BYO-WIKI
Health Warn
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 237 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Build your own LLM-native knowledge library. Search, extract, summarize, Q&A with contextual RAG, layered knowledge graph, and reinforced memory. Most importantly you can use selected context to generate skills empowered by Claude subagents + CodeAct pipeline and gated by human review.
Build Your Own WIKI
Turn the web, your files, and loose notes into a personal wiki that an LLM agent
keeps coherent: search and summarize pages, ingest them into a contextual vector
index for grounded, cited Q&A, and grow a layered knowledge graph that de-duplicates
entities, builds topics, and writes synthesis pages. One Flask app — web UI, JSON API,
and a runner.py CLI. Inspired by LangChain's llm-wiki deep-agents example, but it
builds a private, on-disk library instead of syncing to a hub. Local-first: every
store is plain JSON/SQLite under data/; cloud is opt-in.
Features
- Agentic knowledge graph — a
deepagents
agent (local filesystem backend, no cloud sandbox) saves passages, extracts entities
and typed relations, canonicalizes duplicates, nests topics, and writes synthesis pages. - Contextual RAG — Anthropic-style contextual retrieval over a two-layer HNSW index
(section summaries + chunks), with an LLM re-ranker (precision) or document-aware MMR
(multi-doc recall). Answers are grounded and cited. - Memory — a cross-session store recalled before every answer and written back
after (observations, 👍/👎, corrections that supersede stale notes); it improves from
use, not just ingestion. - Agent skills — turn selected context into a reusable, evaluated skill via a
sub-agent pipeline (understand → analyze → author → eval → gate → refine). Authored by
the latest Claude in-process or via the Claude Code CLI as a subprocess, scored by a
deterministic + rubric panel, and gated behind human review before it joins the
library — optionally as a durable LangGraph build that pauses at the gate and resumes later. - MCP, both directions — connect agents to external MCP servers (Supabase, GitHub, …)
and run BYO-WIKI as an MCP server. Reads join the agent; writes are deny-by-default.
Architecture
flowchart TB
subgraph IF["Interfaces"]
direction LR
UI["Web UI · Flask"]
API["JSON API · /api"]
CLI["CLI · runner.py"]
end
ING["Ingestion pipeline<br/>fetch · clean · contextual summaries<br/>chunk · embed · entity / relation / topic extraction"]
subgraph STORE["Stores · local-first under data/"]
direction LR
KG[("Knowledge graph · layers 0–5<br/>source · section · chunk<br/>entity · topic · synthesis")]
VEC[("HNSW index<br/>section summaries + chunks")]
MEM[("Memory · layer 6")]
SKL[("Skill library · layer 7")]
end
subgraph REASON["Reasoning"]
direction LR
RAG["Contextual RAG<br/>retrieve → re-rank / MMR → cite"]
AGENT["Curating agent · deepagents<br/>ingest · query · lint"]
SKILL["Agent-skill loop · LangGraph<br/>author → eval → gate → human review"]
end
IF --> ING
IF --> REASON
ING --> KG
ING --> VEC
VEC --> RAG
RAG --> EMB["Embeddings · OpenAI"]
RAG <--> MEM
KG <--> AGENT
AGENT <--> MEM
AGENT <--> MCP["External MCP servers<br/>Supabase · GitHub · fetch<br/>reads join agent · writes gated"]
SKILL --> SKL
SKILL --> KG
SKILL --> MCP
REASON --> LLM["LLM providers<br/>Claude · OpenAI · Qwen<br/>DeepSeek · Gemini · Mistral"]
REASON -.->|offline metrics| EVAL["Evaluation<br/>hit@k · MRR · recall<br/>RAGAS · 5-family judge panel"]
REASON -.->|live run traces| OBS["Observability<br/>LangSmith · OpenTelemetry"]
Everything above the stores is stateless; all state lives in data/ (JSON graph,
HNSW vectors, SQLite checkpoints), so the app is reproducible and local-first. The JSON
API can also be exposed as an MCP server (reads open, writes deny-by-default).
Evaluation and observability are different planes — don't conflate them. Evaluation
measures quality offline: deterministic retrieval metrics (hit@k · MRR · recall),
RAGAS (faithfulness · answer-relevancy · context-precision, wrapped as LangSmith
evaluators in ragas_eval.py), and a 5-family LLM-judge panel calibrated against human
labels. Observability traces live runs — agent, RAG, and skill builds — to
LangSmith and, optionally, OpenTelemetry. RAGAS is an evaluator, not a tracer.
How the curating agent works
A deepagents agent drives four modes
(init · ingest · query · lint) as a recursion-limited reason↔act loop over a local
filesystem backend. Its tools read and write the knowledge graph, recall memory before
an answer and write it back after, look up skills, and call external MCP read tools.query grounds cited answers through contextual RAG; ingest/lint canonicalize
duplicates, nest topics, and write synthesis pages.
flowchart TB
subgraph DRIVE["Entry points · Web UI · /api · runner.py"]
direction LR
INIT["init<br/>scaffold"]
INGEST["ingest<br/>organize new material"]
QUERY["query<br/>cited answer"]
LINT["lint<br/>maintain library"]
end
DRIVE --> REASON
subgraph LOOP["deepagents · local filesystem backend"]
REASON["reason ↔ act loop<br/>(recursion-limited)"]
KGRW["KG tools<br/>search · upsert · merge<br/>relate · nest topics · synthesize"]
MEMT["Memory tools<br/>recall before · write after"]
SKT["Skill lookup"]
MCPR["MCP read tools"]
REASON <--> KGRW
REASON <--> MEMT
REASON <--> SKT
REASON <--> MCPR
end
KGRW <--> KG[("Knowledge graph<br/>layers 0–5")]
MEMT <--> MEM[("Memory · layer 6")]
QUERY -.->|grounds answers| RAG["Contextual RAG<br/>retrieve → re-rank / MMR"]
RAG --> VEC[("HNSW index")]
RAG --> KG
Skill builds run as a durable LangGraph
The skill loop has two interchangeable runtimes over the same phase functions: a linear
in-process pipeline (SKILL_BACKEND=pipeline), or a LangGraph StateGraph
(skill_graph.py) that adds conditional gating, a durable human-review interrupt(), and
checkpointing (SQLite / Postgres / memory). Each phase is authored either in-process or by
the Claude Code CLI as a subprocess (generate_cc). The gate never finalizes alone —
it lands a draft in pending_review; only a human promotes it. Pause at the gate,
checkpoint, and resume in another process by thread_id. Every build/eval/refine is traced
to LangSmith (parent run + per-phase children) and, optionally, OpenTelemetry.
stateDiagram-v2
direction TB
[*] --> gather
gather --> understand: backend = pipeline
gather --> generate_cc: backend = claude_code
understand --> analyze
analyze --> codeact
codeact --> evaluate
generate_cc --> evaluate
evaluate --> human_review: pass gate, pending_review
evaluate --> [*]: reject
human_review --> finalize: accept
human_review --> prepare_revision: revise + notes
human_review --> [*]: reject
prepare_revision --> codeact: pipeline
prepare_revision --> generate_cc: claude_code
finalize --> [*]
note right of evaluate
deterministic checks (11)
+ 5-family rubric panel
end note
note right of human_review
interrupt() pauses + checkpoints
(SQLite / Postgres / memory)
resume by thread_id, survives restart
end note
Quick start
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt # add `ragas` for RAGAS metrics
cp .env.example .env # set at least one provider key
python app.py # → http://localhost:5000
Both app.py and runner.py auto-load .env. RAG needs OPENAI_API_KEY for
embeddings (text-embedding-3-small) regardless of chat provider — Anthropic has no
embeddings API.
How it works (the critical bits)
The graph is layered, not a flat entity bag. Nodes climb source → section → chunk → entity → topic → synthesis → memory → agent_skill (layers 0–7), joined by typed edges
(mentions, relation, belongs_to, subtopic_of, …). The KG tab renders three
granularities (document / section / chunk).
Retrieval is vector-only — on purpose. Each section gets one LLM-written contextual
summary; chunks are embedded with title · date · section prepended into a two-layer
HNSW index. Retrieval ranks sections, drills into chunks, then re-ranker or MMR picks
top-k. Entity-graph traversal was built, evaluated, and removed — MMR beat it on
recall and judged synthesis. The graph earns its keep in construction
(canonicalization, topics, provenance) and presentation (concept maps), not retrieval.
Skills are gated. A drafted skill must clear deterministic checks (usable
description, ≥2 steps, positive and negative triggers, declared tools, no placeholders)
and a cross-family rubric judge panel — but the gate never finalizes alone: it lands inpending_review and only a human promotes it. Every build/eval/refine is logged with
per-phase timings, tokens, and triggering precision/recall; refine rebuilds a skill from
its measured weaknesses. Optionally runs as a LangGraph StateGraph where human review is
a durable interrupt() — pause at the gate, checkpoint, resume in another process.
Evaluation
All numbers come from a version-controlled 28-doc corpus (eval/corpus_urls.txt, LangChain
- Anthropic articles). Deterministic retrieval metrics are the most comparable across runs;
absolute LLM-judge scores are judge-dependent, so judging uses a 5-family panel
(gpt-5.2 · qwen3.7-plus · deepseek-v4-flash · gemini-3.5-flash · mistral-large-2512) and
reportsjudge_alignmentagainst human labels.
| Setting | Metric | Result |
|---|---|---|
| Single-doc, re-ranked | hit@6 / MRR | 0.87 / 0.81 |
| Re-ranker off → on | RAGAS context precision | 0.51 → 0.67 |
| Cross-doc, base → MMR | retrieval recall | 0.59 → 0.91 |
| Cross-doc, MMR vs. graph-RAG | retrieval recall | 0.909 vs. 0.788 |
| Cross-doc, synthesis-prompt fix | RAGAS answer relevancy | 0.65 → 0.90 |
MMR winning on recall and synthesis is why graph-RAG was dropped; the relevancy jump
came from letting the generator synthesize across passages instead of refusing when no
single chunk states the connection.
Interfaces
Web UI — tabs for Read (search / fetch+extract / summarize / save-to-KG), Knowledge
Graph (ingest, browse the layer-colored graph, Integrate / Ask / Maintain), Library Q&A
(cited answers, re-ranker/MMR toggles), Memory, and Agent Skills (build, watch the
eval/gate report, accept/revise/reject; toggle durable ⛓ for a checkpointed LangGraph build).
HTTP API — under /api: read · kg · agent · memory · rag · skill · mcp.
CLI (runner.py --mode …):
init · ingest · query · lint # knowledge-graph workspace
memory-add · memory-recall · memory-list # cross-session memory
skill-build · skill-pending · skill-review · skill-refine · skill-observability
skill-graph-build · skill-graph-resume # durable, pause-at-review build
rag-ingest · rag-ask · rag-eval · rag-experiment · rag-ragas · rag-crossdoc
mcp-list · mcp-ingest · mcp-call · mcp-serve # MCP client + serve-as-server
Common flags: --provider, --model, --rerank/--no-rerank, --mmr, --no-agent.
Screenshots
The web UI in action — one image per tab.
Read — search / fetch + extract / summarize / save-to-KG.
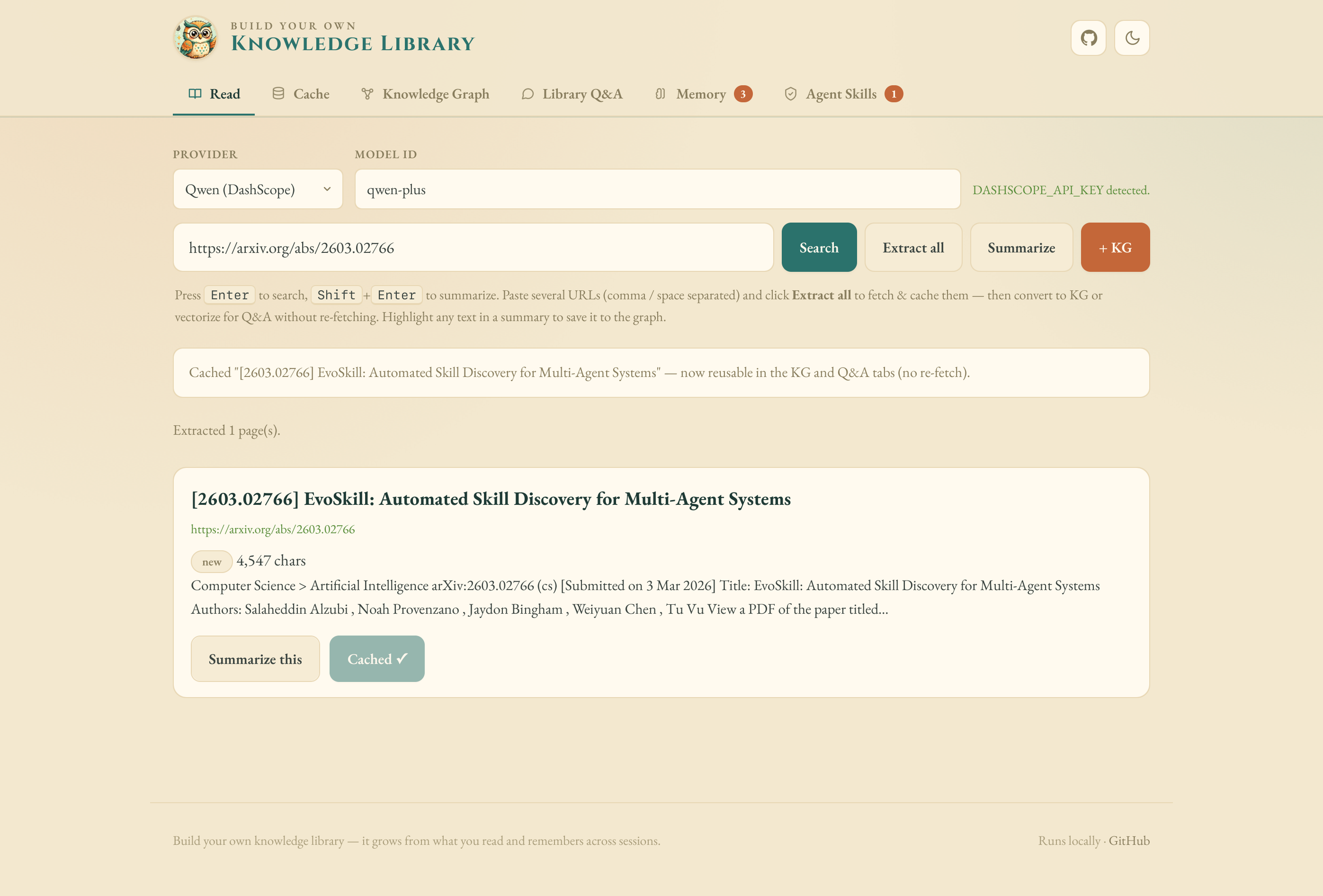
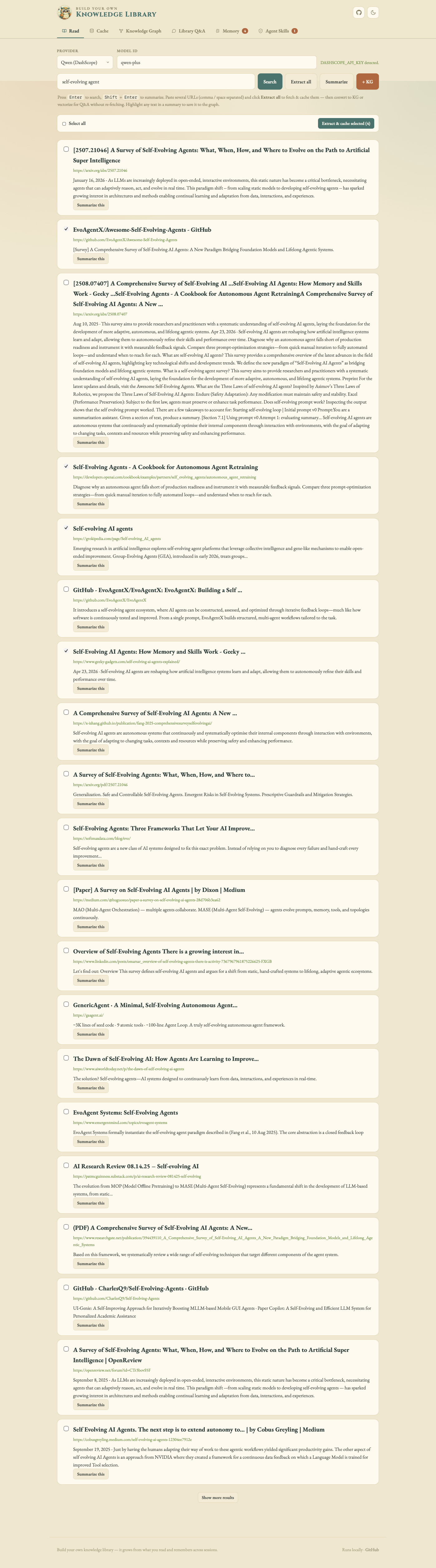
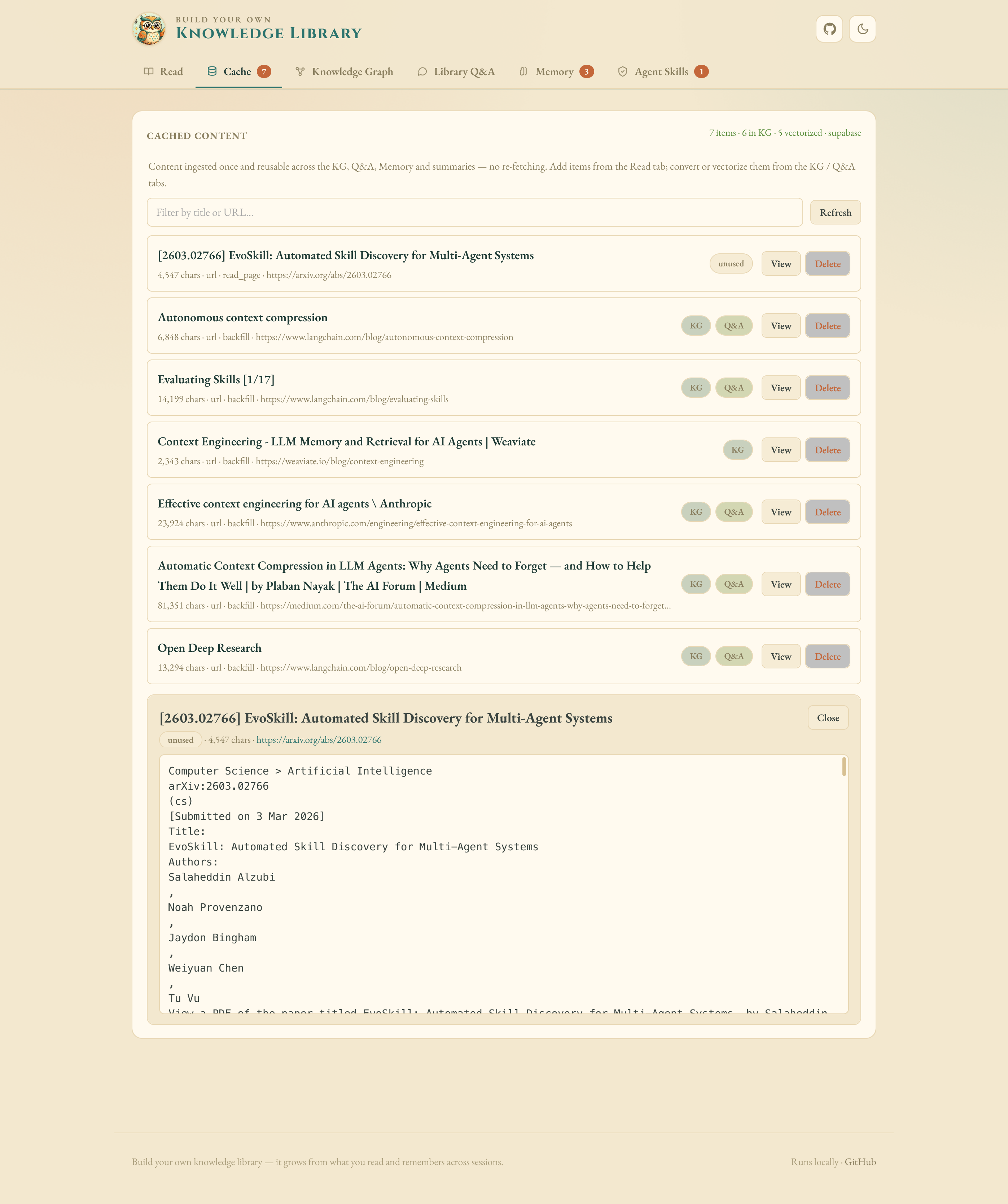
Cache — reuse extracted content across the KG, Q&A and Memory without re-fetching.
Knowledge Graph — ingest, browse the layer-colored graph, Integrate / Ask / Maintain.
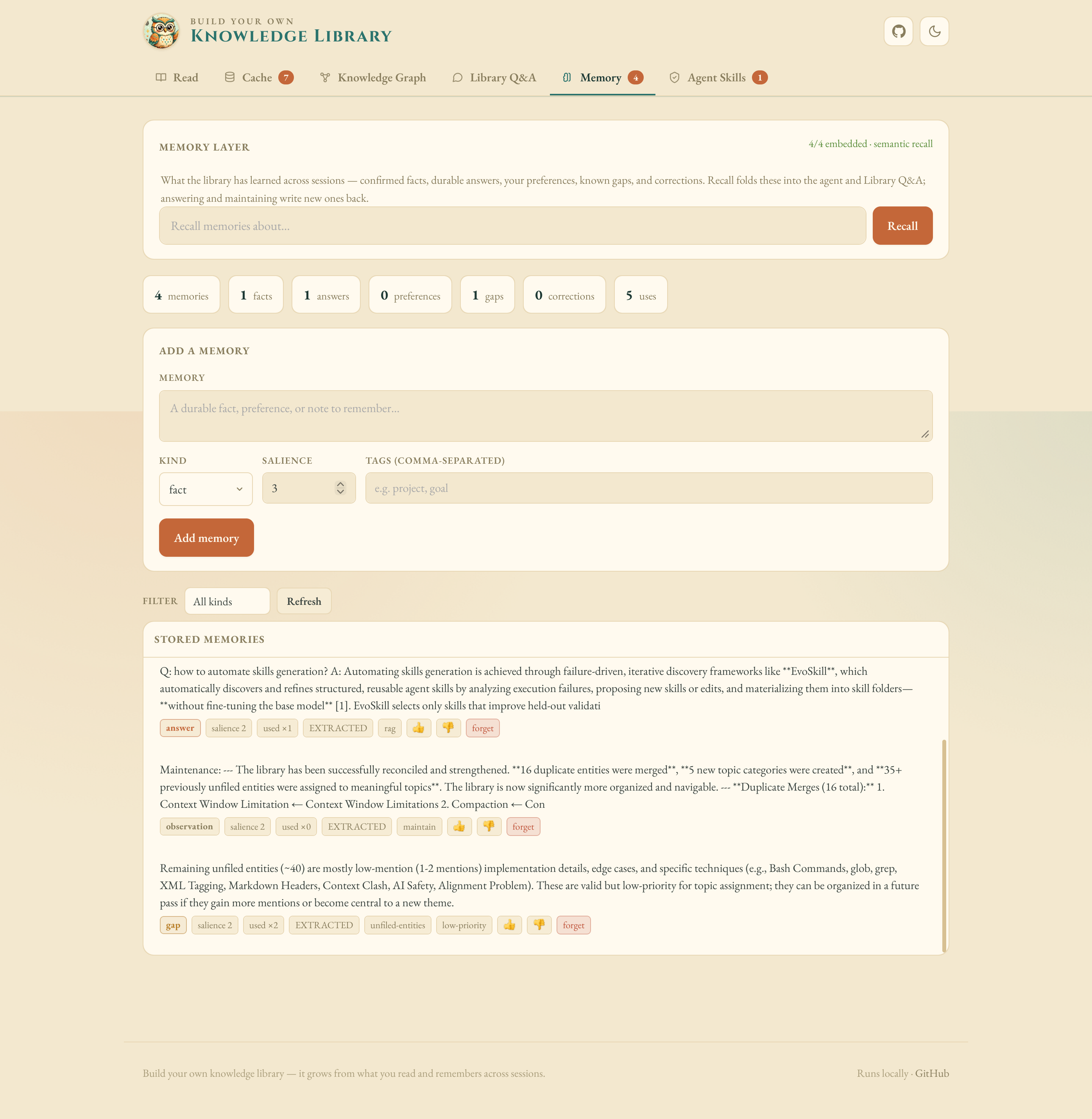
Memory — cross-session store recalled before every answer and written back after.
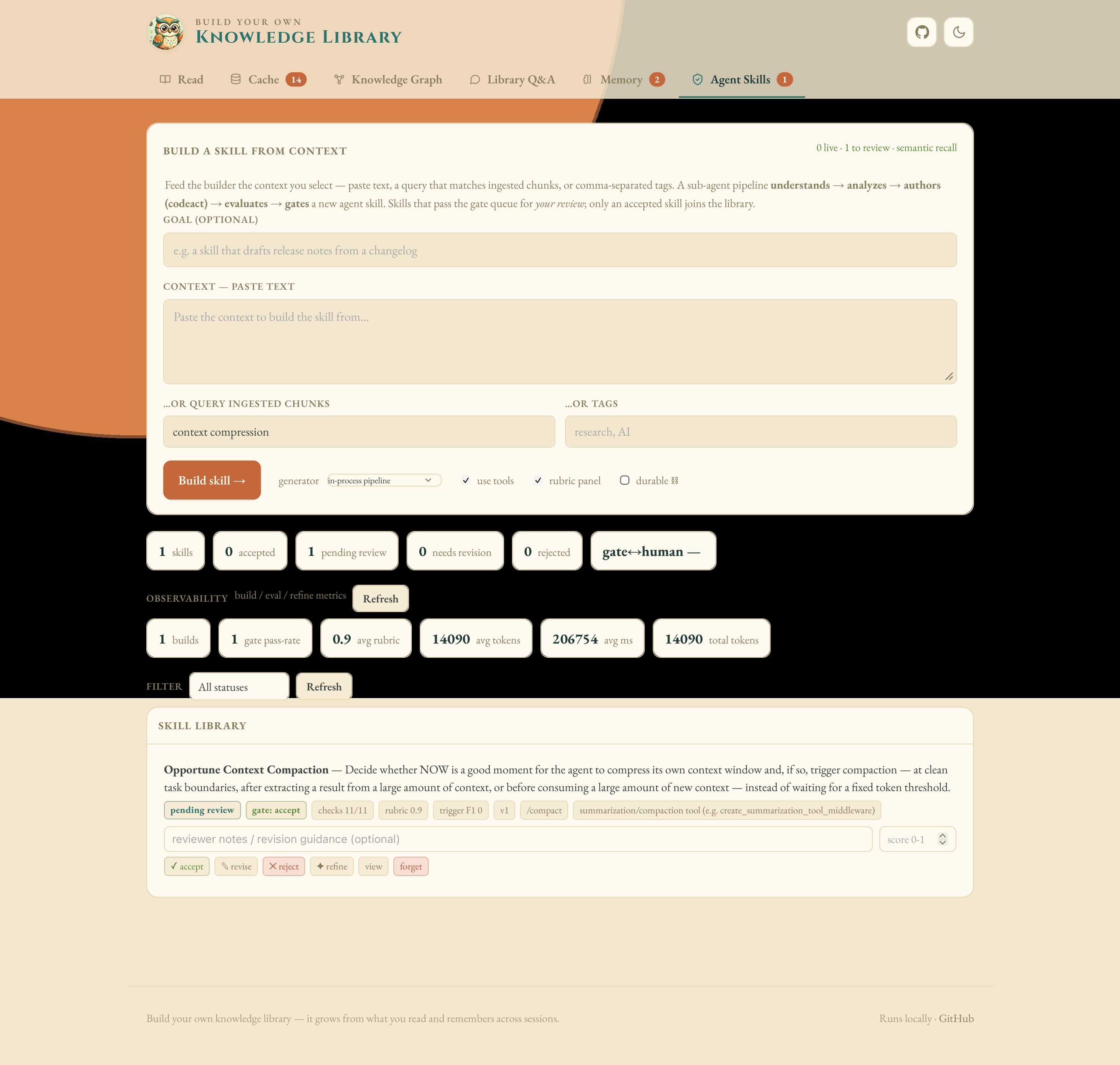
Agent Skills — build, watch the eval/gate report, accept/revise/reject.
Connecting tools (MCP)
Agents can call external MCP servers, and BYO-WIKI can run as one — both opt-in and
local-first. Enable servers with MCP_ENABLED; read tools join the curating agent and the
skill-builder, and mcp-ingest stages a read tool's output into the KG. Writes are
deny-by-default: a write runs only via /api/mcp/write (or mcp-call --confirm) withMCP_ALLOW_WRITES=1 and explicit human approval, and the client gate tracks the server's
own read_only scope so the two never drift. The hosted Supabase MCP is HTTPS, so it works
even where direct Postgres is blocked.
pip install langchain-mcp-adapters mcp
export MCP_ENABLED=supabase SUPABASE_ACCESS_TOKEN=… SUPABASE_PROJECT_REF=…
python runner.py --mode mcp-list
See docs/mcp-proposal.md for the full design.
Configuration
Provider keys live in .env (gitignored — never commit real keys); see .env.example for
the complete list. Common extras:
| Variable | Purpose |
|---|---|
LANGSMITH_TRACING / LANGSMITH_API_KEY |
enable + authenticate LangSmith tracing/eval. |
KG_DATA_DIR |
store directory (default data/). |
SKILL_GATE_ACCEPT / SKILL_GATE_REJECT / SKILL_DET_PASS |
skill-gate thresholds. |
SKILL_BACKEND |
skill generator: pipeline (in-process) or claude_code (CLI subprocess). |
SKILL_GRAPH_CHECKPOINT |
LangGraph checkpoints: sqlite (default) / postgres / memory. |
MCP_ENABLED / MCP_ALLOW_WRITES |
enable external MCP servers; allow (gated) writes. |
PORT |
bind port (default 5000). |
Project layout
app.py / runner.py Flask app (UI + API) / CLI
agent.py kg_tools.py deepagents harness + graph tools
knowledge_graph.py multi-layer graph store + queries
ingestion.py extraction.py enrich.py chunking · entity/relation/topic extraction
pipeline.py embeddings.py vectorstore.py contextual ingest + HNSW + MMR
rag.py rag_experiment.py ragas_eval.py crossdoc.py retrieval, answers, eval suite
memory.py memory_tools.py cross-session memory (layer 6)
skill_*.py agent-skill build loop, eval/gate, observability, LangGraph (layer 7)
mcp_config.py mcp_tools.py mcp_server.py MCP client (gated) + BYO-WIKI as an MCP server
providers.py config.py provider table + judge selection; .env / LangSmith
eval/ static/ templates/ data/ corpus + datasets; UI; local stores
Credits
Inspired by LangChain's llm-wiki deep-agents example. Built with Flask,deepagents/LangChain, hnswlib, OpenAI embeddings, RAGAS, and LangSmith.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found