CogniLayer
Health Pass
- License — License: NOASSERTION
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 24 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
CogniLayer is a persistent memory and code intelligence layer for AI coding agents like Claude Code and Codex CLI. It helps AI agents retain knowledge about your codebase across sessions using semantic search, code graph analysis, and subagent context compression.
Security Assessment
The automated code scan of 12 files found no dangerous patterns, no hardcoded secrets, and no requests for dangerous permissions. However, the tool inherently reads and indexes your source code to build its knowledge graph and memory database, meaning it has broad access to your entire codebase, including potentially sensitive files. No evidence of unexpected network requests or shell command execution was found during the audit. Overall risk: Low.
Quality Assessment
The project is very new but actively maintained, with its most recent push occurring today. It has a small but growing community with 24 GitHub stars. The repository features a comprehensive and professional README. Note that while the license badge claims "Elastic-2.0," the automated check returned "NOASSERTION," which introduces slight uncertainty about the exact licensing terms. It requires Python 3.11 or higher.
Verdict
Safe to use, but be aware it will scan and index your codebase, and verify the license terms before adopting it in a commercial environment.
Stop re-explaining your codebase to AI. Infinite speed memory + code graph for Claude Code & Codex CLI. 17 MCP tools, subagent protocol, hybrid search, TUI dashboard, crash recovery. Save 80-200K+ tokens/session.
🧠 CogniLayer v4
Stop re-explaining your codebase to AI.
Infinite speed memory · Code graph · 200K+ tokens saved
Without CogniLayer, your AI agent starts every session blind. It re-reads files, re-discovers architecture, re-learns decisions you explained last week. On a 50-file project, that's 80-100K tokens burned before real work begins.
With CogniLayer, it already knows. Three things your agent doesn't have today:
🔗 Persistent knowledge across agents - facts, decisions, error fixes, gotchas survive across sessions, crashes, and agents. Start in Claude Code, continue in Codex CLI - zero context loss
🔍 Code intelligence - who calls what, what depends on what, what breaks if you rename a function. Tree-sitter AST parsing across 10+ languages, not grep
🤖 Subagent context compression - research subagents write findings to DB instead of dumping 40K+ tokens into parent context. Parent gets a 500-token summary + on-demand memory_search retrieval
⚡ 80-200K+ tokens saved per session - semantic search replaces file reads, subagent findings go to DB instead of context. Longer sessions with subagents save more
![]()
![]()
![]()
![]()
![]()
![]()
See the Difference
Without CogniLayer
You: "Fix the login bug"
Claude: Let me read the project structure...
Let me read src/auth/login.ts...
Let me read src/auth/middleware.ts...
Let me read src/config/database.ts...
Let me understand your auth flow...
(8 files read, 45K tokens burned, 2 minutes spent on orientation)
Claude: "Ok, I see the issue..."
With CogniLayer
You: "Fix the login bug"
Claude: [memory_search → "login auth flow"] → 3 facts loaded (200 tokens)
[code_context → "handleLogin"] → caller/callee map in 0.2s
Already knows: Express + Passport, JWT in httpOnly cookies,
last login bug was a race condition in session refresh (fixed 2 weeks ago)
Claude: "This looks like the same pattern as the session refresh issue
from March 1st. The fix is..."
That's not a small improvement. That's the difference between an agent that guesses and one that knows.
Real-World Examples
Debugging: "Why is checkout failing?"
Without CogniLayer, Claude reads 15 files to understand your e-commerce flow. With it:
memory_search("checkout payment flow")
→ fact: "Stripe webhook hits /api/webhooks/stripe, validates signature
with STRIPE_WEBHOOK_SECRET, then calls processOrder()"
→ gotcha: "Stripe sends webhooks with 5s timeout - processOrder must
complete within 5s or webhook retries cause duplicate orders"
→ error_fix: "Fixed duplicate orders on 2026-02-20 by adding
idempotency key check in processOrder()"
code_impact("processOrder")
→ depth 1: createOrderRecord, sendConfirmationEmail, updateInventory
→ depth 2: InventoryService.reserve, EmailQueue.push
→ "Changing processOrder will affect 6 functions across 4 files"
Claude already knows the architecture, the past bugs, and what will break if it touches the wrong thing. Instead of 15 file reads (~60K tokens), it uses 3 targeted queries (~800 tokens).
Code Intelligence: "What happens if I change processOrder?"
Without CogniLayer, Claude greps for the function name and hopes for the best. With it:
code_context("processOrder")
→ definition: src/services/order.ts:42
→ incoming (who calls it): StripeWebhookHandler.handle, OrderController.retry,
AdminPanel.reprocessOrder
→ outgoing (what it calls): createOrderRecord, sendConfirmationEmail,
updateInventory, PaymentLog.write
code_impact("processOrder")
→ depth 1 (WILL BREAK): StripeWebhookHandler, OrderController, AdminPanel
→ depth 2 (LIKELY AFFECTED): WebhookRouter, RetryQueue, AdminRoutes
→ depth 3 (NEED TESTING): 3 test files, 1 integration test
→ "Changing processOrder will affect 9 symbols across 7 files"
Before touching a single line, Claude knows the full blast radius - which files will break, which need testing, and which callers depend on the current behavior. No more surprise failures after a refactor.
Refactoring: "Rename UserService to AccountService"
code_search("UserService")
→ class UserService in src/services/user.ts (line 14)
→ 12 references across 8 files
code_impact("UserService")
→ depth 1: AuthController, ProfileController, AdminPanel (WILL BREAK)
→ depth 2: LoginRoute, RegisterRoute, middleware/auth (LIKELY AFFECTED)
→ depth 3: 4 test files (NEED UPDATING)
memory_search("UserService")
→ decision: "UserService handles both auth and profile - planned split
into AuthService + ProfileService (decided 2026-02-15, not yet done)"
Claude doesn't just find-and-replace. It knows there's a planned split and can suggest doing both changes at once - saving you a future refactoring session.
New session after a crash: "What was I working on?"
[SessionStart hook fires automatically]
→ bridge loaded: "Progress: Migrated 3/5 API endpoints to v2 format.
Done: /users, /products, /orders. Open: /payments, /shipping.
Blocker: /payments needs Stripe SDK v12 upgrade first."
memory_search("stripe sdk upgrade")
→ gotcha: "Stripe SDK v12 changed webhook signature verification -
verify() is now async, breaks all sync handlers"
Zero re-explanation. Claude picks up exactly where it left off, including the blocker you hadn't mentioned yet.
Subagent research: "What MCP frameworks exist?"
Without CogniLayer, the subagent returns a 40K-token dump into parent context:
Parent (200K context):
→ spawn subagent: "Research community MCP servers"
← subagent returns: 40K tokens about 15 projects
→ all 40K crammed into parent context
→ remaining: 160K → next subagent → 120K → next → 80K...
With CogniLayer's Subagent Memory Protocol:
Parent (200K context):
→ spawn subagent: "Research MCP servers, save to memory"
← subagent writes details to DB, returns: "Saved 3 facts,
search 'MCP server ecosystem'. Summary: Python dominates,
FastMCP most popular, 3 architectural patterns."
→ parent context: ~500 tokens
→ need details? memory_search("MCP server ecosystem") → targeted pull
40K tokens compressed to 500. The findings persist in DB across sessions - not just for this conversation, but forever.
Killer Features
| Feature | What it means |
|---|---|
| Code Intelligence | code_context shows who calls what. code_impact maps blast radius before you touch anything. Powered by tree-sitter AST parsing |
| Semantic Search | Hybrid FTS5 + vector search finds the right fact even with different wording. Sub-millisecond response |
| MCP Toolset | Memory, code analysis, safety, project context, and safe Codex orchestration helpers |
| Token Savings | 3 targeted queries (~800 tokens) replace 15 file reads (~60K tokens). Typical session saves 80-200K+ tokens |
| Subagent Protocol | Research subagents save findings to DB instead of flooding parent context. 40K → 500 tokens per subagent task |
| Crash Recovery | Session dies? Next one auto-recovers from the change log. Works across both agents |
| Cross-Project Knowledge | Solved a CORS issue in project A? Search it from project B. Your experience compounds |
| 14 Fact Types | Not dumb notes - error_fix, gotcha, api_contract, decision, pattern, procedure, and more |
| Heat Decay | Hot facts surface first, cold facts fade. Each search hit boosts relevance |
| Safety Gates | Identity Card system blocks deploy to wrong server. Audit trail on every safety change |
| Agent Interop | Claude Code and Codex CLI share the same brain. Switch agents mid-task, zero context loss |
| Session Bridges | Every session starts with a summary of what happened last time |
| TUI Dashboard | Visual memory browser with 8 tabs - see everything at a glance |
How It Works
You start a session
↓
SessionStart hook fires → injects project DNA, last session bridge, crash recovery
↓
You work normally - Claude saves facts, decisions, gotchas automatically via MCP tools
↓
You ask about code → code_context / code_impact answer in milliseconds from AST index
↓
Session ends (or crashes)
↓
Next session starts with full context - no re-reading, no re-explaining
Zero effort after install. No commands to learn, no workflow changes. CogniLayer runs in the background via hooks and MCP tools. Claude knows how to use it automatically.
Quick Start
1. Install (30 seconds)
git clone https://github.com/LakyFx/CogniLayer.git
cd CogniLayer
python install.py
That's it. Next time you start Claude Code, CogniLayer is active.
2. Optional: Turbocharge search
# AI-powered vector search (recommended - finds facts even with different wording)
pip install fastembed sqlite-vec
3. Optional: Add Codex CLI support
python install.py --codex # Codex CLI only
python install.py --both # Claude Code + Codex CLI
Codex installs static AGENTS instructions plus reusable workflow files in:
~/.cognilayer/codex/onboard.md
~/.cognilayer/codex/harvest.md
~/.cognilayer/codex/checkpoint.md
~/.cognilayer/codex/multi_agent_safe.md
4. Verify
python ~/.cognilayer/mcp-server/server.py --test
# → "OK: Registered <n> tools."
Troubleshooting
MCP server not connecting? Run the diagnostic tool:
python diagnose.py # Check everything
python diagnose.py --fix # Check + auto-fix missing dependencies
Requirements
- Python 3.11+
- Claude Code and/or Codex CLI
- pip packages:
mcp,pyyaml,textual(installed automatically),fastembed,sqlite-vec(optional),tree-sitter-language-pack(optional, for code intelligence)
Slash Commands (Claude Code only)
Once installed, use these in Claude Code:
| Command | What it does |
|---|---|
/status |
Show memory stats and project health |
/recall [query] |
Search memory for specific knowledge |
/harvest |
Extract and save knowledge from current session |
/onboard |
Scan your project and build initial memory |
/onboard-all |
Batch onboard all projects in your workspace |
/forget [query] |
Delete specific facts from memory |
/identity |
Manage deployment Identity Card |
/consolidate |
Organize memory - cluster, detect contradictions, assign tiers |
/tui |
Launch the visual dashboard |
/cognihelp |
Show all available commands |
Codex CLI users: Slash commands are not available in Codex. Instead, CogniLayer uses AGENTS.md instructions + MCP tools directly. See Codex CLI Integration below.
TUI Dashboard
A visual memory browser right in your terminal. 8 tabs, keyboard navigation, works on Windows, Mac, and Linux.
cognilayer # All projects
cognilayer --project my-app # Specific project
cognilayer --demo # Demo mode with sample data (try it!)
Overview - stats at a glance
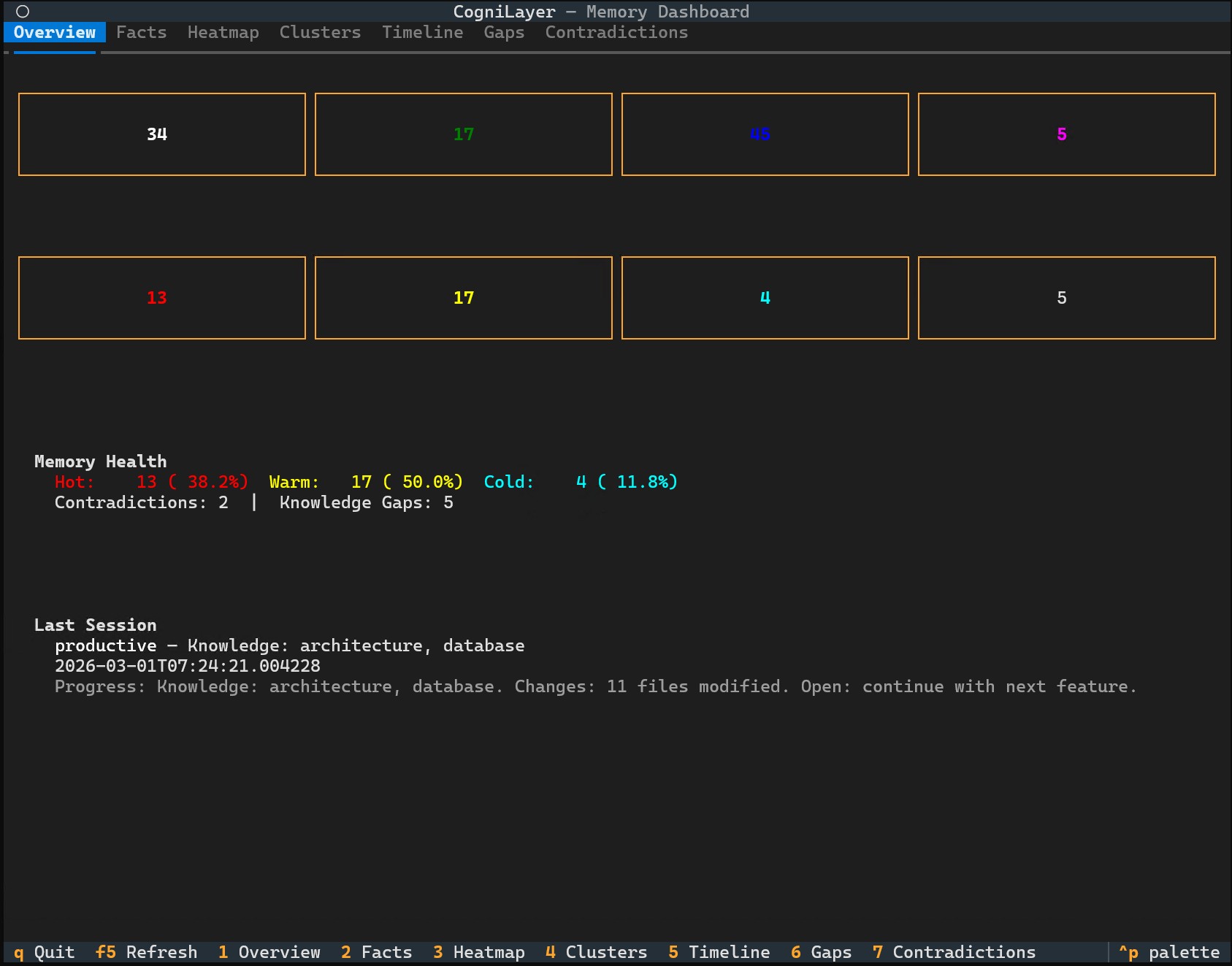
Facts - searchable, filterable, color-coded by heat
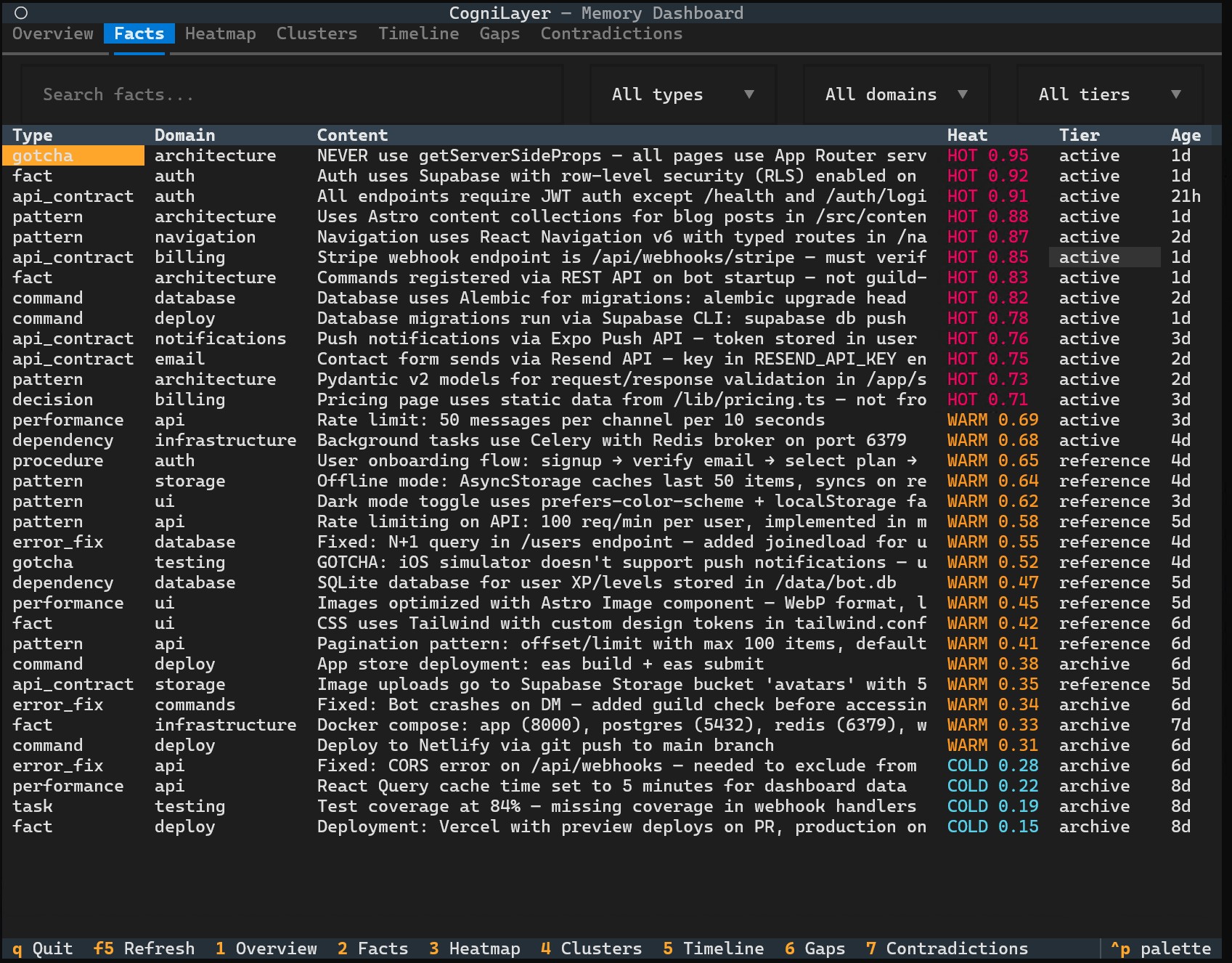
Heatmap - see which knowledge is hot, warm, or cold
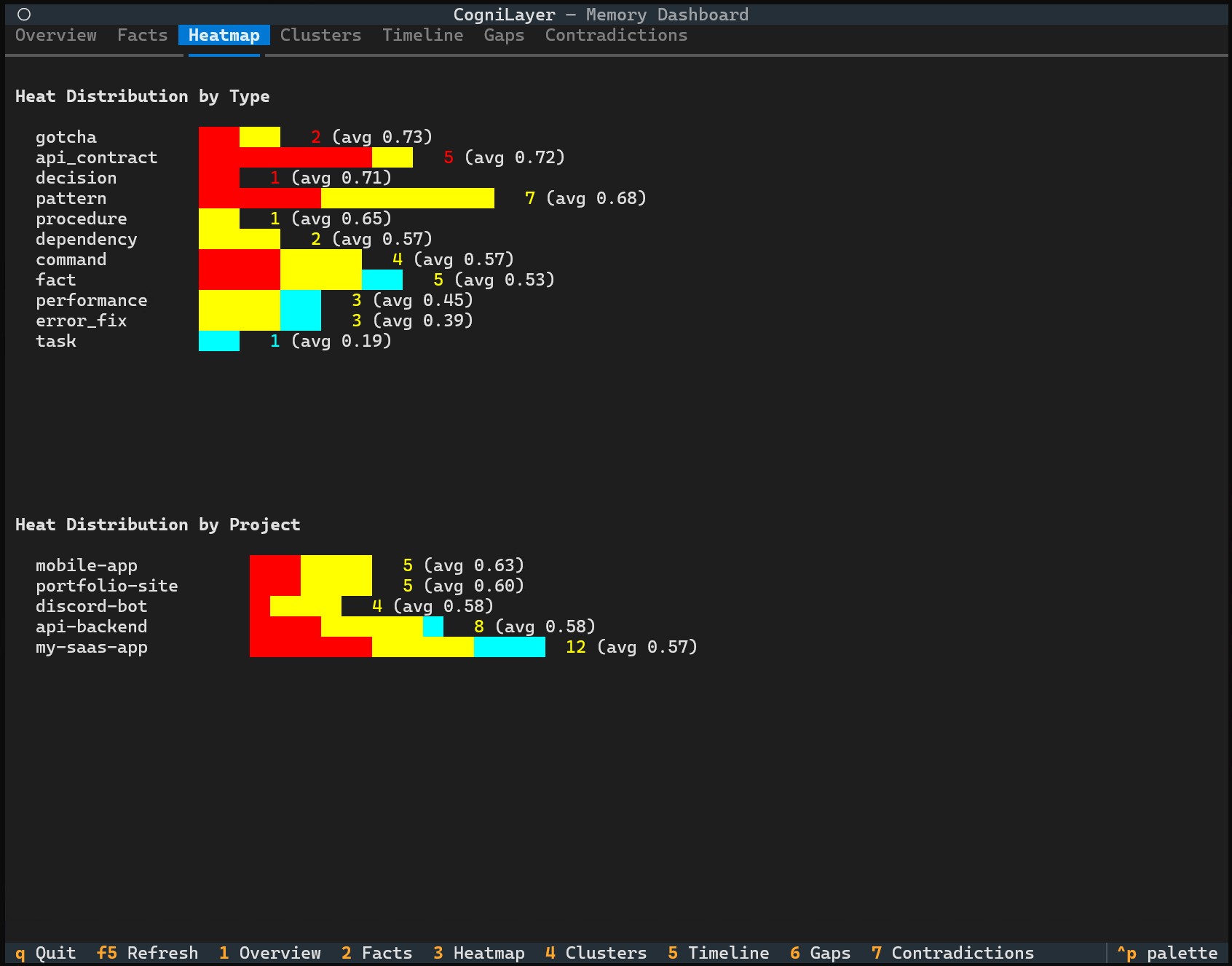
Clusters - related facts organized into groups
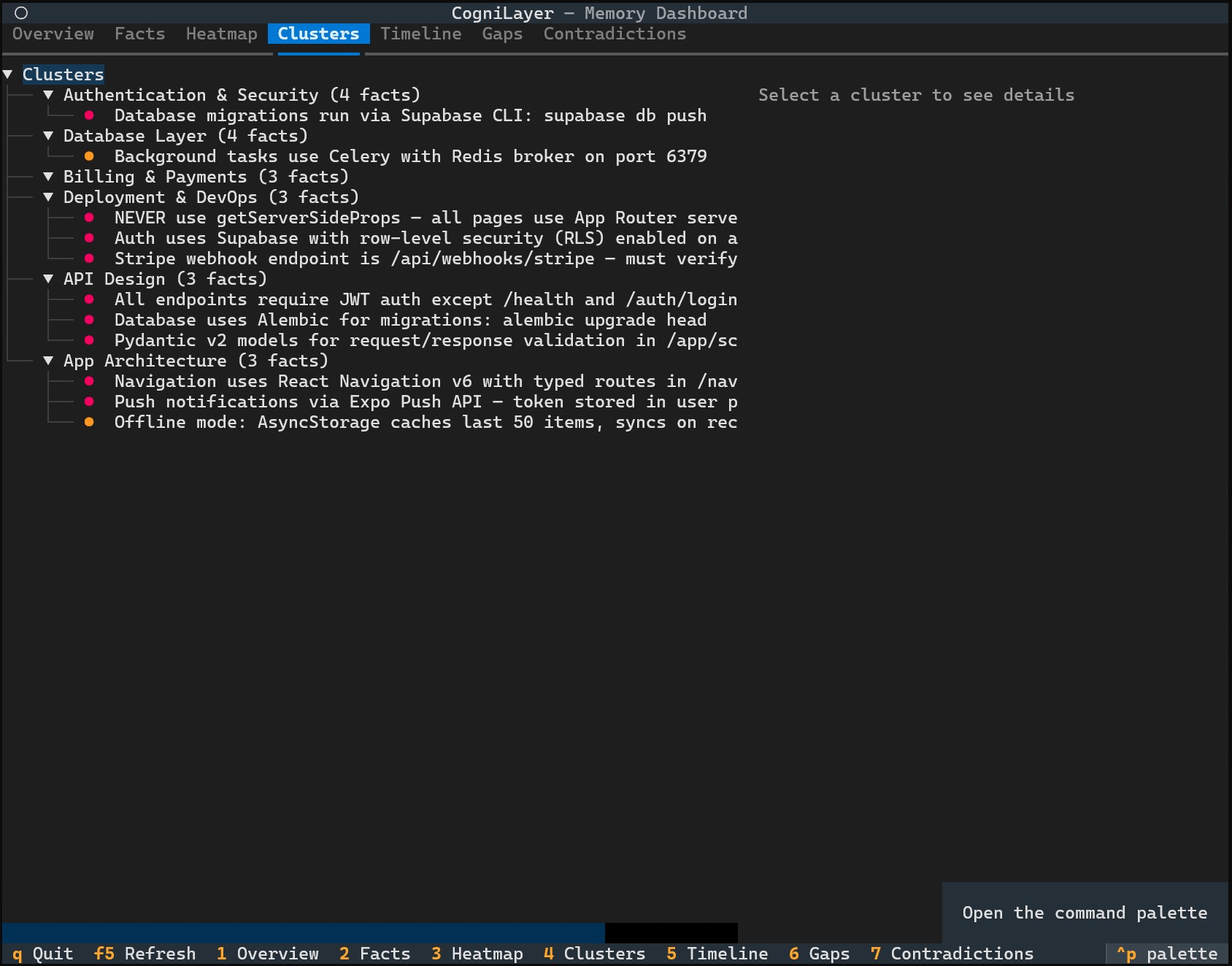
Timeline - full session history with outcomes
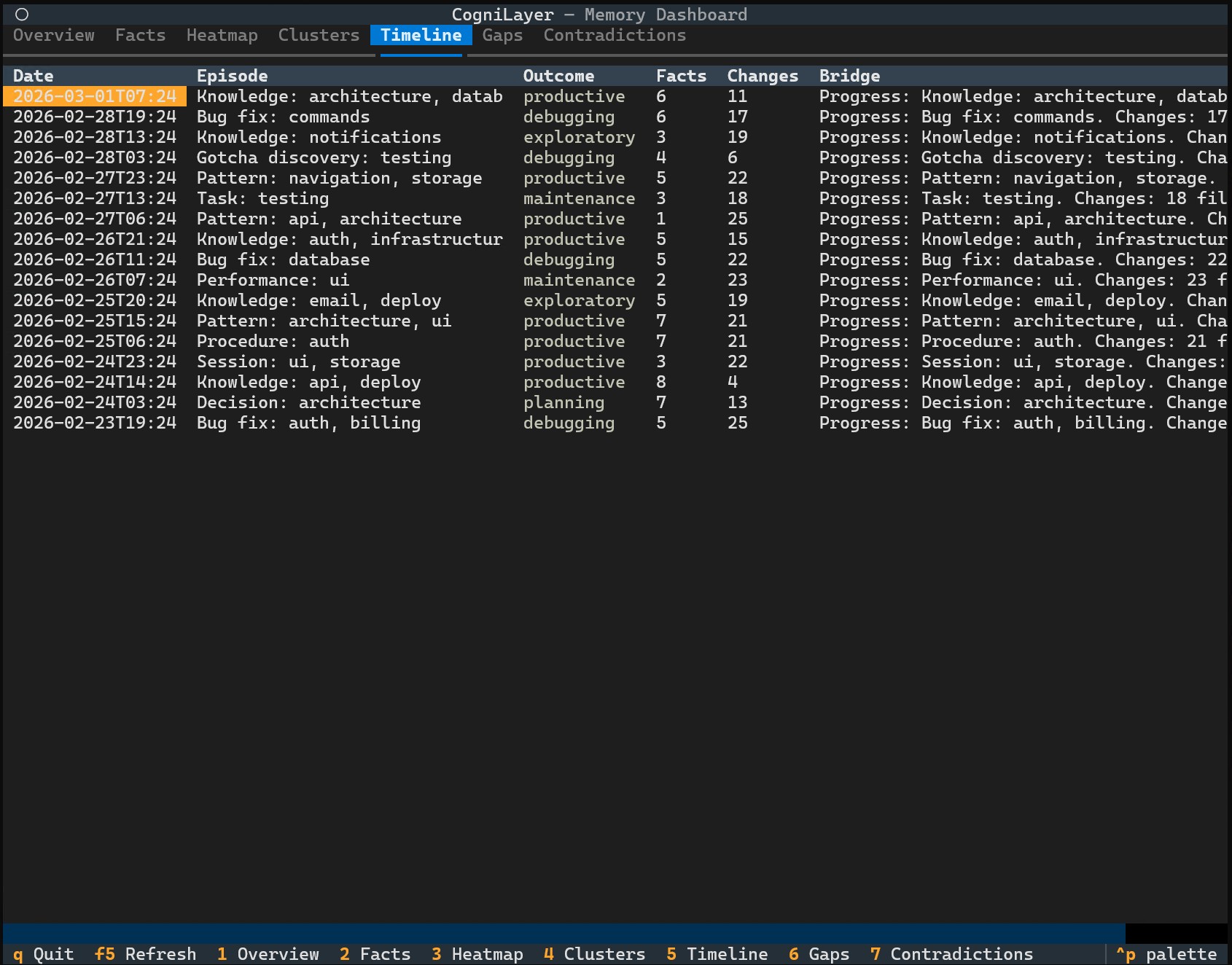
Screenshots show demo mode (cognilayer --demo) with sample data.
Upgrading
The upgrade is safe and non-destructive. Your memory is never lost:
git pull
python install.py
What happens under the hood:
- Code files are replaced with the latest versions
config.yamlis never overwritten (your settings are safe)memory.dbis backed up automatically before any migration- Schema migration is purely additive (new columns/tables, never deletions)
- CLAUDE.md blocks update automatically on next session start
Rollback
If something goes wrong:
# Your backup is timestamped
cp ~/.cognilayer/memory.db.backup-YYYYMMDD-HHMMSS ~/.cognilayer/memory.db
# Restore old code
git checkout <previous-commit> && python install.py
Configuration
Edit ~/.cognilayer/config.yaml:
# Language - "en" (default) or "cs" (Czech)
language: "en"
# Your projects directory
projects:
base_path: "~/projects"
# Indexer settings
indexer:
scan_depth: 3
chunk_max_chars: 2000
# Search defaults
search:
default_limit: 5
max_limit: 10
Known Limitations
- Concurrent CLIs: Running Claude Code and Codex CLI simultaneously on the same project may cause session tracking conflicts. Use one CLI at a time per project.
- Codex hooks: Codex CLI still has no native hook system, so hook-based session/file-change logging is not available there. Code intelligence queries can still self-refresh incrementally on demand.
- Code intelligence: Requires
tree-sitter-language-pack(~20MB). Without it, the memory, session, safety, and orchestration layers still work normally. - TUI: Requires
textualpackage. Read-only except for resolving contradictions.
Architecture (for the curious)
Everything below is for developers who want to understand how CogniLayer works under the hood.
System Overview
Claude Code / Codex CLI Session
│
├── SessionStart hook (Claude Code) / session_init tool (Codex)
│ └── Injects Project DNA + last session bridge into CLAUDE.md
│
├── MCP Server (memory + code intelligence + safe Codex orchestration)
│ ├── memory_search - Hybrid FTS5 + vector search with staleness detection
│ ├── memory_write - Store facts (14 types, deduplication, auto-embedding)
│ ├── memory_delete - Remove outdated facts by ID
│ ├── memory_link - Bidirectional Zettelkasten-style fact linking
│ ├── memory_chain - Causal chains (caused, led_to, blocked, fixed, broke)
│ ├── file_search - Search indexed project docs (chunked, not full files)
│ ├── file_index - Index project docs (README, configs, PRD) into file_chunks
│ ├── project_context - Get project DNA + health metrics
│ ├── session_bridge - Save/load session continuity summaries
│ ├── session_init - Initialize session for Codex CLI (replaces hooks)
│ ├── decision_log - Query append-only decision history
│ ├── verify_identity - Safety gate before deploy/SSH/push
│ ├── identity_set - Configure project Identity Card
│ ├── recommend_tech - Suggest tech stacks from similar projects
│ ├── code_index - Index codebase via tree-sitter AST parsing
│ ├── code_search - Find symbols (functions, classes, methods) by name
│ ├── code_context - 360° view: callers, callees, child methods
│ ├── code_impact - Blast radius analysis (BFS traversal of references)
│ └── Safe Codex orchestration
│ ├── agent_policy_read / agent_delegate_plan / agent_context_brief
│ ├── agent_run_start / agent_run_finish / agent_run_heartbeat / agent_run_list
│ ├── claim_scope / release_scope / list_claims
│ ├── agent_event_write / register_handoff / agent_handoff_inbox / agent_handoff_resolve
│ ├── agent_memory_stage / agent_memory_promote / agent_run_digest
│ └── agent_writer_run_start / agent_review_run_start / agent_research_wave_*
│
├── PostToolUse hook (Claude Code only)
│ └── Logs every file Write/Edit to changes table (<1ms overhead)
│
├── PreCompact hook (Claude Code only)
│ └── Saves comprehensive bridge before context compaction
│
└── SessionEnd hook / session_bridge(save)
└── Closes session, builds emergency bridge if needed
File Structure
~/.cognilayer/
├── memory.db # SQLite (WAL mode, FTS5, code graph + orchestration tables)
├── config.yaml # Configuration (never overwritten by installer)
├── active_session.json # Current session state (runtime)
├── mcp-server/
│ ├── server.py # MCP entry point (memory, code intelligence, orchestration)
│ ├── db.py # Shared DB helper (WAL, busy_timeout, lazy vec loading)
│ ├── i18n.py # Translations (EN + CS)
│ ├── init_db.py # Schema creation + migration
│ ├── embedder.py # fastembed wrapper (BAAI/bge-small-en-v1.5, 384-dim)
│ ├── register_codex.py # Codex CLI config.toml registration
│ ├── indexer/ # File scanning and chunking
│ ├── search/ # FTS5 + vector hybrid search
│ ├── code/ # Code Intelligence (tree-sitter parsers, indexer, resolver)
│ └── tools/ # MCP tool implementations
├── hooks/
│ ├── on_session_start.py # Project detection, DNA injection, crash recovery
│ ├── on_session_end.py # Session close, emergency bridge, episode building
│ ├── on_file_change.py # PostToolUse file change logger + context monitoring
│ ├── on_pre_compact.py # PreCompact bridge preservation
│ ├── generate_agents_md.py # Codex AGENTS.md generator
│ └── register.py # Claude Code settings.json registration
├── tui/ # TUI Dashboard (Textual)
│ ├── app.py # Main application (8 tabs, keyboard nav)
│ ├── data.py # Read-only SQLite data access layer
│ ├── styles.tcss # CSS stylesheet
│ ├── screens/ # 8 tab screen modules
│ └── widgets/ # Heat cell, stats card widgets
└── logs/
└── cognilayer.log
Database Schema (selected core tables)
| Table | Purpose |
|---|---|
projects |
Registered projects with auto-generated DNA |
facts |
14 types of atomic knowledge units with heat scores |
facts_history / memory_brief_cache |
Fact version history and cached compact retrieval summaries |
facts_fts |
FTS5 fulltext index on facts |
file_chunks |
Indexed project documentation (PRDs, READMEs, configs) |
chunks_fts |
FTS5 fulltext index on chunks |
decisions |
Append-only decision log |
sessions |
Session records with bridges, episodes, and outcomes |
session_state |
Active runtime session snapshot used across tool calls and restarts |
changes |
Automatic file change log (PostToolUse) |
project_identity |
Identity Card (SSH, ports, domains, safety locks) |
identity_audit_log |
Safety field change audit trail |
tech_templates |
Reusable tech stack templates |
fact_links |
Zettelkasten bidirectional links between facts |
knowledge_gaps |
Tracked weak/failed searches |
fact_clusters |
Memory consolidation output clusters |
contradictions |
Detected conflicting facts |
causal_chains |
Cause → effect relationship tracking |
retrieval_log |
Search quality tracking (queries, hit counts, latency) |
code_files |
Indexed source files with hash-based change detection |
code_symbols |
AST-parsed symbols (functions, classes, methods, interfaces) |
code_references |
Symbol cross-references (calls, imports, inheritance) |
agent_runs / agent_claims |
Safe multi-agent run registry and single-writer scope claims |
agent_handoffs / agent_events |
Durable handoff ledger and run event timeline |
schema_version |
Schema migration state |
facts_vec / chunks_vec |
Vector embeddings (sqlite-vec, optional) |
Hybrid Search
Two search engines combined for maximum recall:
- FTS5 - SQLite fulltext search for exact keyword matching
- Vector embeddings - fastembed (BAAI/bge-small-en-v1.5, 384-dim, CPU-only ONNX) with sqlite-vec for cosine similarity
- Hybrid ranker - 40% FTS5 + 60% vector similarity, with heat score boosting
Vector search is optional - FTS5 works standalone without any extra dependencies.
Heat Decay
Facts have a "temperature" that models relevance over time:
| Range | Label | Meaning |
|---|---|---|
| 0.7 - 1.0 | Hot | Recently accessed, high relevance |
| 0.3 - 0.7 | Warm | Moderately recent |
| 0.05 - 0.3 | Cold | Old, rarely accessed |
Decay rates vary by fact type - error_fix and gotcha facts decay slower (they stay relevant longer) than task facts. Each search hit boosts a fact's heat score.
Code Intelligence
Powered by tree-sitter AST parsing with language-pack support for 10+ languages:
| Tool | What it does |
|---|---|
code_index |
Scans project files, parses AST, extracts symbols and references into SQLite. Incremental - only re-indexes changed files |
code_search |
FTS5 search over symbol names. Find any function, class, or method by name or partial match |
code_context |
360° view of a symbol: definition, who calls it (incoming), what it calls (outgoing), child methods |
code_impact |
Blast radius analysis - BFS traversal of incoming references. Shows what breaks at depth 1/2/3 |
Indexing runs with a configurable time budget (default 30s). Partial results are usable immediately. Unresolved references are re-resolved on the next incremental run.
Recent accuracy/freshness improvements in the current implementation:
- incremental indexing prunes deleted files instead of leaving dead symbols behind
code_search,code_context, andcode_impacttrigger a safe incremental refresh before answering, which keeps Codex CLI flows usable even without hooks- reference resolution is more stable when projects contain duplicate symbol names, especially for Python relative imports
Subagent Memory Protocol
When Claude spawns research subagents, the raw findings can be 40K+ tokens. Without the protocol, all of that goes into the parent's context window. The Subagent Memory Protocol uses the CogniLayer database as a side channel:
Subagent Parent
│ │
├── research (WebSearch, Read...) │
├── synthesize findings │
├── memory_write(consolidated facts) │ ← data goes to DB, not context
└── return: 500-token summary ────────┤ ← only summary enters context
│
memory_search() ──┤ ← parent pulls details on demand
Key design decisions:
- Synthesis over granularity - subagents group related findings into cohesive facts, not one-per-discovery
- Task-specific tags - each subagent gets a unique tag (e.g.
tags="subagent,auth-review") for filtering viamemory_search(tags="auth-review") - Keywords inside facts - each fact ends with
Search: keyword1, keyword2so retrieval works even after context compaction - Write-last pattern - all
memory_writecalls happen as the last step before return, saving subagent turns and tokens - Foreground-first - subagents launch as foreground (reliable MCP access), user can Ctrl+B to background
- Graceful fallback - if MCP tools are unavailable, findings go directly in return text
The protocol is injected into CLAUDE.md automatically and requires no user configuration.
Codex CLI Integration
Codex CLI has no hook system, so CogniLayer adapts:
| Aspect | Claude Code | Codex CLI |
|---|---|---|
| Config | ~/.claude/settings.json |
~/.codex/config.toml |
| Hooks | SessionStart/End/PreCompact/PostToolUse | None - uses MCP tools + static AGENTS.md + Codex workflows |
| Instructions | CLAUDE.md |
AGENTS.md (generated by generate_agents_md.py) |
| Session init | Automatic via hook | session_init MCP tool called per AGENTS.md instructions |
| Onboarding | /onboard slash command |
~/.cognilayer/codex/onboard.md + MCP tools |
| Harvest | /harvest slash command |
~/.cognilayer/codex/harvest.md + MCP tools |
| File tracking | Automatic via PostToolUse | No hook-based change log, but code intelligence tools can refresh incrementally on query |
Same memory database shared between both CLIs.
Codex onboarding workflow
AGENTS.md stays static on purpose and tells Codex to load runtime context via session_init().
For first-run onboarding, Codex should open ~/.cognilayer/codex/onboard.md and follow it:
session_init()- register project, load DNA + bridgefile_index()- index documentation files sofile_searchworkscode_index()- index source code socode_search/context/impactwork- Read key files and save findings via
memory_write()(the AI does intelligent analysis)
For end-of-session knowledge capture, Codex should use ~/.cognilayer/codex/harvest.md.
For a lightweight handoff before context loss, use ~/.cognilayer/codex/checkpoint.md.
Safe multi-agent orchestration is available for Codex too, but it is opt-in and OFF by default:
codex:
multi_agent:
enabled: false
mode: "off" # off | research_only | safe
After enabling it in ~/.cognilayer/config.yaml, Codex should check agent_policy_read() and then follow ~/.cognilayer/codex/multi_agent_safe.md for supervisor-driven delegation, staged memory, and write-claim rules.
Current safe multi-agent helper surface includes:
- run lifecycle:
agent_run_start,agent_run_finish,agent_run_heartbeat,agent_run_list - safety and ownership:
claim_scope,release_scope,list_claims,agent_delegate_plan - context + evidence packets:
agent_context_brief,agent_run_digest - explicit coordination:
register_handoff,agent_handoff_inbox,agent_handoff_resolve - staged memory flow:
agent_memory_stage,agent_memory_promote - opinionated workflows:
agent_writer_run_start,agent_review_run_start,agent_research_wave_start,agent_research_wave_collect,agent_research_wave_finalize
This matches what /onboard and /harvest do in Claude Code, but through Codex workflow files instead of slash commands.
Project Identity Card
Deployment safety system that prevents "oops, wrong server" incidents:
- Safety locking - locked fields require explicit update + audit log entry
- Hash verification - SHA-256 detects tampering of safety-critical fields
- Required field checks -
verify_identityblocks deploy if critical fields are missing - Audit trail - every safety field change is logged with timestamp and reason
Contributing
Contributions are welcome! Please open an issue first to discuss what you'd like to change.
License
Elastic License 2.0 - Free to use, modify, and distribute. You may not provide it as a managed/hosted service.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found