Cortex
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 7 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
This tool is a cognitive profiling and memory system designed for Claude Code. It uses published computational neuroscience algorithms and information retrieval techniques to give the AI a structured, long-term memory.
Security Assessment
The overall risk is Low. A scan of 12 files found no dangerous patterns, hardcoded secrets, or dangerous permission requests. The tool appears to strictly process and store data locally using scientific equations rather than executing system shell commands or making unauthorized external network requests.
Quality Assessment
The project is of high technical quality and actively maintained, with its last code push happening today. The documentation is exceptionally thorough, explicitly emphasizing peer-reviewed science, rigorous sourcing, and verifiable benchmarks (with over 2,000 passing tests). It uses the permissive MIT license, making it safe for commercial and personal use. The only notable drawback is low community visibility; it currently has only 7 GitHub stars, meaning it has not yet been broadly reviewed by the open-source public.
Verdict
Safe to use, though you should keep in mind that it is a very new and unproven tool with minimal community oversight.
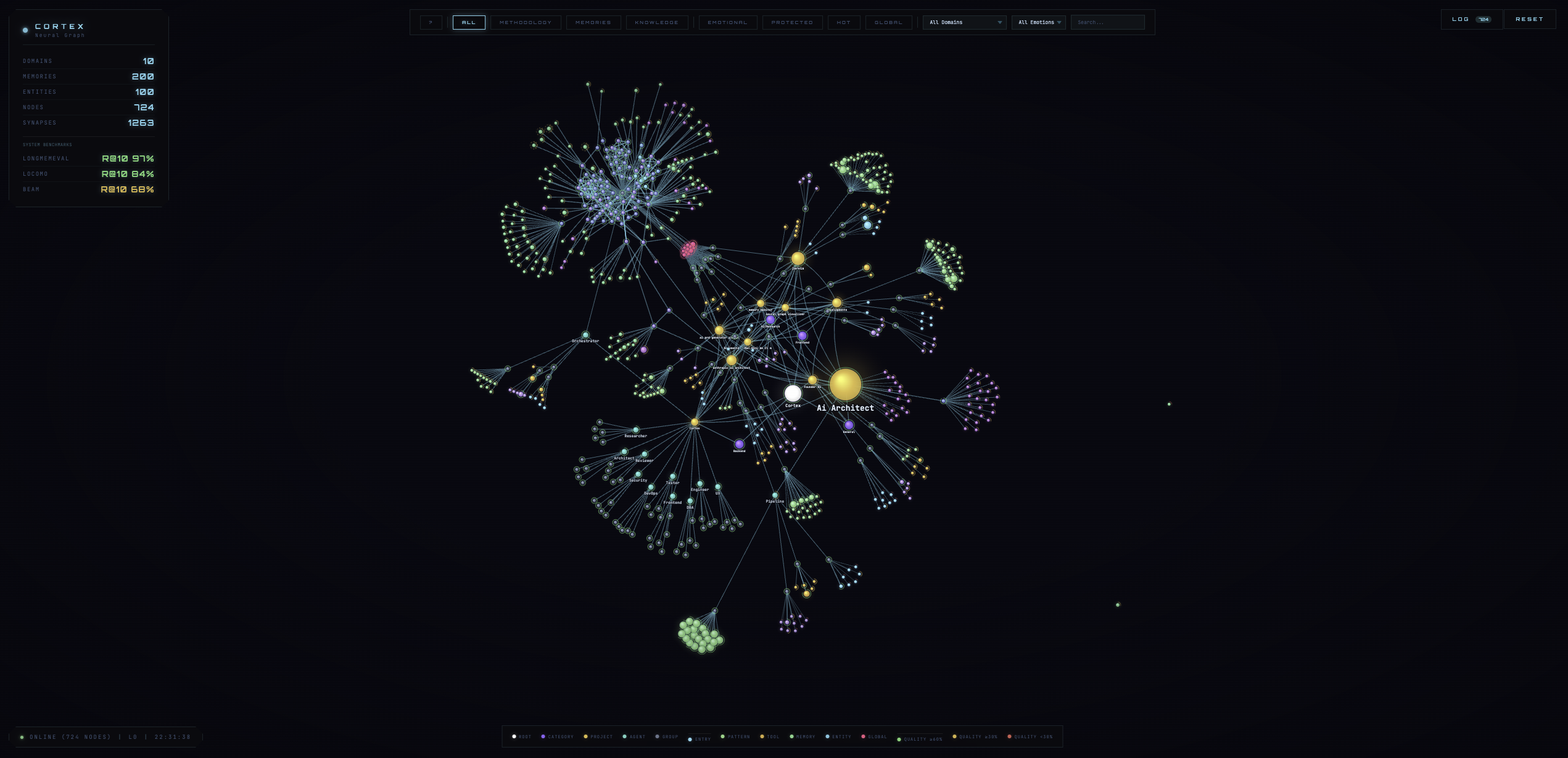
C.O.R.T.E.X. — Cognitive profiling system for Claude Code
Cortex
A scientifically-grounded memory system built on published neuroscience and information retrieval research
![]()
![]()
![]()
![]()
Every algorithm, constant, and threshold in this codebase traces to a published paper or measured ablation data. Nothing is guessed. Where engineering defaults exist, they are explicitly documented as such.
Scientific Foundation | Paper Index | Architecture | Benchmarks | References
Scientific Foundation
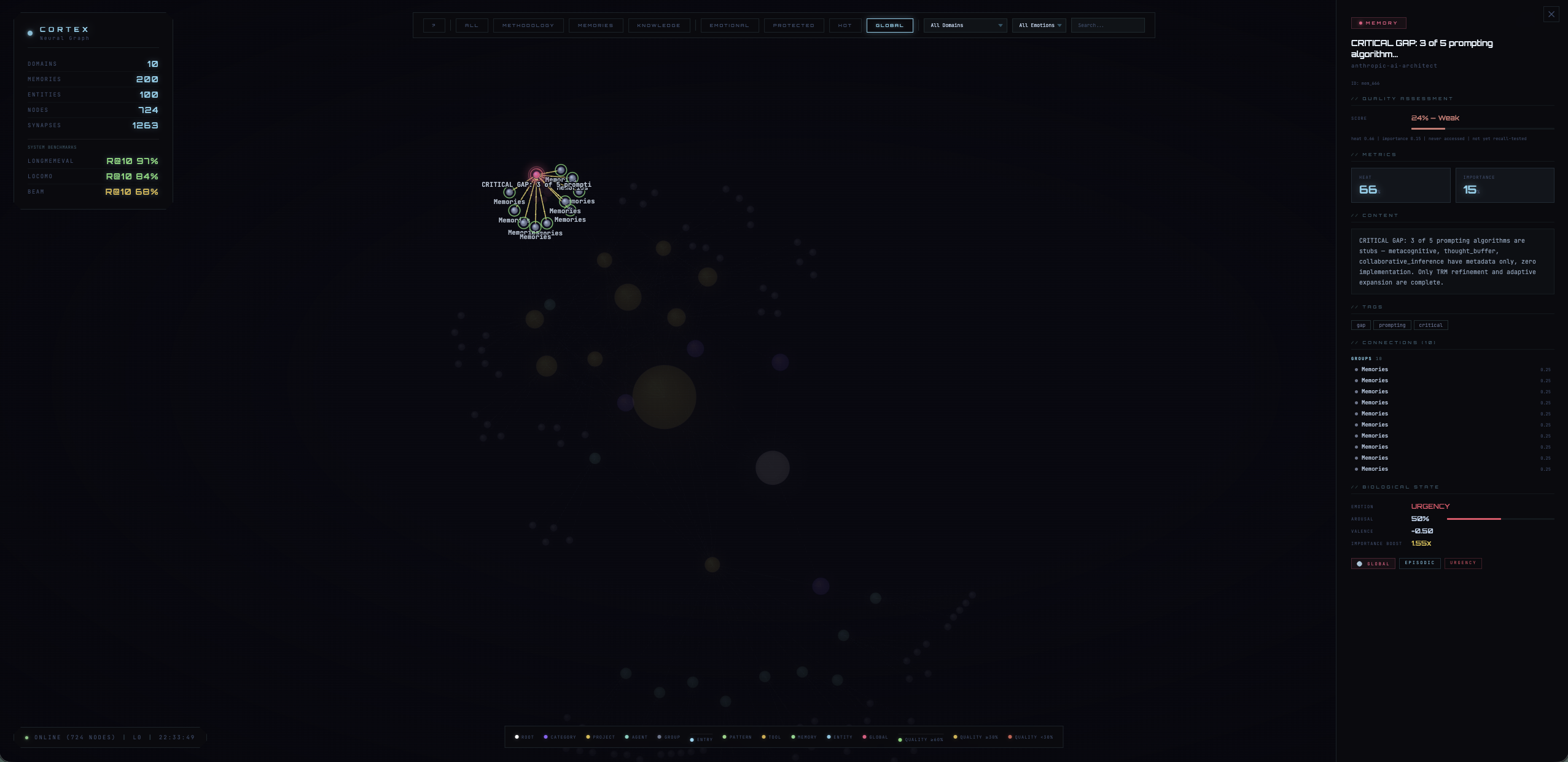
Cortex implements 23 computational neuroscience mechanisms and 5 information retrieval techniques. Each is a faithful translation of published equations into working code — not a metaphor, not an analogy, not a "bio-inspired heuristic."
The Zetetic Standard
Every module follows a strict evidence protocol:
- No source, no implementation. Every algorithm must trace to a published paper with exact equations.
- Multiple sources required. A single paper is a hypothesis. Cross-reference before accepting.
- Read the actual paper. Not blog posts, not summaries. The equations.
- No invented constants. Every hardcoded number comes from paper equations, paper experiments, or measured ablation data.
- Benchmark before commit. Every change is measured. No regression accepted.
- Say "I don't know." A confident wrong answer destroys trust.
Where engineering defaults exist (signal weights, blend parameters), they are explicitly labeled in the code and accompanied by ablation data where available (see benchmarks/beam/ablation_results.json). They are never falsely attributed to a paper.
How to audit this codebase
Every module's docstring cites its source paper and the exact equations implemented:
grep -r "et al\." mcp_server/core/ --include="*.py" -l # All paper citations
cat tasks/paper-implementation-audit.md # Full audit trail
Paper Index
Information Retrieval
| Paper | Year | Venue | Implementation | Module |
|---|---|---|---|---|
| Bruch et al. "An Analysis of Fusion Functions for Hybrid Retrieval" | 2023 | ACM TOIS | TMM normalization for multi-signal fusion: TMM(s) = (s - m_theoretical) / (M_query - m_theoretical) |
pg_schema.py |
| Nogueira & Cho "Passage Re-ranking with BERT" | 2019 | arXiv | Linear interpolation of first-stage and cross-encoder scores. Alpha=0.70 from BEAM ablation. | reranker.py |
| Joren et al. "Sufficient Context" | 2025 | ICLR | Binary confidence gate on cross-encoder output. Simplified from calibrated sigmoid. | reranker.py |
| Collins & Loftus "A spreading-activation theory of semantic processing" | 1975 | Psych. Review | Recursive entity graph traversal with exponential decay, implemented as PL/pgSQL recursive CTE. | spreading_activation.py |
Neuroscience — Encoding
| Paper | Year | Venue | Implementation | Module |
|---|---|---|---|---|
| Friston "A theory of cortical responses" | 2005 | Phil. Trans. R. Soc. B | 3-level free energy write gate (sensory/entity/schema). Fires when prediction error exceeds threshold. | hierarchical_predictive_coding.py |
| Bastos et al. "Canonical microcircuits for predictive coding" | 2012 | Neuron | Forward (prediction error) and backward (prediction) message passing in the 3-level hierarchy. | hierarchical_predictive_coding.py |
| Wang & Bhatt "Emotional modulation of memory" | 2024 | Psych. Review | Yerkes-Dodson inverted-U priority encoding: priority = valence * yerkes_dodson(arousal). |
emotional_tagging.py |
| Doya "Metalearning and neuromodulation" | 2002 | Neural Networks | DA/NE/ACh/5-HT coupled cascade with cross-channel effects. | coupled_neuromodulation.py |
| Schultz "A neural substrate of prediction and reward" | 1997 | Science | Dopamine prediction error: DA = reward - expected_reward. |
coupled_neuromodulation.py |
Neuroscience — Consolidation
| Paper | Year | Venue | Implementation | Module |
|---|---|---|---|---|
| Kandel "The molecular biology of memory storage" | 2001 | Nobel / Science | Four-stage cascade: LABILE -> EARLY_LTP -> LATE_LTP -> CONSOLIDATED. | cascade.py |
| Dudai "The restless engram" | 2012 | Phil. Trans. R. Soc. B | Reconsolidation: accessing a consolidated memory returns it to labile state. | reconsolidation.py |
| McClelland et al. "Why there are complementary learning systems" | 1995 | Psych. Review | CLS: fast hippocampal binding + slow cortical integration. Two-stage transfer. | dual_store_cls.py, two_stage_model.py |
| Kumaran et al. "What learning systems do intelligent agents need?" | 2016 | Neurosci. & Biobehav. Rev. | Schema-consistent rapid cortical learning accelerating hippocampal transfer. | two_stage_model.py |
| Frey & Morris "Synaptic tagging and long-term potentiation" | 1997 | Nature | Weak memories sharing entities with strong ones get retroactively promoted. | synaptic_tagging.py |
| Josselyn & Tonegawa "Memory engrams" | 2020 | Science | CREB-like excitability slots for engram allocation competition. | engram.py |
Neuroscience — Retrieval & Navigation
| Paper | Year | Venue | Implementation | Module |
|---|---|---|---|---|
| Behrouz et al. "Titans: Learning to Memorize at Test Time" | 2025 | ICML | S_t = eta*S_{t-1} - theta*grad_l(M;x), M_t = M_{t-1} - S_t. Note: paper uses learned eta/theta; we use fixed constants (documented simplification). |
titans_memory.py |
| Stachenfeld et al. "The hippocampus as a predictive map" | 2017 | Nat. Neurosci. | Successor Representation: co-access matrix for "what memories are usually accessed together?" | cognitive_map.py |
| Ramsauer et al. "Hopfield Networks is All You Need" | 2021 | ICLR | Modern continuous Hopfield for content-addressable recall: E = -log(sum(exp(beta * xi^T * q))). |
hopfield.py |
| Kanerva "Hyperdimensional computing" | 2009 | Cognitive Computation | 1024-dim bipolar HDC: bind, bundle, permute for compositional memory addressing. | hdc_encoder.py |
Neuroscience — Plasticity & Maintenance
| Paper | Year | Venue | Implementation | Module |
|---|---|---|---|---|
| Hasselmo "What is the function of hippocampal theta rhythm?" | 2005 | Hippocampus | Theta/gamma oscillatory gating for encoding vs retrieval phases. | oscillatory_clock.py |
| Buzsaki "Hippocampal sharp wave-ripple" | 2015 | Neuron | SWR events trigger replay and consolidation during idle periods. | oscillatory_clock.py |
| Leutgeb et al. "Pattern separation in the dentate gyrus" | 2007 | Science | DG orthogonalization via random projection: output = sign(W_random @ input). |
pattern_separation.py |
| Yassa & Stark "Pattern separation in the hippocampus" | 2011 | Trends Neurosci. | Neurogenesis analog: new random projections increase separation capacity over time. | pattern_separation.py |
| Turrigiano "The self-tuning neuron" | 2008 | Nat. Rev. Neurosci. | Homeostatic synaptic scaling: proportional rescaling when average heat drifts from target. | homeostatic_plasticity.py |
| Abraham & Bear "Metaplasticity" | 1996 | Trends Neurosci. | BCM sliding threshold: LTP/LTD threshold shifts based on recent activity history. | homeostatic_plasticity.py |
| Tse et al. "Schemas and memory consolidation" | 2007 | Science | Schema-accelerated consolidation: matching memories skip hippocampal replay. | schema_engine.py |
| Gilboa & Marlatte "Neurobiology of schemas" | 2017 | Trends Cogn. Sci. | Piaget accommodation: schema updates when new evidence conflicts. | schema_engine.py |
| Hebb The Organization of Behavior | 1949 | Book | delta_w = lr * pre * post. Co-occurrence strengthening of entity edges. |
synaptic_plasticity.py |
| Bi & Poo "Synaptic modifications in cultured hippocampal neurons" | 1998 | J. Neurosci. | STDP: temporal order determines LTP vs LTD direction. | synaptic_plasticity.py |
| Perea et al. "Tripartite synapses" | 2009 | Trends Neurosci. | Astrocyte calcium dynamics: dCa/dt = IP3_influx - SERCA_pump + leak. D-serine LTP facilitation. |
tripartite_synapse.py |
| Kastellakis et al. "Synaptic clustering within dendrites" | 2015 | Neuron | Branch-specific nonlinear integration: co-active inputs produce supralinear summation. | dendritic_clusters.py |
| Wang et al. "Microglia-mediated synapse elimination" | 2020 | Science | Complement-dependent pruning of weak edges + orphan archival. | microglial_pruning.py |
| Wixted "The psychology and neuroscience of forgetting" | 2004 | Ann. Rev. Psych. | Proactive/retroactive interference detection + sleep orthogonalization. | interference.py |
| Ebbinghaus Memory | 1885 | Book | Exponential forgetting: retention = e^(-t/S). Foundation for heat decay. |
thermodynamics.py |
| Kosowski et al. "Dragon Hatchling" | 2025 | arXiv | Hebbian co-activation: weight += lr * score_a * score_b on co-retrieved entity edges. |
pg_store_relationships.py |
Ablation Data
Ablation results are committed to the repository as JSON for reproducibility.
Rerank Alpha (Cross-Encoder Blend Weight)
Tested on BEAM 100K (20 conversations, 395 questions). Source: benchmarks/beam/ablation_results.json
| Alpha | BEAM MRR | Note |
|---|---|---|
| 0.00 | 0.442 | No CE reranking |
| 0.30 | 0.511 | Light CE influence |
| 0.50 | 0.529 | Equal blend |
| 0.55 | 0.535 | Previous default |
| 0.70 | 0.542 | Current default |
Higher CE weight helps because conversational memory benefits more from semantic understanding (cross-encoder) than lexical matching (first-stage).
Documented Engineering Defaults
These values lack paper backing and are explicitly marked as such in code:
| Constant | Value | Location | Status |
|---|---|---|---|
| FTS weight | 0.5 | pg_recall.py |
Engineering default |
| Heat weight | 0.3 | pg_recall.py |
Engineering default |
| Ngram weight | fts * 0.6 | pg_recall.py |
Engineering heuristic |
| Recency decay | 0.01/day | pg_schema.py |
Half-life ~69 days |
| Titans eta | 0.9 | titans_memory.py |
Paper uses learned params; this is fixed SGD default |
| Titans theta | 0.01 | titans_memory.py |
Paper uses learned params; this is fixed lr default |
| CE gate threshold | 0.15 | reranker.py |
Engineering default |
| CE suppression | 0.1 | reranker.py |
Engineering default |
Architecture
Clean Architecture. Inner layers never import outer layers.

| Layer | Modules | Rule |
|---|---|---|
| core/ | 108 | Pure business logic. Zero I/O. Imports only shared/. |
| infrastructure/ | 21 | All I/O: PostgreSQL, embeddings, file system. |
| handlers/ | 60 | Composition roots wiring core + infrastructure. |
| shared/ | 11 | Pure utilities. Python stdlib only. |
Storage: PostgreSQL 15+ with pgvector (HNSW) and pg_trgm. All retrieval in PL/pgSQL stored procedures.
Retrieval pipeline: Intent classification -> PG recall_memories() (5-signal TMM fusion) -> FlashRank cross-encoder reranking -> Titans surprise update.
| Signal | Source | TMM Theoretical Min | Paper |
|---|---|---|---|
| Vector similarity | pgvector HNSW (384-dim) | -1.0 | Bruch et al. 2023 |
| Full-text search | tsvector + ts_rank_cd | 0.0 | Bruch et al. 2023 |
| Trigram similarity | pg_trgm | 0.0 | Bruch et al. 2023 |
| Thermodynamic heat | Ebbinghaus decay model | 0.0 | Ebbinghaus 1885 |
| Recency | Exponential time decay | 0.0 | -- |
Benchmarks
All scores are retrieval-only — no LLM reader in the evaluation loop. We measure whether retrieval places correct evidence in the top results. Nothing else.
Most memory systems report full QA scores (retrieve + GPT-4 reader + judge). This conflates retrieval quality with reader model strength. A strong reader compensates for broken retrieval. We don't do that.
| Benchmark | Metric | Cortex | Best in Paper | Paper |
|---|---|---|---|---|
| LongMemEval | R@10 | 98.0% | 78.4% | Wang et al., ICLR 2025 |
| LongMemEval | MRR | 0.880 | -- | |
| LoCoMo | R@10 | 97.7% | -- | Maharana et al., ACL 2024 |
| LoCoMo | MRR | 0.840 | -- | |
| BEAM | Overall MRR | 0.532 | 0.329 (LIGHT) | Tavakoli et al., ICLR 2026 |
Note: BEAM LIGHT comparison is full QA (LLM-as-judge from Table 2), not retrieval-only — shown for reference.
BEAM per-ability breakdown| Ability | MRR | R@5 | R@10 | LIGHT (Table 2) |
|---|---|---|---|---|
| contradiction_resolution | 0.879 | 100.0% | 100.0% | 0.050 |
| knowledge_update | 0.867 | 97.5% | 97.5% | 0.375 |
| temporal_reasoning | 0.857 | 95.0% | 97.5% | 0.075 |
| multi_session_reasoning | 0.738 | 87.5% | 92.5% | -- |
| information_extraction | 0.542 | 65.0% | 72.5% | 0.375 |
| summarization | 0.359 | 61.1% | 69.4% | 0.277 |
| preference_following | 0.356 | 55.0% | 62.5% | 0.483 |
| event_ordering | 0.353 | 52.5% | 62.5% | 0.266 |
| instruction_following | 0.242 | 37.5% | 52.5% | 0.500 |
| abstention | 0.125 | 12.5% | 12.5% | 0.750 |
Known weaknesses: Abstention requires knowing what was never discussed — a comprehension problem, not retrieval. Instruction following requires surfacing meta-directives semantically distant from topical queries.
LongMemEval per-category breakdown| Category | MRR | R@10 |
|---|---|---|
| Single-session (user) | 0.793 | 91.4% |
| Single-session (assistant) | 0.970 | 100.0% |
| Single-session (preference) | 0.706 | 96.7% |
| Multi-session reasoning | 0.917 | 100.0% |
| Temporal reasoning | 0.887 | 97.7% |
| Knowledge updates | 0.884 | 100.0% |
| Category | MRR | R@5 | R@10 |
|---|---|---|---|
| single_hop | 0.714 | 85.5% | 91.8% |
| multi_hop | 0.736 | 82.2% | 84.1% |
| temporal | 0.538 | 65.2% | 76.1% |
| open_domain | 0.817 | 88.8% | 91.1% |
| adversarial | 0.809 | 87.0% | 89.0% |
Development
pytest # 2068 tests
pytest tests_py/core/ # Core layer only
References
- Ebbinghaus, H. (1885). Memory: A Contribution to Experimental Psychology.
- Hebb, D.O. (1949). The Organization of Behavior. Wiley.
- Collins, A.M. & Loftus, E.F. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6).
- Bienenstock, E.L., Cooper, L.N. & Munro, P.W. (1982). Theory for the development of neuron selectivity. J. Neuroscience, 2(1).
- McClelland, J.L., McNaughton, B.L. & O'Reilly, R.C. (1995). Why there are complementary learning systems. Psychological Review, 102(3).
- Abraham, W.C. & Bear, M.F. (1996). Metaplasticity. Trends in Neuroscience, 19(4).
- Frey, U. & Morris, R.G.M. (1997). Synaptic tagging and long-term potentiation. Nature, 385.
- Schultz, W. (1997). A neural substrate of prediction and reward. Science, 275(5306).
- Bi, G.Q. & Poo, M.M. (1998). Synaptic modifications in cultured hippocampal neurons. J. Neuroscience, 18(24).
- Kandel, E.R. (2001). The molecular biology of memory storage. Science, 294(5544).
- Doya, K. (2002). Metalearning and neuromodulation. Neural Networks, 15(4-6).
- Wixted, J.T. (2004). The psychology and neuroscience of forgetting. Ann. Rev. Psychology, 55.
- Friston, K. (2005). A theory of cortical responses. Phil. Trans. R. Soc. B, 360(1456).
- Hasselmo, M.E. (2005). What is the function of hippocampal theta rhythm? Hippocampus, 15(7).
- Leutgeb, J.K. et al. (2007). Pattern separation in the dentate gyrus and CA3. Science, 315(5814).
- Tse, D. et al. (2007). Schemas and memory consolidation. Science, 316(5821).
- Turrigiano, G.G. (2008). The self-tuning neuron. Nature Reviews Neuroscience, 135(3).
- Kanerva, P. (2009). Hyperdimensional computing. Cognitive Computation, 1(2).
- Perea, G. et al. (2009). Tripartite synapses. Trends in Neuroscience, 32(8).
- Yassa, M.A. & Stark, C.E.L. (2011). Pattern separation in the hippocampus. Trends in Neuroscience, 34(10).
- Bastos, A.M. et al. (2012). Canonical microcircuits for predictive coding. Neuron, 76(4).
- Dudai, Y. (2012). The restless engram. Ann. Rev. Neuroscience, 35.
- De Pitta, M. et al. (2012). Computational quest for understanding astrocyte signaling. Front. Comp. Neuroscience, 6.
- Sutskever, I. et al. (2013). On the importance of initialization and momentum in deep learning. ICML.
- Kastellakis, G. et al. (2015). Synaptic clustering within dendrites. Prog. in Neurobiology, 126.
- Buzsaki, G. (2015). Hippocampal sharp wave-ripple. Hippocampus, 25(10).
- Kumaran, D. et al. (2016). What learning systems do intelligent agents need? Neurosci. & Biobehav. Rev., 68.
- Gilboa, A. & Marlatte, H. (2017). Neurobiology of schemas. Trends in Cognitive Sciences, 21(8).
- Stachenfeld, K.L. et al. (2017). The hippocampus as a predictive map. Nature Neuroscience, 20.
- Nogueira, R. & Cho, K. (2019). Passage re-ranking with BERT. arXiv:1901.04085.
- Josselyn, S.A. & Tonegawa, S. (2020). Memory engrams. Science, 367(6473).
- Wang, C. et al. (2020). Microglia mediate forgetting via complement-dependent synaptic elimination. Science, 367(6478).
- Ramsauer, H. et al. (2021). Hopfield networks is all you need. ICLR.
- Bruch, S. et al. (2023). An analysis of fusion functions for hybrid retrieval. ACM TOIS, 42(1).
- Wang, X. & Bhatt, S. (2024). Emotional modulation of memory. Psychological Review.
- Maharana, A. et al. (2024). LoCoMo: Long context conversational memory. ACL.
- Behrouz, A. et al. (2025). Titans: Learning to memorize at test time. arXiv:2501.00663.
- Joren, D. et al. (2025). Sufficient context. ICLR.
- Kosowski, A. et al. (2025). Dragon Hatchling: Memory management system. arXiv.
- Wang, Y. et al. (2025). LongMemEval. ICLR.
- Tavakoli, M. et al. (2026). BEAM: Beyond a million tokens. ICLR.
License
MIT
Citation
@software{cortex2026,
title={Cortex: Scientifically-Grounded Memory System Based on Computational Neuroscience},
author={Deust, Clement},
year={2026},
url={https://github.com/cdeust/Cortex}
}
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found