spector
Health Warn
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
The Zero-Overhead, Agent-Ready AI Memory Backbone. Ultra‑fast, SIMD‑accelerated semantic search engine built on Java Vector API + modern JVM technologies.
![]()
The Zero-Overhead, Agent-Ready AI Memory Backbone.
![]()
![]()
![]()
Legacy search engines bolted vectors onto text databases. Spector is designed from the ground up for modern AI — leveraging Java Project Panama to achieve C++ bare-metal SIMD speeds natively, with a built-in MCP server that turns any AI agent into a search-powered reasoning machine.
System Architecture
graph TB
subgraph Clients["Client Interfaces"]
claude["🤖 Claude Desktop"]
cursor["✏️ Cursor / AI IDEs"]
agents["🦾 Autonomous Agents"]
sdk["☕ Java SDK"]
spring["🌱 Spring AI"]
cli["🖥️ spectorctl CLI"]
rest["🌐 REST / gRPC"]
end
subgraph Transport["Transport Layer"]
mcp["MCP Server<br/><i>stdio · Streamable HTTP · 21 tools</i>"]
armeria["Armeria Server<br/><i>REST + gRPC + SSE</i>"]
end
subgraph Core["Spector Engine"]
runtime["SpectorRuntime<br/><i>Composition Root</i>"]
subgraph Search["Search Pipeline"]
hybrid["Hybrid Search<br/><i>Vector + Keyword</i>"]
hnsw["HNSW Index<br/><i>M=16, ef=200</i>"]
bm25["BM25 Index<br/><i>Inverted Index</i>"]
rrf["RRF Fusion<br/><i>+ LLM Re-ranking</i>"]
end
subgraph Memory["Cognitive Memory"]
cortex["4-Tier Cortex<br/><i>Working → Episodic → Semantic → Procedural</i>"]
hebbian["Hebbian Graph<br/><i>Associative links</i>"]
entity_graph["Entity Graph<br/><i>LLM-powered knowledge</i>"]
temporal["Temporal Chain<br/><i>Causal sequences</i>"]
decay["Memory Decay<br/><i>Power-law forgetting</i>"]
consolidation["Sleep Consolidation<br/><i>Hippocampal replay</i>"]
end
subgraph Ingestion["Ingestion Pipeline"]
chunking["Document Chunking<br/><i>Sentence · Paragraph · Semantic</i>"]
embedding["Embedding<br/><i>Ollama · Provider SPI</i>"]
indexing["Index Writer<br/><i>Batch + streaming</i>"]
end
end
subgraph Platform["Platform Layer"]
simd["SIMD Kernels<br/><i>AVX2 / AVX-512 / NEON</i>"]
panama["Panama Storage<br/><i>Off-heap MemorySegment</i>"]
quant["SVASQ Quantization<br/><i>INT8 · INT4 · IVF-PQ</i>"]
gpu["GPU Acceleration<br/><i>CUDA via Panama FFM</i>"]
end
subgraph Observe["Observability"]
events["TelemetryBus<br/><i>12 event types</i>"]
metrics["Micrometer<br/><i>Prometheus export</i>"]
sse["SSE Stream<br/><i>Real-time events</i>"]
end
claude & cursor & agents --> mcp
sdk & spring & cli & rest --> armeria
mcp & armeria --> runtime
runtime --> Search
runtime --> Memory
runtime --> Ingestion
Search --> simd & panama & quant
Memory --> simd & panama
Ingestion --> embedding
runtime --> events
events --> metrics & sse
gpu -.->|optional| simd
style Clients fill:#1a1a2e,stroke:#e94560,color:#fff
style Transport fill:#16213e,stroke:#0f3460,color:#fff
style Core fill:#0f3460,stroke:#533483,color:#fff
style Platform fill:#533483,stroke:#e94560,color:#fff
style Observe fill:#1a1a2e,stroke:#533483,color:#fff
style Search fill:#16213e,stroke:#0f3460,color:#fff
style Memory fill:#16213e,stroke:#0f3460,color:#fff
style Ingestion fill:#16213e,stroke:#0f3460,color:#fff
Data Flow
graph LR
subgraph Ingest["Ingest"]
docs["📄 Documents"]
files["📁 Files"]
api["🌐 API Data"]
end
subgraph Process["Process"]
chunk["✂️ Chunk"]
embed["🧬 Embed"]
quantize["🗜️ Quantize"]
end
subgraph Store["Store"]
vectors["📊 Vector Index<br/><i>HNSW · IVF-PQ</i>"]
text["📝 Text Index<br/><i>BM25</i>"]
memory["🧠 Cognitive Store<br/><i>4-tier cortex</i>"]
end
subgraph Query["Query"]
search["🔍 Hybrid Search"]
recall["💭 Memory Recall"]
rag["🤖 RAG Pipeline"]
end
docs & files & api --> chunk --> embed --> quantize
quantize --> vectors & text & memory
vectors & text --> search --> rag
memory --> recall --> rag
style Ingest fill:#1a1a2e,stroke:#e94560,color:#fff
style Process fill:#16213e,stroke:#0f3460,color:#fff
style Store fill:#0f3460,stroke:#533483,color:#fff
style Query fill:#533483,stroke:#e94560,color:#fff
Deployment Topology
graph TB
subgraph Standalone["Standalone Mode"]
jar["java -jar spector.jar<br/><i>Embedded engine + server</i>"]
end
subgraph Embedded["Embedded Mode"]
lib["SpectorEngine API<br/><i>In-process, zero-network</i>"]
end
subgraph Distributed["Distributed Mode"]
coord["Coordinator Node<br/><i>Query routing · fan-out</i>"]
shard1["Shard 1<br/><i>Partition A</i>"]
shard2["Shard 2<br/><i>Partition B</i>"]
shard3["Shard N<br/><i>Partition C</i>"]
coord --> shard1 & shard2 & shard3
end
style Standalone fill:#0f3460,stroke:#533483,color:#fff
style Embedded fill:#16213e,stroke:#0f3460,color:#fff
style Distributed fill:#1a1a2e,stroke:#e94560,color:#fff
🤖 MCP-Native — Built for AI Agents
Spector is an MCP-native engine — not an afterthought adapter. The MCP server runs in-process with the search engine (zero network, zero serialization), giving agents direct SIMD-accelerated access to 21 tools across search, memory, and RAG.
MCP Architecture
graph TB
subgraph Agents["AI Agents"]
claude["🤖 Claude Desktop"]
cursor["✏️ Cursor"]
cline["🔧 Cline"]
custom["🦾 Custom Agents"]
end
subgraph MCP["MCP Server — Dual Transport"]
transport["JSON-RPC 2.0<br/><i>stdio (stdin/stdout) · Streamable HTTP (/mcp)</i>"]
registry["SpectorToolRegistry<br/><i>21 tools auto-registered</i>"]
subgraph EngineTools["Engine Tools — 6"]
engine_search["engine_search<br/><i>Semantic vector search</i>"]
engine_hybrid["engine_hybrid_search<br/><i>Vector + keyword + RRF</i>"]
engine_rag["engine_rag<br/><i>RAG with context assembly</i>"]
engine_ingest["engine_ingest<br/><i>File/text ingestion</i>"]
engine_delete["engine_delete<br/><i>Remove documents</i>"]
engine_status["engine_status<br/><i>Index stats & health</i>"]
end
subgraph MemoryTools["Cognitive Memory Tools — 15"]
mem_remember["memory_remember<br/><i>Store with importance/tags</i>"]
mem_recall["memory_recall<br/><i>Recall with fused scoring</i>"]
mem_scratchpad["working_memory_scratchpad<br/><i>In-progress reasoning</i>"]
mem_reinforce["memory_reinforce<br/><i>Outcome feedback +/-</i>"]
mem_forget["memory_forget<br/><i>Intentional forgetting</i>"]
mem_status["memory_status<br/><i>Per-tier statistics</i>"]
mem_introspect["memory_introspect<br/><i>Self-reflection</i>"]
mem_suppress["memory_suppress<br/><i>Temporary suppression</i>"]
mem_resolve["memory_resolve<br/><i>Conflict resolution</i>"]
mem_reminder["memory_reminder<br/><i>Proactive reminders</i>"]
mem_whynot["memory_why_not<br/><i>Explain recall misses</i>"]
mem_importance["memory_compute_importance<br/><i>Pre-ingestion scoring</i>"]
mem_inspect["memory_inspect<br/><i>Cognitive X-ray</i>"]
mem_export["memory_export<br/><i>Bulk export</i>"]
mem_browse["memory_browse<br/><i>Browse by tag</i>"]
end
end
subgraph Core["In-Process Engine — Zero Network"]
runtime["⚡ SpectorRuntime<br/><i>SIMD search + cognitive memory</i>"]
simd["🔬 SIMD Kernels<br/><i>~100µs per query</i>"]
end
Agents -->|stdio| transport
transport --> registry
registry --> EngineTools & MemoryTools
EngineTools & MemoryTools --> runtime
runtime --> simd
style Agents fill:#1a1a2e,stroke:#e94560,color:#fff
style MCP fill:#16213e,stroke:#0f3460,color:#fff
style EngineTools fill:#0f3460,stroke:#533483,color:#fff
style MemoryTools fill:#533483,stroke:#e94560,color:#fff
style Core fill:#1a1a2e,stroke:#e94560,color:#fff
Agent Interaction Flow
sequenceDiagram
participant Agent as 🤖 AI Agent
participant MCP as 📡 MCP Server (stdio / Streamable HTTP)
participant Tools as 🔧 Tool Registry
participant Runtime as ⚡ SpectorRuntime
participant SIMD as 🔬 SIMD (off-heap)
Note over Agent,SIMD: Everything runs in ONE JVM process — zero network hops
Agent->>MCP: tools/call {"name": "memory_remember", "arguments": {...}}
MCP->>Tools: Route to MemoryRememberTool
Tools->>Runtime: runtime.memory().remember(text, tags, importance)
Runtime->>SIMD: Embed → HNSW insert → tier assignment (~1ms)
SIMD-->>Agent: ✅ {"memoryId": "...", "tier": "EPISODIC"}
Agent->>MCP: tools/call {"name": "memory_recall", "arguments": {"query": "..."}}
MCP->>Tools: Route to MemoryRecallTool
Tools->>Runtime: runtime.memory().recall(query, topK)
Runtime->>SIMD: Fused SIMD scoring: similarity × importance × decay (~0.13ms)
SIMD-->>Agent: 📋 Top memories with scores, tiers, associations
Agent->>MCP: tools/call {"name": "engine_hybrid_search", "arguments": {...}}
MCP->>Tools: Route to EngineHybridSearchTool
Tools->>Runtime: runtime.search().hybridSearch(text, vector, topK)
Runtime->>SIMD: Parallel HNSW + BM25 → RRF fusion (~88µs)
SIMD-->>Agent: 🔍 Ranked results with scores
Why MCP-Native Matters
| Spector (MCP-native) | Typical MCP adapter | |
|---|---|---|
| Architecture | Engine + MCP in one JVM | Python wrapper → HTTP → DB |
| Search latency | 88µs (in-process SIMD) | 5–50ms (network + serialization) |
| Memory recall | 0.13ms (fused scoring) | 50–200ms (Mem0/Letta/Zep) |
| Tools | 21 (6 engine + 15 cognitive) | 3–5 basic CRUD |
| Cognitive features | Decay, Hebbian, consolidation, valence | Key-value store |
| GC pressure | Zero (Panama off-heap) | Full GC overhead |
🧠 Cognitive Memory — AI Agents That Actually Remember
Spector Memory is a biologically-inspired cognitive memory engine that gives AI agents the ability to remember, forget, consolidate, and associate — with microsecond latency and zero garbage collection pressure.
| Capability | What it does |
|---|---|
| 🧠 4-Tier Cortex | Working → Episodic → Semantic → Procedural memory |
| ⚡ 0.13ms recall at 1M memories | 15× faster than the 2ms target (vs. 50–200ms for Mem0/Letta/Zep) |
| 🔗 Fused SIMD Scoring | Similarity × importance × decay in a single pass — no truncation trap |
| 🛏️ Sleep Consolidation | Hippocampus-inspired pruning and partition rebuild |
| 😱 Emotional Valence | Amygdala-driven positive/negative/neutral tagging |
| 🚫 Zero GC | 100% off-heap Panama storage (≤0.01% overhead measured) |
✨ Key Capabilities
| Capability | Technology | Performance |
|---|---|---|
| 🤖 Agent-Native (MCP) | Model Context Protocol · 21 tools · stdio + Streamable HTTP | Claude · Cursor · autonomous agents |
| ⚡ SIMD Search | Java Vector API (AVX2/AVX-512/NEON) | 88µs p50 · 61K QPS |
| 🧊 Off-Heap Storage | Panama MemorySegment · zero-copy I/O | 0.01% GC overhead |
| 🗜️ Quantization | SVASQ-8/4 · IVF-PQ · FWHT rotation | 4–32× compression · 99.5% recall |
| 🔍 Hybrid Search | HNSW + BM25 + RRF + LLM re-ranking | Sub-ms latency |
| 🖥️ GPU Acceleration | CUDA via Panama FFM | Optional · zero-copy transfer |
| 📦 Flexible Deployment | Embedded JAR · Standalone · Distributed | Zero to cluster in one config |
📸 Demo
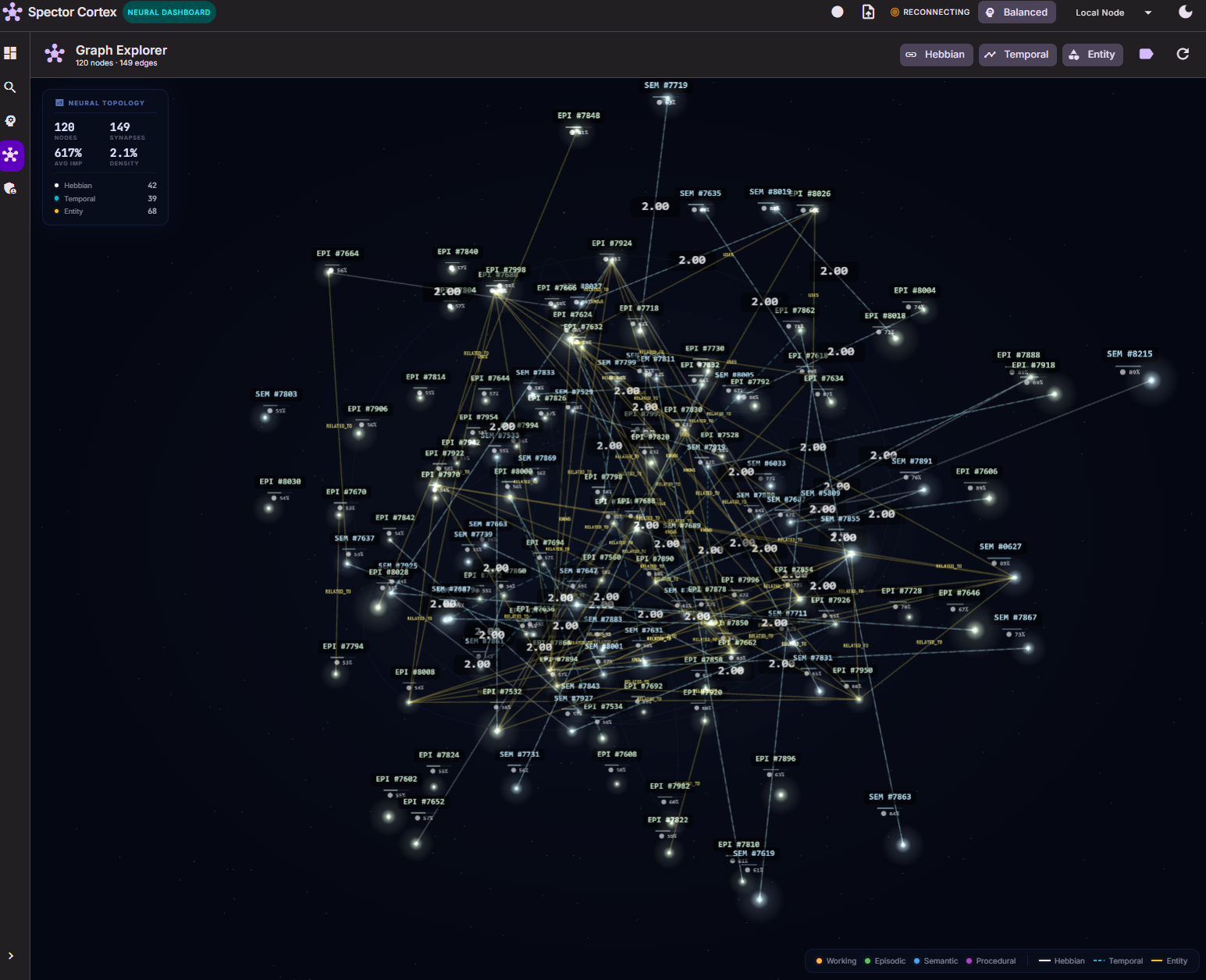
🎥 Watch the Neural Graph in action →
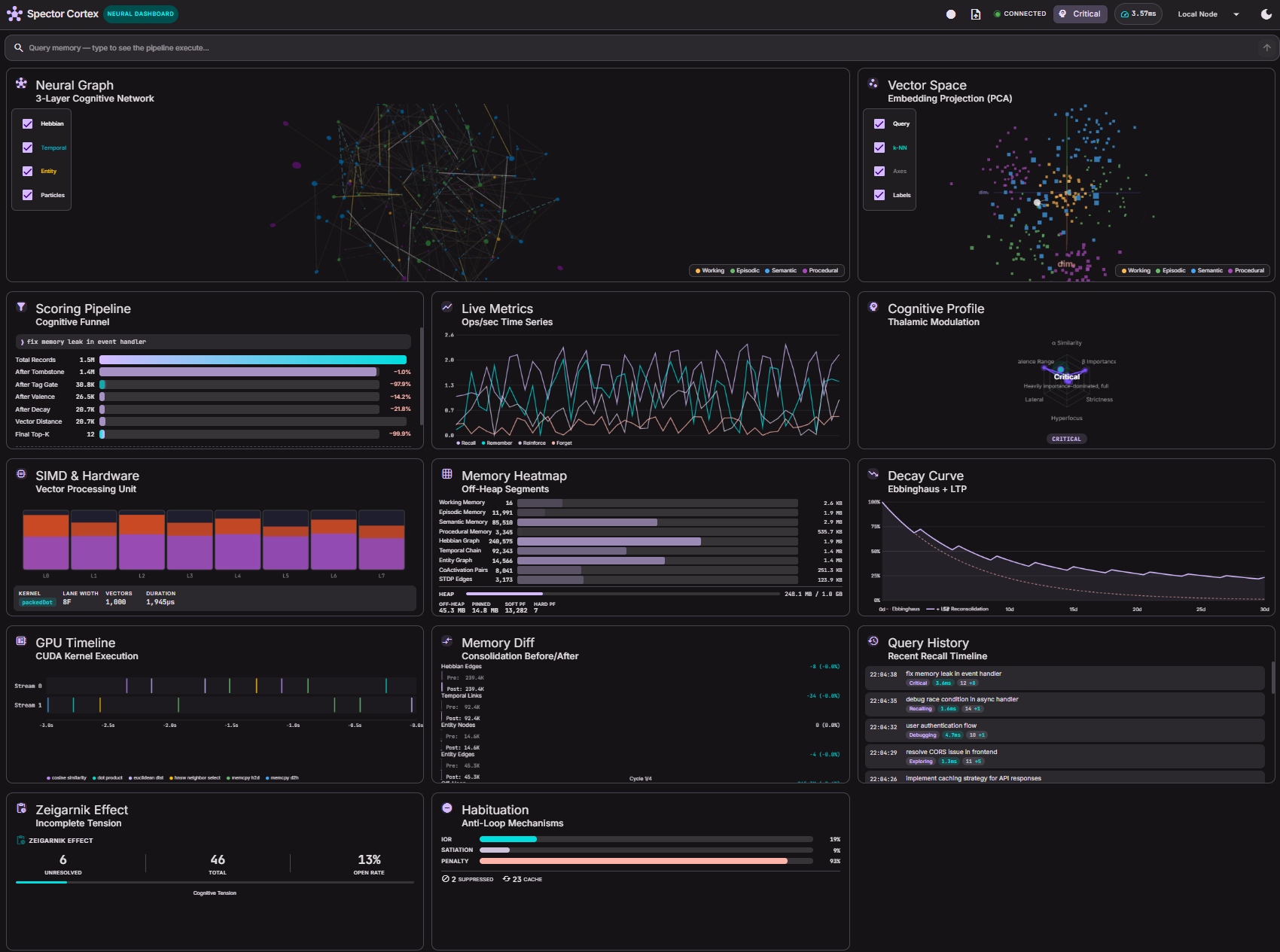
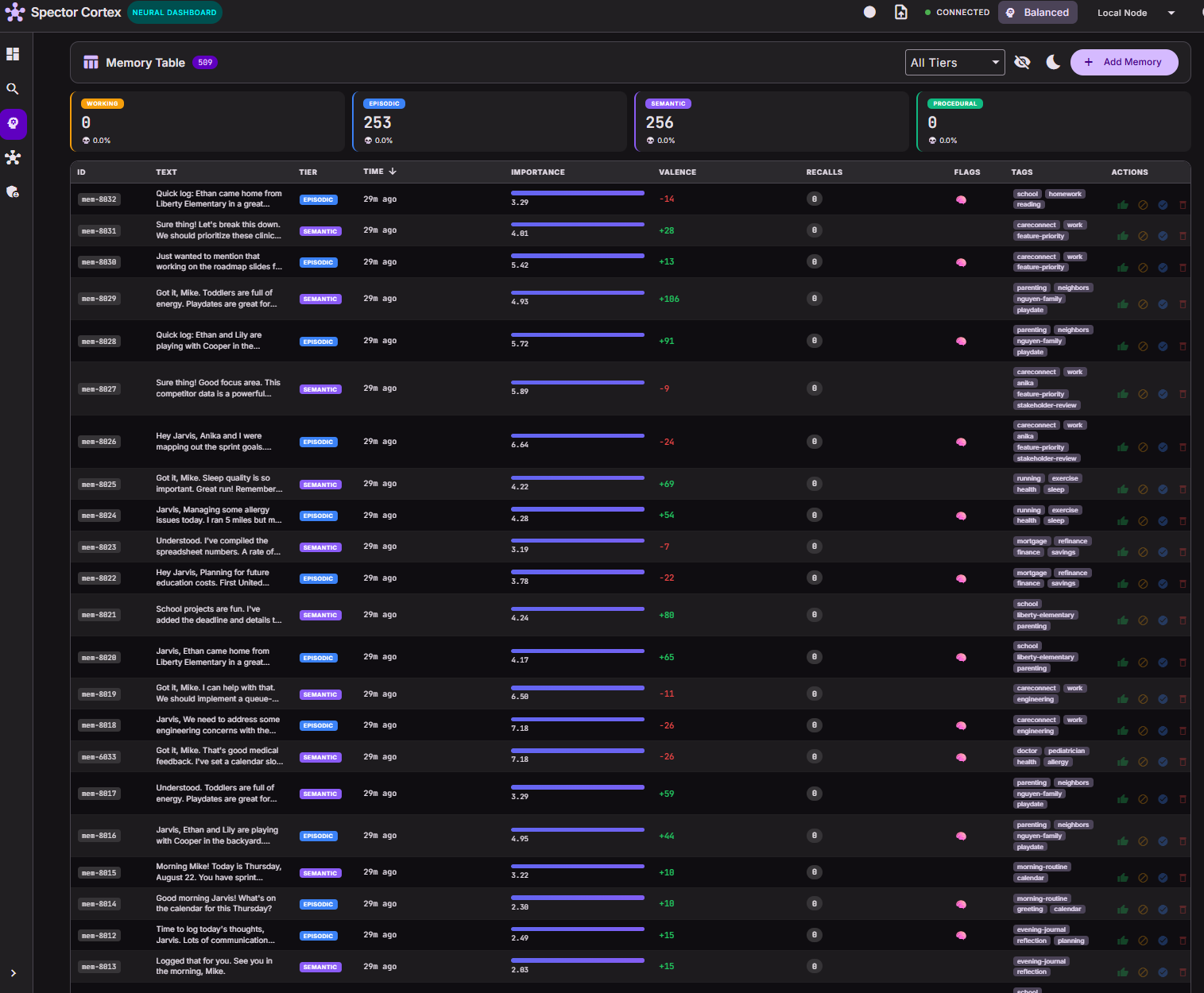
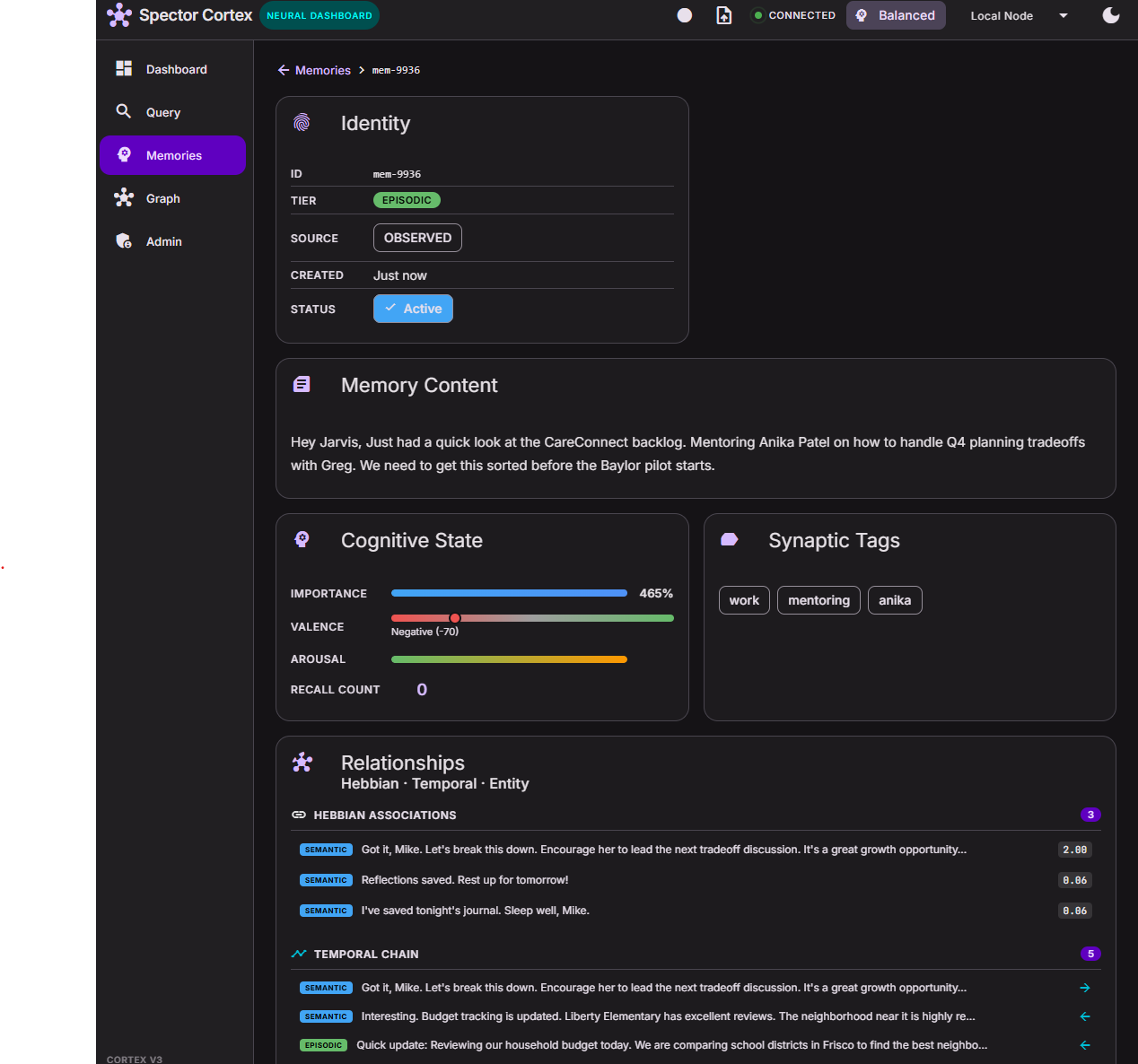
🚀 Quick Start
Prerequisites: JDK 25+, Maven 3.9+
git clone https://github.com/spectrayan/spector.git
cd spector
mvn clean test # Build & run all 685+ tests
mvn package -pl spector-dist -am -DskipTests # Build the distribution JAR
Start the MCP server (for AI agents):
java --add-modules jdk.incubator.vector \
--enable-native-access=ALL-UNNAMED --enable-preview \
-jar spector-dist/target/spector.jar \
--config spector.yml
Claude Desktop config — add to claude_desktop_config.json:
{
"mcpServers": {
"spector": {
"command": "java",
"args": [
"--add-modules", "jdk.incubator.vector",
"--enable-native-access=ALL-UNNAMED",
"--enable-preview",
"-jar", "/path/to/spector-dist/target/spector.jar",
"--config", "/path/to/spector.yml"
]
}
}
}
📊 Benchmarks
All numbers measured on Intel Core Ultra 9 285K, Java 25, AVX2 256-bit.
| Benchmark | Result | Notes |
|---|---|---|
| Vector search p50 | 88–143µs | 10K–100K docs, HNSW M=16 |
| Cognitive recall at 1M | 0.13ms p50 | 15× better than 2ms target |
| Peak QPS (16 threads) | 61,011 | Concurrent vectorSearch |
| GC overhead | 0.01% | 1 pause / 100K searches |
| vs. Python MCP servers | 23–113× faster | In-process SIMD, zero network |
📖 Documentation
| I want to... | Start here |
|---|---|
| Use Spector | Quick Start · Installation · Configuration |
| Connect an AI agent | MCP Server Guide · Claude Desktop Config |
| Add cognitive memory | Memory Overview · Getting Started · Use Cases |
| Use the Java SDK | Java SDK Guide · Spring AI Integration |
| Deploy to production | Docker Deployment · Performance Tuning |
| Extend with Enterprise | Spector Enterprise — LLM providers, Cortex dashboard, data connectors |
🤝 Contributing
We welcome contributions of all kinds — code, docs, tests, benchmarks, and ideas!
- 🐛 Found a bug? → Open an Issue
- 💡 Have an idea? → Start a Discussion
- 🔧 Want to contribute code? → See CONTRIBUTING.md
- 🤖 AI-assisted PRs welcome!
⭐ Star History
📄 License
This repository uses a split licensing model:
spector-memory— Business Source License 1.1 (transitions to Apache 2.0 on May 27, 2030)- All other modules — Apache License 2.0
For branding and trademark guidelines, see the NOTICE file.
🔒 Security
See SECURITY.md for our security policy and vulnerability reporting.
🙏 Acknowledgments
See ACKNOWLEDGMENTS.md for credits to the cognitive science researchers, open-source frameworks, and AI coding tools that made Spector possible.
Built with ⚡ by Spectrayan
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found