labrat
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Autonomous multi-branch research lab. Branches compete for compute budget. The system converges on what works.
labrat
![]()
Quickstart · For Agents · Example · Docs · DXRG
Autonomous research lab that explores multi-branch research trees in parallel. An economic funding mechanism prioritizes across competing trajectories -- productive branches earn more compute, dead branches get defunded. The system converges on what works without manual steering.
v2: Deep research agents that design their own trees via web search, periodic expansion scouts that inject external knowledge to prevent local optima, belief revision that catches when assumptions change, and graduated context management for long-running sessions.
Extends Karpathy's autoresearch from single-agent single-metric to multi-branch market allocation. Born out of work at DXRG to push autoresearch into broader, more exploratory domains where you need to map the full surface area of a problem before committing to a direction.
Built for Claude Code. Works with Codex, OpenClaw, or any agent that reads markdown and runs shell commands.
When to use this
Labrat is for problems where you have many plausible directions and need to figure out which ones are worth pursuing. Some examples:
Transformer architecture search -- you have a small validation set and want to compare attention patterns, layer depths, positional encodings, and activation functions. Each branch tests one axis. The market tells you which dimensions of the architecture actually move the needle vs which are flat.
Kernel and systems optimization -- testing compiler flags, memory layouts, tiling strategies, and fusion patterns for a GPU kernel. Experiments run in seconds. The market burns through hundreds of configs and finds the 3 that matter.
Feature engineering for tabular models -- you suspect some of your 200 features are noise. Branches test feature subsets, encoding strategies, interaction terms, and normalization methods. The market identifies the minimal feature set.
Prompt and retrieval tuning -- different chunking strategies, embedding models, reranking approaches, and prompt templates for a RAG system. Each branch is a different axis of the retrieval pipeline.
Drug compound screening -- molecular descriptors, fingerprint types, model architectures, and training strategies for QSAR models. Branches compete for compute based on which descriptor/model combos actually predict activity.
Trading strategy research -- signal features, execution methods, regime filters, and sizing rules tested across walk-forward windows. The market finds which components have real edge vs which are overfitting to history.
The common thread: you have a baseline, a metric, multiple axes of variation, and more ideas than compute. The market figures out where to spend.
How it works
You define a research tree. The orchestrator explores it.
A tree can be anything -- different model architectures, feature engineering strategies, data preprocessing pipelines, hyperparameter regions, loss functions, training regimes. Branches are just dimensions of variation you want to explore. They can be narrow (testing 5 values of learning rate) or broad (comparing entirely different algorithmic families). We recommend experimenting with how you define them. The structure of your tree matters as much as what's in it.
In the example below, branches converge into a capstone that combines winners. We've also experimented with spawning sub-trees off productive branches for deeper exploration, then running a separate pass to look across sub-trees for shared learnings and unexpected synergies. That pattern works well for deep domains but isn't formalized in the framework yet.
baseline
TF-IDF + LR
│
┌──────────┬───────┼───────┬──────────┐
│ │ │ │ │
features model preproc objectives ensemble
budget:20 budget:20 b:15 b:15 b:10
│ │ │ │
bigrams SVM stopwords balanced ← promoted
trigrams catboost min_df C=0.5 ← tested
char_wb lightgbm max_df C=5.0 ← rejected
50K feat rand.for. C=10
│ │ │ │
└──────────┴───────┴───────┘
│
capstone
combine branch winners
Your agent harness (Claude Code, Codex, etc.) acts as the orchestrator. It dispatches labrats (subagents) to explore branches in parallel. Each experiment changes one thing. A formula scores results. Budget flows to what produces.
orchestrator (the monolith)
│
├─ Select branches by priority
├─ Dispatch labrats in parallel ─────────────────┐
│ ├── ᘛ⁐ᕐᐷ~ features: run + judge │
│ ├── ᘛ⁐ᕐᐷ~ model: run + judge │ concurrent
│ └── ᘛ⁐ᕐᐷ~ objectives: run + judge │
├─ Collect + score mechanically ◄────────────────┘
├─ Update beliefs, budget, champions
└─ Write handoff → next cycle
Every 5th cycle: red team (shuffled labels). Every 10th: budget replenishment. Every 20th: expansion scout searches for external approaches. Stuck branches trigger a research scout that finds papers and proposes new experiments. At convergence: frame challenge tests assumptions before declaring the lab done.
orchestrator (the monolith)
│
├─ Graduated context reading (handoff-first)
├─ Expansion check (every 20 cycles: inject external knowledge)
├─ Research scout check (stuck branches: search papers/repos)
├─ Select branches by priority (shared allocator.py)
├─ Dispatch labrats in parallel ─────────────────┐
│ ├── ᘛ⁐ᕐᐷ~ features: run + judge │
│ ├── ᘛ⁐ᕐᐷ~ model: run + judge │ concurrent
│ └── ᘛ⁐ᕐᐷ~ objectives: run + judge │
├─ Collect + score mechanically ◄────────────────┘
├─ SYNTHESIS: "What did we learn?" (new)
├─ Update beliefs, budget, champions
├─ Belief revision check (new)
├─ Log transition type (new)
└─ Write handoff → next cycle
Quickstart
1. Design your research tree. Option A: use the automated tree designer that surveys the landscape via web search:
# In Claude Code:
Read labrat/templates/tree_designer.md and design a research tree for:
Mission: Maximize macro F1 on 5-class sentiment. Baseline F1=0.36.
Constraints: CPU only, <8K samples, no pretrained embeddings.
Option B: use a deep research model manually (GPT-5.4 Pro, Claude with extended thinking, or similar). Give it your problem, baseline, and constraints. Convert to YAML:
mission: "Maximize macro F1 on 5-class sentiment. Baseline F1=0.36."
branches:
model:
initial_budget: 25
search_space:
- delta_key: "model.type"
values: ["svm", "catboost", "random_forest"]
features:
initial_budget: 20
search_space:
- delta_key: "features.ngram_max"
values: [2, 3]
2. Write your experiment runner -- thin wrapper around your eval pipeline:
# research_lab/scripts/run_experiment.py
def run_experiment(config):
model = train(config)
return {"metrics": {"test": {"primary_metric": evaluate(model).f1}}, ...}
3. Bootstrap and loop:
cp templates/* research_lab/ # orchestrator, constitution, dead_ends
cd research_lab && python scripts/bootstrap.py
python -m http.server 8787 & # dashboard
Then tell your agent:
/loop 10m Read research_lab/orchestrator.md and execute one research cycle.
Watch it live at localhost:8787/dashboard.html.
For agents
If a user pointed you here, your job is to set up and run a research lab for their problem.
If they haven't given you context yet, ask:
- What problem are you solving? What's your baseline and target metric?
- What are your constraints? (compute, time, dataset size)
- Any recent papers or prior experiments to build on?
- Do you have an eval pipeline, or should I build one?
Once you have the problem:
- Design the tree -- use a deep research model to map the problem space, convert to
branches.yaml - Build the lab -- create
run_experiment.py, customizeconstitution.mdanddead_ends.md - Check in -- "Here's N branches with M budget. Scoring weights X. Ready?"
- Run -- bootstrap, start dashboard, enter
/loop. Followorchestrator.mdexactly. - Report -- when converged, summarize: what matters, what's flat, what surprised you.
templates/orchestrator.md is your brain during the loop. Everything is in there.
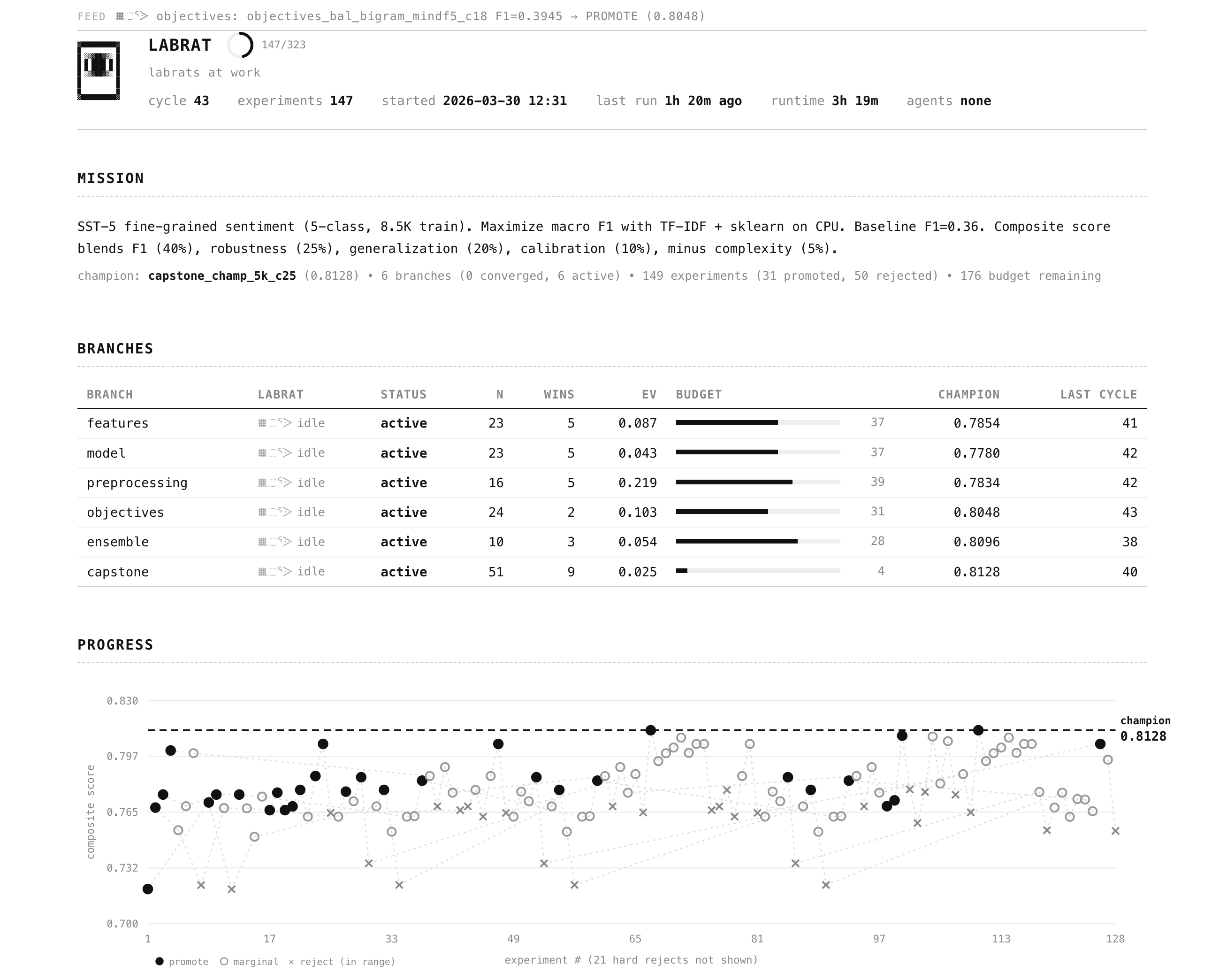
Example
examples/nlp-sentiment/ -- 5-class sentiment on SST-5. CPU-only, 3 seconds per experiment. 43 cycles, 147 experiments.
The market found 3 axes that matter, 9 that are flat, and that branch winners don't always stack. Production champion: F1=0.398 vs 0.360 baseline. Full writeup.
Docs
Getting Started · Architecture · Deep Research Guide · Data Splitting · Economics · Domains · Runners · Assessment · Visual Identity
Credits
Extends autoresearch with market-based multi-branch allocation and parallel agents. Built with Claude Code at DXRG. MIT license.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found