Box
Health Pass
- License — License: NOASSERTION
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 482 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Private on-device AI suite for Android. Fork of Google AI Edge Gallery with llama.cpp, whisper.cpp, stable-diffusion.cpp, GGUF import, voice chat, vision AI, on-device image generation, biometric lock, encrypted history, and CPU/NPU/GPU acceleration.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

If this project helped you, please ⭐️ star it to help others find it.
📱 Download
Note: If you're using a custom ROM (LineageOS, GrapheneOS, CalyxOS), download the
custom-rom-supportAPK from the latest release instead.
Install via Obtainium
- Open Obtainium on your phone
- Tap the + button
- Paste this repo URL:
https://github.com/jegly/Box - Tap Add
Recommended for most users: Main version
Which version should I install?
| Version | For |
|---|---|
| Main | Stock Android (Pixel, Samsung, etc.) |
| Custom ROM | GrapheneOS, LineageOS, CalyxOS — no Google services |
The in-app updater is also available in Settings
Setup steps
- Tap the badge for your version above — this opens Obtainium with the repo pre-filled
- Under APK filter regex, enter one of the following:
- Main:
Main - Custom ROM:
custom-rom-support
- Main:
- Tap Add — Obtainium will find the latest release and install it
- Future updates will be detected automatically
Note: The version number shown inside the app (1.0.15) reflects the
upstream Google AI Edge Gallery build number and is unrelated to the Box
release version. Box releases are tracked via GitHub tags (v1.0.11 etc).
Use Settings → Check for updates to see if a newer Box release is available.
Box is a security-hardened fork of Google AI Edge Gallery — with on-device image generation, voice mode (speech-to-speech AI chat), voice input, document analysis, vision AI, biometric lock, encrypted chat history, llama.cpp support, and GGUF model import.
[!IMPORTANT]
Disclaimer
Box is an independent community fork of Google AI Edge Gallery and is not affiliated with or endorsed by Google LLC. Google branding has been replaced throughout. All credit for the underlying platform goes to Google and the original contributors — this fork simply builds on top of their work.
Changelog v1.0.7 – v1.0.11
| Version | Feature | Details |
|---|---|---|
| v1.0.11 | MCP server support | The Agent tab can now connect to external Model Context Protocol servers (e.g. gitmcp.io/<owner>/<repo>) and give the model access to remote tools. Off by default — enable in Settings, add a server URL, accept the disclaimer. Every tool call fires a per-call permission dialog (Allow once / Always allow / Deny). Hard Offline Mode disables MCP. |
| v1.0.11 | "Agent Skills" renamed to "Agent" | Reflects the addition of MCP tools alongside the existing 20 built-in skills. Internal IDs unchanged. |
| v1.0.11 | Broader NPU init crash recovery (main) | Snapdragon 8 Elite / Vivo OriginOS users (e.g. iQOO 13) reporting hard crashes on NPU model open now fall back silently to GPU instead. Any catchable NPU init exception is recovered, not just TF_LITE_AUX. |
| v1.0.11 | Pixel 8/9 TPU label | Tensor G3 / G4 devices now show the TPU accelerator label alongside Pixel 10 (isPixelDevice() broadened from isPixel10()). |
| v1.0.11 | Smoother streaming render | BufferedFadingMarkdownText two-layer crossfade reduces markdown re-render jank during token streaming. |
| v1.0.11 | Chat scroll performance | snapshotFlow + derivedStateOf translated to Box's LazyColumn. Significantly fewer Compose recompositions per generated token. |
| v1.0.11 | ChatGPT-style chat layout | User and assistant messages both left-aligned, restoring Box's original look. |
| v1.0.11 | Downloaded-model tick icon | Once a model is on device, the model picker chip and Model Manager show a filled-circle tick instead of the download-arrow icon. |
| v1.0.11 | Gemma 4 model hashes refreshed | Gemma 4 E2B / E4B / E2B-Snapdragon entries updated to upstream's latest commits (6e5c4f1e… / 28299f30…). |
| v1.0.11 | R8 keep rule for tool calls | Release builds preserve @Tool method names on every ToolSet subclass — MCP and Agent skills now work in release APKs (was silently broken). |
| v1.0.11 | Upstream merged to 1.0.15 | Internal versionName bumped to match upstream gallery 1.0.15 (cherry-picked over multiple sessions; chat history, model schema, and other heavily-customised Box paths preserved). |
| v1.0.10 | Gemini Nano hub | 6 on-device ML Kit features powered by Gemini Nano on Pixel 9+ (via AICore, NPU/TPU-accelerated): Summarize, Proofread, Rewrite, Chat, Describe Image, and Speech-to-Text. First use triggers an automatic background download of Gemini Nano (~1–2 GB via AICore). |
| v1.0.10 | Nano Chat — multi-session | Persistent multi-turn chat with Gemini Nano. Sessions are stored in the existing encrypted SQLCipher database, auto-titled from the first message, and fully resumable. Sessions can be renamed or deleted. Long-press any bubble to copy. |
| v1.0.10 | Document attachment in Nano | Proofread and Rewrite now accept attached documents (PDF, TXT, MD) — content is read and passed to Gemini Nano as context. |
| v1.0.10 | Live camera in Describe Image | Gallery tab + Live Camera tab. Camera tab binds an ImageCapture use case — tap Capture to send the current frame to Nano for description. |
| v1.0.10 | Background Removal | New tool powered by ML Kit Subject Segmentation (main branch). One tap removes the background from any photo with a transparency-preserving PNG output. Includes a "Trim transparent edges" toggle. Save or share the result. |
| v1.0.10 | Catppuccin + Dracula themes | Three-way theme picker in Settings: System (Material You) / Catppuccin (14 accents) / Dracula (7 accents). Accent colour persists across restarts with no first-frame flicker. |
| v1.0.10 | Tap jacking protection toggle | New toggle in Settings (on by default) — filterTouchesWhenObscured blocks touch events when an overlay is detected, preventing tap-jacking attacks. |
| v1.0.10 | Accessibility data sensitivity toggle | New Settings toggle hides app content from untrusted accessibility services. Off by default (note: incompatible with TalkBack). |
| v1.0.10 | LaTeX in table cells | Inline math inside markdown table cells no longer wraps across multiple lines. Uses Compose InlineTextContent to embed math as a single placeholder inside Text(). |
| v1.0.10 | Import button simplified | Home screen import button label shortened to just "Import" (removed "GGUF · LiteRT" subtitle). |
| v1.0.10 | NPE crash fix | Fixed a null-pointer crash on startup and on Retry caused by a broken fallback comparator in groupTasksByCategory. |
| v1.0.9 | Document Q&A | New RAG pipeline: import PDFs and ask questions grounded in the document. Uses MiniLM embeddings (on-device, LiteRT) for chunk retrieval — model only sees the relevant passages. Every answer cites the source chunks it used. |
| v1.0.9 | Model picker in Document Q&A | Choose which downloaded LLM handles answering — defaults to first available, switchable mid-session. |
| v1.0.9 | Kokoro TTS (English) | Single Kokoro model (csukuangfj/kokoro-en-v0_19, ~346 MB) replaces broken individual-voice entries. Correct tensor shapes and metadata — works first time. |
| v1.0.9 | 13 Piper voices | 8 new voices: LibriTTS-R, HFC Female, HFC Male, Arctic (US English); Thorsten (German); UPMC (French); MLS 10246 (Spanish); Huayan (Chinese Mandarin). 13 total across both branches. |
| v1.0.9 | 10 Whisper models | Expanded from 3 hardcoded to 10: Tiny, Base, Small, Medium, Large-v3-Turbo, and Large-v3 — each in multilingual and English-only variants. Shared across Audio Scribe and Voice Input. |
| v1.0.9 | Gemma-4-E2B-it (Snapdragon 8 Elite) | NPU-optimised variant added to the model allowlist — visible only on SM8750 devices. |
| v1.0.9 | Fix #46 — Audio Scribe OOM crash | Replaced boxed List<Float> (~16 bytes/sample) with a primitive growing FloatArray (4 bytes/sample). 30-min audio at 16 kHz no longer causes ~460 MB excess allocation. |
| v1.0.9 | Fix #47 — TTS silent with non-Amy voice | Auto-init and GrapheneOS TTS fallback now filter by download status before selecting a voice model (custom-rom-support only). |
| v1.0.8 | Saved System Prompts | Save, name, and reuse system prompts from the model settings dialog. Tap to apply, swipe to delete. |
| v1.0.8 | Restore Defaults | New button in model settings resets all sliders (temperature, top-K, top-P, max tokens) back to defaults in one tap. |
| v1.0.8 | System prompt actually applied | Changing the system prompt mid-session now correctly resets the conversation with the new instruction — previously saved in UI but not passed to the model. |
| v1.0.8 | Markdown fix in math responses | Plain-text segments in chat bubbles now render through the Markdown pipeline, fixing broken formatting in responses that mix text and LaTeX math. |
| v1.0.8 | Randomised inference seed | Each conversation now uses a unique random seed for more varied outputs on CPU backend. |
| v1.0.8 | GPU determinism root cause found | LiteRT LM v0.11.0 hard-caps max_top_k: 1 on devices without a GPU sampler, forcing greedy decoding. Switch to CPU for varied outputs. Reported upstream as issue #817. |
| v1.0.7 | Gemma 4 E2B & E4B updated | Model files refreshed on HuggingFace — new commit hashes, smaller sizes, same multimodal capabilities. |
| v1.0.7 | Speculative decoding / MTP | Multi-Token Prediction reads capability from the model file itself. Gemma 4 E2B reaches 66–91 tok/s on Galaxy S26 Ultra (GPU + spec) vs 52 tok/s plain GPU. |
| v1.0.7 | Sustained Performance Mode | setSustainedPerformanceMode(true) locks clocks during inference — no mid-conversation thermal throttling on long generations. |
| v1.0.7 | Benchmark spec decoding toggle | Benchmark screen shows a speculative decoding toggle for supported models. |
| v1.0.7 | AI Chat app shortcut | Long-press the Box icon → AI Chat jumps straight into chat, even from a cold start. |
| v1.0.7 | In-app update checker | Settings → Check for updates — fetches the latest GitHub release and offers a direct download link for your variant. |
| v1.0.7 | Model import from list | Whisper and TTS models can now be imported directly from the model list. |
Related
Built OfflineLLM first — a privacy-first Android chat app with a pure llama.cpp backend.
What is Box?

Box is an Android app for running AI entirely on-device — chat, voice mode, image generation, speech-to-text, document analysis, and vision, all without a network connection. It inherits the full feature set of the upstream Google AI Edge Gallery and layers on top: encrypted conversations, biometric lock, hard offline mode, and three additional native inference engines (llama.cpp, stable-diffusion.cpp, whisper.cpp) alongside LiteRT.
Box: On-Device AI. No Cloud. No Compromise.
What makes Box unique? You can sit at your desk, tap two buttons, and have a real flowing voice conversation with an AI — no wake word, no account, no server, no subscription. It listens, thinks, and speaks back sentence by sentence before it's even finished generating. Point the camera at something and ask about it out loud. The AI sees it and answers. All of it runs on the phone in your hand, completely offline, faster than you'd expect.
[!TIP]
Custom ROM users (GrapheneOS, LineageOS, CalyxOS): Use the custom-rom-support APK, not Main. Third-party ROMs lack AICore and system TTS, which impairs voice mode and NPU acceleration on the Main build. The custom-rom-support branch works around these limitations with built-in Piper TTS and alternative voice input. TPU/NPU acceleration is supported on Tensor devices; Snapdragon NPU remains untested on custom ROMs.
Screenshots
 Home Overview |
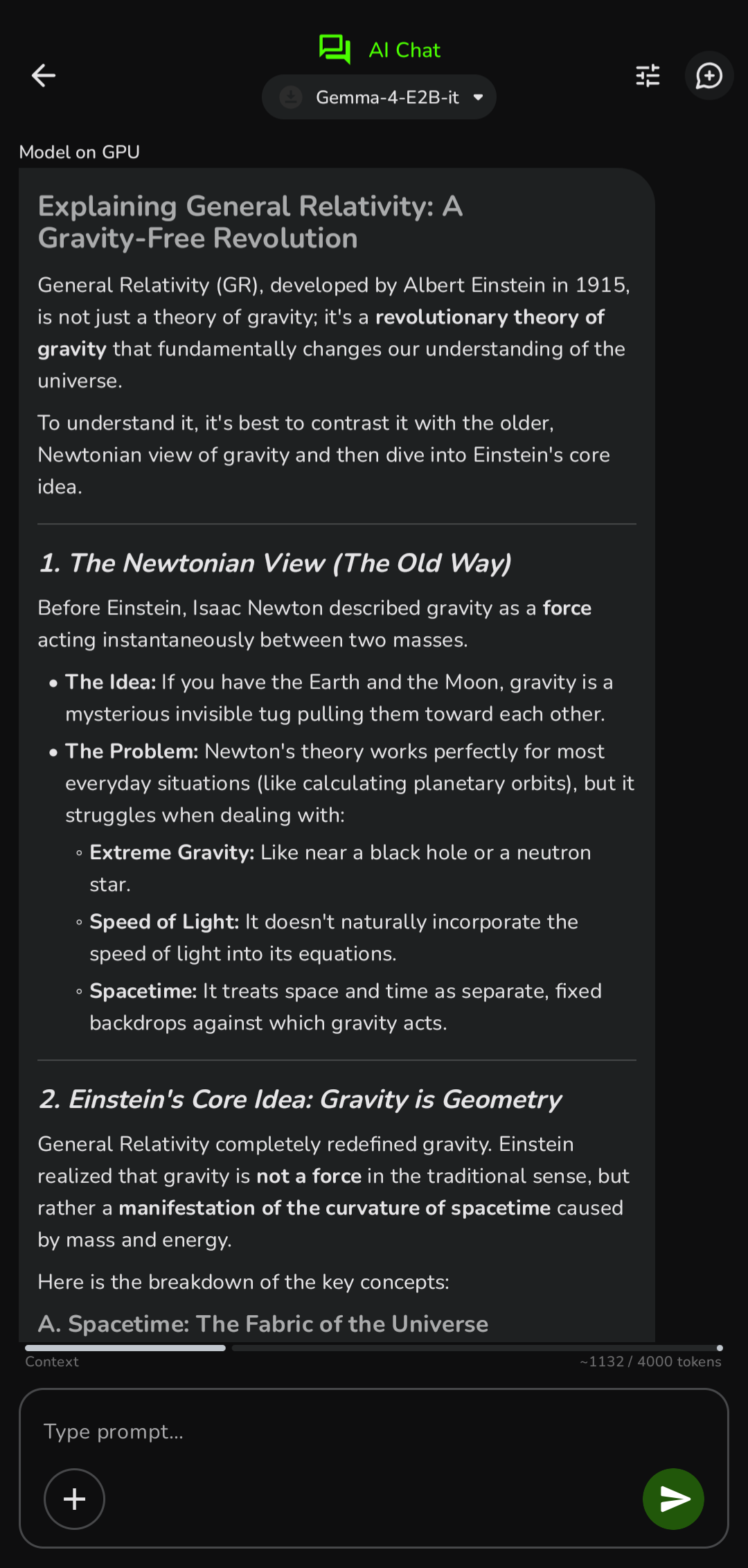 AI Chat |
 Chat Overview |
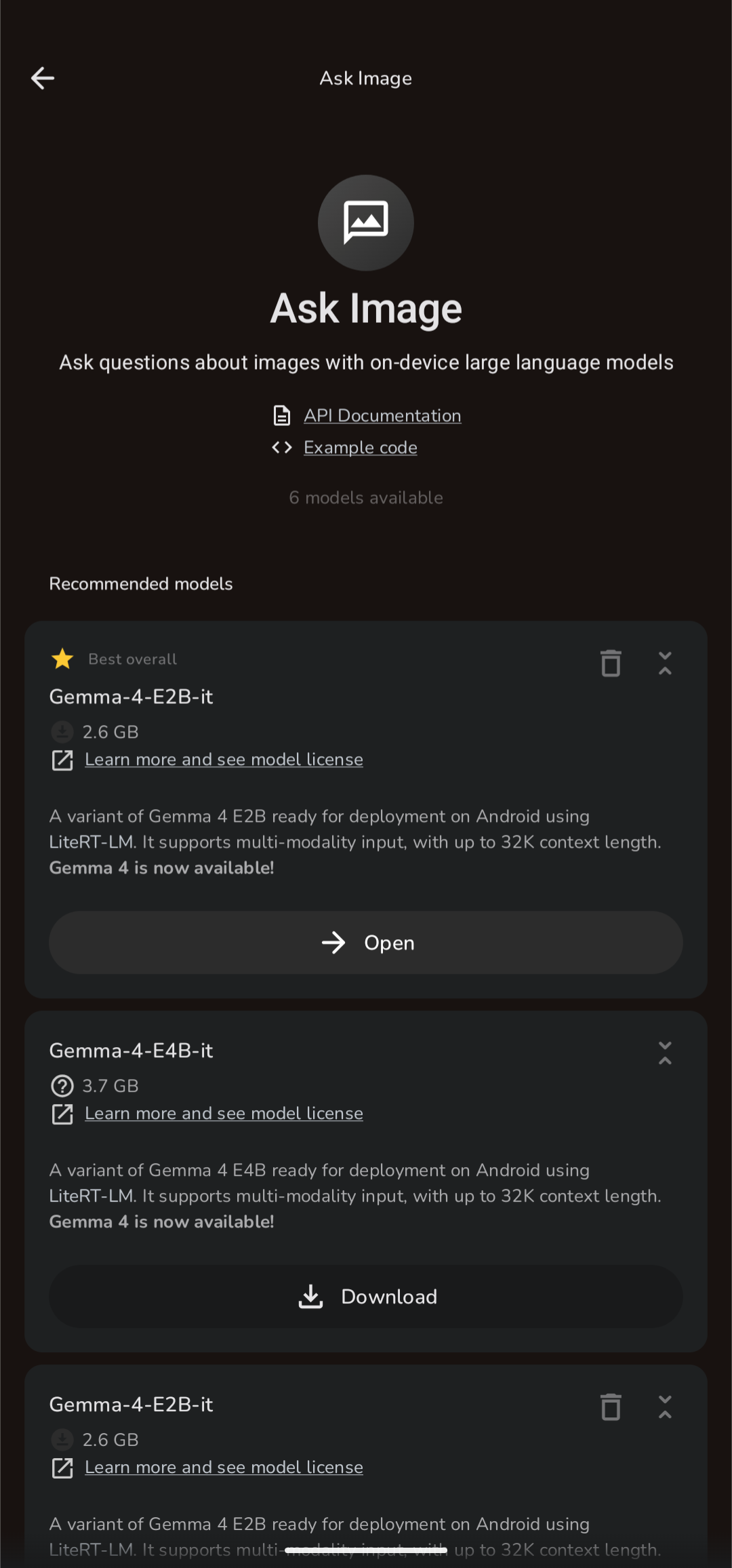 Vision AI |
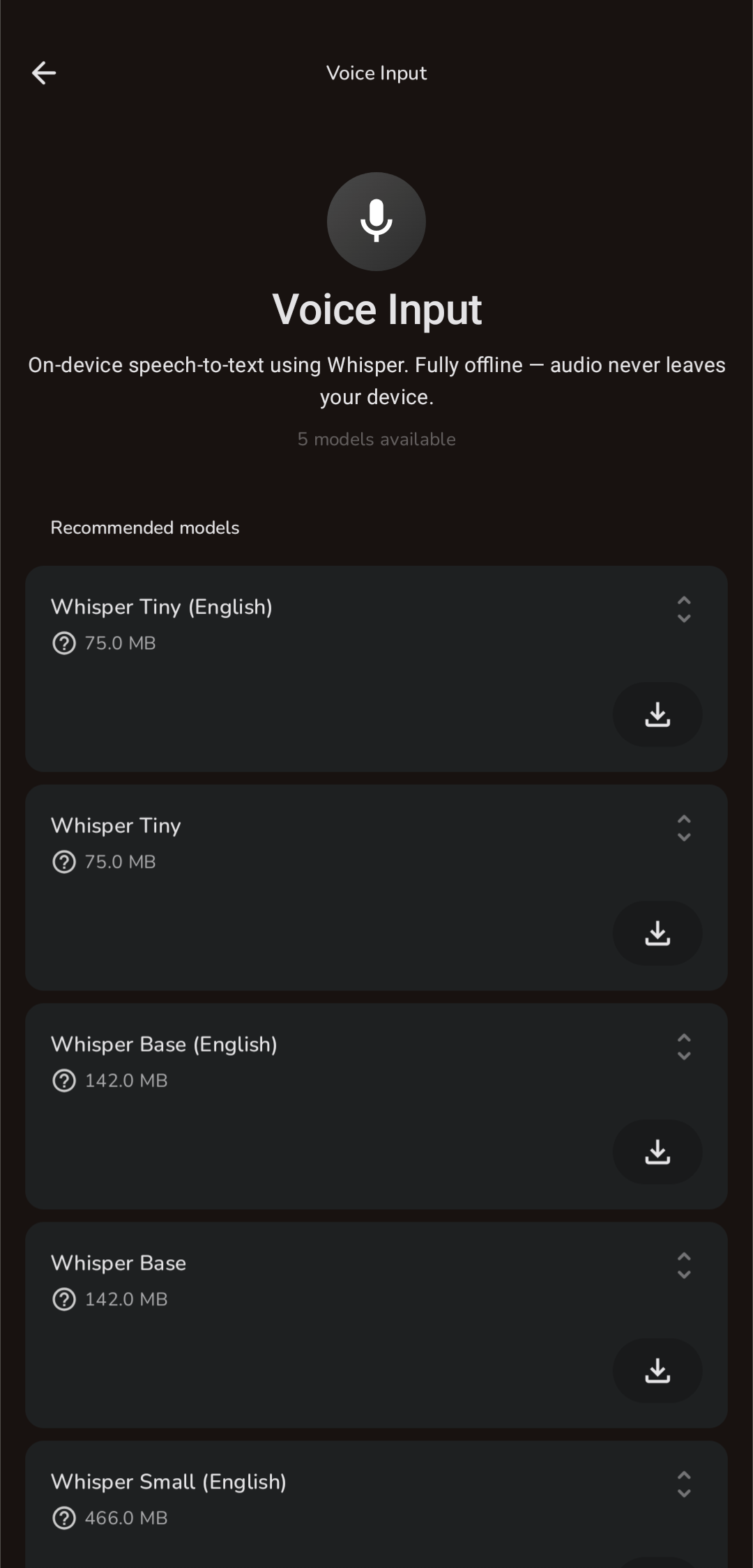 Voice Input |
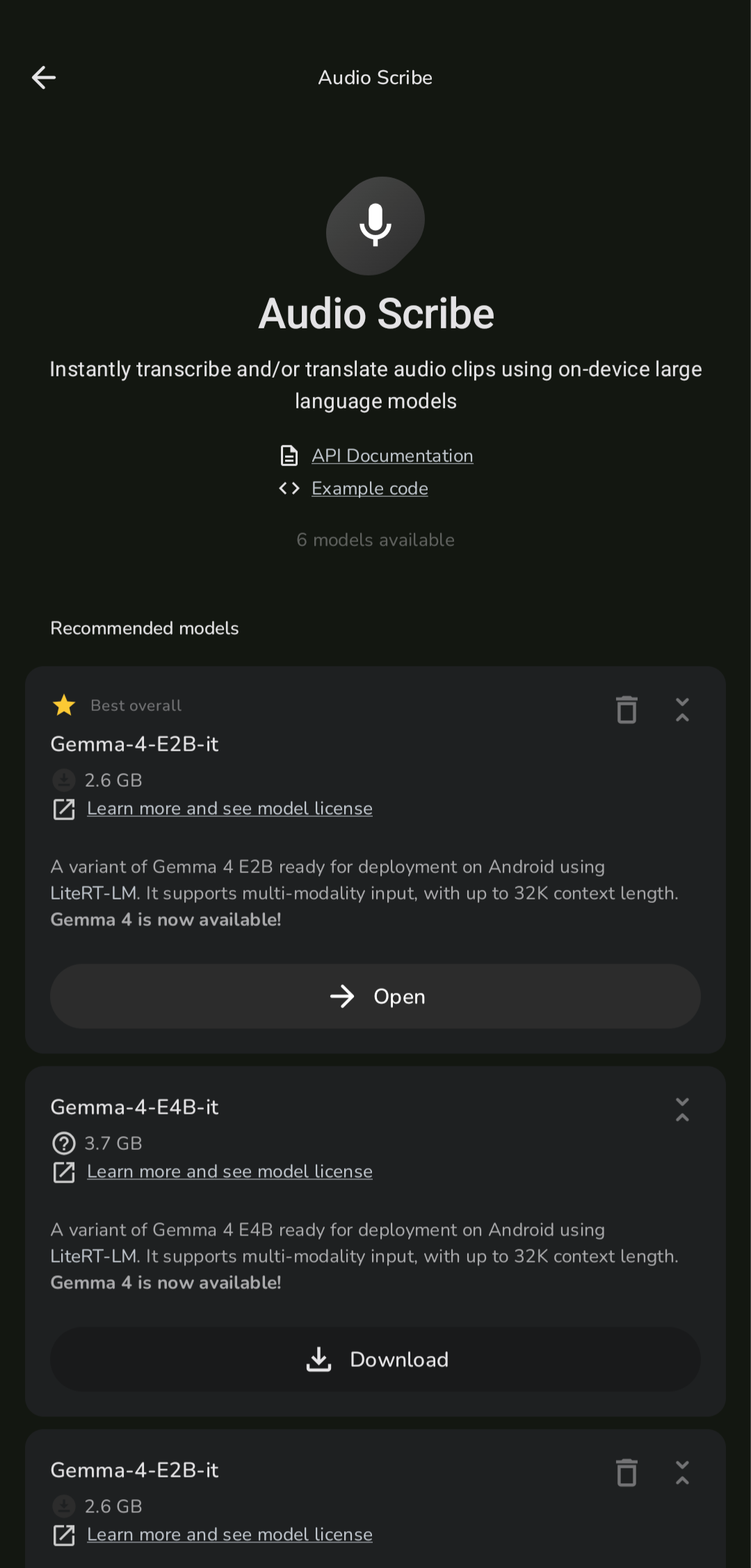 Audio Scribe |
 Whisper STT |
 Voice Mode |
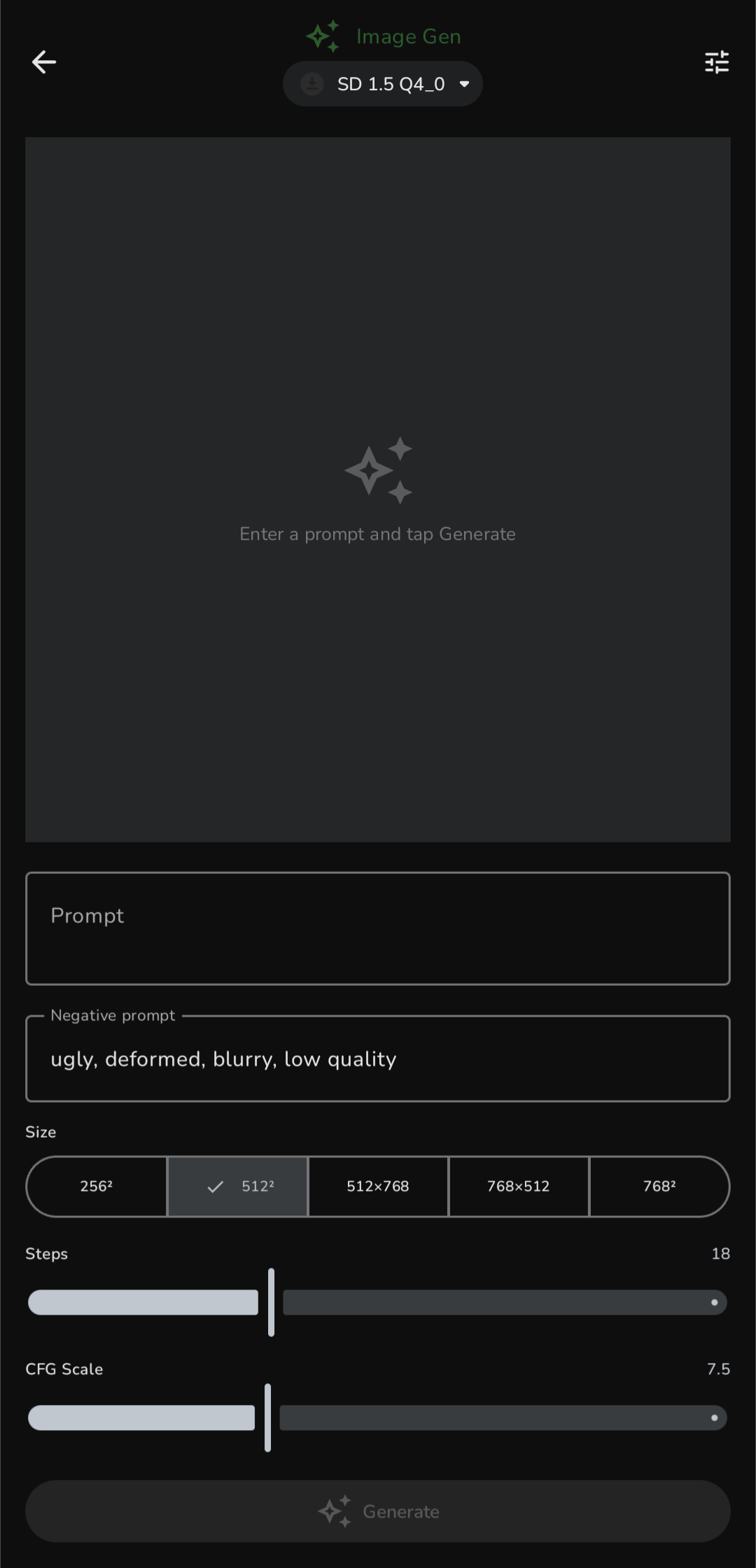 Image Generation |
 Agent (Skills + MCP) |
 Prompt Lab |
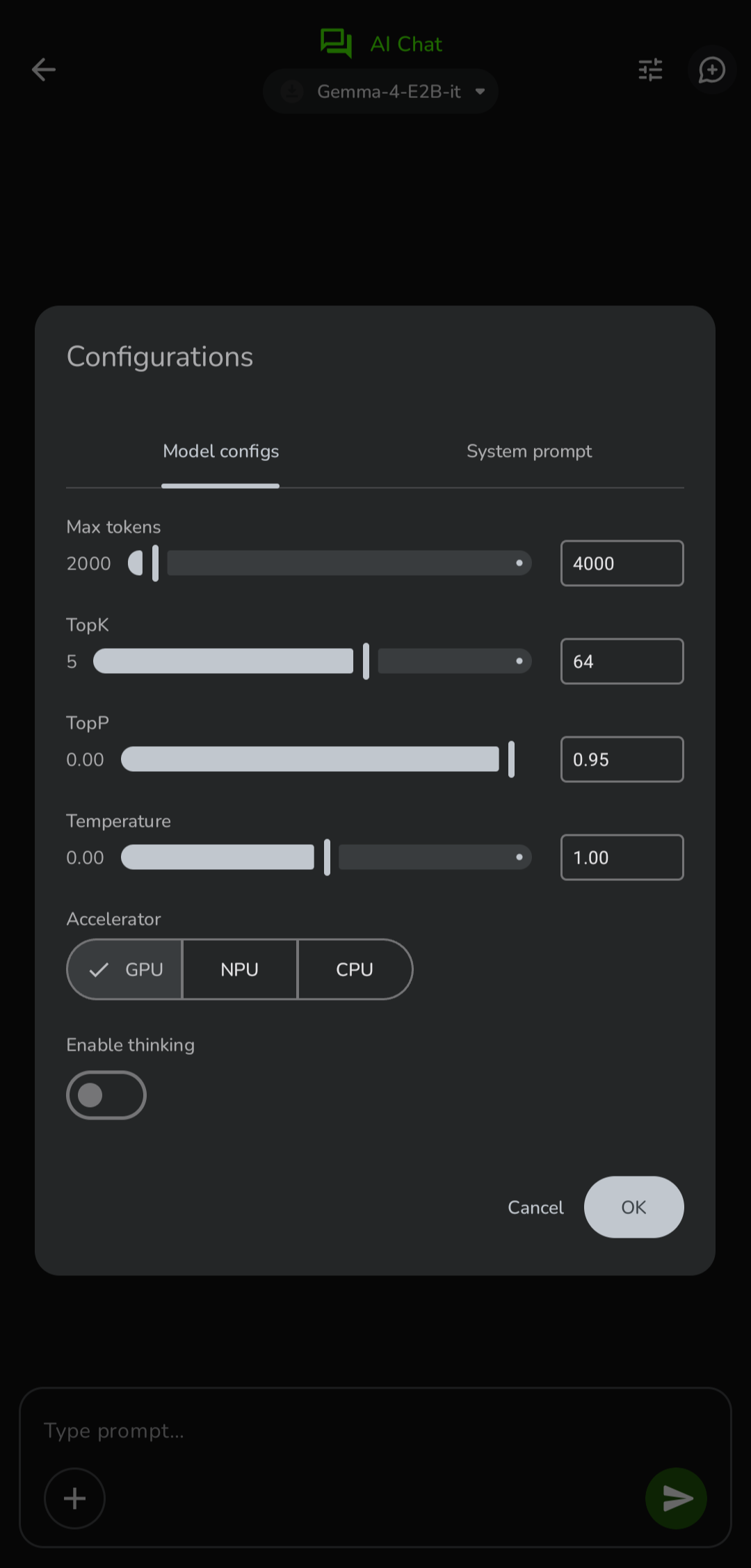 Model Config |
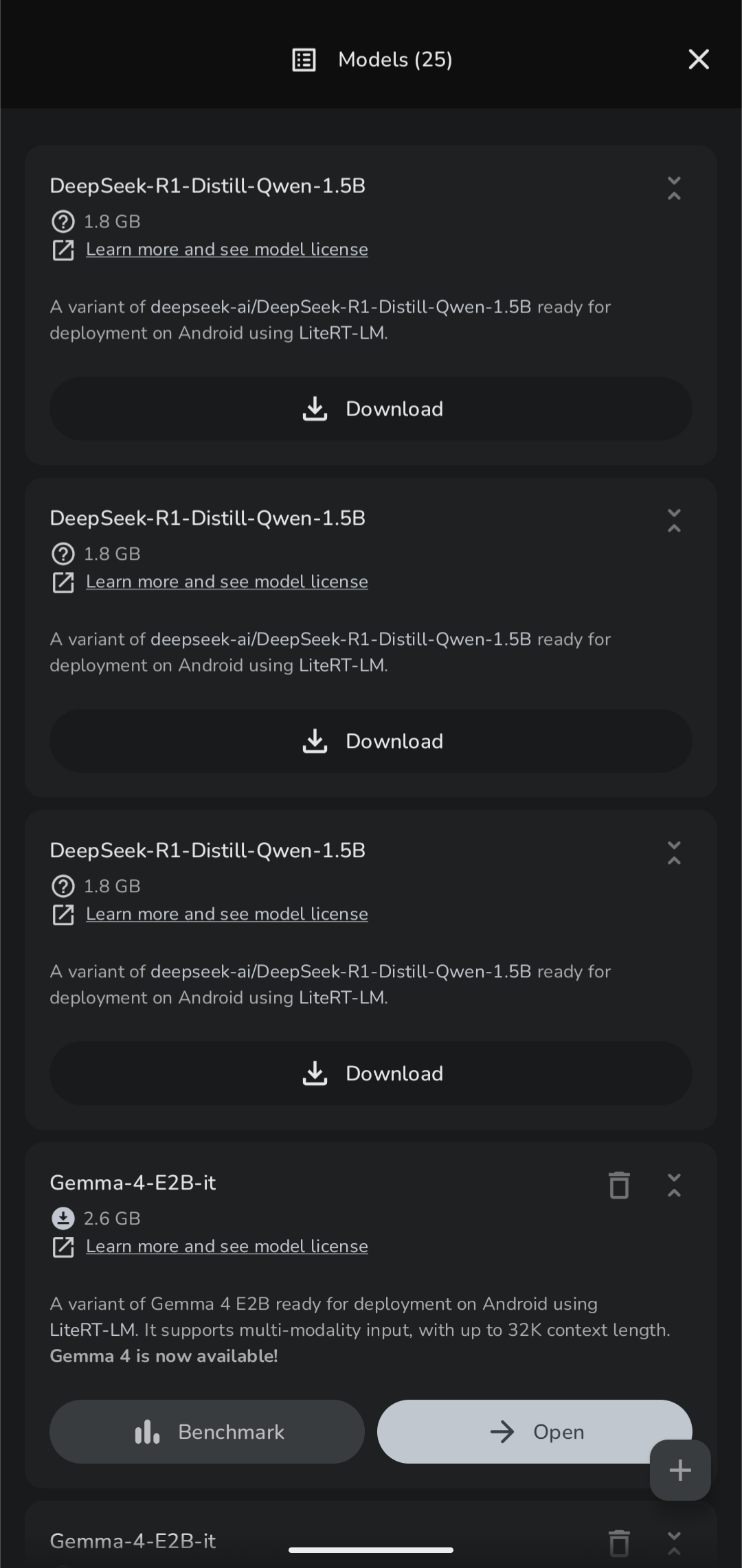 Model Select |
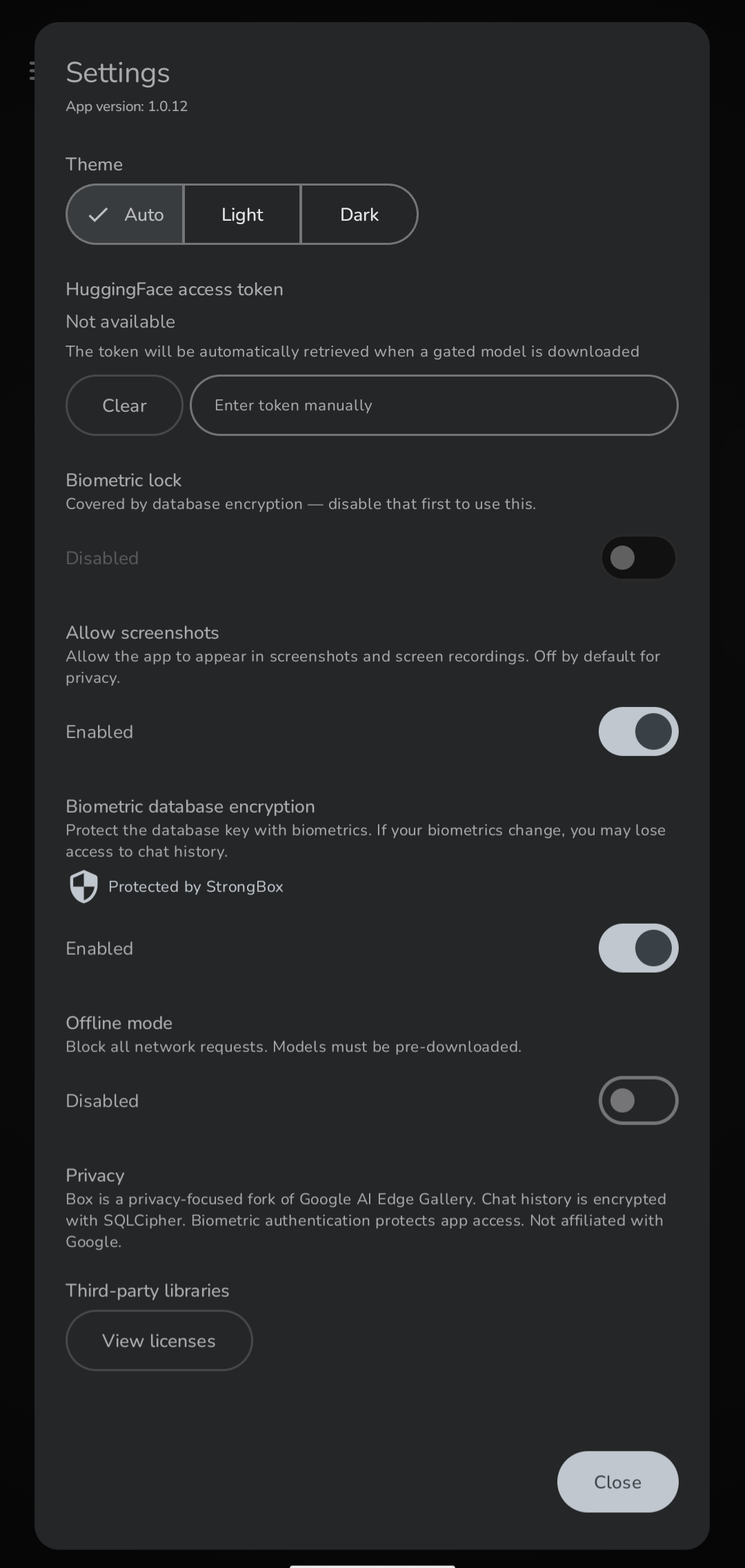 Settings |
 Gemini Nano |
[!NOTE]
What Box adds on top of upstream
Box is a fork of Google AI Edge Gallery. The upstream project is excellent — Box just layers on additional capabilities:
| Area | What Box adds |
|---|---|
| Inference engines | llama.cpp (GGUF LLMs), stable-diffusion.cpp (image gen), whisper.cpp (STT) alongside LiteRT |
| Model import | Import any local GGUF file — not limited to the curated download list |
| NPU / TPU | All Snapdragon / Tensor / MediaTek variants bundled in one APK (upstream ships per-SoC) |
| Voice mode / Vision mode | Free talk (continuous hands-free loop) and Vision talk (live camera + voice) |
| Image generation | On-device Stable Diffusion via GGUF |
| Speech-to-text | On-device Whisper STT |
| Document analysis | Attach text files (.txt, .md, .csv, .kt, etc.) directly in chat |
| Document Q&A | RAG pipeline: import PDFs, embed with MiniLM on-device, ask questions grounded in document content — answers cite their source passages |
| Gemini Nano | 6 on-device ML Kit features (Summarize, Proofread, Rewrite, Chat, Describe, Speech) — NPU/TPU-accelerated on Pixel 9+, entirely on-device via AICore (main branch) |
| Background Removal | ML Kit Subject Segmentation — remove backgrounds from photos, output a transparency-preserving PNG (main branch) |
| Chat history | Persisted to a SQLCipher-encrypted Room database, resumable across sessions |
| Security | Biometric app lock, hard offline mode, prompt sanitisation, audit log, tap jacking protection, accessibility data sensitivity |
| Themes | Catppuccin (14 accents) and Dracula (7 accents) alongside Material You — three-way picker in Settings |
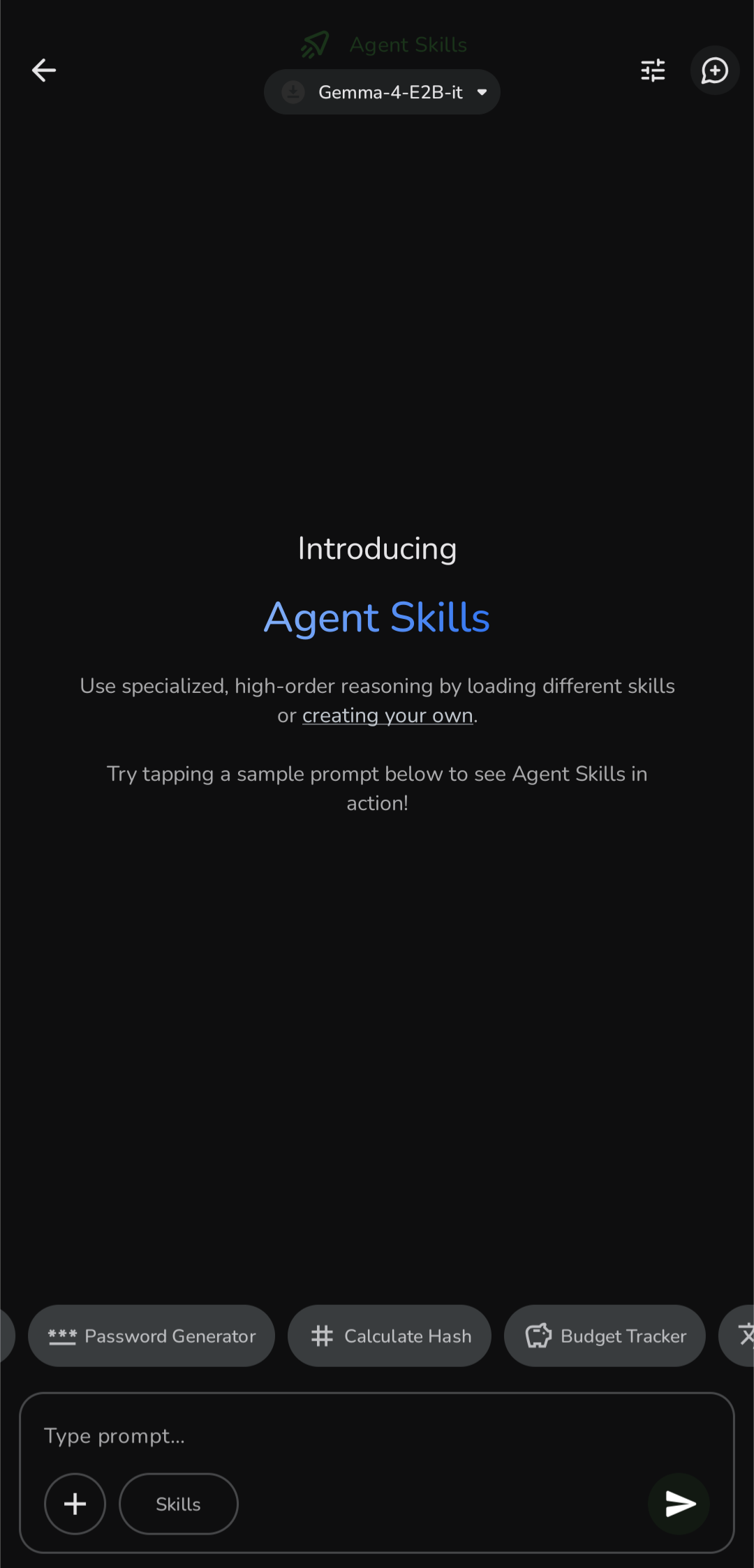
| Agent (skills + MCP) | 20 built-in skills (upstream has 9) plus Model Context Protocol — connect to remote MCP servers and give the model real tools, with per-call permission prompts |
| Math rendering | LaTeX expressions rendered as Unicode in chat, including inside markdown table cells |
| App shortcut | Long-press icon → AI Chat for instant cold-start navigation |
| In-app updates | Settings → Check for updates — compares against latest GitHub release, downloads correct variant |
Core Features
Local Chat
Multi-turn conversations with on-device LLMs. Import any GGUF model or download LiteRT models from the built-in list. Supports Thinking Mode on compatible models. Full markdown rendering with LaTeX math support — Greek letters, operators, fractions, and notation are rendered as Unicode symbols. Conversations are persisted and resumable.
Recommended models: We highly recommend Gemma 4 E2B or Gemma 4 E4B (LiteRT) as your primary models — best-tested, support vision, voice, and documents, and run efficiently with GPU/NPU acceleration. Available to download directly in the app.
With Gemma 4 E2B / E4B selected, the chat input expands to a full multimodal interface:
- 📎 Attach documents (
.txt,.md,.csv,.json,.py,.kt, and more) — content is injected into context automatically - 🎙 Record an audio clip or pick a WAV file to speak your question
- 📷 Take a photo or pick from album for visual Q&A
Local Diffusion
On-device image generation powered by stable-diffusion.cpp. Runs Stable Diffusion 1.5 in GGUF format fully offline — no API key, no cloud. Configurable steps, CFG scale, seed, and image size presets. Save generated images directly to your gallery. Import your own GGUF diffusion models.
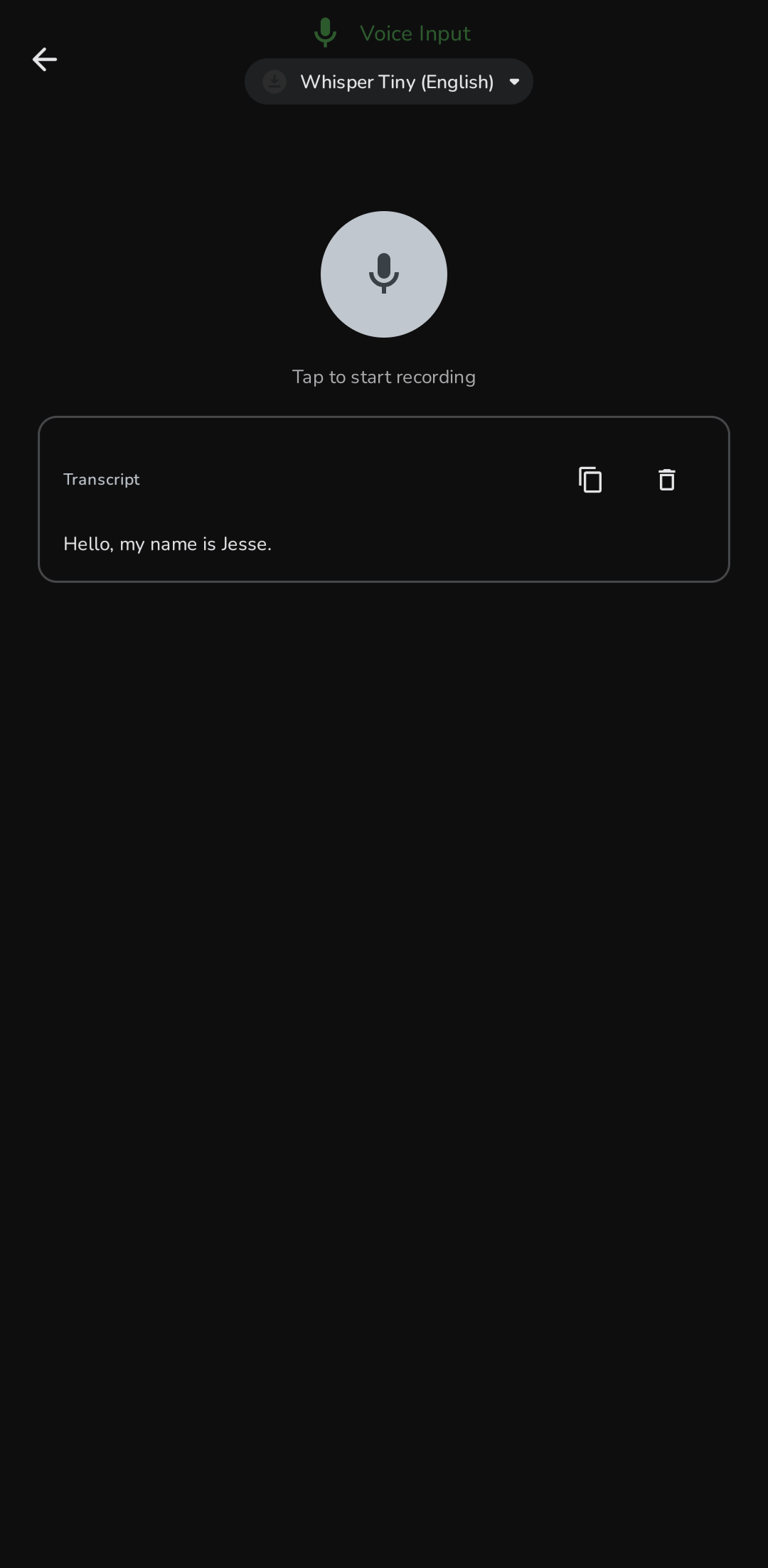
Voice Input
On-device speech-to-text using whisper.cpp. Tap to record, tap to transcribe. Copy or clear results. Supports Whisper Tiny through Small models in multiple languages. Audio never leaves the device.
Free Talk — Real-Time Voice Conversation
Tap the mic and the speaker. That's it. Box listens to you, sends your words to the AI, and speaks the reply back — then immediately starts listening again. No tapping between turns. No waiting for a full response before it starts speaking. Just sit there and talk to it like a person.
On Gemma 4 E2B it keeps up in real time. The first sentence of the reply is already being spoken while the model is still generating the rest.
- "Explain quantum entanglement like I'm five" → speaks the answer, listens for your follow-up
- "Actually, go deeper on that last point" → multi-turn, completely hands-free
- "Help me think through a problem I'm having at work" → back and forth, no typing ever
- "What should I cook for dinner tonight? I've got chicken and not much else" → practical daily use
It feels like having an AI sitting across from you. Entirely offline. Nothing leaves the device.
Three toggles in AI Chat control it:
- 🎤 Mic — tap once to enter free talk mode, tap again to stop
- 🔊 Speaker — AI replies spoken aloud, sentence by sentence as they generate
- 📹 Camera — live vision mode (see below)
Enable Real-time voice reply in Settings for sentence-by-sentence speech as the model generates. Works out of the box with Android's built-in speech and TTS — load a Whisper or Piper model for higher quality.
De-Googled ROMs (GrapheneOS, CalyxOS, LineageOS without GApps): Use the custom-rom-support APK — it includes Piper TTS (Amy) as a built-in download in the Voice tab, so no third-party TTS app is needed. If you're on the Main build, install a TTS engine from F-Droid (e.g. RHVoice or eSpeak NG) and set it as default in Android Settings → Accessibility → Text-to-speech.
Vision Talk — Live Camera + Voice AI
Tap the camera toggle to stream your back camera directly to the AI. Point it at anything and ask — the AI sees the current frame alongside your question and speaks its answer back. All offline, no cloud.
Things you can do:
- Point at a plant → "What species is this and how do I care for it?"
- Point at food in your fridge → "What can I cook with what's here?"
- Point at a label or sign in another language → "What does this say?"
- Point at a circuit board → "What component is this and what does it do?"
- Point at your code on a laptop screen → "What's wrong with this function?"
- Point at a meal → "Roughly how many calories is this?"
- Point at a maths problem → "Walk me through how to solve this"
Combine with mic + speaker for a fully hands-free vision conversation — speak your question, AI sees the scene, speaks the answer, listens for the next question. Requires a vision-capable model (Gemma 4 E2B or E4B).
When mic is off, camera mode sends a frame every 3 seconds automatically with "What do you see?" — useful for passive scene description.
Vision AI
Ask questions about images using on-device vision models. Powered by LiteRT with Gemma 4 E2B / E4B — GPU-accelerated, up to 32K context.
Biometric App Lock
Enable an optional biometric lock from Settings. The app re-locks automatically every time it is backgrounded. Unlock via fingerprint or face authentication before any content is shown.
Encrypted Chat History
All conversations are stored in a SQLCipher-encrypted Room database. History persists across sessions and is resumable from the Chat History screen. Swipe to delete individual conversations, or wipe all at once.
NPU / TPU Acceleration
All Qualcomm Hexagon NPU variants (Snapdragon 8 Gen 2 / 8 Gen 3 / 8 Elite / newer), Google Tensor TPU (Pixel 8–10), and MediaTek NPU are bundled in a single APK — no separate builds per device. Select NPU/TPU in the model's accelerator dropdown; Box auto-detects the chip and loads the right runtime.
Note: NPU acceleration currently falls back to GPU/CPU for most models. The NPU path (via AICore on Tensor, QNN on Snapdragon) requires model-side AUX metadata that current litert-community models don't yet include. GPU is the recommended accelerator and performs excellently on all supported chips.
Supported hardware:
- Snapdragon 888 / 8 Gen 1 (Hexagon V69)
- Snapdragon 8 Gen 2 (SM8550, Hexagon V73)
- Snapdragon 8 Gen 3 (SM8650, Hexagon V75)
- Snapdragon 8 Elite (SM8750, Hexagon V79)
- Snapdragon next-gen (SM8850, Hexagon V81)
- Google Tensor G3 / G4 / G5 (Pixel 8 / 9 / 10)
- MediaTek Dimensity (MT6989, MT6991)
GGUF Model Import
Import any GGUF model file from local storage. At import time set the display name and choose the accelerator (CPU, GPU via OpenCL/Vulkan, or NPU via QNN delegate). Stable Diffusion GGUF models can also be imported for image generation.
Hard Offline Mode
A toggle in Settings forces the app into a fully airgapped state — all download attempts throw an exception and no network calls are made.
Getting Started
Requirements
- Android 16+
- ~4 GB of free storage for a typical quantised LLM
- `6 GB of Ram
Build from source
git clone --recurse-submodules https://github.com/jegly/box
cd box/Android
./gradlew :app:assembleDebug
The --recurse-submodules flag is required to pull llama.cpp, stable-diffusion.cpp, and whisper.cpp submodules. The first build compiles all three native libraries from source — expect 15–25 minutes.
Open Android/ in Android Studio and run on a physical device for best performance.
Loading a LiteRT/GGUF model
- Copy a
.litertlm/GGUFfile to your device (Downloads, USB, etc.) - Open the app → Model Manager in the drawer
- Tap Import and pick your file
- Set a display name and choose CPU / GPU / NPU
- The model appears in AI Chat
Security Architecture
| Mechanism | Details |
|---|---|
| Database encryption | SQLCipher via androidx.room — AES-256 at rest |
| Biometric gate | BiometricPrompt API, re-prompts on each foreground |
| Offline mode | OfflineMode singleton blocks DownloadWorker and network calls |
| Prompt sanitisation | SecurityUtils.sanitizePrompt() strips control characters before inference and persistence |
| Tap jacking protection | filterTouchesWhenObscured on the window — user-configurable in Settings (on by default) |
| Accessibility data sensitivity | ViewCompat.setAccessibilityDataSensitive() hides content from untrusted accessibility services — user-configurable in Settings |
| Screenshot protection | FLAG_SECURE blocks screen capture and Recent Apps thumbnails — user-configurable in Settings |
| Audit log | SecurityAuditLog writes security events to a local append-only log |
Technology Stack
- Kotlin + Jetpack Compose — UI
- Hilt — dependency injection
- Room + SQLCipher — encrypted persistence
- LiteRT-LM — LiteRT inference runtime for LLMs (GPU + NPU/TPU)
- Qualcomm QNN / QAIRT 2.41 — Hexagon NPU runtime (V69–V81, bundled)
- LiteRT NPU dispatch — auto-selects Qualcomm / Google Tensor / MediaTek at runtime
- llama.cpp — GGUF LLM inference (git submodule)
- stable-diffusion.cpp — GGUF image generation (git submodule)
- whisper.cpp — on-device speech-to-text (git submodule)
- Sherpa-ONNX (k2-fsa) — Piper TTS engine for on-device voice synthesis (custom-rom-support branch)
Acknowledgements
Box would not exist without the work of the teams and individuals behind the projects it builds on.
Google AI Edge Gallery — the upstream project this fork is based on. The Google AI Edge team built an exceptionally well-structured, open-source Android app and made it available under the Apache 2.0 licence. Everything in Box starts from their foundation. Upstream changes are periodically merged and any improvements we make that are appropriate to contribute back will be.
llama.cpp — Georgi Gerganov and the llama.cpp contributors for making high-performance on-device LLM inference accessible to everyone.
stable-diffusion.cpp — leejet and contributors for the C++ Stable Diffusion implementation that powers on-device image generation.
whisper.cpp — Georgi Gerganov and contributors for the Whisper speech-to-text port.
LiteRT / TensorFlow Lite — the Google teams behind LiteRT (formerly TFLite) and the NPU/GPU delegate infrastructure.
Sherpa-ONNX / k2-fsa — the k2-fsa team for Sherpa-ONNX, which powers the Piper TTS engine (Amy and other voices) in the custom-rom-support branch.
off-grid-mobile-ai — Mohammed Ali Chherawalla for the on-device Stable Diffusion Android implementation, which was instrumental in getting efficient on-device image generation working and influenced parts of Box’s pipeline.
PocketSage — Umer Arif for the clean, fully offline RAG-on-Android
reference implementation that the Document Q&A feature in Box is based on.
Thanks to aryoda and all the contributors for consistently reporting valid bugs. Appreciate the reports !
Thank you to everyone who has opened issues, tested builds, or contributed to any of these projects. On-device AI is a community effort.
License
 Licensed under the Apache License, Version 2.0
Licensed under the Apache License, Version 2.0
Links
- Box repository
- Upstream: google-ai-edge/gallery
- llama.cpp
- stable-diffusion.cpp
- whisper.cpp
- LiteRT-LM
- LiteRT NPU docs
- Qualcomm QAIRT SDK
- Hugging Face LiteRT Community
Checksums
| Variant | SHA-256 |
|---|---|
| main | d6406193d0857cc60d99d169738058cb99c40ed84bf4adc82733480bc5ad0f49 |
| custom-rom-support | 160eb2ed07997412ecfb29416fa79d2d6b708ef093544ac54526071e6509c04f |

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Box for Linux (Desktop)
Box for Linux is a native GTK4 / libadwaita desktop app that brings the Box
experience to the Linux desktop — fully offline local chat, real-time voice
conversation, live camera vision, document Q&A, and web/file tools, all running
on your own machine. Built on Google's LiteRT-LM runtime, it shares the
philosophy of the Android app — on-device, offline-first AI, no account, no
telemetry — in an app designed from the ground up for the Linux desktop.
[!IMPORTANT]
Box for Linux is a separate application, written from scratch — it is
not a port, build, or fork of the Android app. The two share a name, a
philosophy, and many similar features, but they are independent codebases.
The Android app is open source (Apache-2.0); Box for Linux is distributed
as a closed-source binary — the.debships compiled code and its source
is not currently published. It does not include the Android app's Stable
Diffusion image generation, Whisper STT, SQLCipher encryption, or biometric
lock.
What is Box for Linux?
A local-first chat app where the language model, the retrieval embedder, the
image captioner, and the text-to-speech all run on your own hardware. The
interface is native — not Electron, not a browser shell — so it starts in under
a second, uses sane amounts of memory, and sits properly inside your GTK
desktop.
It's built to be the daily-driver assistant on a Linux laptop: fast enough for
quick back-and-forth questions, capable enough to ground its answers in your
local documents, your webcam, and the open web — without ever sending your
conversation to someone else's server.
Screenshots
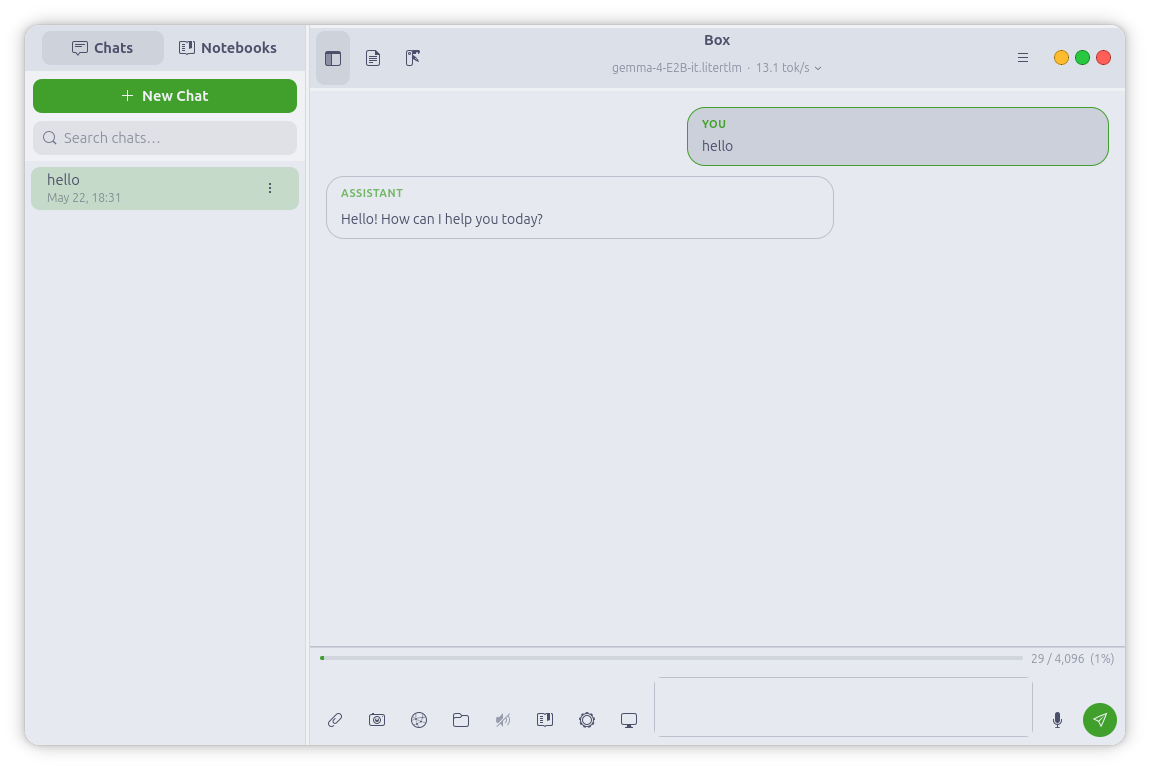 Local Chat |
 Knowledge Base |
 Permission Prompts |
 Web & File Tools |
 Agent Mode |
 Persistent Memory |
 Vision & Camera |
 Voice & TTS |
 RAG Settings |
 Model Settings |
 Behaviour |
 Themes & Appearance |
Core Features
Local Chat
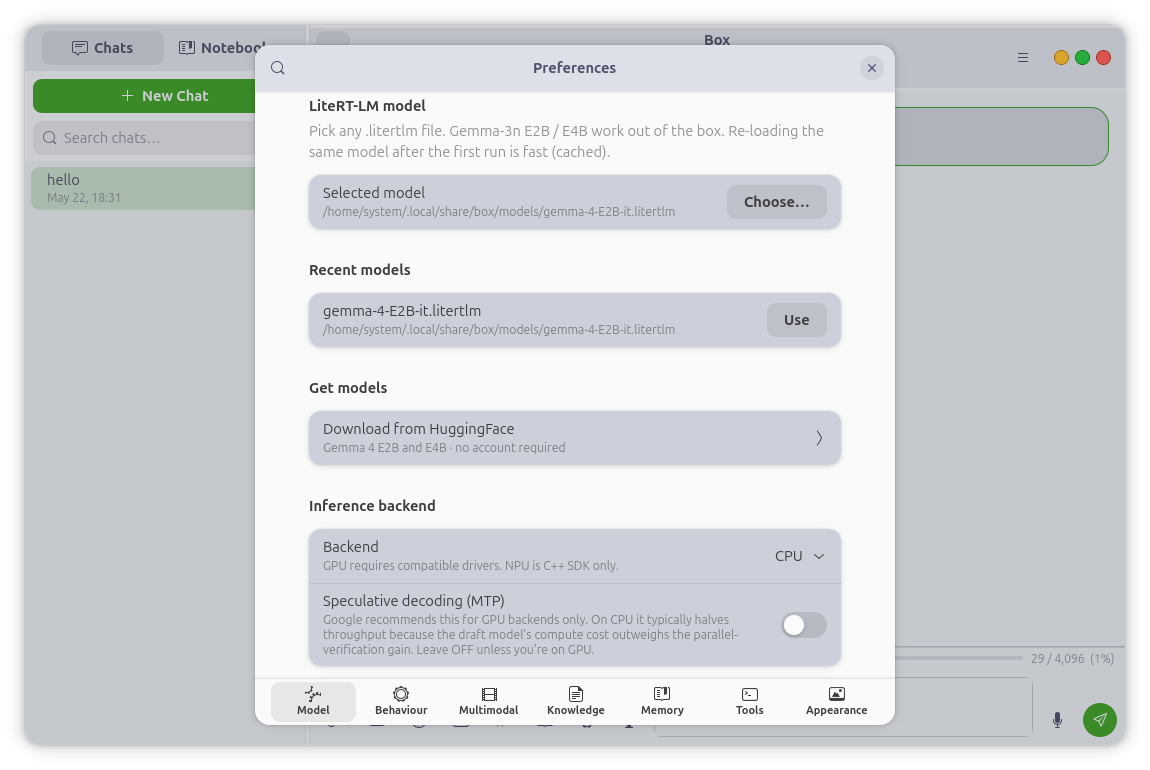
Multi-turn conversations with on-device LLMs in .litertlm format — Gemma 4 E2B
and E4B are the recommended daily drivers, both supported up to 128K context.
Tokens stream in as they generate, and a snappy Stop button interrupts
mid-token. Full Markdown rendering with LaTeX math — inline expressions render
as Unicode, display equations as images. Attach text, PDF, image, or audio
files directly in the composer. Conversations are saved and resumable, with a
searchable, resizable, hideable sidebar, a live token-usage bar, an adjustable
context window, and a CPU or GPU backend.
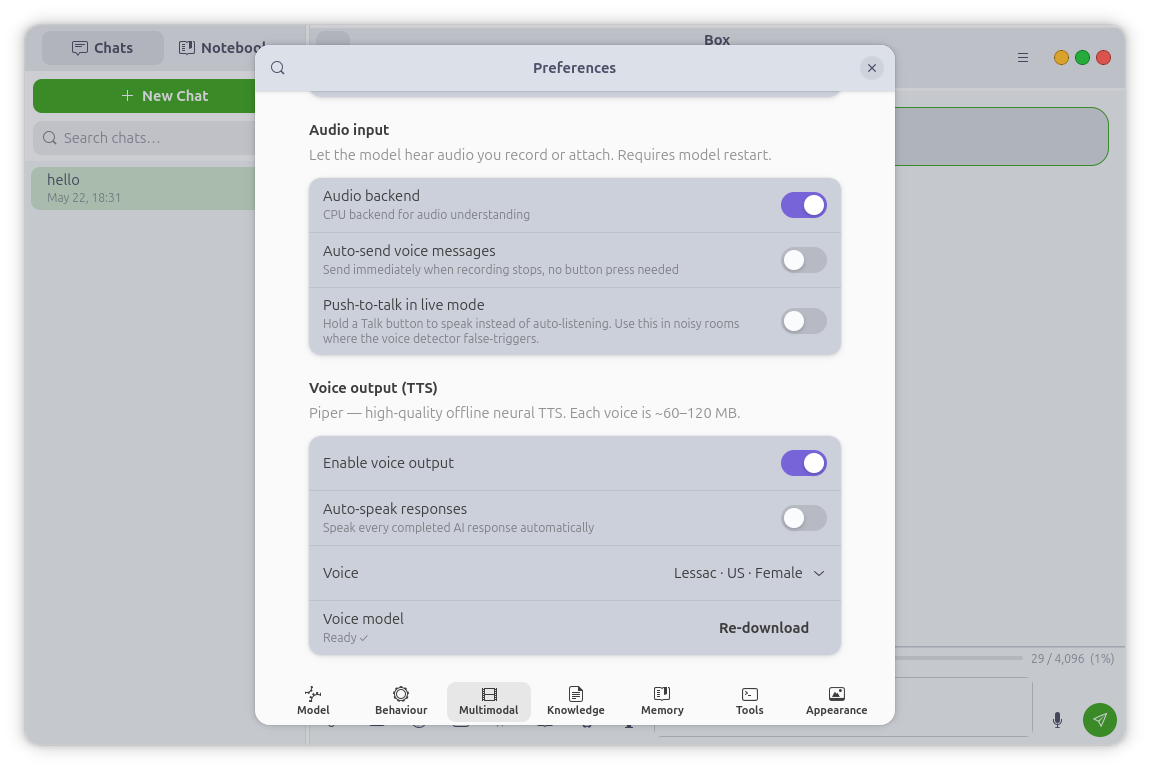
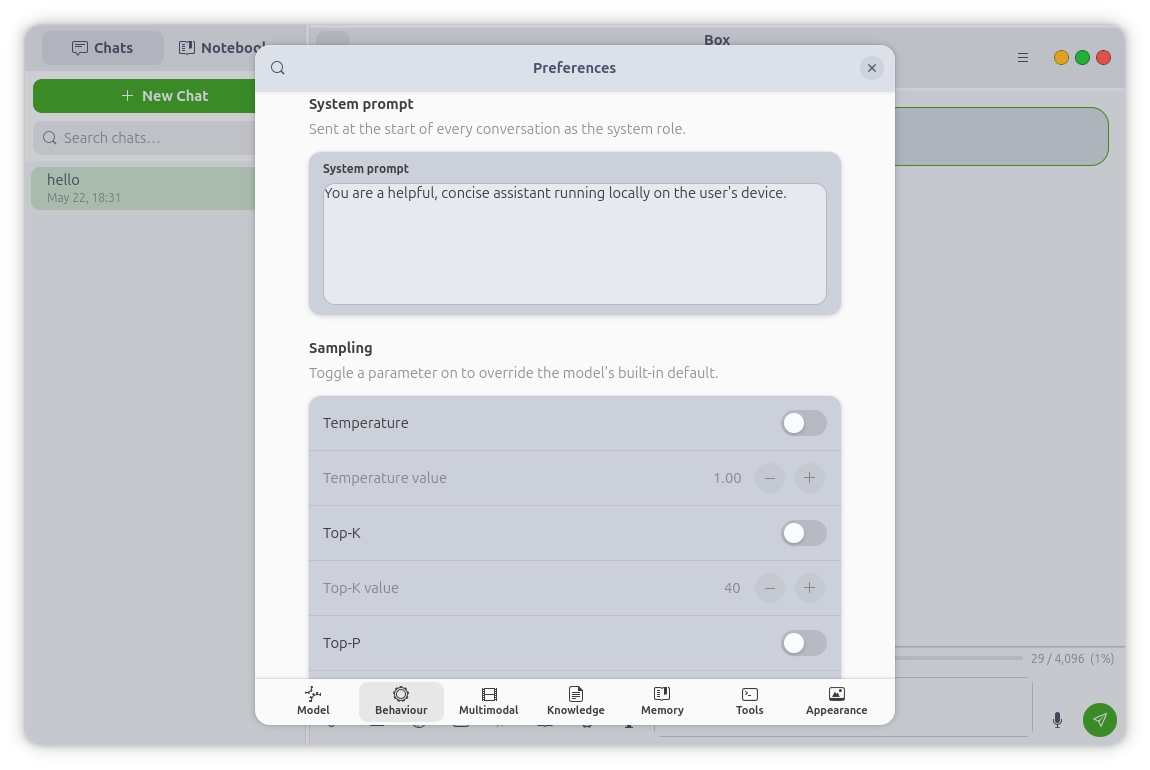
Voice & Conversation
Box listens, thinks, and speaks back. With the audio backend enabled the model
reasons about spoken or attached audio directly — not just transcription.
Record a voice message, play it back inline, and optionally auto-send it. Or
enter voice conversation mode: a hands-free, voice-activity-driven loop —
speak, the model replies aloud sentence by sentence as it generates, then it
listens again, no tapping between turns. An optional push-to-talk button
covers noisy rooms. Replies are spoken with Piper, an offline neural TTS, in
any of six voices, with adjustable volume.
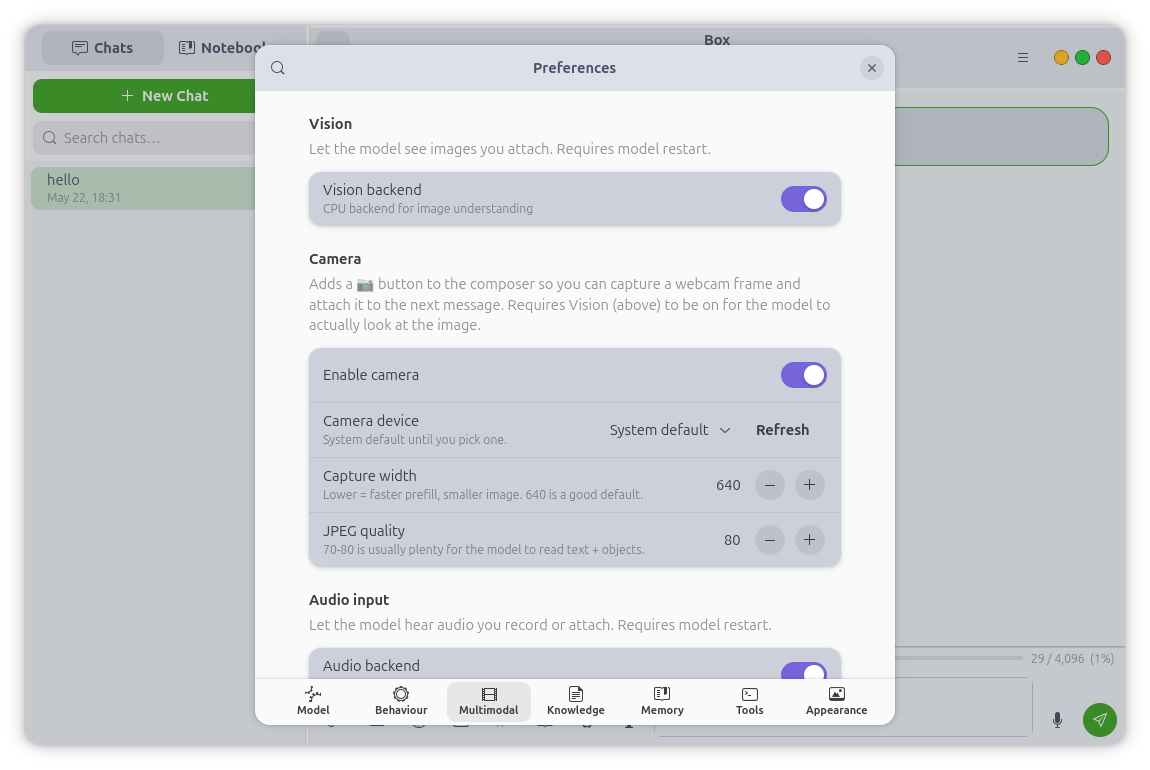
Live Camera Vision
Point a webcam at something and ask about it. The 📷 button in the composer
opens a live preview — capture a frame and the model sees it on send.
Vision Mode keeps the camera on and auto-captures a frame each turn for a
continuous live-vision conversation. Capture runs through GStreamer + PipeWire
(with a V4L2 fallback), so it integrates cleanly with the Linux camera
permission portal — and the camera light goes off deterministically when you're
done. Images can also be added to your knowledge base, where the model captions
them and makes them searchable.
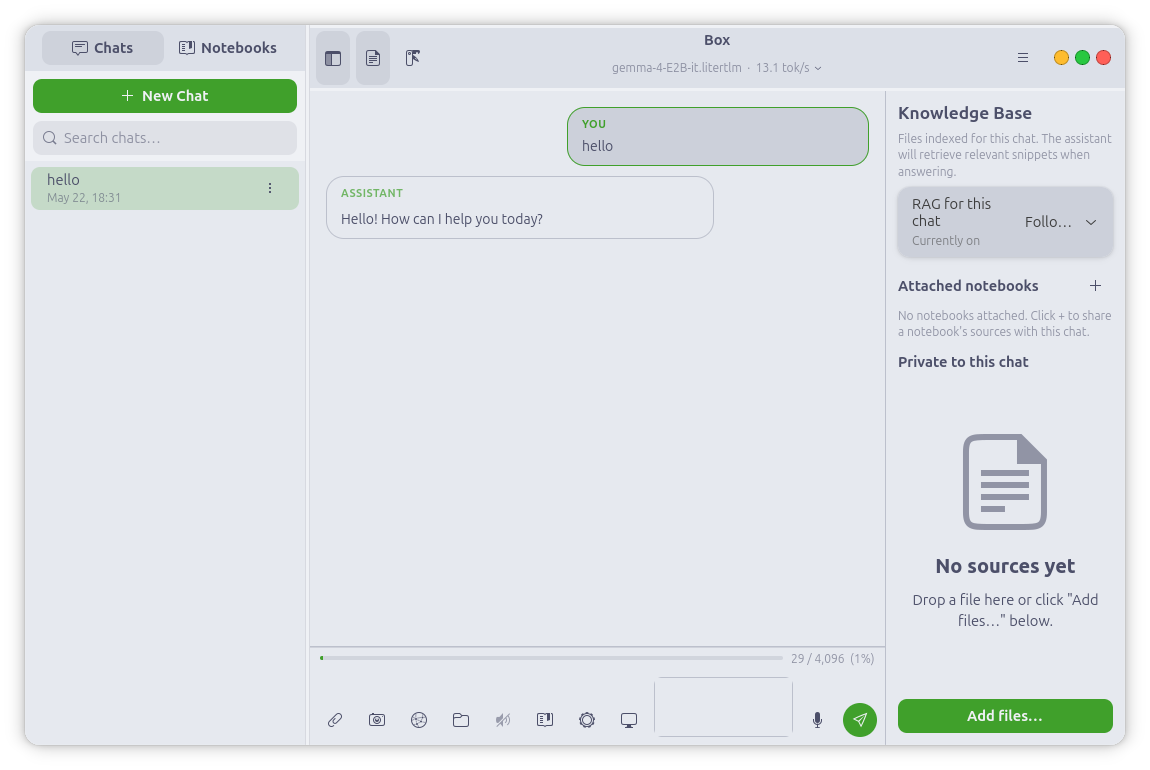
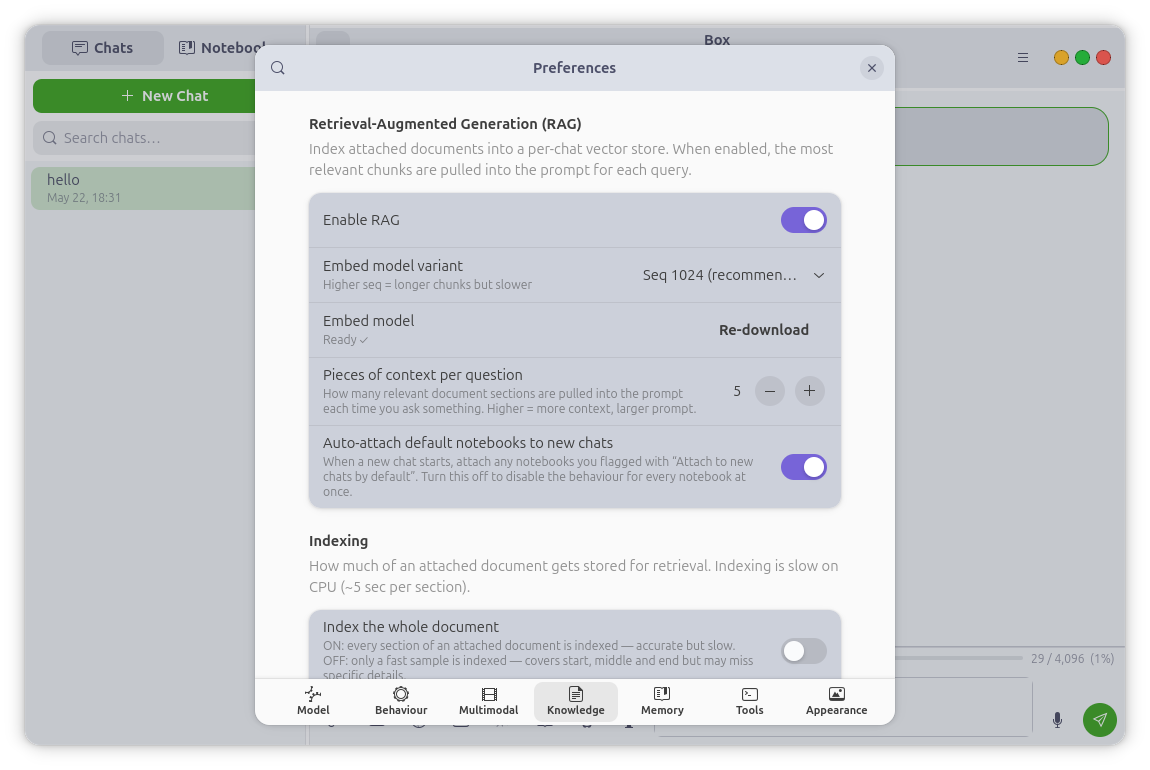
Knowledge Base — Document Q&A
Attach a PDF, Markdown file, source file, or plain text and Box chunks, embeds,
and indexes it for retrieval — every answer is grounded in your documents, and
a card on each reply shows exactly which passages the model used.
Notebooks are named, reusable collections of documents that live
independently of any chat: index a body of knowledge once and attach it to as
many chats as you like, with an optional auto-attach for collections you always
want. Retrieval unions a chat's private sources with every attached notebook.
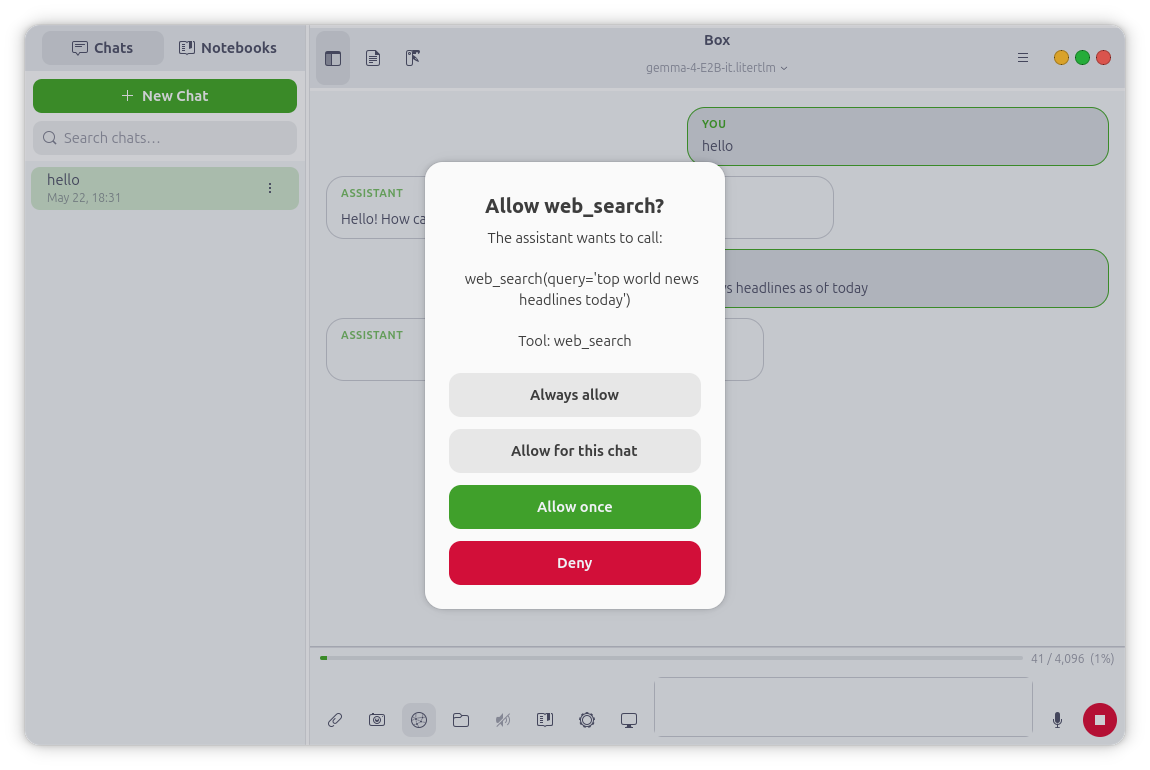
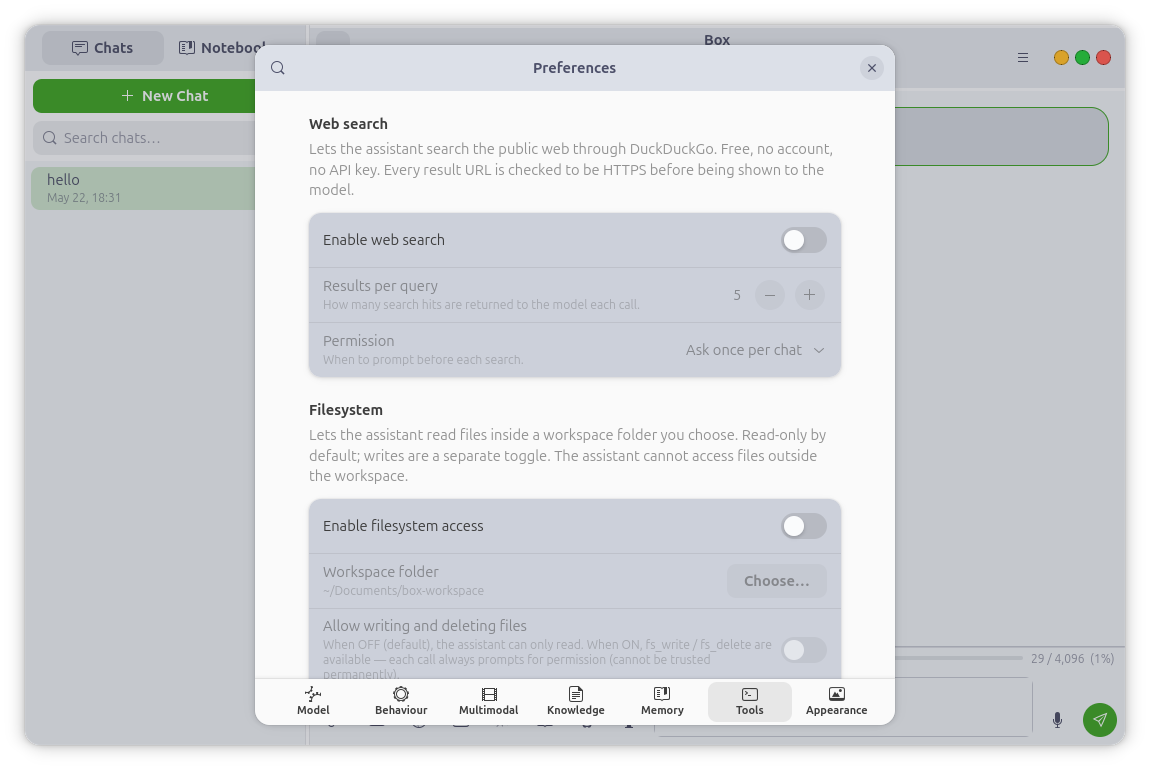
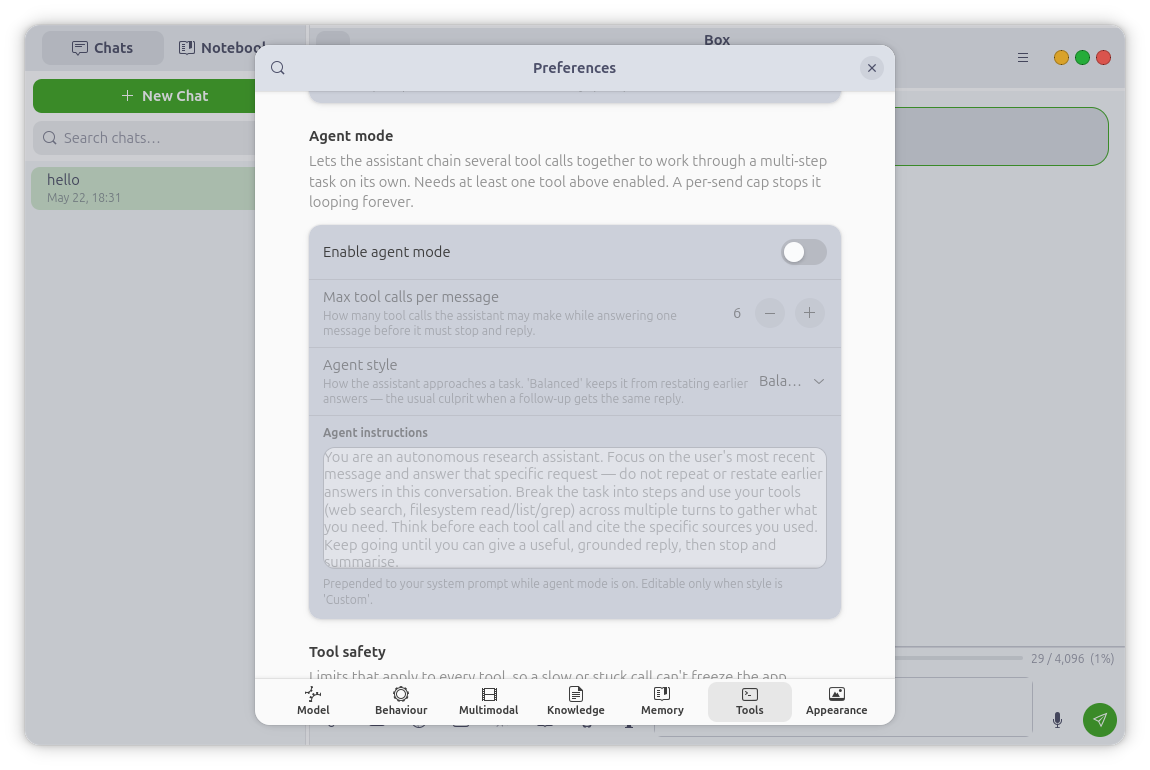
Tools & Agent Mode
Box can search the web (DuckDuckGo, HTTPS-only, no API key, no signup) and read
or write files in a workspace folder you choose. Agent mode chains multiple
tool calls to handle multi-step tasks — research and report, compare, plan —
with a configurable per-message cap on tool calls and a live progress pill.
Every tool invocation renders as a collapsible card in the reply, showing the
exact arguments and result.
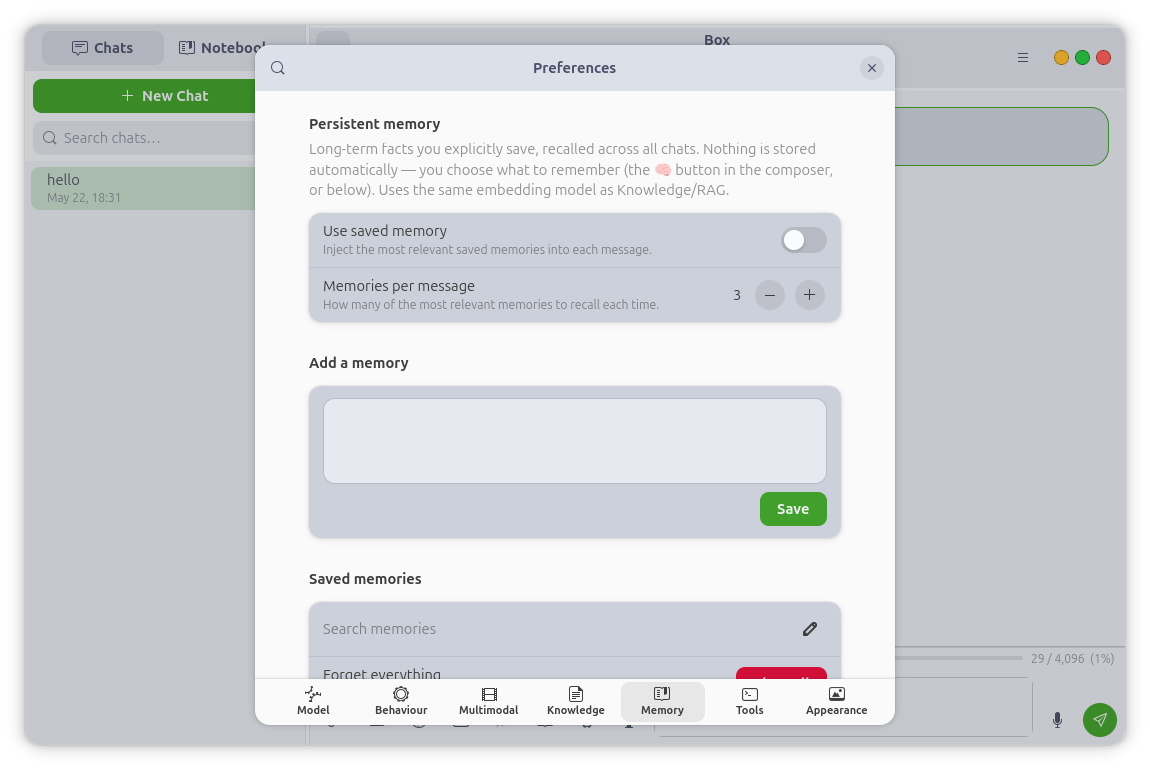
Persistent Memory
Save a fact once and Box recalls the relevant ones across all of your chats,
from a long-term store kept separate from per-chat documents. Capture is always
explicit — nothing is remembered without you asking — and a memory inspector
lets you view, search, and delete what Box knows.
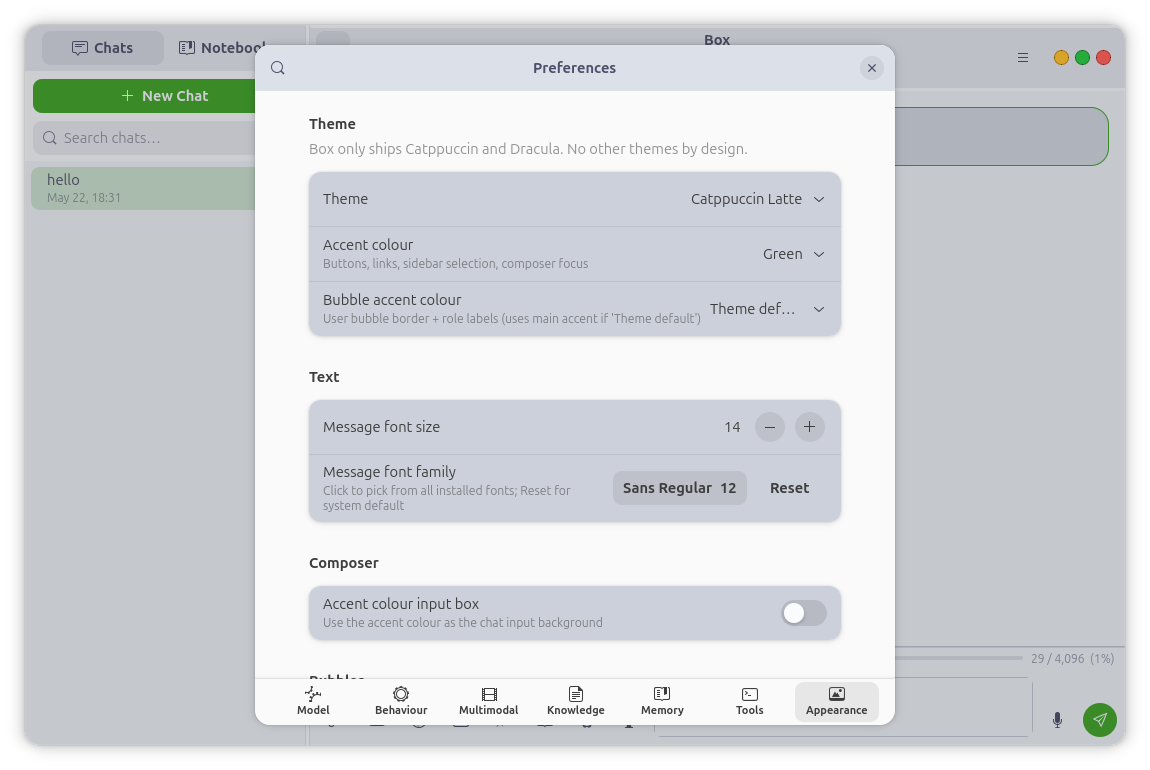
Themes
Six themes — Catppuccin Mocha, Latte, Frappé, and Macchiato, plus Dracula and
Dracula Pro — each with 14 accent colours, five iMessage-style bubble palettes,
a bubble-opacity slider, custom fonts, and macOS-style traffic-light window
controls.
[!NOTE]
You control everything
Every capability in Box for Linux is a separate switch, and everything is OFF
by default — vision, audio, TTS, knowledge base, web search, filesystem,
agent mode, and memory are each opt-in.
| Control | What it means |
|---|---|
| Granular toggles | Each capability is its own switch — nothing runs unless you turn it on |
| Permission prompts | Any tool that touches your machine asks first — Allow once / Allow for this chat / Always / Deny |
| Writes always ask | File writes and deletes can never be set to "trust always" — they prompt every time |
| Per-chat overrides | Flip any tool on or off for a single conversation, independent of the global setting |
| HTTPS-only | Every network boundary rejects non-HTTPS URLs — model downloads, web search results, everything |
| Fully on-device | No account, no telemetry, no phoning home; models download once, then run offline |
Install
Download the latest .deb from the Releases page:
sudo apt install ./box_<version>_amd64.deb
The package pulls its system dependencies automatically. Then launch Box
from your application menu, or run box from a terminal. On first run, Box
offers to download a model (Gemma 4 E2B, ~2.59 GB) — models are downloaded
once and then used entirely offline.
Requirements
- Ubuntu (amd64) with a GTK4 / libadwaita desktop session
- ~3–4 GB of free storage for a model
- A webcam is optional (live vision mode)
- CPU-only works fine; GPU acceleration is faster but not required. NPU/GPU
paths are included but not all hardware is tested.
Source & License
The Android app is open source (Apache-2.0). The Linux desktop app is
distributed as a closed-source binary — the .deb ships compiled code and
its source is not currently published. © Jegly. All rights reserved.
Downloads
| Platform | Download | Source |
|---|---|---|
| Android | APK (Releases) / Obtainium | Open (Apache-2.0) |
| Linux (Ubuntu, amd64) | .deb (Releases) |
Closed (binary only) |
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found