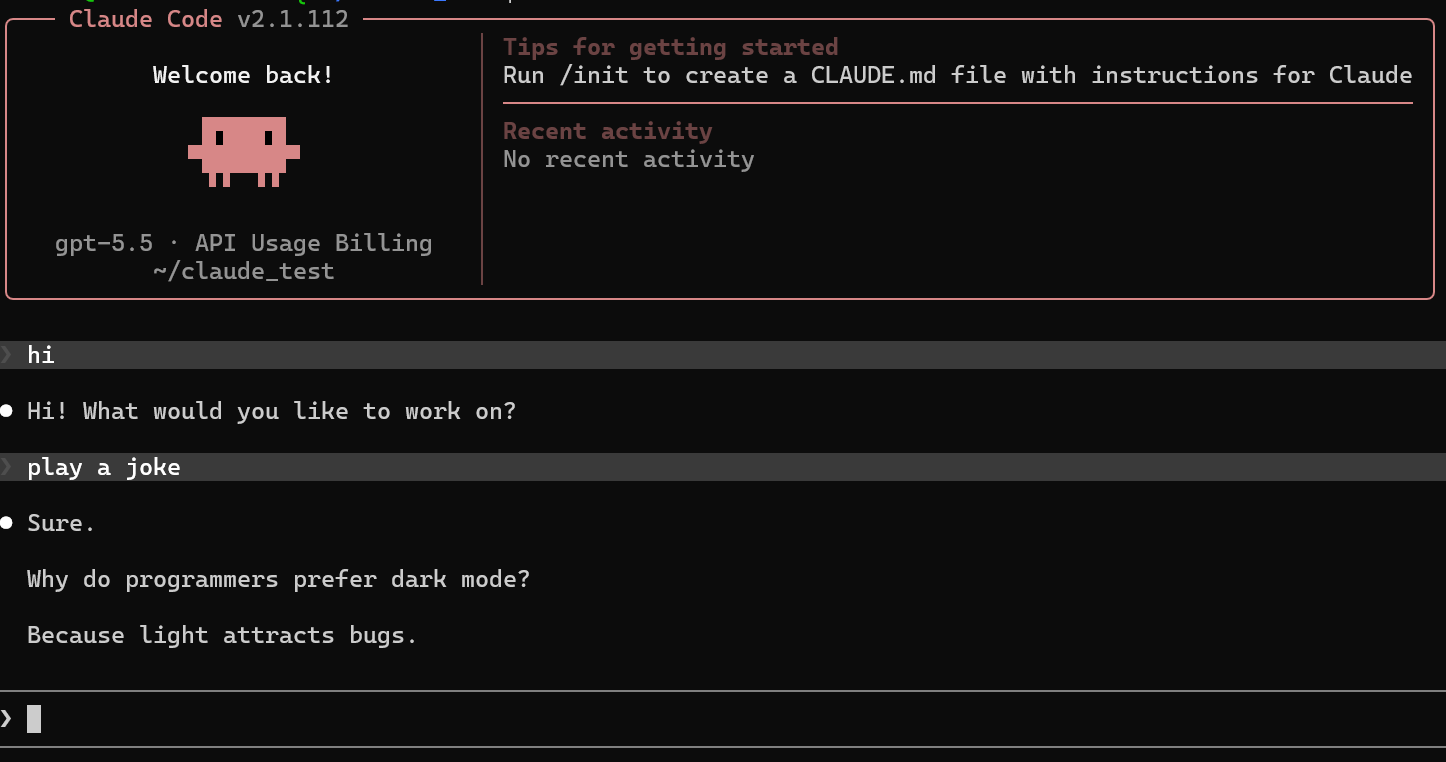
Claude Code
Install & run
# one-time GitHub device login
npx betahi-copilot-bridge@latest auth
# start the bridge on 127.0.0.1:4142
npx betahi-copilot-bridge@latest start
start flags: --host, --port, --show-token, --debug,--no-codex-setup, --select-model, --no-prompt,--rate-limit <seconds>, --wait.
After startup the banner prints a Usage Viewer link of the formhttps://betahi.github.io/copilot-bridge?endpoint=http://127.0.0.1:4142/usage,
which renders the Copilot quota snapshot (chat / completions / premium
interactions) read from GET /usage.
The bridge exposes both adapter-style endpoints (/v1/responses,/v1/messages) and the raw OpenAI-compatible surface
(/v1/chat/completions, /v1/embeddings, /v1/models) so tools like
LiteLLM, Continue, Cline and Aider work out of the box. CORS is enabled
globally for browser-based clients.
--rate-limit N enforces a minimum of N seconds between upstream
requests (anti–abuse-detection throttle). Add --wait to block instead
of returning HTTP 429 when the window has not elapsed.
--debug enables extra upstream error diagnostics in console logs.
- Includes: token limits, stream mode, tool count, invalid tool names, and suspicious tool-schema paths.
- Does not include: request messages, prompt text, bearer tokens, tool descriptions, or the full request body.
Review or redact debug logs before sharing them publicly.
Configure Codex CLI
start writes a managed block into ~/.codex/config.toml. You don't edit
this block; the bridge regenerates it on every start.
# >>> copilot-bridge managed block — auto-generated, do not edit between markers >>>
model_provider = "bridge"
[model_providers.bridge]
name = "Copilot Bridge"
base_url = "http://127.0.0.1:4142/v1"
wire_api = "responses"
prefer_websockets = false
requires_openai_auth = false
# <<< copilot-bridge managed block — edits outside this block are preserved <<<
To pin the default model for codex (without passing -m every time),
edit the top of the same file — outside the markers. The bridge preserves
these keys across rewrites:
model = "gpt-5.3-codex"
model_reasoning_effort = "high"
If model_reasoning_effort is omitted, the bridge leaves it unset and does not
send a reasoning effort for Codex requests (a startup info log also reminds you).
model_reasoning_effort only affects Codex requests; it does not affect Claude.
That's it — codex exec '...' will now route through the bridge to Copilot.
Use --no-codex-setup to skip the managed-block writer entirely (e.g. if you
manage ~/.codex/config.toml yourself).
Codex warning: "Model metadata ... not found"
This is a Codex client-side metadata warning, not a bridge routing failure.
Requests can still complete through the bridge.
For claude-opus-4.6-1m, upstream still enforces a 1,000,000-token prompt
limit (about 900k succeeds; around 1,000,046 is rejected as too long).
Configure Claude Code
Bridge endpoints: POST /v1/messages, POST /v1/messages/count_tokens.
copilot-bridge start automatically writes ANTHROPIC_BASE_URL (and a dummyANTHROPIC_AUTH_TOKEN if absent) into ~/.claude/settings.json, soclaude works the moment the bridge is listening — even on a different host
or port. Pass --no-claude-setup to skip this. All other keys in your
settings file (model overrides, plugins, marketplaces) are preserved.
Minimal recommended config is:
{
"env": {
"ANTHROPIC_BASE_URL": "http://127.0.0.1:4142",
"ANTHROPIC_AUTH_TOKEN": "dummy",
"ANTHROPIC_MODEL": "claude-opus-4.7",
"MODEL_REASONING_EFFORT": "medium"
}
}
Optional slot-specific:
{
"env": {
"ANTHROPIC_BASE_URL": "http://127.0.0.1:4142",
"ANTHROPIC_AUTH_TOKEN": "dummy",
"ANTHROPIC_MODEL": "claude-opus-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "claude-sonnet-4.6",
"ANTHROPIC_SMALL_FAST_MODEL": "claude-haiku-4.5",
"MODEL_REASONING_EFFORT": "medium"
}
}
MODEL_REASONING_EFFORT (case-insensitive key lookup) is also read from the
project-local .claude/settings.json and .claude/settings.local.json and
applied to Claude requests only when the model supports reasoning. If it is not
configured, Claude requests do not infer or attach a reasoning effort.
Environment overrides
| Variable | Purpose |
|---|---|
COPILOT_TOKEN |
Pre-issued Copilot bearer token (skip device login). |
COPILOT_ACCOUNT_TYPE |
individual | business | enterprise. |
COPILOT_BASE_URL |
Override the upstream Copilot base URL. |
COPILOT_VSCODE_VERSION |
Override the VS Code version sent upstream. |
MODEL_REASONING_EFFORT |
Claude-side reasoning effort override. |
Supported models
The bridge resolves aliases and clamps reasoning effort to what each model
accepts upstream.
GPT-5 family — native Responses passthrough
| Model | Reasoning efforts |
|---|---|
gpt-5.5 |
none, low, medium, high, xhigh |
gpt-5.4 |
low, medium, high, xhigh |
gpt-5.4-mini |
none, low, medium |
gpt-5.3-codex |
low, medium, high, xhigh |
gpt-5.2 |
low, medium, high, xhigh |
gpt-5.2-codex |
low, medium, high, xhigh |
gpt-5-mini |
low, medium, high |
Claude family — translated to chat completions
| Model | Reasoning efforts | Notes |
|---|---|---|
claude-opus-4.7 |
low, medium, high, xhigh, max |
Effort sent as output_config.effort. |
claude-opus-4.6 |
low, medium, high |
|
claude-opus-4.6-1m |
low, medium, high |
1M-token context window. |
claude-sonnet-4.6 |
low, medium, high |
|
claude-opus-4.5 |
— | Reasoning not accepted upstream. |
claude-sonnet-4.5 |
— | Reasoning not accepted upstream. |
claude-sonnet-4 |
— | Reasoning not accepted upstream. |
claude-haiku-4.5 |
— | Reasoning not accepted upstream. |
Gemini family — translated to chat completions
| Model | Aliases |
|---|---|
gemini-3.1-pro-preview |
gemini-3.1-pro |
gemini-3-flash-preview |
gemini-3-flash |
gemini-2.5-pro |
— |
Legacy
gpt-4.1, gpt-4o — chat-only upstream, no reasoning parameter.
Reasoning effort
For OpenAI-compatible clients, unsupported reasoning values are clamped to the
model capability table instead of being forwarded upstream. If a request omits
reasoning effort, the bridge leaves it omitted rather than inferring a default.
Claude-side reasoning can be set globally via MODEL_REASONING_EFFORT (env, orenv in ~/.claude/settings.json); invalid Claude-side values are ignored,
and per-request reasoning_effort takes precedence.
Development
Requires Bun ≥ 1.2.
bun install
bun run dev # watch mode against src/main.ts
bun test # run all tests (bun test runner)
bun run typecheck # tsc --noEmit
bun run build # produce dist/main.js with tsdown
# run directly from source (no build, no npx); --port specifies the port
bun run ./src/main.ts start --host 127.0.0.1 --port 4141 --no-prompt
Adding another CLI: drop a new translator under src/bridges/<client>/,
reuse src/services/copilot/ for upstream calls, register routes insrc/server.ts, and add tests under tests/.
License
MIT — see LICENSE.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found