inalpha
Health Warn
- License — License: AGPL-3.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 7 GitHub stars
Code Warn
- process.env — Environment variable access in apps/dashboard/next.config.ts
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
🦊 Open-source professional quant agent framework. Agents pick the factors working now to time entries, write full strategies, and evolve them in a sandbox — every order through machine approval, the LLM never on the order path. Multi-market, audit-grade.
Inalpha
Quant agents that evolve under audit.
An oracle that keeps a ledger.
Factor timing · Multi-perspective research · Factor lab · Risk engine · Strategy evolution · Machine-approved orders · Backtest = paper · Omikuji
English | 中文
![]()
![]()
![]()
![]()
![]()
Every factor proposed, every strategy mutated, every order routed — logged, versioned, reviewable. Agents pick the currently-effective factors to time entries, write the strategies, and evolve them; the LLM writes the code, and the engineering harness signs every decision.
Inalpha is a professional quant agent framework — an open-source system where LLM agents research (with a panel of investing legends), pick the factors that work now, write and evolve strategy code, and route every order through machine approval, all under an audit-grade engineering harness. A unified backtest=paper=live kernel (one strategy codebase — swap only the Clock and Gateway), multi-market routing (crypto, US equities, A-shares, global indices, macro), and a Claude Code-style hooks/permissions/plan-exec layer back it — built for teams that demand every decision be provable and every order path be unreachable by the LLM directly.
Overview
Inalpha is a professional quant agent framework, governed by engineering discipline. It treats LLM agents not as black-box signal generators, but as code-writing collaborators bounded by hooks, permissions, plan-then-execute approval, and a one-shot signature on every order path.
Agents pick the factors that work now. Instead of a hard-coded indicator set, they rank factors by time-series Rank IC and surface the ones currently effective (factor.timing), then use that to back research and timing. Data itself is source-attributed by default — as_of-stamped and freshness-checked — so agents don't quietly reason on stale data.
Several capability lines sit on top of that harness:
- Factor lab + factor timing — agents formalize, compute, IC-test, multiple-testing-check, and register factors, and rank them by time-series Rank IC to time entries; every hypothesis is logged with author, timestamp, and the economic-story gate decision.
- Multi-perspective research — a deep dive convenes technical / fundamental / sentiment analysts, plus an optional panel of investing legends (Buffett / Lynch / Wood / Burry / Druckenmiller / Marks) for opposing views that feed a synthesis.
- Risk engine — declarative rules (notional caps, price deviation, drawdown veto) enforced at the HTTP boundary, not in prompts.
- Strategy evolution — LLMs mutate full Python source; three sandbox gates (AST audit, subprocess isolation,
Strategyprotocol contract) precede any candidate run; multi-objective fitness (Sharpe + Calmar − turnover − drawdown) so no metric can be gamed alone. - Machine-approved orders (no direct LLM path) — order intents go
trade.create_plan → approve → execute_planwith a single-use, TTL-boundapproval_token; the LLM has no direct path to placing an order, and every step is logged into the audit trail. - Inari Omikuji — a shrine fortune draw (playful easter egg) — undecided on direction? Cast a hexagram or draw a tarot card for a vantage outside the data; hard-walled from decisions, it can't touch risk, orders, or factors (see Core Capabilities §6).
The name combines Inari (the Japanese fox deity of prosperity) with alpha (the quant term for excess return) — a companion that reads your direction and keeps every step on the record.
Status: Inalpha is in alpha (Phase D-11 — multi-market paper trading: cross-currency cash + a live runner that auto-runs promoted strategies on live bars, on top of D-10 multi-market data and D-9 LLM-authored strategies + risk engine). Read the code, weigh in on design — do not run this against real money (real-money trading is out of scope).
Design Principles
| Principle | Substance |
|---|---|
| Discipline over vibes | Hooks, permissions, plan-exec separation, and a one-shot approval token are declared in config — not in prompts. A failing guardrail has a single point of debug. |
| Agents are first-class | Research, decision, risk, and review have dedicated agents — opposing stances, distinct toolsets, traceable decisions. Not a chat wrapper. |
| Transparency over precision | Prefer an agent that says "I don't know" over one that sounds certain but cannot show its evidence. |
| Unified kernel | One strategy codebase across backtest and paper — swap the Clock and Gateway, not the logic. The kernel is same-code by design (the seam that would reach live is just a Gateway swap), but real-money live trading is out of scope. When behavior diverges, the cause is physical (slippage, latency, data precision), not "two code paths." |
| Long-horizon compounding | Solid infrastructure before flashy features. Surviving long matters more than running fast. |
System Architecture
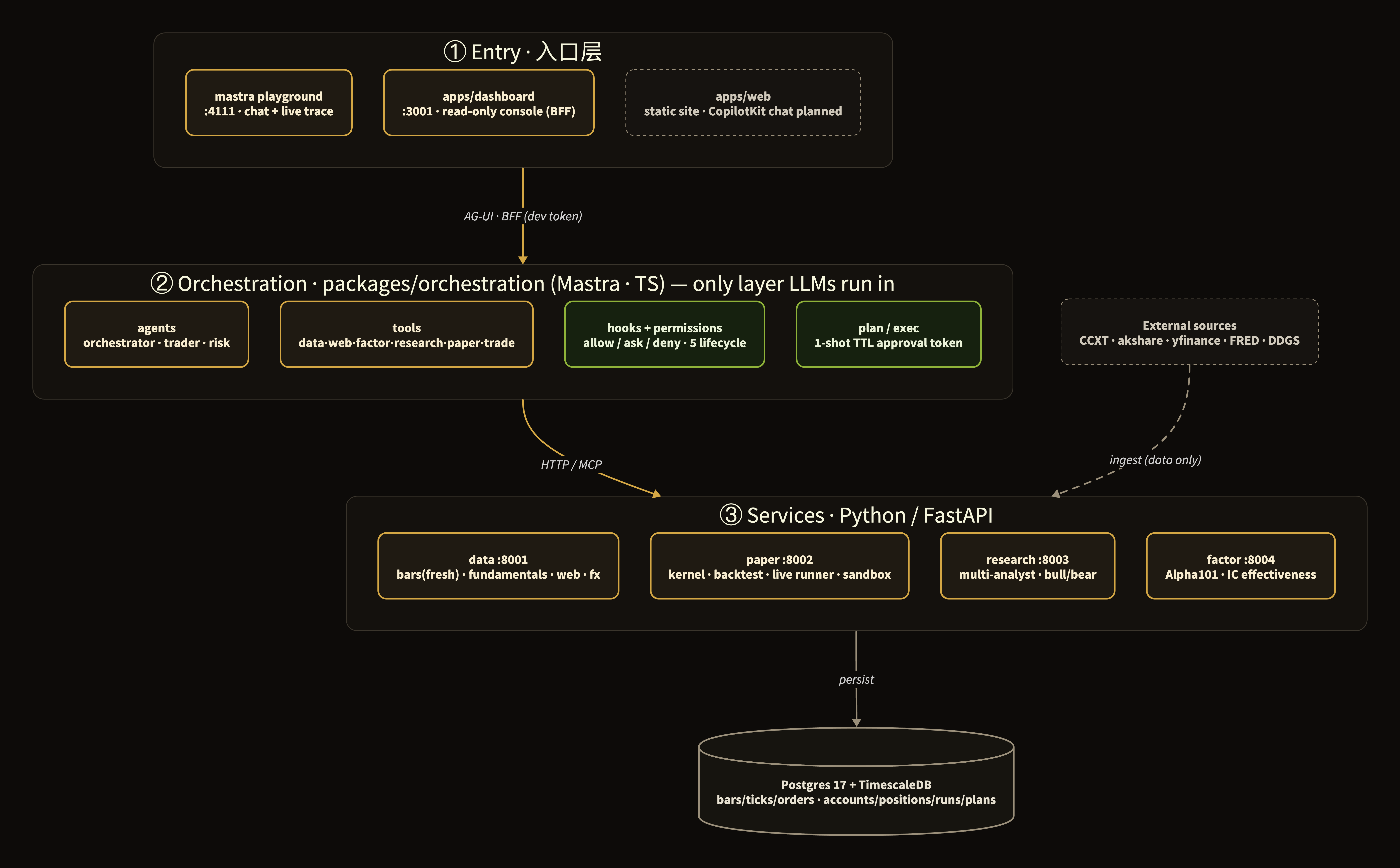
Four layers, top to bottom:
- L1 · User entry. The Operator Console (
apps/dashboard, with a docked agent chat) is the home base; themastra devplayground is there for live trace, and direct CLI tool calls still work. - L2 ·
packages/orchestration(Mastra · TypeScript). Where agents, tools, hook/permission middleware, the in-memory plan store, conversation memory, and telemetry live side by side. This is the only layer LLMs run in. - L3 · Python kernel services (FastAPI). Each service is an independent, stateful process. Today:
services/data(market data ingest + web search + financial fundamentals across A-shares / HK / US / global),services/paper(event-driven kernel running backtest and paper on the same code),services/research(initial multi-agent scaffolding; analysts pull fundamentals + web intel with fallback; the full bull/bear debate loop is slated for Phase E+), andservices/factor(factor library — pandas-ta / Alpha101 / qlib — with IC effectiveness screening and current-effective factor timing; signals only, no execution). The asynchronousStrategy Evolutionloop runs alongside. - L4 · Persistence & external. Postgres + TimescaleDB stores all time-series and business state. External venues span crypto, US equities, A-shares, Hong Kong, major Asian and European markets, global indices, and FRED macro data — routed automatically by the orchestrator based on market classification.
Strategy Evolution loop (Phase E+)

The evolution loop runs asynchronously alongside the agent runtime, with winners promoted back into services/paper for backtest evaluation. Details — sandbox gates, fitness function, and the E1 → E4 ramp — live in Core Capabilities §3 below.
Both diagrams are rendered from D2 sources at assets/architecture.d2 and assets/strategy-evolution.d2. See docs/04-current-state.md for the live module inventory and what's still in flight.
Core Capabilities
Each capability below is built so the work it produces is auditable from day one — not retrofitted later.
1. Factor Lab — propose, validate, and version every alpha hypothesis
An alpha hypothesis is a guess about what predicts returns ("stocks with low volatility outperform"; "options skew steepens before drawdowns"). Traditional factor research is bottlenecked by the manual loop — a single researcher can usually validate 5–10 such guesses a day. Inalpha lets agents do that work without taking shortcuts.
- Talk it through. Drop a hypothesis in plain language; agents formalize it, compute the values, and run the standard statistical checks in seconds.
- Not just a registry — timing too. Rather than a hard-coded indicator set, agents rank factors by time-series Rank IC to surface the ones effective right now (
factor.timing), backing research and entry timing — when the market rotates, the chosen factors rotate with it. - An economic story gate. A factor without a "why" never enters the library. The gate is a required step, not a recommendation.
- Guardrails for the classic mistakes. Looking ahead in time, surviving-only universes, over-parameterized search, too few samples, normalization leaks — five middleware checks intercept each one before it pollutes a result.
- No silent promotion. Registering a factor to the library is permanently human-only. Rejected factors are kept on file for postmortems, not silently dropped.
Conversational tools live at L0; a fixed validation workflow at L1; a multi-agent research crew at L2; weekly automated scans at L3. Design notes in
docs/03-kernel-design.md.
2. Risk & Audit — no LLM reaches the order path unsupervised
Letting an LLM call submit_order directly is how you lose money fast. Telling it "don't exceed 10% of capital" in a prompt is a suggestion, not a constraint — a sufficiently confident model will override it. So Inalpha moves risk out of prompts and into the middleware.
- Three-step orders. Every trade idea travels propose → approve → execute. Approval (by a risk agent, by a human, or by an automated rule) mints a single-use, short-lived signing token. Execution consumes the token; the token is revoked the moment it is spent.
- Hard rules at the service boundary. Notional caps, price-deviation guards, drawdown veto, per-instrument-class limits — enforced before any state change. A violating order is rejected with its reason logged against the originating proposal.
- A complete audit trail. Every proposal, approval, and execution is persisted with who, why, when, and the token's full lifecycle. The same record drives postmortems and feeds back into the strategy-evolution loop.
3. Strategy Evolution — let strategies write better versions of themselves
Human-written strategies hit a velocity ceiling, and parameter tuning can only adjust dials — it cannot discover a structural change like "add an RSI filter to the SMA cross." Inalpha lets an LLM rewrite the strategy's Python source, then puts every candidate through hard gates before it ever touches a backtest.
- Small diffs, not whole rewrites. The LLM gets the current source plus the last backtest report and returns a short unified diff — easy to review, easy to roll back.
- Three sandbox gates. A static code audit, an isolated subprocess run, and a final check that the result still satisfies the
Strategyinterface. Malicious or malformed code never reaches the backtest. - Diversity preserved, single metrics not chased. Candidates are scored on a balanced fitness (return + risk-adjusted return − turnover − drawdown veto) and stored in a behavioral grid, so the population doesn't collapse onto one Sharpe-maximizing clone.
- Reproducible end to end. Each candidate's parent, prompt, sandbox verdict, and scores are versioned — the entire lineage can be replayed later.
Ships as E1 (single-generation closed loop) in D-9 and ramps to E4 (loop exposed to the orchestrator as a single MCP tool), with two weeks of stable operation required between tiers.
4. Swarm — run dozens of backtests in parallel
Real quant research is concurrent by nature: 5 symbols × 3 factor families × 4 time windows = 60 backtests. Running them one at a time inside the agent runtime is a dead end.
Inalpha splits scheduling from compute. The agent runtime fans out the grid and aggregates results; a Python worker pool inside services/paper actually runs the backtests in parallel processes with resource limits. "Run momentum / mean-reversion / breakout across BTC, ETH, SOL, BNB, AVAX for 2024" becomes one workflow call that returns a Pareto frontier.
Current implementation (S1): single-host process pool, concurrency 4, grid capped at 20 backtests per call.
5. Research — a panel of investing legends
A deep dive doesn't hand you one "correct answer." Beyond the usual technical, fundamental, and sentiment analysts, you can convene a panel of master personas — Buffett (value / moats), Lynch (GARP growth), Wood (disruptive innovation), Burry (contrarian / bubbles), Druckenmiller (macro trends), Marks (cycles / risk): each argues in their own style, naturally forming opposing views that feed a synthesized judgment.
- Opt-in, cost-controlled. A plain deep dive costs the same as before; you only pay for the masters you actually convene.
- Views grounded in data. Each persona reads technicals / fundamentals / web intel with
as_ofpinned to now — no passing a stale forecast off as the present. - The full bull/bear structured debate lands in Phase E+; today you already get multiple perspectives side by side with opposing stances feeding the synthesis.
6. Inari Omikuji — undecided? draw a slip for direction
Real money invites real hesitation. When you're stuck, let the Inari priestess — α kit on her shoulder — draw you an omikuji (a shrine fortune slip): cast an I Ching hexagram or pull a tarot card for a vantage outside the data. A different angle, a breath, maybe a small unexpected nudge from Inari.
- A whisper, not an order. The hexagram or card never touches risk, approval, order placement, or factor scoring — it can't read or sway a single real decision. Which quietly makes the point: if even Inari's omen can't reach the decision path, the machine-approval boundary is real.
- The trade still answers to data. Once the slip is drawn, the call still belongs to research, factors, and backtests; the omikuji only helps unknot your brow.
Roadmap
Where each capability stands today. Live module inventory and the end-to-end decision sequence diagram live in docs/04-current-state.md.
| Status | Capability | Phase | Highlight |
|---|---|---|---|
| ✅ Shipped | Plan/Exec audit trail + Hooks + Permission Engine | D-8a | three-step orders · one-shot signing token · 5 lifecycle hook events · allow / ask / deny tri-state |
| ✅ Shipped | Research → strategy → backtest lineage | D-8c | deep_dive → compose_strategy → run_backtest with research_id / backtest_id threaded through |
| ✅ Shipped | LLM-authored strategies — E1 MVP | D-9 | three sandbox gates (AST · subprocess · Strategy contract) + multi-objective fitness + baseline auto-run |
| ✅ Shipped | Risk engine at the HTTP boundary | D-9 | declarative risk_rules.toml · pre-trade enforce · risk_locks table with independent commit |
| ✅ Shipped | Bull / bear researcher debate | D-9 | opposing-stance researchers under services/research |
| ✅ Shipped | Scheduler / cron agent mode | D-9 | scheduler_jobs + advisory lock + /api/scheduler/* management plane |
| ✅ Shipped | RiskGuard per-account isolation | D-9.1a | RiskGuardFactory removes cross-account state bleed |
| ✅ Shipped | Multi-market data sources — web search + financial fundamentals | D-10 | zero-key DDGS web search · akshare (A-shares/HK) + yfinance (global) fundamentals · analyst integration + fallback · per-market lookbackDays |
| ✅ Shipped | Risk engine — all 5 rules live in HTTP path | D-9 closed | closed_trades writes from HTTP order flow; RoutingCalendar for US equity + crypto; all trade-based rules trigger on real data |
| ✅ Shipped | askUserChoice — ask permission path |
D-11 (issue #2) | pending-permission flow resolves the ask state (no longer a workaround) |
| ✅ Shipped | permissions.yaml configuration |
D-11 (issue #4) | config/permissions.default.yaml + yaml_loader.ts replace the hard-coded defaults.ts |
| ✅ Shipped | Multi-market paper trading — live runner + multi-currency cash | D-11 | closed-bar on_bar → guarded plan/exec · per-currency cash buckets + FX-converted equity · D-11.1 trust-boundary hardening (candidate ownership check · per-account run cap · retryable-error split) |
| ✅ Shipped | Factor library + IC effectiveness | D-11 | services/factor (pandas-ta / Alpha101 / qlib) · factor.timing / .score / .catalog · signals only, no execution |
| ✅ Shipped | Live runner ops hardening | D-11.2 | net PnL (fees deducted) · runtime TTL auto-stop · build-phase backoff + error classification |
| 🗓️ Planned | Strategy evolution — E2 | D-12 | multi-generation loop + MAP-Elites + Island Model + unified-diff mutations |
| 🗓️ Planned | Research-hub nested supervisor | D-10+ | 4 analysts + bull/bear/risk debate as a single closed loop |
| 🗓️ Planned | Factor discovery — L0 → L1 | D-11+ | walk-forward IC + multiple-testing correction + factor_candidates table |
| 🔬 Exploring | Skills as procedural memory | TBD | reusable markdown skills with auto-discovery |
| 🔬 Exploring | Alpha Zoo cold start | E1+ | seed factor library with public alphas (Qlib / Kakushadze / GTJA) |
| 🔬 Exploring | E4 evolve_strategy MCP tool |
E4 | evolution loop exposed to the orchestrator as one MCP tool |
| 🔬 Exploring | Analog backtesting | TBD | similarity-window-driven backtest range selection (STUMPY) |
Legend — ✅ Shipped: behavior already lives in
main· ⏭️ In Flight: actively in this phase · 🗓️ Planned: scoped for an upcoming phase, not started · 🔬 Exploring: research recorded, no commit date.
For whom
| Audience | Value |
|---|---|
| Quant researchers and students | LLM agents accelerate research; one tech stack for backtest and live |
| Trading system engineers | A reference integration of modern agents with traditional kernels, cross-referenced against Nautilus / qlib / vnpy |
| AI agent developers | Real-world financial deployment of multi-agent + hooks + permissions |
| Individual traders (research-oriented) | A research companion you can talk to, plus an engineered home for your strategies |
Quick Start
1 · Install dependencies
pnpm i # Node packages (packages/orchestration)
uv sync # Python packages (services/_shared, data, paper, research, factor)
2 · Configure your LLM key (required)
A single .env at the repo root is read by Mastra (TS) and all Python services. Copy the template and fill in the LLM provider you want to use:
cp .env.example .env
Inside .env, set LLM_PROVIDER to one of deepseek | anthropic | openai | gemini | kimi | zhipu | ollama and fill in the matching key.
Defaults pick each vendor's current flagship as of 2026-05. Override with LLM_MODEL=... if you want a reasoning / cheaper variant.
| Provider | env var | Default model (2026-05) | Get a key |
|---|---|---|---|
deepseek |
DEEPSEEK_API_KEY |
deepseek-v4-pro |
platform.deepseek.com |
anthropic |
ANTHROPIC_API_KEY |
claude-opus-4-7 |
console.anthropic.com |
openai |
OPENAI_API_KEY |
gpt-5.5 |
platform.openai.com |
gemini |
GEMINI_API_KEY |
gemini-3-pro |
aistudio.google.com |
kimi |
KIMI_API_KEY |
kimi-k2.6 |
platform.moonshot.ai |
zhipu |
ZHIPU_API_KEY |
glm-5.1 |
open.bigmodel.cn |
ollama |
— (local) | llama4 |
ollama pull llama4 |
Override the default model by setting LLM_MODEL=... in the same file. Mastra and services/research both read this one file — no per-service config to juggle.
Already have keys in
services/*/.envorpackages/orchestration/.envfrom earlier? Those still work as cwd-level overrides while you migrate. Once you copy them up into the root.env, the per-service files can be deleted.
3 · Start everything
bash scripts/dev.sh # one shot — data (8001) + paper (8002) + research (8003) + factor (8004) + mastra (4111)
bash scripts/dev.sh logs # follow service logs
bash scripts/dev.sh stop # stop everything
4 · Open the Operator Console — your home base
The Operator Console is the recommended way to use Inalpha — your home base. A runtime
dashboard surfaces everything you'd otherwise have to ask the agent for, at a glance:
portfolio & positions, live runners with bar-by-bar decisions, the cross-module agent
activity timeline, the strategy lab, the system factor library, the risk panel, and the
Inari Omikuji. A docked agent chat sits on the right — talk to the orchestrator
directly: pull quotes, run backtests, tune factors, draw a hexagram, all in one place.
cd apps/dashboard
pnpm i # first time only
pnpm dev # → http://localhost:3001
No extra config — the console reads the repo-root .env directly (backend URLs + JWT_SECRET
are inherited), so as long as the services from step 3 are up, it just connects. It ships with
dark / light themes (a terminal "Vermilion" aesthetic — see apps/dashboard/design.md)
and an en / 中 switcher in the sidebar.
The console is the single front door: data, research, backtests, live runners, and the
conversation with the orchestrator now all live in one place.
Only the orchestrator (Mastra) and
services/researchconsume your LLM key;services/paper
never calls an LLM directly. Prefer the manual three-terminal flow, or want the low-level live
trace (themastra devplayground at http://127.0.0.1:4111)? SeeAGENTS.md §4.
AI Collaboration
Inalpha is tool-neutral and local-first. Strategies, data, and decision records live in your repository — LLM calls go to external providers, but structured outputs and cache control are owned by the codebase, so the harness is observable, auditable, and provider-swappable. The hard constraints (naming, untouchable directories, commit conventions, three-part tool-description style) are declared once and read by every AI coding tool:
CLAUDE.md— Claude Code project-level memoryAGENTS.md— common entry point for Cursor / OpenAI Codex / Aider / Continue / Clinescripts/check-consistency.sh— mechanical cross-file consistency checks
Acknowledgments
Inalpha is built on top of other people's good ideas. What we borrowed is named here so it's clear we're standing on their shoulders, not starting from zero.
Trading system designs
- Nautilus Trader — the same-code invariant across backtest / paper / live, and the event-driven kernel
- vnpy — the Gateway abstraction and multi-market access mindset
- Microsoft qlib — factor expression DSL and point-in-time universe handling
- Hummingbot · Freqtrade — what open-source crypto tooling can be
Agent and LLM engineering
- TradingAgents — multi-agent opposing-stance debate for research
- Anthropic and the Claude Code team — hooks, permissions, plan/exec, MCP, and subagents as borrowable engineering primitives
- Mastra — the TypeScript agent orchestration scaffolding
- Model Context Protocol — the open protocol that lets tools plug in without hand-rolled glue
Infrastructure
- PostgreSQL · TimescaleDB · FastAPI · CCXT · Next.js · CopilotKit · uv · pnpm
And to every quant researcher who refuses to accept opaque "AI signals" — this project is written for you. We hope to give back, in time.
License
GNU AGPL-3.0 — free software with a strong network copyleft.
- Allowed: any use (personal research, academic, commercial in-house, integration into AGPL-compatible projects)
- Required: if you modify Inalpha and offer it as a network service, you must release the complete corresponding source under AGPL-3.0
- Commercial licensing (proprietary / closed-source / hosted SaaS without source release): please open an issue to discuss a dual license
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found