selftune
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 10 GitHub stars
Code Fail
- rm -rf — Recursive force deletion command in .github/workflows/publish.yml
Permissions Pass
- Permissions — No dangerous permissions requested
This toolkit monitors your AI agent sessions, learning your natural language patterns to automatically rewrite and optimize skill descriptions for better triggering. It operates as a CLI and an agent skill with zero runtime dependencies.
Security Assessment
Overall risk: Low. The tool requires no API keys or external services, which significantly limits data exposure. However, one issue was flagged: a recursive force deletion command (`rm -rf`) was found in the `.github/workflows/publish.yml` file. While this is standard for cleaning up automated CI/CD pipelines and does not affect the end-user's machine, it is worth noting. The project requests no dangerous local permissions and no hardcoded secrets were detected. Because it needs to read your local sessions and rewrite local skill files, it does access and modify your workspace data, but keeps this processing local.
Quality Assessment
This is a healthy, well-maintained project. It uses the permissive MIT license and features a clean TypeScript codebase. Activity is very high, with the most recent code push occurring today. It utilizes strong development standards, evidenced by integrated CodeQL analysis and an OpenSSF Scorecard. While the community is currently small (10 GitHub stars), the project demonstrates high developer maturity and professionalism.
Verdict
Safe to use.
Skill observability & self-improving toolkit for agent skills.
selftune
Self-improving skills for AI agents.
![]()
![]()
![]()
![]()

Your agent skills learn how you work. Detect what's broken. Fix it automatically.
Install · Use Cases · How It Works · Commands · Platforms · Docs
Your skills don't understand how you talk. You say "make me a slide deck" and nothing happens — no error, no log, no signal. selftune watches your real sessions, learns how you actually speak, and rewrites skill descriptions to match. Automatically.
Works with Claude Code (primary). Codex, OpenCode, and OpenClaw adapters are experimental. Zero runtime dependencies.
Install
npx skills add selftune-dev/selftune
Then tell your agent: "initialize selftune"
Two minutes. No API keys. No external services. No configuration ceremony. Uses your existing agent subscription. You'll see which skills are undertriggering.
CLI only (no skill, just the CLI):
npx selftune@latest doctor
Updating
The skill and CLI ship together as one npm package. To update:
npx skills add selftune-dev/selftune
This reinstalls the latest version of both the skill (SKILL.md, workflows) and the CLI. selftune doctor will warn you when a newer version is available.
Before / After

selftune learned that real users say "slides", "deck", "presentation for Monday" — none of which matched the original skill description. It rewrote the description to match how people actually talk. Validated against the eval set. Deployed with a backup. Done.
Built for How You Actually Work
I write and use my own skills — Your skill descriptions don't match how you actually talk. Tell your agent "improve my skills" and selftune learns your language from real sessions, evolves descriptions to match, and validates before deploying. No manual tuning.
I publish skills others install — Your skill works for you, but every user talks differently. selftune ships skills that get better for every user automatically — adapting descriptions to how each person actually works.
I manage an agent setup with many skills — You have 15+ skills installed. Some work. Some don't. Some conflict. Tell your agent "how are my skills doing?" and selftune gives you a health dashboard and automatically improves the skills that aren't keeping up.
I use skills for non-coding work — Marketing workflows, research pipelines, compliance checks, slide decks. You say "make me a presentation" and nothing happens. selftune learns that "slides", "deck", and "presentation for Monday" all mean the same skill — and fixes the routing automatically.
How It Works
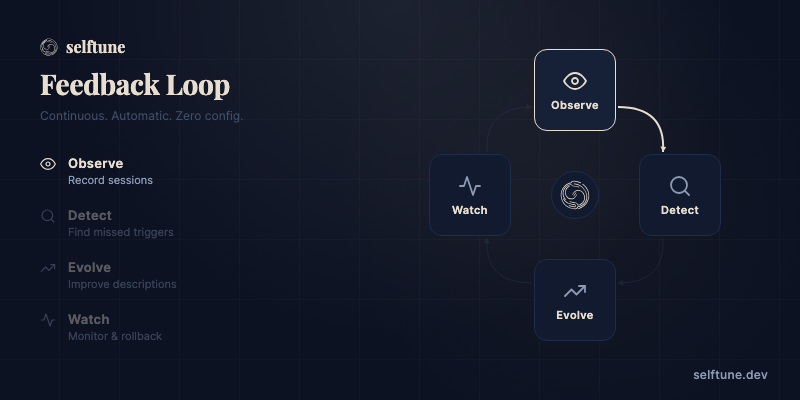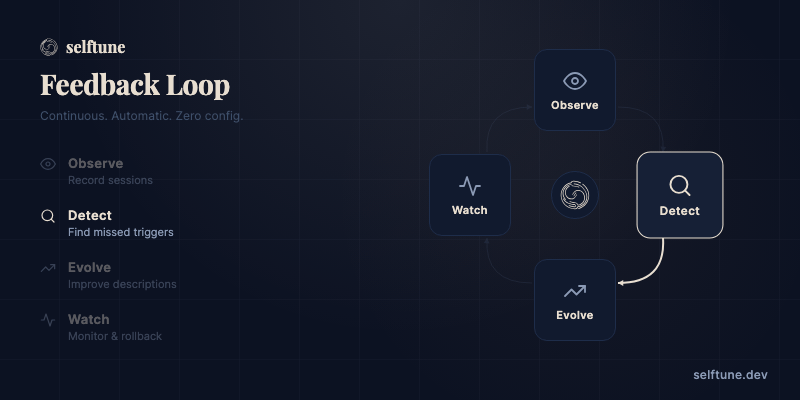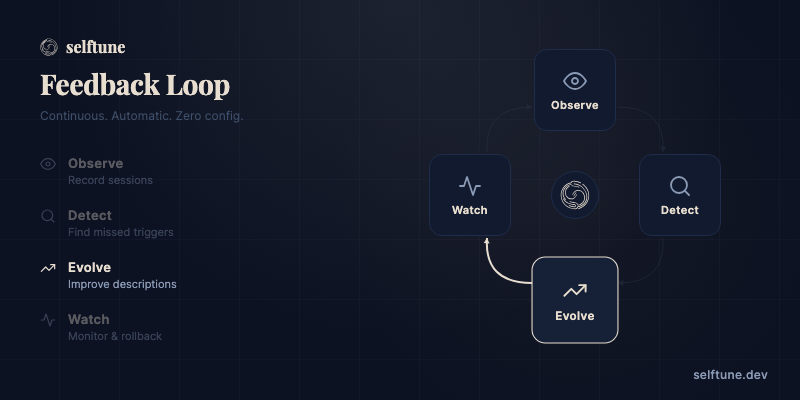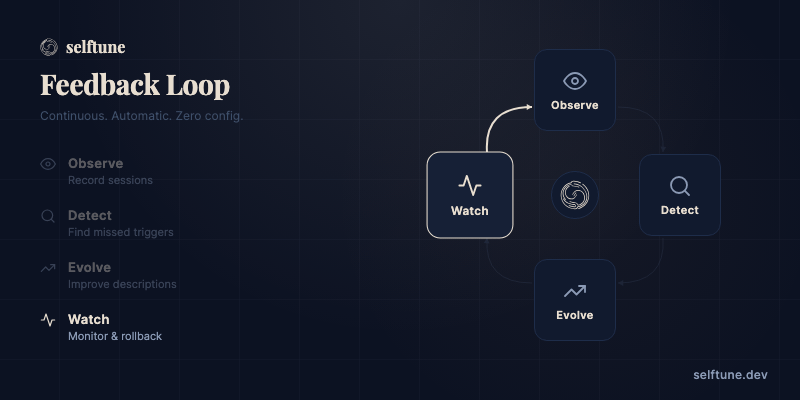
A continuous feedback loop that makes your skills learn and adapt. Automatically. Your agent runs everything — you just install the skill and talk naturally.
Observe — Seven real-time hooks capture every query, every skill invocation, and every correction signal. Structured telemetry — not raw logs. On Claude Code, hooks install automatically during selftune init. Backfill existing transcripts with selftune ingest claude.
Detect — Finds the gap between how you talk and how your skills are described. You say "make me a slide deck" and your pptx skill stays silent — selftune catches that mismatch. Clusters missed queries by invocation type. Detects correction signals ("why didn't you use X?") and triggers immediate improvement.
Evolve — Generates multiple proposals biased toward different invocation types, validates each against your real eval set with majority voting, runs constitutional checks, then gates with an expensive model before deploying. Not guesswork — evidence. Automatic backup on every deploy.
Watch — After deploying changes, selftune monitors trigger rates, false negatives, and per-invocation-type scores. If anything regresses, it rolls back automatically. No manual monitoring needed.
Automate — Run selftune cron setup to install OS-level scheduling. selftune syncs, grades, evolves, and watches on a schedule — fully autonomous.
How Is This Different from Agents That "Learn"?
Some agents claim self-improvement by saving notes about what worked. That's knowledge persistence — not a closed loop. There's no measurement, no validation, and no way to know if the saved notes are actually correct.
selftune is empirical. It observes real sessions, grades execution quality, detects missed triggers, proposes changes, validates them against eval sets, deploys with automatic backup, monitors for regressions, and rolls back on failure. Twelve interlocking mechanisms — not one background thread writing markdown.
| Approach | Measures quality? | Validates changes? | Detects regressions? | Rolls back? |
|---|---|---|---|---|
| Agent saves its own notes | No | No | No | No |
| Manual skill rewrites | No | No | No | No |
| selftune | 3-tier grading | Eval sets + majority voting | Post-deploy monitoring | Automatic |
Commands
Your agent runs these — you just say what you want ("improve my skills", "show the dashboard").
| Group | Command | What it does |
|---|---|---|
selftune status |
Get a one-line health summary plus compact attention / improving highlights | |
selftune last |
Quick insight from the most recent session | |
selftune orchestrate |
Run the full autonomous loop (sync → grade → evolve → watch) | |
selftune sync |
Replay source-truth transcripts/rollouts into SQLite and refresh repair state | |
selftune dashboard |
Open the visual skill health dashboard | |
selftune doctor |
Health check: logs, hooks, config, permissions | |
| ingest | selftune ingest claude |
Backfill from Claude Code transcripts |
selftune ingest codex |
Import Codex rollout logs (experimental) | |
| grade | selftune grade --skill <name> |
Grade a skill session with evidence |
selftune grade auto |
Auto-grade recent sessions for ungraded skills | |
selftune grade baseline --skill <name> |
Measure skill value vs no-skill baseline | |
| evolve | selftune evolve --skill <name> |
Propose, validate, and deploy improved descriptions |
selftune evolve body --skill <name> |
Evolve full skill body or routing table | |
selftune evolve rollback --skill <name> |
Rollback a previous evolution | |
| eval | selftune eval generate --skill <name> |
Generate eval sets (--synthetic for cold-start) |
selftune eval unit-test --skill <name> |
Run or generate skill-level unit tests | |
selftune eval composability --skill <name> |
Detect conflicts between co-occurring skills | |
selftune eval family-overlap --prefix sc- |
Detect sibling overlap and suggest when a skill family should be consolidated | |
selftune eval import |
Import external eval corpus from SkillsBench | |
| auto | selftune cron setup |
Install OS-level scheduling (cron/launchd/systemd) |
selftune watch --skill <name> |
Monitor after deploy. Auto-rollback on regression. | |
| other | selftune workflows |
Discover and manage multi-skill workflows |
selftune contributions |
Manage creator-directed sharing preferences | |
selftune creator-contributions |
Create or remove bundled selftune.contribute.json configs for skill creators |
|
selftune contribute |
Export an anonymized community contribution bundle | |
selftune recover |
Recover SQLite from legacy/exported JSONL during migration or disaster recovery | |
selftune badge --skill <name> |
Generate a health badge for your skill's README | |
selftune telemetry |
Manage anonymous usage analytics (status, enable, disable) | |
selftune alpha upload |
Run a manual SQLite-backed alpha upload cycle and emit a JSON send summary |
Full command reference: selftune --help
Why Not Just Rewrite Skills Manually?
| Approach | Problem |
|---|---|
| Rewrite the description yourself | No data on how users actually talk. No validation. No regression detection. |
| Add "ALWAYS invoke when..." directives | Brittle. One agent rewrite away from breaking. |
| Force-load skills on every prompt | Doesn't fix the description. Expensive band-aid. |
| selftune | Learns from real usage, rewrites descriptions to match how you work, validates against eval sets, auto-rollbacks on regressions. |
Different Layer, Different Problem
LLM observability tools trace API calls. Infrastructure tools monitor servers. Neither knows whether the right skill fired for the right person. selftune does — and fixes it automatically.
selftune is complementary to these tools, not competitive. They trace what happens inside the LLM. selftune makes sure the right skill is called in the first place.
| Dimension | selftune | Langfuse | LangSmith | OpenLIT |
|---|---|---|---|---|
| Layer | Skill-specific | LLM call | Agent trace | Infrastructure |
| Detects | Missed triggers, false negatives, skill conflicts | Token usage, latency | Chain failures | System metrics |
| Improves | Descriptions, body, and routing automatically | — | — | — |
| Setup | Zero deps, zero API keys | Self-host or cloud | Cloud required | Helm chart |
| Price | Free (MIT) | Freemium | Paid | Free |
| Unique | Self-improving skills + auto-rollback | Prompt management | Evaluations | Dashboards |
Platforms
Claude Code (fully supported) — Hooks install automatically. selftune ingest claude backfills existing transcripts. This is the primary supported platform.
Codex (experimental) — selftune ingest wrap-codex -- <args> or selftune ingest codex. Adapter exists but is not actively tested. Skill attribution is conservative: selftune only records explicit Codex skill evidence, not incidental assistant/meta mentions.
OpenCode (experimental) — selftune ingest opencode. Adapter exists but is not actively tested.
OpenClaw (experimental) — selftune ingest openclaw + selftune cron setup for autonomous evolution. Adapter exists but is not actively tested.
Requires Bun or Node.js 18+. No extra API keys.
Architecture · Contributing · Security · Integration Guide · Sponsor
MIT licensed. Free forever. Primary support for Claude Code; experimental adapters for Codex, OpenCode, and OpenClaw.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found