lossless-code
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
This MCP server provides DAG-based, lossless context management for Claude Code. It preserves every conversation message in a local SQLite database, enabling full recall and structured searches across multiple sessions.
Security Assessment
The overall risk is Low. A lightweight code scan of 12 files found no dangerous patterns, hardcoded secrets, or requests for dangerous permissions. The tool operates locally using SQLite with FTS5 for storage and retrieval, which inherently limits data exposure to your local machine. Since it is designed to capture your entire conversation history, the local database will naturally contain highly sensitive data depending on what you discuss with the AI. Developers should treat the local `vault.db` file as sensitive. No suspicious network requests or background shell executions were detected.
Quality Assessment
The project is very new and currently has low community visibility with only 5 GitHub stars. However, it is actively maintained, with the most recent push occurring today. The codebase is properly licensed under the permissive MIT license. Because it is an early-stage tool with minimal community vetting, you may encounter bugs or breaking changes, but the foundational repository health is solid.
Verdict
Safe to use, but keep in mind that it is an early-stage project with limited community testing.
DAG-based Lossless Context Management for Claude Code. Every message preserved, summaries cascade as a DAG, patterns extracted via Lossless Dream — full recall and reflection across sessions.
🧠 lossless-code
DAG-based Lossless Context Management for Claude Code.
Every message preserved forever. Summaries cascade, never delete. Full recall across sessions.
![]()




![]()
Getting Started · MCP Server · Commands · Dream · Terminal UI · How It Works · Configuration · Contributing
Claude Code forgets. claude-mem remembers fragments. lossless-code remembers everything.
Try it in 60 seconds
/plugin marketplace add GodsBoy/lossless-code
/plugin install lossless-code
That's it. Start a new session and search your history:
lcc_grep "database migration"
The Problem
Claude Code forgets everything between sessions. Memory tools like ClawMem, context-memory, and claude-mem use flat retrieval: keyword search over snippets, no structure, no hierarchy, no way to trace a summary back to its source conversation.
When a project spans weeks and hundreds of sessions, flat search fails. You get fragments without lineage.
What Makes lossless-code Different
lossless-code uses DAG-based lossless preservation, the same approach pioneered by lossless-claw for OpenClaw:
- Nothing is ever deleted. Every message stays in
vault.dbforever. - Summaries form a directed acyclic graph. Messages cascade to depth-0 summaries, which roll up to depth-1, depth-2, and beyond.
- Full drill-down.
lcc_expandtraces any summary back to the exact messages that created it. - Automatic. Claude Code hooks capture every turn and trigger summarisation transparently. Zero manual effort.
- Cross-session recall. Start a new session and your full project history is immediately searchable.
- Lossless Dream. Extracts recurring patterns (corrections, preferences, conventions) from vault history and injects them into future sessions — like Auto-Dream but without forgetting.
┌──────────────────┐
│ Claude Code │
│ Session │
└────────┬─────────┘
│
┌────────────────────────┼────────────────────────┐
│ │ │ │
┌─────▼─────┐ ┌──────▼──────┐ ┌──────▼──────┐ ┌────▼─────┐
│ Hooks │ │ Skills │ │ CLI │ │ MCP │
│ (write) │ │ (shell) │ │ Tools │ │ Server │
│ │ │ │ │ │ │ (stdio) │
│ SessionStart│ │ lcc_grep │ │ lcc_status │ │ │
│ Stop │ │ lcc_expand │ │ │ │ 6 tools │
│ PreCompact │ │ lcc_context │ │ │ │ read-only│
│ PostCompact│ │ lcc_sessions│ │ │ │ │
│ UserPrompt │ │ lcc_handoff │ │ │ │ │
└─────┬──────┘ └──────┬──────┘ └──────┬──────┘ └────┬─────┘
│ │ │ │
└──────────────────┼────────────────┼──────────────┘
│ │
┌────────▼────────────────▼──┐
│ vault.db │
│ (SQLite) │
│ │
│ messages summaries │
│ summary_sources sessions │
│ FTS5 indexes │
└──────────────────────────────┘
Comparison
| lossless-code | ClawMem | context-memory | claude-mem | |
|---|---|---|---|---|
| Storage | SQLite with FTS5 | SQLite + vector DB | Markdown files | SQLite + Chroma |
| Structure | DAG (summaries cascade) | Flat RAG retrieval | Flat retrieval | Flat retrieval |
| Drill-down | Full (summary to source messages) | None | None | None |
| Auto-capture | Hooks (zero manual effort) | Hooks + watcher | Manual | Hooks + worker |
| Cross-session | Yes (vault persists) | Yes | Yes | Yes |
| Summarisation | Cascading DAG (depth-N) | Single-level | None | Single-level |
| Search | FTS5 full-text | Hybrid (BM25 + vector + reranker) | Keyword | Hybrid (BM25 + vector) |
| MCP tools | 6 | 28 | 0 | 10+ |
| Background services | None | watcher + embed timer + GPU servers | None | Worker on port 37777 |
| Runtime | Python (stdlib) | Bun + llama.cpp (optional) | None | Bun |
| Models required | None (optional for summarisation) | 2GB+ GGUF (embed + reranker) | None | Chroma embeddings |
| Idle cost | Zero | CPU/RAM for services + embedding sweeps | Zero | Worker process |
Why lossless-code Costs Less
Memory tools that inject context on every prompt are silently expensive. Here's why lossless-code's design saves tokens:
1. On-demand recall, not automatic injection
ClawMem injects relevant memory into 90% of prompts automatically (their stated design). claude-mem injects a context index on every SessionStart. Both approaches front-load tokens whether or not the agent needs that context.
lossless-code injects nothing by default. Context surfaces only when the agent explicitly calls an MCP tool or the PreCompact hook fires. Most coding turns (writing code, running tests, reading files) don't need historical context at all. You pay for recall only when recall matters.
2. Fewer MCP tool definitions = fewer tokens per turn
Every MCP tool registered in ~/.claude.json has its schema injected into every single API call as available tools. Claude Code's own docs warn: "Prefer CLI tools when available... they don't add persistent tool definitions."
- ClawMem: 28 MCP tools (query, intent_search, find_causal_links, timeline, similar, etc.)
- claude-mem: 10+ search endpoints via worker service
- lossless-code: 6 MCP tools (grep, expand, context, sessions, handoff, status)
Over a 200-turn session, that difference in tool schema overhead compounds significantly.
3. No background embedding costs
ClawMem runs a watcher service (re-indexes on file changes) and an embed timer (daily embedding sweep across all collections). These require GGUF models (~2GB minimum) and consume CPU/GPU continuously. claude-mem runs a persistent worker service on port 37777.
lossless-code has zero background processes. Hooks fire only during Claude Code events. The vault is pure SQLite with FTS5 (built into SQLite, no external models). Nothing runs between sessions.
4. DAG summarisation reduces compaction waste
When Claude Code hits its context limit, it compacts: summarising earlier context to make room. With flat memory systems, compaction loses fidelity and the agent may re-explore territory it forgot, costing more tokens ("debugging in circles").
lossless-code's DAG captures the full conversation before compaction happens (PreCompact hook). After compaction, the PostCompact hook re-injects only the top-level summaries. The agent can drill down via lcc_expand if it needs detail, but the DAG ensures nothing is truly lost. This means:
- Fewer repeated explorations after compaction
- One long session is cheaper than multiple short sessions covering the same ground
- Context survives compaction without paying to re-read everything
5. No runtime dependencies
| Dependency | lossless-code | ClawMem | claude-mem |
|---|---|---|---|
| Python 3.10+ | Yes (usually pre-installed) | No | No |
| Bun | No | Required | Required |
| llama.cpp / GGUF models | No | Optional (2GB+) | No |
| Chroma / vector DB | No | No | Required |
| systemd services | No | Recommended | No |
mcp Python SDK |
Yes (pip install) | No (TypeScript) | No |
Fewer dependencies means less to maintain, fewer failure modes, and lower resource consumption.
Install
Option A: Claude Code Plugin (recommended)
/plugin marketplace add GodsBoy/lossless-code
/plugin install lossless-code
Hooks, MCP server, and skill are activated automatically. No manual setup needed.
Option B: Standalone Install
git clone https://github.com/GodsBoy/lossless-code.git
cd lossless-code
bash install.sh
The installer:
- Creates
~/.lossless-code/withvault.dband scripts - Configures Claude Code hooks in
~/.claude/settings.json - Installs the skill to
~/.claude/skills/lossless-code/ - Adds CLI tools to PATH
Idempotent: safe to run again to upgrade.
Requirements
- Python 3.10+
- SQLite 3.35+ (for FTS5)
- Claude Code CLI
Optional: anthropic Python package for AI-powered summarisation (falls back to extractive summaries without it).
MCP Server
lossless-code includes an MCP (Model Context Protocol) server so Claude Code can access the vault as native tools without shelling out to CLI commands.
Setup
The installer (install.sh) automatically:
- Copies the MCP server to
~/.lossless-code/mcp/server.py - Installs the
mcpPython SDK - Registers the server in
~/.claude.json
After installation, every new Claude Code session auto-discovers 6 MCP tools:
| Tool | Description |
|---|---|
lcc_grep |
Full-text search across messages and summaries |
lcc_expand |
Expand a summary back to source messages (DAG traversal) |
lcc_context |
Get relevant context for a query |
lcc_sessions |
List sessions with metadata |
lcc_handoff |
Generate session handoff documents |
lcc_status |
Vault statistics (sessions, messages, DAG depth, DB size) |
Manual Registration
If you need to register the MCP server manually:
// ~/.claude.json
{
"mcpServers": {
"lossless-code": {
"command": "python3",
"args": ["~/.lossless-code/mcp/server.py"]
}
}
}
Architecture
Claude Code ──stdio──▶ MCP Server ──read-only──▶ vault.db
(server.py)
6 tools
The MCP server is read-only. All writes to the vault happen through hooks (SessionStart, Stop, UserPromptSubmit, PreCompact, PostCompact). The MCP server imports db.py directly for SQLite access.
Commands
lcc_grep <query>
Full-text search across all messages and summaries.
lcc_grep "database migration"
lcc_grep "auth refactor"
lcc_expand <summary_id>
Expand a summary node back to its source messages.
lcc_expand sum_abc123def456
lcc_expand sum_abc123def456 --full
lcc_context [query]
Surface relevant DAG nodes for a query. Without a query, returns highest-depth summaries.
lcc_context "auth system"
lcc_context --limit 10
lcc_sessions
List recorded sessions with timestamps and handoff status.
lcc_sessions
lcc_sessions --limit 5
lcc_handoff
Show or generate a session handoff.
lcc_handoff
lcc_handoff --generate --session "$CLAUDE_SESSION_ID"
lcc_status
Show vault statistics: message count, summary count, DAG depth, dream stats, and FTS index health.
lcc_status
lcc_dream
Run the dream cycle — extract patterns from vault history and consolidate the DAG.
lcc_dream --run # Dream for current working directory
lcc_dream --run --project /path # Dream for a specific project
lcc_dream --run --global # Cross-project dream
See Lossless Dream for details.
Terminal UI (lcc-tui)
lcc-tui is a terminal-based browser for your vault. Built with Textual.
lcc-tui
Views
| Tab | Key | Description |
|---|---|---|
| Sessions | 1 |
Browse all sessions; select to view messages |
| Search | 2 |
Full-text search across messages and summaries |
| Summaries | 3 |
Browse DAG summaries by depth; select to expand |
| Stats | 4 |
Dashboard: sessions, messages, summaries, vault size |
Navigation
1to4: switch tabs/: open search modal from any viewEnter: drill into selected session or summaryEsc: go backq: quit
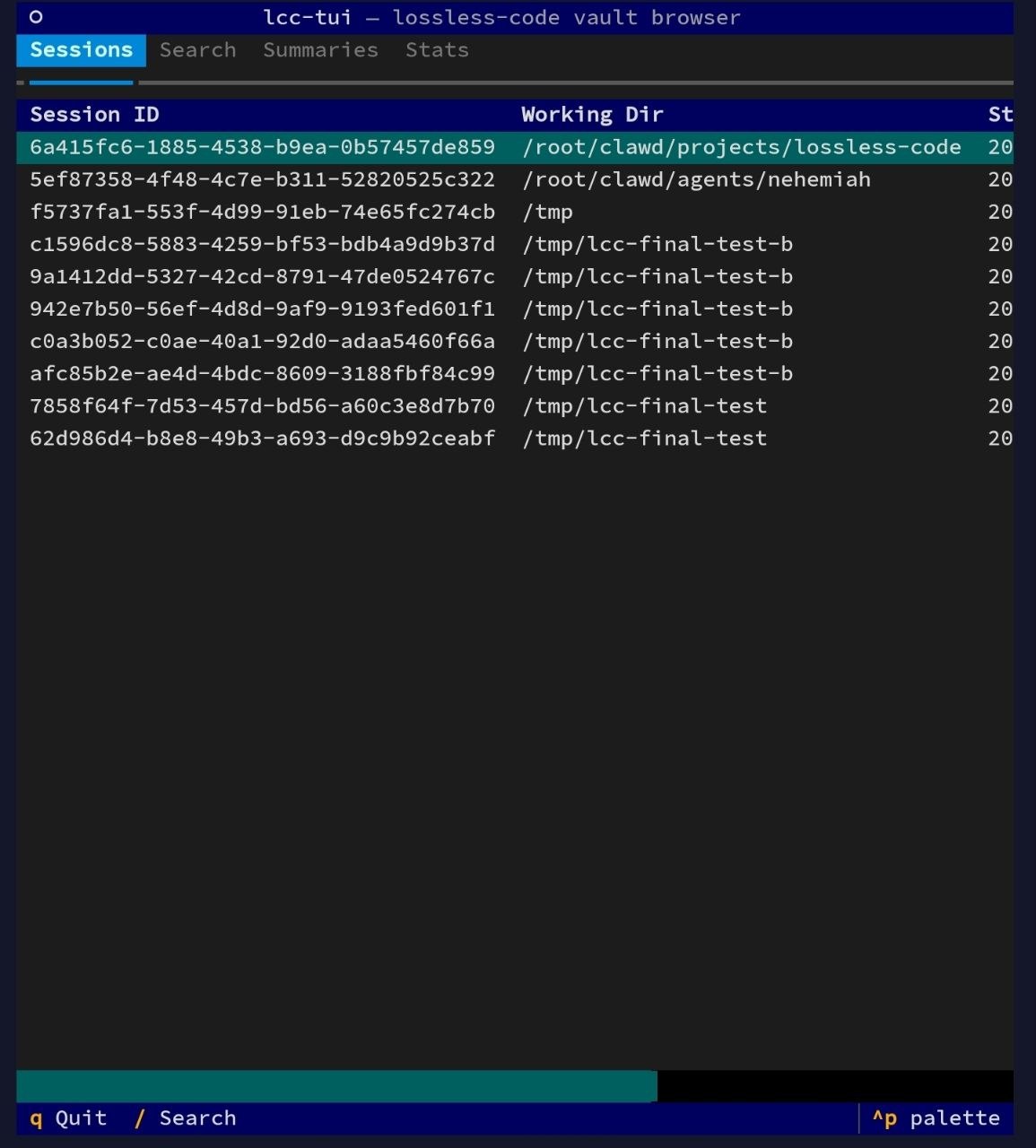
Full reference: docs/tui.md
How It Works
Hooks (Automatic)
| Hook | Event | Purpose |
|---|---|---|
session_start.sh |
SessionStart | Register session, inject handoff + summaries |
stop.sh |
Stop | Persist each turn to vault.db; trigger auto-dream if conditions met |
user_prompt_submit.sh |
UserPromptSubmit | Surface relevant context for the prompt |
pre_compact.sh |
PreCompact | Run DAG summarisation before compaction |
post_compact.sh |
PostCompact | Record compaction, re-inject top summaries |
DAG Summarisation
- Collect unsummarised messages, chunk into groups of ~20
- Summarise each chunk (via Claude API or extractive fallback)
- Write summary nodes to
summariestable (depth=0) - Link to sources in
summary_sources - Mark source messages as summarised
- If depth-N exceeds threshold: cascade to depth-N+1
- Repeat until under threshold at every depth
Lossless Dream
Dream is the intelligence layer on top of the DAG. It analyzes vault history to extract recurring patterns and consolidate redundant summaries — all without deleting anything.
Three-phase cycle:
- Pattern extraction — Queries messages and summaries since the last dream, chunks them, and sends each chunk to the LLM. Extracts patterns in 5 categories: corrections, preferences, anti-patterns, conventions, decisions. Falls back to keyword heuristics when no LLM API is available.
- DAG consolidation — Finds summaries with overlapping sources (>50% shared), merges them into tighter nodes via LLM, marks originals as
consolidated=1. Nothing is deleted. - Report generation — Writes a timestamped report and updates the dream log for idempotent reruns.
Auto-trigger: Dream runs automatically from the stop.sh hook when configurable conditions are met (default: 5+ sessions or 24+ hours since last dream). Runs as a background process with file-based locking to prevent concurrent races.
Context injection: On SessionStart, per-project and global dream patterns are injected alongside existing handoff and summaries, within a configurable token budget (default 2000 tokens).
Lineage: Every pattern in patterns.md includes source reference IDs. Use lcc_expand to trace any pattern back to the original conversation.
# Run dream manually
lcc dream --run
# Dream for a specific project
lcc dream --run --project /path/to/project
# Cross-project dream
lcc dream --run --global
Semantic Search (v1.1.0+)
Hybrid FTS5 + vector search, activated optionally. Default is FTS5-only — install nothing and the plugin behaves exactly as before.
Enable semantic search:
# Install the optional embedding dependency
pip install fastembed
# Turn it on in ~/.lossless-code/config.json
{"embeddingEnabled": true}
# Index your existing vault (one-time backfill)
lcc reindex --embeddings
How it works: New messages are embedded in the background after each session (same non-blocking pattern as dream auto-trigger). Queries combine FTS5 keyword results with vector cosine similarity using Reciprocal Rank Fusion (k=60). When hybrid search is active, lcc grep shows a [hybrid] tag on results.
Provider tiers:
fastembed(default local): ONNX-based, no PyTorch, ~200 MB install. Default model:BAAI/bge-small-en-v1.5openai/anthropic: API-based, higher quality. SetembeddingProviderin config and export the API key- Fallback: pure-Python numpy cosine similarity (no extra install, works for smaller vaults)
- Always: FTS5-only if no provider installed
Config keys (all optional, flat in ~/.lossless-code/config.json):
| Key | Default | Description |
|---|---|---|
embeddingEnabled |
false |
Master switch |
embeddingProvider |
"local" |
"local", "openai", "anthropic" |
embeddingModel |
"BAAI/bge-small-en-v1.5" |
Model name passed to provider |
ftsWeight |
1.0 |
RRF weight for FTS5 results |
vectorWeight |
1.0 |
RRF weight for vector results |
Switching models: Change embeddingModel and run lcc reindex --embeddings --force to re-embed with the new model.
Check status:
lcc status # shows "Vector search: active (fastembed, BAAI/bge-small-en-v1.5)"
# "Embeddings: 4,231 / 4,400 messages indexed (169 pending)"
Storage
~/.lossless-code/
vault.db # SQLite: all messages, summaries, DAG, sessions, dream_log
config.json # Settings (summary model, thresholds, dream config)
scripts/ # Python modules and CLI tools
hooks/ # Shell scripts called by Claude Code hooks
dream/ # Dream output
reports/ # Timestamped dream reports
projects/ # Per-project pattern files (keyed by working dir hash)
global/ # Cross-project pattern files
dream.log # Dream cycle log (for debugging background execution)
Configuration
~/.lossless-code/config.json:
{
"summaryModel": "claude-haiku-4-5-20251001",
"summaryProvider": "anthropic",
"anthropicBaseUrl": null,
"chunkSize": 20,
"depthThreshold": 10,
"incrementalMaxDepth": -1,
"workingDirFilter": null,
"autoDream": true,
"dreamAfterSessions": 5,
"dreamAfterHours": 24,
"dreamModel": "claude-haiku-4-5-20251001",
"dreamTokenBudget": 2000,
"contextTokenBudget": 8000
}
| Key | Default | Description |
|---|---|---|
summaryModel |
claude-haiku-4-5-20251001 |
Model for compactions |
summaryProvider |
anthropic |
LLM provider: anthropic or openai |
anthropicBaseUrl |
null |
Custom Anthropic-compatible API endpoint (overrides ANTHROPIC_BASE_URL env) |
chunkSize |
20 |
Messages per compaction chunk |
depthThreshold |
10 |
Max nodes at any depth before cascading |
incrementalMaxDepth |
-1 |
Max cascade depth (-1 = unlimited) |
workingDirFilter |
null |
Only capture messages from this directory |
autoDream |
true |
Enable automatic dream trigger from stop hook |
dreamAfterSessions |
5 |
Sessions since last dream before auto-trigger |
dreamAfterHours |
24 |
Hours since last dream before auto-trigger |
dreamModel |
claude-haiku-4-5-20251001 |
Model for dream pattern extraction |
dreamTokenBudget |
2000 |
Max tokens for dream pattern injection on SessionStart |
contextTokenBudget |
8000 |
Max tokens for total context injection on SessionStart (summaries + handoff + dreams) |
Compaction Configuration
lossless-code supports multiple LLM providers for compactions. Configure your provider in ~/.lossless-code/config.json:
{
"summaryModel": "gpt-4.1-mini",
"summaryProvider": "openai",
"chunkSize": 20,
"depthThreshold": 10
}
Supported Providers
Anthropic (default)
Authentication is resolved automatically from multiple sources (in priority order):
ANTHROPIC_API_KEYenvironment variable (standard API key)- Claude Code OAuth token from
~/.claude/.credentials.json(setup-token) CLAUDE_CODE_OAUTH_TOKENenvironment variable
Note: OAuth/setup-tokens require
ANTHROPIC_BASE_URLpointing to a compatible proxy (e.g. OpenClaw), sinceapi.anthropic.comdoes not accept OAuth tokens directly. If you only have a setup-token and no proxy, use the OpenAI provider instead.
{ "summaryProvider": "anthropic", "summaryModel": "claude-haiku-4-5-20251001" }
Model examples: claude-haiku-4-5-20251001, claude-sonnet-4-20250514
OpenAI
Set OPENAI_API_KEY in your environment.
{ "summaryProvider": "openai", "summaryModel": "gpt-4.1-mini" }
Model examples: gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini
You can use any model your provider supports. These are just common choices.
Custom Anthropic-compatible endpoints
Any provider that exposes an Anthropic Messages API endpoint works (e.g. MiniMax, Cloudflare AI Gateway, custom proxies). Set anthropicBaseUrl in config (or ANTHROPIC_BASE_URL env var) and provide the provider's API key via ANTHROPIC_API_KEY.
{
"summaryProvider": "anthropic",
"summaryModel": "MiniMax-M2.7",
"anthropicBaseUrl": "https://api.minimax.io/anthropic"
}
export ANTHROPIC_API_KEY="your-minimax-api-key"
Reasoning models that return ThinkingBlock responses are handled automatically.
Model examples: MiniMax-M2.7, MiniMax-M2.7-highspeed
Cost Comparison
| Model | Input cost (per 1M tokens) |
|---|---|
gpt-4.1-nano |
~$0.10 |
gpt-4o-mini |
~$0.15 |
MiniMax-M2.7 |
~$0.30 |
gpt-4.1-mini |
~$0.40 |
claude-haiku-4-5-20251001 |
~$0.80 |
claude-sonnet-4-20250514 |
~$3.00 |
Estimated Monthly Costs
For typical compaction workloads using gpt-4.1-mini:
| Usage | Estimated cost |
|---|---|
| Light (1-2 sessions/day) | $1-3/month |
| Moderate (3-5 sessions/day) | $3-7/month |
| Heavy (10+ sessions/day) | $7-15/month |
Compactions are triggered automatically before context compaction (PreCompact hook) and at session end (Stop hook). The extractive fallback runs automatically when no API key is configured: no hard dependency on any LLM provider.
CLI Usage
The lcc CLI provides direct access to vault operations.
# Run compaction manually
lcc summarise --run
# Run compaction for a specific session
lcc summarise --run --session <session-id>
# Check vault status
lcc status
# Search all messages and summaries
lcc grep "auth refactor"
# Show handoff from last session
lcc handoff
# Generate and save a handoff for current session
lcc handoff --generate --session "$CLAUDE_SESSION_ID"
# List recent sessions
lcc sessions
# Expand a summary node
lcc expand sum_abc123def456
# Run dream cycle
lcc dream --run
# Dream for a specific project directory
lcc dream --run --project /path/to/project
Schema
sessions -- session_id, working_dir, started_at, last_active, handoff_text
messages -- id, session_id, turn_id, role, content, tool_name, working_dir, timestamp, summarised
summaries -- id, session_id, content, depth, token_count, created_at, consolidated
summary_sources -- summary_id, source_type, source_id
dream_log -- id, project_hash, scope, dreamed_at, patterns_found, consolidations, sessions_analyzed, report_path
messages_fts -- FTS5 index on messages.content
summaries_fts -- FTS5 index on summaries.content
Uninstall
rm -rf ~/.lossless-code
# Remove hooks from ~/.claude/settings.json manually
# Remove skill: rm -rf ~/.claude/skills/lossless-code
Prior Art and Acknowledgements
lossless-code is a Claude Code adaptation of the Lossless Context Management (LCM) architecture created by Jeff Lehman and the Martian Engineering team. Their lossless-claw plugin for OpenClaw proved that DAG-based context preservation eliminates the information loss problem in long-running AI sessions. lossless-code brings that same architecture to Claude Code.
Additional references:
- ClawMem by yoloshii (hooks architecture patterns)
- Voltropy LCM paper (theoretical foundation)
Contributing
Contributions are welcome! Please:
- Fork the repository
- Create a feature branch (
git checkout -b feat/your-feature) - Write tests for new functionality
- Ensure tests pass
- Open a pull request
Roadmap
lossless-code currently supports Claude Code natively. The hook and plugin ecosystem across coding agents is converging fast, and we're tracking compatibility:
| Agent | Hook Support | MCP | Status | Notes |
|---|---|---|---|---|
| Claude Code | 20+ lifecycle events | ✅ | ✅ Supported | Full plugin with hooks, MCP, skills |
| Copilot CLI | Claude Code format | ✅ | 🟢 Next | Reads hooks.json natively; lowest adaptation effort |
| Codex CLI | SessionStart, Stop, UserPromptSubmit | ✅ | 🟡 Planned | Experimental hooks engine (v0.114.0+); MCP works today |
| Gemini CLI | BeforeTool, AfterTool, lifecycle | ✅ | 🟡 Planned | Different event names; needs thin adapter layer |
| OpenCode | session.compacting + plugin hooks | ✅ | 🔵 Researching | Plugin architecture differs; compacting hook maps to PreCompact |
MCP works everywhere today. Any agent that supports MCP servers can already use
lcc_grep,lcc_expand,lcc_context,lcc_sessions,lcc_handoff, andlcc_statusfor manual recall. The roadmap above tracks automatic capture via hooks.
Contributions welcome for any of the planned integrations.
Star History
Contributors

Licence
MIT
If lossless-code helps your workflow, consider giving it a ⭐
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found