Your-First-LLM-Studio
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 20 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
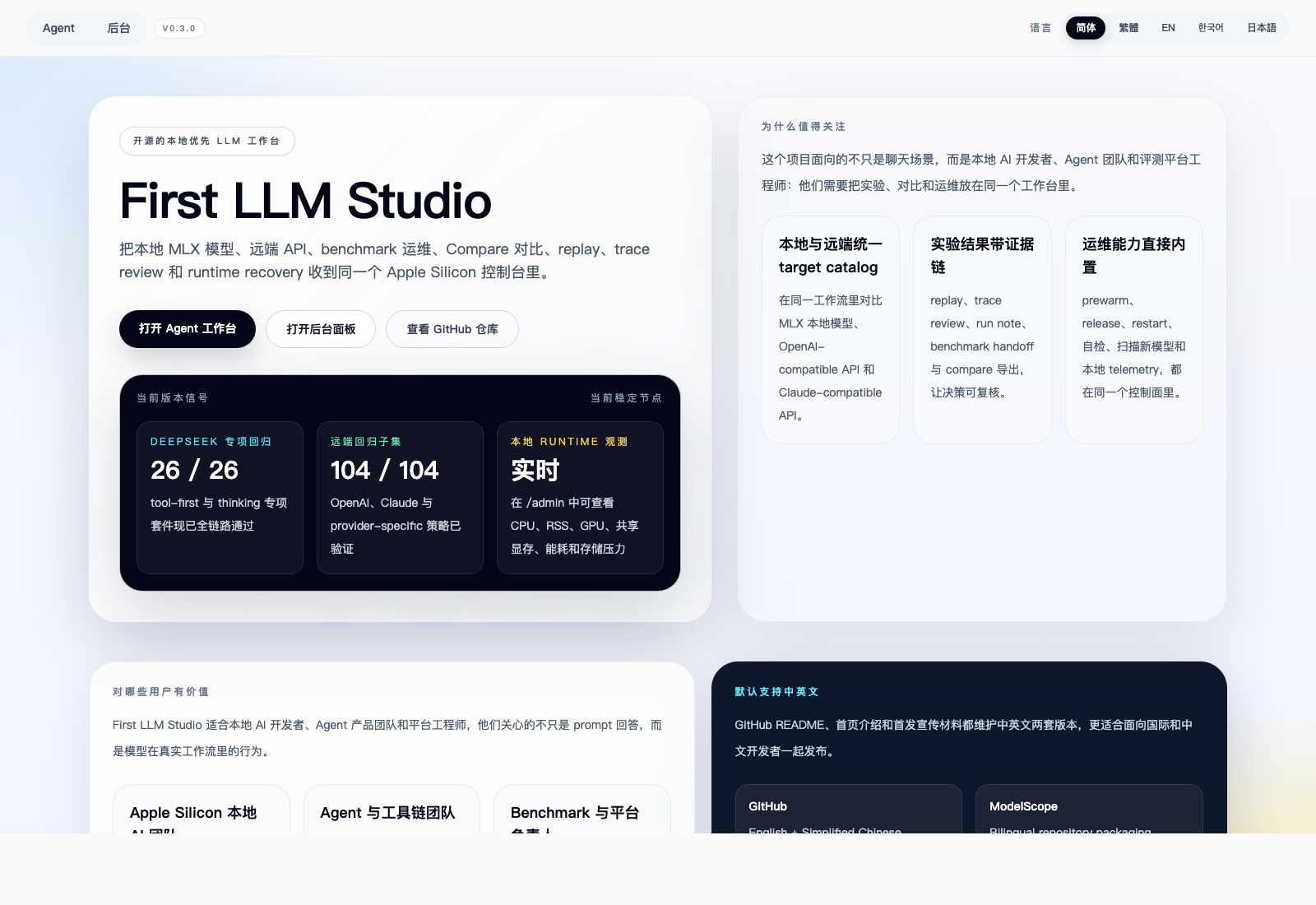
First LLM Studio: local-first LLM studio for Apple Silicon with MLX runtimes, Compare Lab, benchmark ops, replay, and runtime telemetry.
First LLM Studio



English
First LLM Studio is a local-first LLM workbench for Apple Silicon. It brings local MLX runtimes, remote API targets, Agent sessions, Compare, Fine-tune, Benchmark, model discovery, runtime recovery, release evidence, and admin monitoring into one operating surface.
It is not another chat shell. It is built for people who need to compare behavior, debug runtimes, run evals, prepare adapters, and keep local and remote model work inside one product loop.
Product Surfaces
| Route | Core workflow |
|---|---|
/agent |
Tool-enabled Agent sessions, target selection, runtime state, replay, trace review, and embedded Compare entry. |
/compare |
Route-owned Compare Studio for prompt composition, lane preview, recipe persistence, review drawer, and benchmark handoff. |
/fine-tune |
Foreground Fine-tune Studio for datasets, recipes, training, evaluation, chat adapter proof loops, export, reports, and artifacts. |
/models |
Model discovery and install verification for local/community models plus hardware-fit and risk signals. |
/benchmarks |
Benchmark run controls, progress, reports, release evidence, baselines, and regression review. |
/retrieval |
Foreground knowledge management, path import, chunk inspection, and grounded retrieval validation. |
/experiments |
Unified run/session timeline with artifact lineage, cross-feature navigation, filters, and retention controls. |
/admin |
Monitoring/configuration mirror for runtime, queues, benchmark history, provider health, guardrails, and audit timelines. |
Major Version Story
| Version | Core capabilities |
|---|---|
v0.1 Foundation |
Established the local-first web studio, Apple Silicon/MLX gateway workflow, local + remote target catalog, runtime telemetry, and the first Agent/Admin operating split. |
v0.2 Agent + Benchmark Ops |
Added richer Agent workbench flows, Compare-style target review, replay/trace inspection, runtime recovery controls, formal benchmark operations, baselines, and regression evidence. |
v0.3 Fine-tune + Release Evidence |
Added fine-tune operation loops for evaluation, adapter chat, adapter export, and distillation starters; expanded operation history, partitioned typechecks, screenshot smoke, route smoke, and public launch assets. |
v0.4 Product IA release |
Moves /fine-tune, /compare, /models, /benchmarks, /retrieval, and /experiments into foreground product routes with feature-owned state/actions, artifact lineage and retention, dark-glass studio/workbench styling, canonical APIs, and admin narrowed toward monitoring/configuration. |
Current release: VERSION.
Who It Helps
Local AI builders on Apple Silicon
- Compare MLX local models against hosted APIs under aligned context budgets.
- Inspect runtime cost, prewarm, release, recovery, and hardware pressure without leaving the app.
- Decide which local model is actually usable for daily coding and analysis workflows.
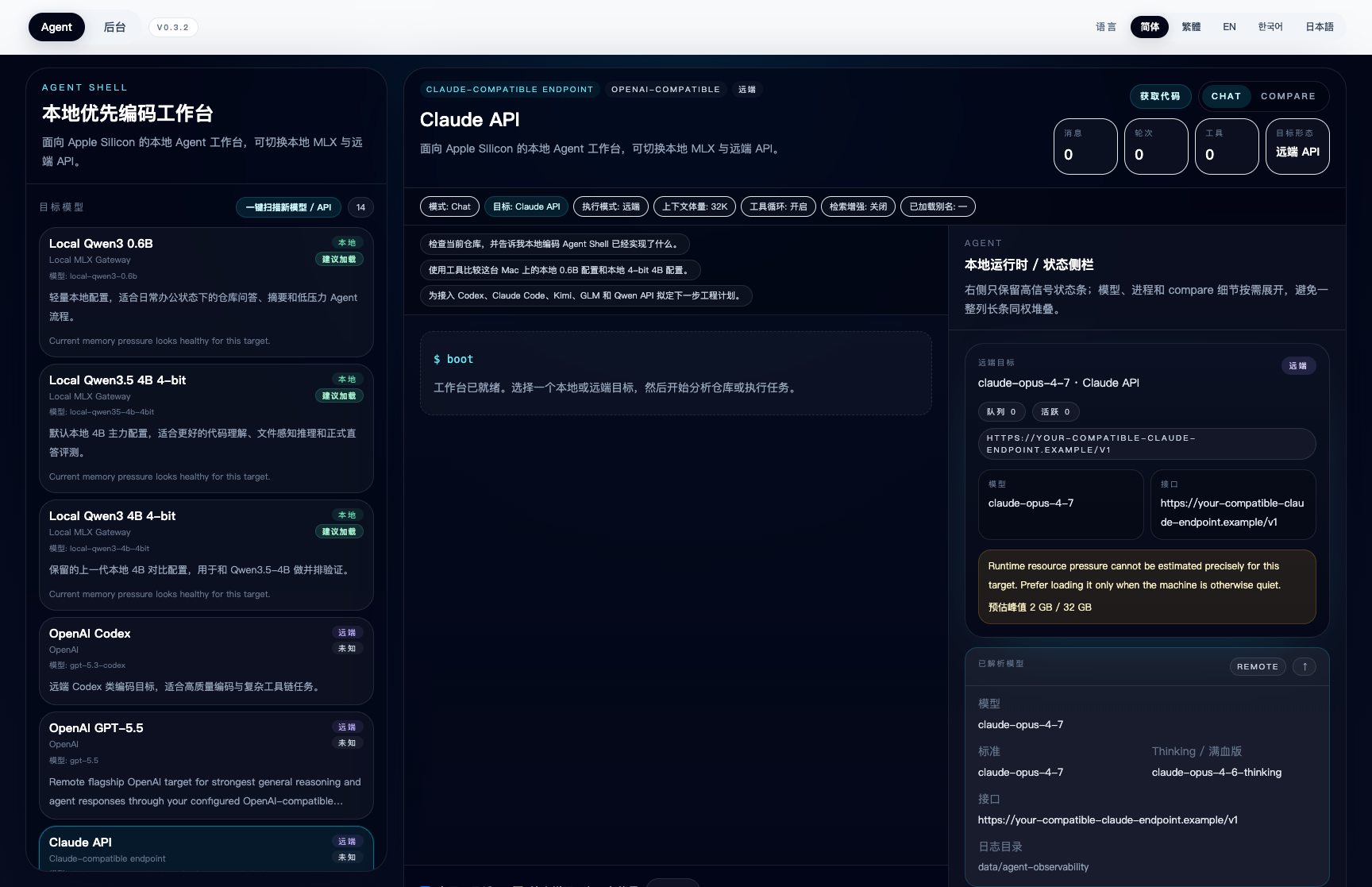
Agent and tooling teams
- Validate tool-calling, repo-grounded behavior, replay, and patch flows in one workbench.
- Turn Compare runs into benchmark handoff without switching products.
- Separate model-quality failures from provider quirks and local runtime instability.
Evaluation and platform engineers
- Run formal and focused benchmark suites with repeatable profiles.
- Review baselines, deltas, run notes, failure classifications, and release evidence.
- Keep local and remote targets inside one comparable target catalog.
Core Value
- Unified local + remote target catalog.
- Compare Lab for model-vs-model output review.
- Fine-tune workflows for datasets, recipes, training, evaluation, adapter proof loops, and export.
- Benchmark operations with history, progress, baselines, reports, and release evidence.
- Foreground Retrieval for document import, chunk inspection, and grounded evidence probes.
- Experiments timeline for session/run lineage, artifact navigation, and retention policy.
- Replay, trace review, patch inspection, and exportable review notes.
- Runtime operations for prewarm, release, restart, log inspection, telemetry, and recovery.
- Dynamic local/community model discovery plus remote provider health scanning.
Current Targets
Local
Local Qwen3 0.6BLocal Qwen3 4B 4-bitLocal Qwen3.5 4B 4-bitLocal Gemma 3 4B It Qat 4-bit
Remote
OpenAI CodexOpenAI GPT-5.5Claude APIDeepSeek APIKimi APIGLM APIQwen API
Screenshots
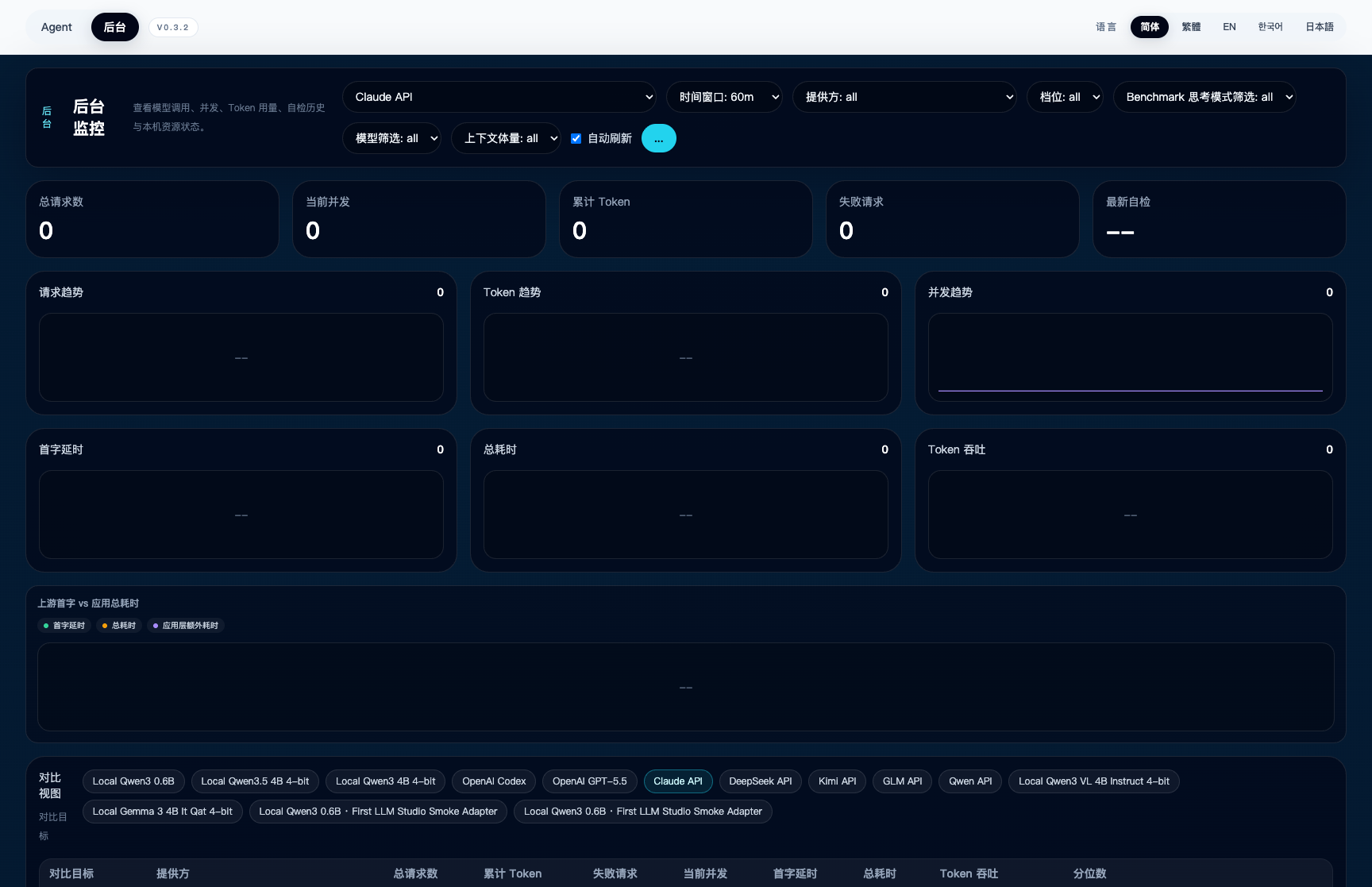
Benchmark percentile board:

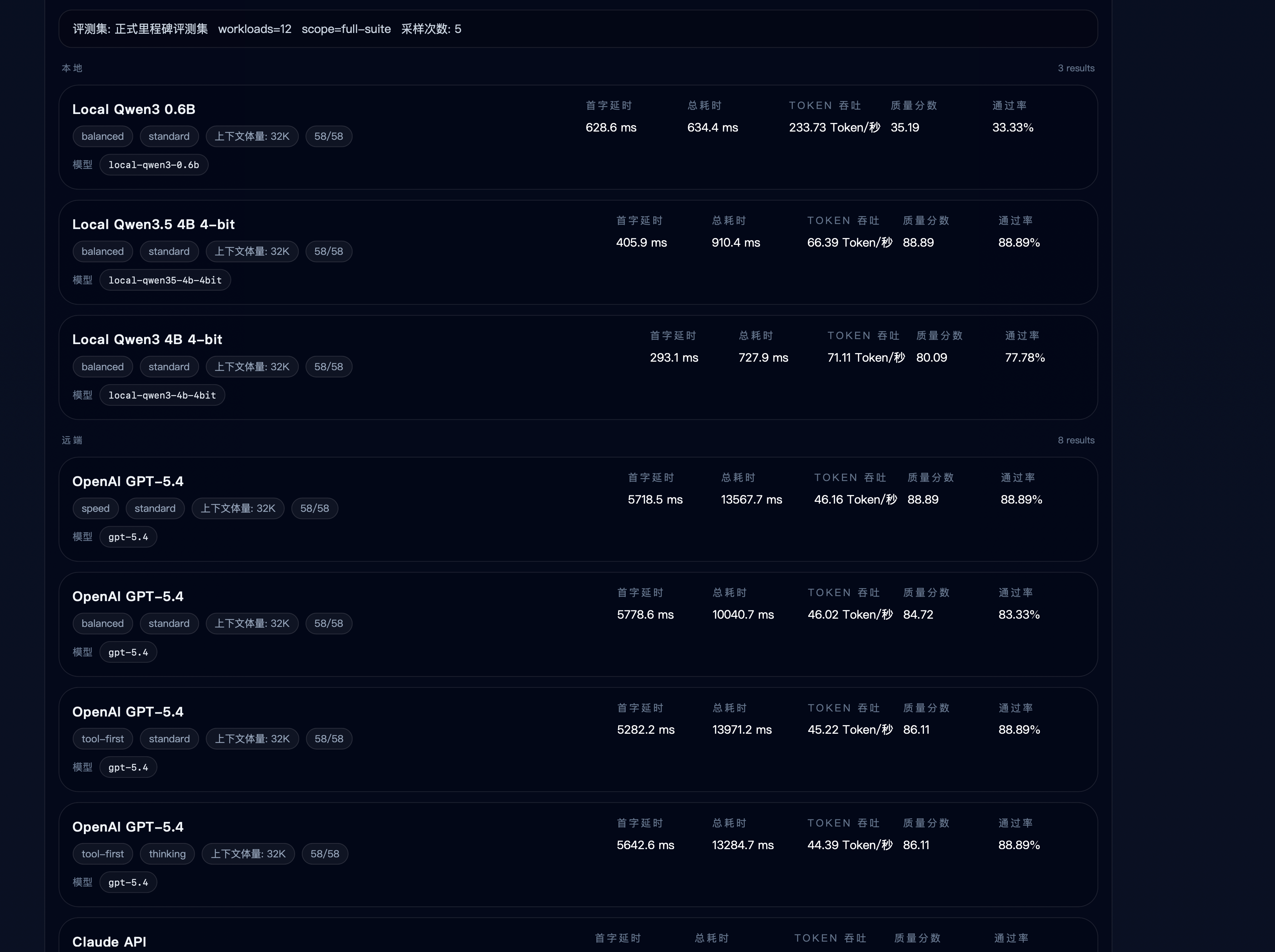
Formal milestone regression summary:
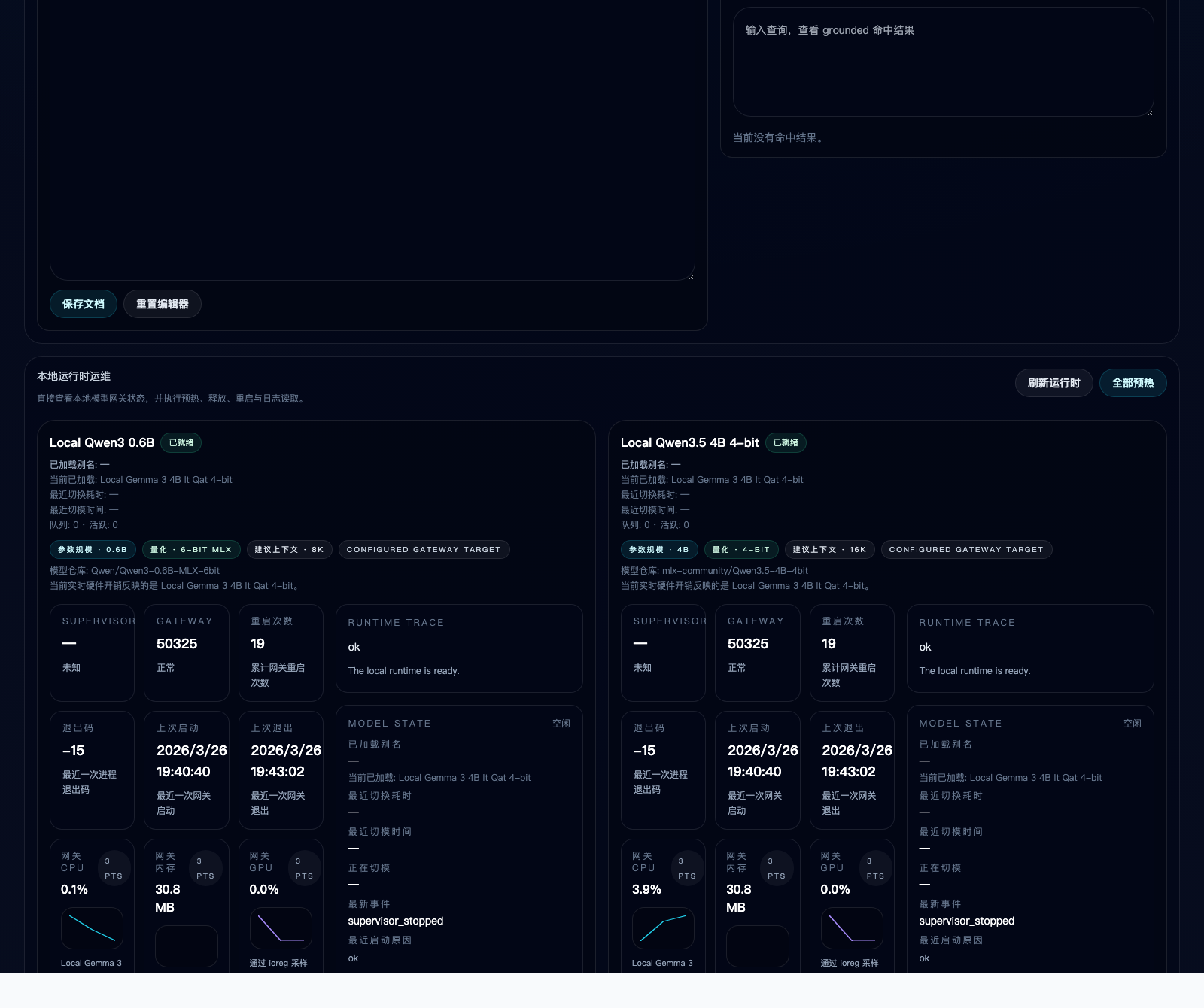
Local runtime telemetry:
Quick Start
Requirements
- macOS on Apple Silicon
- Node
22.x - Python
3.12 - MLX-compatible local environment
Install
nvm install 22
nvm use 22
npm install
cp .env.example .env.local
Start the web app
npm run dev
Default routes:
- http://localhost:3011/agent
- http://localhost:3011/compare
- http://localhost:3011/fine-tune
- http://localhost:3011/models
- http://localhost:3011/benchmarks
- http://localhost:3011/retrieval
- http://localhost:3011/experiments
- http://localhost:3011/admin
Start the local model gateway
python3.12 -m venv .venv
source .venv/bin/activate
pip install -U pip
pip install mlx mlx-lm
python scripts/local_model_gateway_supervisor.py
Gateway health:
Verification
npm run typecheck:changed
npm run smoke:routes
npm run smoke:screenshots
Configuration
Copy .env.example to .env.local and fill only the providers you want to use.
Important notes:
.env.localis ignored by git.- Remote providers are optional.
- Several targets use OpenAI-compatible or Claude-compatible endpoints.
- Public defaults in this repository are sanitized placeholders.
Repository Structure
app/ Next.js app routes and thin API transports
components/ Shared UI and compatibility shells
features/ Feature-owned routes, contracts, state, actions, and application ports
lib/agent/ Agent runtime, providers, benchmark, gateway helpers
lib/finetune/ Fine-tune store facade and split operation services
scripts/ Local gateway, runtime, verification, and release scripts
docs/ Architecture, release notes, launch notes, roadmap, and assets
modelscope/ ModelScope profile/readme metadata
public/ Public assets and social cover art
Distribution
- GitHub: https://github.com/ChrisChen667788/local-agent-lab
- ModelScope profile: https://www.modelscope.cn/profile/haozi667788
- Default ModelScope repo id:
haozi667788/first-llm-studio
The ModelScope package script exports the committed Git tree so GitHub and ModelScope can stay file-identical for each synced version.
Security and Privacy
- Sensitive local actions require confirmation.
- Secrets belong in
.env.local. - Public repository defaults are sanitized.
- New public commits should use a GitHub noreply address where possible.
- See SECURITY.md.
Contributing
Issues and PRs are welcome.
Release Notes
- Current version:
VERSION - Release notes:
docs/releases - Release process:
docs/release-process.md - Latest release note: v0.4.0
简体中文
First LLM Studio 是一个面向 Apple Silicon 的本地优先 LLM 工作台。它把本地 MLX 运行时、远端 API 目标、Agent 会话、Compare 对比、Fine-tune 微调、Benchmark 评测、模型发现、runtime 恢复、发布证据和后台监控统一到一个产品界面里。
它不是另一个聊天壳,而是给真正需要比较模型行为、调试 runtime、跑评测、准备 adapter,并把本地/远端模型工作流收在同一个产品循环里的开发者使用。
产品入口
| 路由 | 核心工作流 |
|---|---|
/agent |
带工具循环的 Agent 会话、target 选择、runtime 状态、replay、trace review,以及内嵌 Compare 入口。 |
/compare |
前台 Compare Studio,负责 prompt 编排、lane preview、recipe 持久化、review drawer 和 benchmark handoff。 |
/fine-tune |
前台 Fine-tune Studio,覆盖数据集、配方、训练、评估、adapter proof loop、导出、报告和 artifacts。 |
/models |
本地/社区模型发现、安装验证、硬件适配和风险提示。 |
/benchmarks |
Benchmark run controls、进度、报告、发布证据、baseline 和回归审阅。 |
/retrieval |
前台知识管理、路径导入、chunk 检查和 grounded retrieval 验证。 |
/experiments |
统一 Session/Run 时间线、artifact lineage、跨功能导航、筛选和保留策略。 |
/admin |
Runtime、队列、benchmark 历史、provider health、guardrails 和 audit timeline 的监控/配置镜像。 |
大版本核心功能
| 版本 | 核心功能 |
|---|---|
v0.1 基础版 |
建立本地优先 Web Studio、Apple Silicon/MLX 网关工作流、本地 + 远端 target catalog、runtime telemetry,以及 Agent/Admin 的第一版操作分层。 |
v0.2 Agent + Benchmark 运维 |
增强 Agent 工作台、Compare 式 target review、replay/trace 检查、runtime recovery controls、正式 benchmark 运维、baseline 和回归证据。 |
v0.3 Fine-tune + 发布证据 |
加入 evaluation、adapter chat、adapter export、distillation starter 等 fine-tune 操作循环;扩展 operation history、分区 typecheck、截图 smoke、route smoke 和公开发布素材。 |
v0.4 产品结构发布版 |
把 /fine-tune、/compare、/models、/benchmarks、/retrieval、/experiments 推进为前台产品路由;迁移 feature-owned state/actions;接通 artifact lineage、导航和 retention;统一 dark-glass studio/workbench 视觉;使用 canonical API;Admin 收口为监控/配置。 |
当前发布版本见 VERSION。
对哪些用户有价值
Apple Silicon 本地 AI 开发者
- 在统一上下文预算下,对比 MLX 本地模型和托管 API。
- 不离开应用就能查看 runtime 成本、prewarm、release、恢复动作和硬件压力。
- 判断哪个本地模型真的适合日常 coding / analysis 工作流。
Agent / 工具链团队
- 在一个工作台里验证 tool calling、repo-grounded behavior、replay 和 patch 流程。
- 直接把 Compare 结果送入 Benchmark,不必切换产品。
- 区分失败来源:模型质量、provider 行为,还是本地 runtime 不稳。
评测 / 平台工程团队
- 用可复现 profile 跑 formal 和 focused benchmark suites。
- 查看 baseline、delta、run note、失败分类和发布证据。
- 让本地与远端 target 落在同一个可比较的 target catalog 里。
核心价值
- 本地 + 远端统一 target catalog。
- Compare Lab 支持模型对模型审阅。
- Fine-tune 工作流覆盖 dataset、recipe、training、evaluation、adapter proof loop 和 export。
- Benchmark 运维覆盖 history、progress、baseline、report 和 release evidence。
- Retrieval 前台覆盖文档导入、chunk 检查和 grounded evidence probe。
- Experiments 时间线覆盖 Session/Run lineage、artifact 导航和 retention policy。
- Replay、trace review、patch inspection 与可导出的审阅记录。
- Runtime 运维覆盖 prewarm、release、restart、日志检查、telemetry 和 recovery。
- 支持本地/社区模型发现和远端 provider health 扫描。
当前支持的 Target
本地
Local Qwen3 0.6BLocal Qwen3 4B 4-bitLocal Qwen3.5 4B 4-bitLocal Gemma 3 4B It Qat 4-bit
远端
OpenAI CodexOpenAI GPT-5.5Claude APIDeepSeek APIKimi APIGLM APIQwen API
截图
Benchmark 百分位看板:
正式里程碑回归汇总:
本地 runtime 实时监控:
快速开始
环境要求
- Apple Silicon macOS
- Node
22.x - Python
3.12 - 可运行 MLX 的本地环境
安装
nvm install 22
nvm use 22
npm install
cp .env.example .env.local
启动 Web 应用
npm run dev
默认入口:
- http://localhost:3011/agent
- http://localhost:3011/compare
- http://localhost:3011/fine-tune
- http://localhost:3011/models
- http://localhost:3011/benchmarks
- http://localhost:3011/retrieval
- http://localhost:3011/experiments
- http://localhost:3011/admin
启动本地模型网关
python3.12 -m venv .venv
source .venv/bin/activate
pip install -U pip
pip install mlx mlx-lm
python scripts/local_model_gateway_supervisor.py
网关健康检查:
验证
npm run typecheck:changed
npm run smoke:routes
npm run smoke:screenshots
配置说明
把 .env.example 复制成 .env.local,只填写你要启用的 provider 即可。
需要注意:
.env.local已被 git 忽略。- 远端 provider 是可选的。
- 部分 target 走 OpenAI-compatible / Claude-compatible endpoint。
- 本仓库公开版本已经做过脱敏,占位值需要替换成你自己的 endpoint。
仓库结构
app/ Next.js app routes 与 thin API transports
components/ 共享 UI 与兼容 shell
features/ feature-owned routes、contracts、state、actions、application ports
lib/agent/ Agent runtime、providers、benchmark、gateway helpers
lib/finetune/ Fine-tune store facade 与拆分后的 operation services
scripts/ 本地网关、runtime、验证和发布脚本
docs/ 架构、release notes、launch notes、roadmap 和 assets
modelscope/ ModelScope 主页/readme 元数据
public/ 对外资源和社媒封面图
发布与同步
- GitHub: https://github.com/ChrisChen667788/local-agent-lab
- ModelScope profile: https://www.modelscope.cn/profile/haozi667788
- 默认 ModelScope repo id:
haozi667788/first-llm-studio
ModelScope 打包脚本会导出已提交的 Git tree,因此每次同步都可以让 GitHub 和 ModelScope 保持同一份文件快照。
安全和隐私
- 敏感本地操作默认需要确认。
- Secret 应保存在
.env.local。 - 公开仓库默认配置已经做过脱敏。
- 新增公开提交应尽量使用 GitHub noreply 地址。
- 见 SECURITY.md。
贡献
欢迎 issue 和 PR。
发布说明
- 当前版本:
VERSION - Release notes:
docs/releases - 发布流程:
docs/release-process.md - 最新版本说明:v0.4.0
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found