autonomous-ai-agency
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Autonomous AI Agent Infrastructure Platform — OpenAI-compatible AI gateway with MCP support, multi-agent orchestration, tool calling, observability, memory, RAG, AI workflows, and unified infrastructure for any LLM provider.
Autonomous AI Agency
Your first AI hire comes with an entire agency.
Self-hosted · Privacy-first · One URL to start
![]()
![]()
![]()
![]()
The problem Autonomous AI Agency solves
You're running a small or medium-sized company. You know AI could help — but the reality is messy:
- Claude Code, Codex, and equivalent agentic platforms don't automatically do the work. They need prompting, PR creation, test execution, CVE checks, and doc updates — and all of that requires skills setup and workflow creation that most teams never get right.
- Your context isn't getting built. Every prompt you send to Copilot or Claude is training data for someone else's model. The model gets smarter, but your agents don't learn your codebase, your preferences, or your business rules. Context built for your agents stays yours — it compounds over time and makes the next run faster and smarter than the last.
- Monthly SaaS bills are stacking up. Copilot + Notion AI + Jasper + SEO tool + monitoring tool = hundreds of dollars a month per person, and they don't talk to each other.
- "AI agents" are mostly demos. They hallucinate, they can't commit code, they don't remember yesterday, and they crash silently. Where AI agents genuinely help is running the full operations of a company — autonomously, end to end — in a managed platform that brings only the decisions that matter to you for approval.
Autonomous AI Agency is the answer to all of this. It is a self-hosted AI agency — a platform that provisions a full fleet of specialist agents for your business from a single website URL, runs them 24x7 on hardware you control, and brings only the decisions that matter to you for approval.
What you get
Paste one URL. Walk away. Come back to a working AI team.
https://yourcompany.com
↓
[Autonomous AI Agency]
↓
CEO agent + specialist fleet
running 24x7 on your server
↓
Bug fixes · PRs · blog posts · CVE scans · SEO · support replies
— with your approval before anything ships
No config files. No integration wiring. No per-seat pricing. No data leaving your server.
Screenshots
Captured from a live deployment. Regenerate with
python scripts/capture_screens.py, thenpython scripts/sync_readme_gallery.py.
See the full UI tour below — every screen, desktop and mobile.
Who is this for?
The 5-person SaaS startup that can't afford a full team yet
You ship fast but quality suffers. PRs pile up. Docs go stale. Dependencies rot. The security audit you've been meaning to run has been in the backlog for six months.
With Autonomous AI Agency:
- A Dev specialist reviews every PR while you sleep and leaves inline comments
- A Security specialist runs a daily CVE scan and opens fix PRs automatically
- A Docs specialist keeps your README and API docs in sync with code changes — on every push
- A Release manager bumps the version, writes the changelog, tags, and opens the release PR — you just approve
Result: A team that works at night, never asks for a raise, and doesn't need you to explain the codebase.
The e-commerce shop with a 10-person ops team
You're running Shopify or a custom store. Your team spends half their time on tasks a machine could do: updating product descriptions, checking for broken pages, triaging support tickets, monitoring SEO rankings.
With Autonomous AI Agency:
- An E-commerce specialist monitors your storefront every 30 minutes for uptime issues, TLS expiry, and stack changes
- A PIM specialist keeps product descriptions, attributes, and taxonomy consistent
- A Support specialist triages incoming tickets, drafts responses, and flags edge cases for human review
- An SEO specialist runs Screaming Frog-class site audits (103 checks across SEO/GEO/AEO/AIO pillars), quantifies findings as revenue-at-risk, can auto-fix issues when your repo is connected (dry-run diffs by default;
apply=truewrites changes), and delegates the rest as WSJF-prioritized tasks — see docs/seo-audit.md - A Content specialist writes product copy and blog drafts from a brief you drop in plain English
Result: Your ops team focuses on decisions, not repetitive maintenance.
The digital agency running 10 client accounts
You manage multiple companies' tech stacks. Right now that means 10 sets of credentials, 10 monitoring setups, 10 different runbooks.
With Autonomous AI Agency:
- Each client gets their own company profile with its own agent fleet, knowledge graph, and schedules
- Agents are isolated per tenant — no cross-contamination of client data or context
- One dashboard to see the health of all clients, with per-client HITL approval flows
- On-call handoff is automatic — agents brief you when they find something, not at 3 AM when the site is down
Result: The same ops coverage you'd charge for a full-time hire, at marginal infrastructure cost.
The professional services firm that runs on documents and tribal knowledge
Your company's knowledge lives in Slack threads, email chains, and the heads of people who might leave next month.
With Autonomous AI Agency:
- The Knowledge specialist reads your code, docs, Slack exports, and past decisions and builds a living internal wiki — updated automatically when things change
- The Research specialist monitors industry trends, competitor moves, and technology updates and drops weekly digests
- The Portfolio manager tracks initiatives, surfaces blockers, and runs weekly stand-up summaries
- Every agent response comes with sources and reasoning — nothing is a black box
Result: Knowledge that doesn't walk out the door.
How it works — the 5-minute version
- Paste your website URL.
https://acme-store.com - Autonomous AI Agency scans it. Playwright + HTTP fingerprinting detects your tech stack, business systems, and integrations (Shopify, Stripe, Google Analytics, GitHub, Intercom, Salesforce, …).
- It asks you the right questions. AI-generated onboarding questions based on what it found — not generic forms.
- Specialists are auto-provisioned. A fleet of agents is assembled from 35 specialist families — exactly the ones your business needs, with the right runtimes and skills bound.
- Schedules activate. Health scans, security audits, code quality checks, SEO monitoring, graph sync — all running on their own cadence without manual setup.
- You talk to the CEO in plain English. "Fix the memory leak in issue #142." "Write the Q3 launch post." "Plan next sprint." The CEO decomposes the job, delegates to the right specialist, and returns a result with evidence — PR link, test output, diff, reasoning trace.
- You approve what matters. Agents never merge code, deploy, or send external messages without your explicit sign-off. Low-risk tasks (formatting docs) can be auto-approved. High-stakes decisions (production deployments) always pause for you.
The 24x7 agency — your agents never go idle
The defining feature of Autonomous AI Agency is not what agents can do — it's that they keep doing it, automatically, even when you're not watching.
What runs automatically after onboarding
| Schedule | Cadence | What it does |
|---|---|---|
| Website health scan | Every 30 min | Uptime, TLS expiry, stack drift detection |
| Security audit | Daily 9 AM | CVE scan, security headers, repo secret scan |
| Stack change detection | Daily 6 AM | New frameworks, dropped libraries, new integrations |
| Code quality scan | Daily 12 PM | Lint, duplication, complexity, stale dependencies |
| Trend watch | Every 6 hrs | Model releases, framework updates, competitor tech |
| Company graph sync | Every 30 min | Specialist health, runtime responsiveness, schedule status |
| Doc-sync | On every push | API docs, architecture records, and runbooks auto-updated |
When something goes wrong, agents fix it — not you
Health scan detects broken page at 3 AM
↓
Security or Dev specialist creates a fix task automatically
↓
Agent branches, writes fix, opens PR, watches CI
↓
CI green + low-risk → auto-approve gate passes, PR merges
CI green + needs human eyes → surfaces to your dashboard
↓
You see it in the morning: "PR merged, page restored at 3:12 AM"
Nothing goes down quietly
| Failure scenario | Countermeasure |
|---|---|
| Agent crashes mid-task | Crash-recovery reconciler re-queues stranded tasks on restart |
| Runtime sidecar goes to sleep | Every CEO delegation calls RuntimeManager.wake_all_sleeping_runtimes() first — sleeping sidecars are woken or marked still_sleeping, and the CEO routes around whichever stay down |
| AI session rate-limited / exhausted | ai_runner.py watchdog detects the gap and resumes from last checkpoint |
| LLM provider goes down | Provider chain: Bedrock → NIM → DeepSeek → Anthropic → Ollama — automatic failover |
| Missed schedule | Scheduler reconciles on boot — nothing is silently skipped |
| Context lost between sessions | Company Graph + persistent chat history give full context on every wake |
Two layers, plain English: Portfolio Management vs. Loop Engineering
People often ask how the portfolio process differs from loop engineering. They sound similar — both are about the agency running itself — but they answer two different questions and work at two different layers. You need both.
The kitchen analogy. Imagine a restaurant that runs itself.
- Portfolio Management is the manager deciding what to cook tonight — which dishes are worth the kitchen's limited time, based on what sells and how much effort each takes.
- Loop Engineering is the kitchen line that actually cooks the food, tastes it, and re-cooks anything that's wrong — on its own, every night, without someone standing over it.
The manager points the kitchen at the right work; the kitchen is the machine that does the work and keeps itself running. A great manager with no kitchen ships nothing; a great kitchen with no manager cooks the wrong food.
What they have in common
- Both let the agency operate without you micromanaging every step.
- Both are continuous — they run on a cadence, not once.
- Both feed each other: the portfolio decides priorities; the loops carry them out and report back what got done.
Where they differ
| Portfolio Management | Loop Engineering | |
|---|---|---|
| The question it answers | What should we work on, and in what order? | How does the work get done — and stay healthy — without me? |
| Layer | Deciding / prioritising (strategy) | Doing / orchestrating (execution) |
| How it decides | WSJF — ranks big initiatives by value ÷ effort and lays out a Now / Next / Later roadmap | A repeating schedule → do → check → fix → repeat cycle with memory and self-healing |
| Time horizon | Weeks to quarters (epics, roadmap) | Seconds to hours (each run, continuous) |
| If it's missing | The agency works hard on the wrong things | The right work never actually gets done or maintained |
The neat part: in this repo, the portfolio process is itself just one of the loops. The roadmap refresh runs on its own cadence (every 6 h) like every other autonomous loop — catalogued alongside the rest in loops/registry.yaml. So Loop Engineering is the operating model for the whole machine, and Portfolio Management is the planning discipline that one of those loops runs to aim the others.
One line to remember: Portfolio Management points the machine at the highest-value work; Loop Engineering is the machine that runs itself.
The full agent capability roster
Engineering
| What you say | What the agent does |
|---|---|
| "Fix the bug in issue #142" | Reads issue, reproduces, writes fix, opens PR, watches CI, awaits your approval |
| "Audit our dependencies" | Scans for CVEs, generates an upgrade plan with test coverage, opens a safe PR |
| "Review this PR" | Multi-perspective analysis: security, correctness, performance, maintainability — inline comments |
| "Write tests for the auth module" | Generates unit + integration tests with realistic fixtures |
| "Do a release" | Bumps version, writes changelog, tags, runs CI, opens release PR |
| "Refactor the payment service" | Identifies coupling issues, proposes a plan, executes on approval |
| "Keep docs in sync" | After every push: updates API docs, architecture records, runbooks automatically |
Content & knowledge
- Write product descriptions, landing pages, blog posts, and case studies from a brief
- Summarise and classify GitHub issues, Slack threads, and support tickets
- Maintain an internal wiki — agents update pages when code or decisions change
- Weekly trend digests: new model releases, framework updates, industry moves
Operations & DevOps
- Monitor CI/CD pipelines; alert when something needs a human decision
- Schedule daily summaries, weekly audits, and on-call handoff briefs
- Route every LLM request to the optimal local model (code → Qwen3-Coder, reasoning → DeepSeek-R1)
- Real-time health diagnostics for all agents, runtimes, and providers
Agile, portfolio & product
- Agentic agile: standups, retrospectives, sprint reviews, backlog grooming — coached cadence, automated artifacts
- Portfolio management: roadmapping, prioritisation, resource allocation, strategy tracking
- Delivery management: sprint planning, release coordination, cross-team unblocking
- Product: turn a brief into user stories, acceptance criteria, and a prioritised backlog
Business & domain specialists (auto-provisioned from the URL scan)
| Detected system | Specialist provisioned |
|---|---|
| Storefront / commerce stack | E-commerce · Merchandising · OMS |
| Product catalog / PIM | PIM (product data, attributes, taxonomy) |
| Media / asset platform | DAM (ingestion, metadata, delivery) |
| CRM / support desk | CRM operations · Support (triage, KB, SLA) |
| Analytics / search / SEO | Analytics · SEO · Content strategist |
| Marketing automation | Marketing (campaigns, attribution, A/B) |
| Research / market data | Trading & market research · Research |
| Cloud / infra / CI | Platform operations · DevOps · Security · CI/fix |
35 specialist families total — engineering + business + domain. Each family has typed I/O contracts, an optimal runtime, and bound Skills.
The skill library — superpowers agents can call
Every specialist can call typed, versioned Skills on demand:
| Skill | What it does |
|---|---|
| ECC | Orchestrate other AI harnesses: Claude Code, Cursor, Codex, OpenCode, Aider |
| Graphify | Query your entire codebase as a knowledge graph — 70x fewer tokens than reading files |
| Council Review | Multi-perspective diff review: security / correctness / performance / maintainability — structured APPROVE / REJECT verdict |
| Obsidian Knowledge Graph | BFS traversal, connected components, tag search over your internal wiki |
| Dependency Audit | CVE scan + safe upgrade PR generation |
| Agentic Agile | Sprint ceremonies, retros, standups as a coached cadence |
| Financial Analyst | Burn rate, runway, gross margin, ROI-based budget reallocation |
| Release Readiness | Gate check before any version tag |
| Docs Sync | Keep API docs and architecture records in sync after code changes |
| Karpathy Guidelines | Behavioral guardrails for coding agents: surface assumptions, minimum viable diff, surgical changes, verifiable success criteria (issue #926) |
The Skill Registry discovers new skills automatically from GitHub repositories — flat or nested layouts — with ETag caching and rate-limit-aware fetching. No restart required.
HITL approval gates — you stay in control
Autonomous AI Agency never merges code, deploys, or sends external messages without your explicit sign-off.
- Agent reaches a decision gate → pauses, surfaces exactly what will happen (the diff, the deploy command, the email body)
- You choose: Approve · Deny · Redirect (send back with comments)
- Gate policy is configurable per task type: auto-approve reformatting, require sign-off on production deployments
This means you get the leverage of a 24x7 team without the risk of autonomous agents acting beyond their mandate.
Live monitoring, self-supervision, and a knowledge base that writes itself
Three capabilities landed in June 2026, each verified end-to-end against the live Cloudflare deployment:
Switchable execution brain. The agent runtime resolves its LLM from a DB-persisted brain config at run time. The Brain card on the Providers screen lets you set the provider and the per-role models (planner / executor / verifier / judge) in one click — persisted in the DB, picked up on the next agent run, no redeploy, no code. Every model is liveness-probed before it's saved, so you can never land on a dead model. The recommended free-cloud chain is Cerebras → Groq → NVIDIA NIM → Ollama, and the brain auto-selects the first provider whose API key is present in the environment — so just adding CEREBRAS_API_KEY switches the brain to Cerebras with no UI step. (You can also run the brain from your own machine — see Running the brain on local Ollama.) Failed runs report failed with the real error — verification results can never be masked as success.
Live alerts (the 🔔 actually rings). The top-right bell derives alerts on every read with zero stored state: failed runs surface as P1, runs awaiting your approval as P2 with a one-tap jump to the Tasks board, and an empty scheduler raises a wipe warning. Because alerts are computed from live platform state rather than a log table, the monitoring layer itself cannot be lost to a restart.
Self-supervising backlog. Three standing cadences run the improvement loop: an agency supervisor (every 4 h) re-files failed runs, picks up unchecked items from the autonomy epic, and verifies PRs exist for completed work; a post-deploy verifier (daily) health-checks Doctor, runs a smoke task, and resurrects the cadences if a deploy wiped them; and a tech-debt burndown (Mon/Thu) that fixes three tracked code markers per run with PRs. Work is tracked where it survives restarts — GitHub issues and PRs — and the operating manual lives in docs/knowledge/agency-operational-knowledge.md, mirrored as a wiki page in the Knowledge screen.
Honest status: schedule and run persistence across redeploys landed (#505) — the
ScheduleStorenow honoursSTORAGE_BACKEND=sqlite(the README's zero-dependency default) as well as Mongo, and theAgentSchedulerrehydrates every company cadence on boot (Hydrated N scheduled job(s) from durable store). The APScheduler worker thread now dispatcheson_firecoroutines onto the FastAPI main loop viaasyncio.run_coroutine_threadsafe, so 24x7 cadences actually produce tasks instead of silently dying on a "Future attached to a different loop" error. Capture-hub FAB (#517) and automatic README/changelog/knowledge ingestion on repo connect (#518) are specced and queued.
Quick Notes — capture ideas from your phone
Drop a task from anywhere — no laptop needed.
- Use an iOS Shortcut or share sheet to POST a URL + instruction
- Autonomous AI Agency's Quick Note processor enqueues it with capped-backoff retry
- The CEO routes it to the right specialist as a normal task
- You see it on the Task Board when you open your laptop
Issue → Context → Draft PR automation
Every GitHub issue is automatically turned into an actionable, codebase-aware
implementation plan — no manual triage required.
issue opened (or `quick-note` label added)
↓
[issue-context-generator workflow]
↓
fetch linked URL (multi-strategy) ──► NVIDIA NIM (free models)
↓ fallback: Claude Opus
generate: implementation prompt + prioritised TODO list
+ relevant files + risk flags, grounded in CLAUDE.md
and the graphify codebase graph
↓
commit docs/context/issue-N.md ──► open DRAFT PR ──► close issue
Why draft PRs? Draft status suppresses CodeRabbit / Copilot auto-reviews,
so the plan lands cleanly without burning review cycles. When you (or the
Process Quick Note workflow) implement against the plan, mark the PR ready
for review.
The workflows
| Workflow | Trigger | What it does |
|---|---|---|
issue-context-generator.yml |
Any issue opened, or quick-note label added |
Fetches the linked URL, generates a grounded prompt + TODO plan, commits docs/context/issue-N.md, opens a draft PR, closes the issue. |
bulk-issue-context.yml |
Manual (workflow_dispatch) |
Backfills all open issues in one run. Supports dry_run, label exclusions, explicit issue_numbers targeting, and regenerate mode (updates an existing draft PR in place — preserves the PR number). |
process-quick-note.yml |
Schedule / manual | Picks up a context branch and implements the plan — runs the agentic loop, tests, applies review feedback, and opens its PR as a draft. Reuses an existing claude/context-issue-N branch so implementation commits land on the pre-built draft PR. |
Free-first model routing
Context generation runs on free NVIDIA NIM models by preference —qwen/qwen3-coder-480b-a35b-instruct → nvidia/llama-3.3-nemotron-super-49b-v1
→ meta/llama-3.3-70b-instruct → qwen/qwen2.5-coder-32b-instruct, with
Claude Opus as a final fallback only if every NVIDIA model is unavailable.
Backfilling existing issues
# Dry run — list what would be processed, change nothing
gh workflow run bulk-issue-context.yml -f dry_run=true
# Process all open issues (skips exhausted / agency-escalation by default)
gh workflow run bulk-issue-context.yml
# Target specific issues; regenerate updates existing draft PRs in place
gh workflow run bulk-issue-context.yml \
-f issue_numbers="416,398,364" -f regenerate=true
Note: the
issues-event auto-trigger only fires once these workflows are
on the default branch (master) — GitHub runs event-triggered workflows
from master only. Before merge, useworkflow_dispatch(thebulk-issue-context
commands above) to process issues from any branch.
Privacy, security, and cost
Your data never leaves your server
Autonomous AI Agency runs entirely on hardware you control. There is no cloud relay, no usage telemetry, no shared inference endpoint. Your code, your prompts, your company graph — all local.
What it costs to run
| What you'd pay elsewhere | Autonomous AI Agency equivalent | Monthly cost |
|---|---|---|
| GitHub Copilot (5 seats) | Dev specialist on Qwen3-Coder | $0 (local GPU) or ~$5 (NIM) |
| Notion AI | Knowledge specialist | $0 |
| Jasper / Copy.ai | Content specialist | $0 |
| Snyk / Dependabot Pro | Security specialist | $0 |
| A part-time DevOps engineer | Platform ops + CI/fix specialists | $0 |
| Total comparison | Autonomous AI Agency on a $10 VPS | ~$10/month |
Marginal inference cost is electricity. Scale a 50-person team for the same server bill.
Security posture
- No secrets in source — all config via environment variables; nothing hardcoded
- RBAC: three roles —
user,power_user,admin - JWT Bearer auth on every API endpoint; configurable expiry
- Ed25519 instance activation — tamper-evident licensing
- Audit log for all admin actions
- Bandit SAST + CodeQL + secret scanning on every push
- Dependency CVE audit on every PR
- Per-task git worktree isolation — concurrent agents can't clobber each other
The V5 Control Plane — every screen
The dashboard has 18 fully-wired screens, all backed by live API endpoints:
| Screen | What it does |
|---|---|
| Chat | Conversational interface to the CEO agent; persistent history, ModelPicker, code-task repo URL |
| Dashboard | Live health of all agents, recent activity, system metrics at a glance |
| Task Board | Kanban: queued → planning → executing → review → awaiting approval → done; sprint metrics + burndown |
| Agents | All specialists: capabilities, current load, runtime, model, task stats — includes the runtime status bar (Hermes, OpenCode, Claude Code, …) and health per specialist |
| Schedules | Recurring agent tasks; pause, resume, trigger, view run history; signal-driven instructions |
| Skills | The skill library — dynamic registry with local + remote GitHub discovery, auto-recommendations per tech stack |
| Portfolio | WSJF-prioritized initiatives with Now/Next/Later roadmap, source-provenance badges, sprint-health rollup |
| Intelligence | Routing policy editor — model, cost tier, task-type rules; competitor/keyword tracking |
| Knowledge | Wiki pages, source docs, and agent activity — the team's persistent, self-updating memory |
| Providers | Connected LLM providers (Ollama, Bedrock, Nvidia NIM, 17 clouds) with health + cost; MCP server CRUD |
| Loops | Every autonomous loop catalogued: readiness score, maturity, self-heal coverage, drift status, cost estimate |
| Logs | Every LLM call: tokens, latency, provider, cost, decision context; expandable messages |
| GitHub | Connected repos, PR management, issue tracking, repo scanner with authenticated API access |
| Company | Organisation profile, tech stack detection, knowledge graph seed, system status badges |
| Onboarding | Company setup wizard — URL scan → AI questions → specialist provisioning → 24x7 schedules |
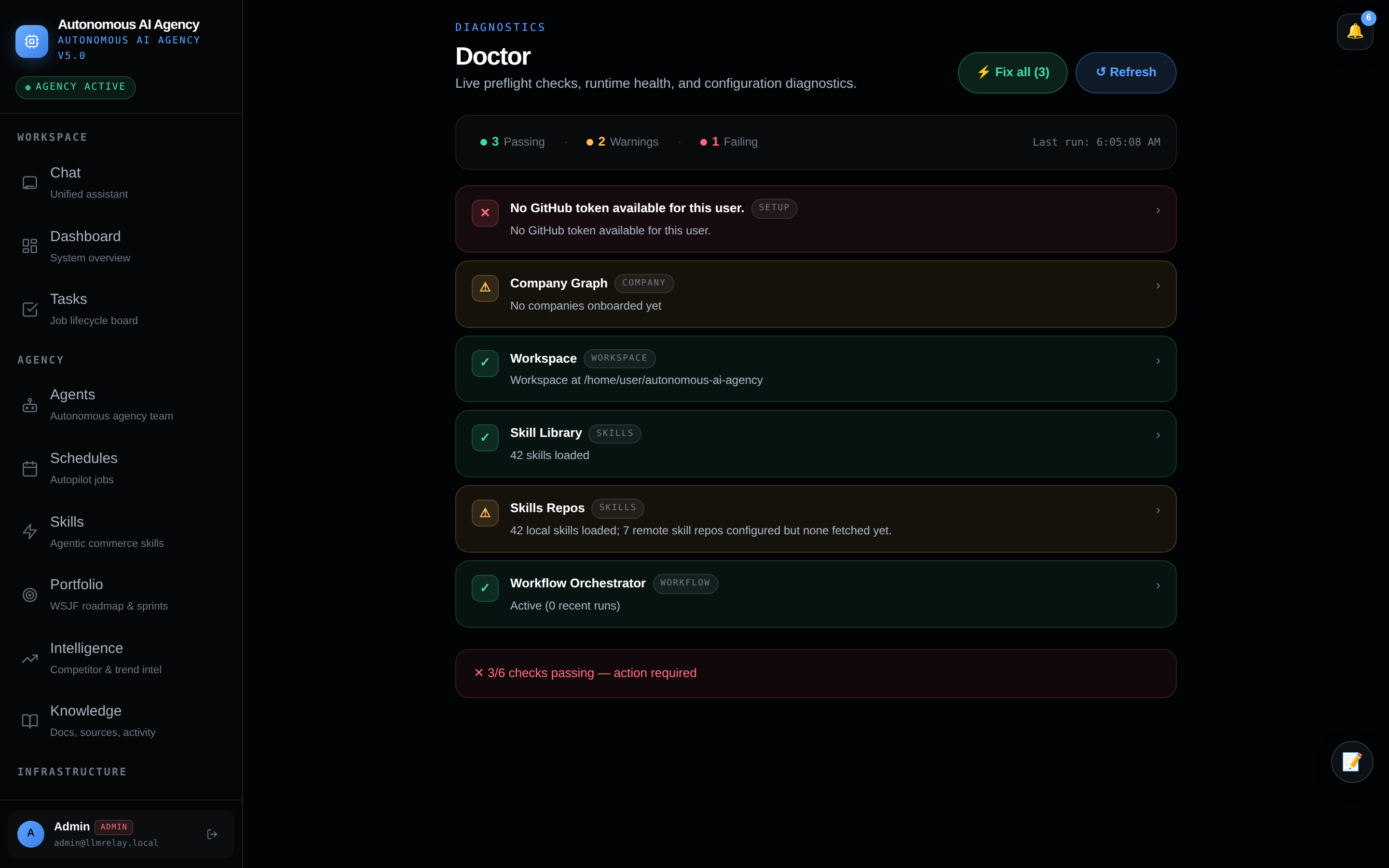
| Doctor | Live self-diagnostics — per-check pass/warn/fail scores, one-click Fix buttons, auto-refresh every 60s |
| Admin | Users, roles, instance activation, audit log, company management with delete cleanup |
| SAM | Voice command and control of the agency — push-to-talk Web Speech API STT/TTS by default, hands-free live conversation when LiveKit is configured |
The standalone "Runtimes" screen from earlier versions was folded into Agents (per-specialist runtime + health) and Doctor (aggregate runtime health panel) — there's no separate Runtimes page anymore.
Screens
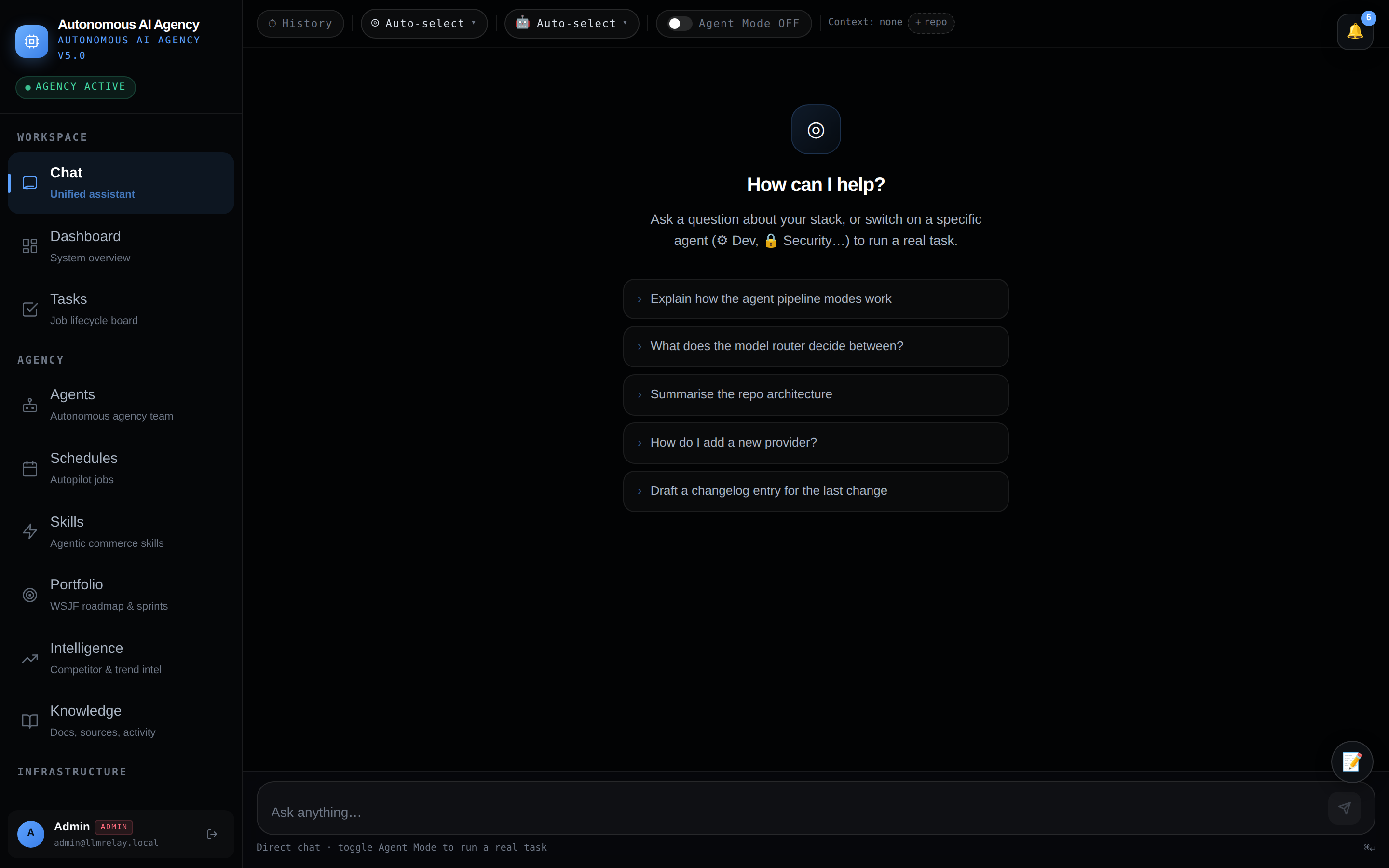
💬 Chat — unified assistant
Talk to the CEO agent directly; it decomposes goals and routes work to the right specialists.
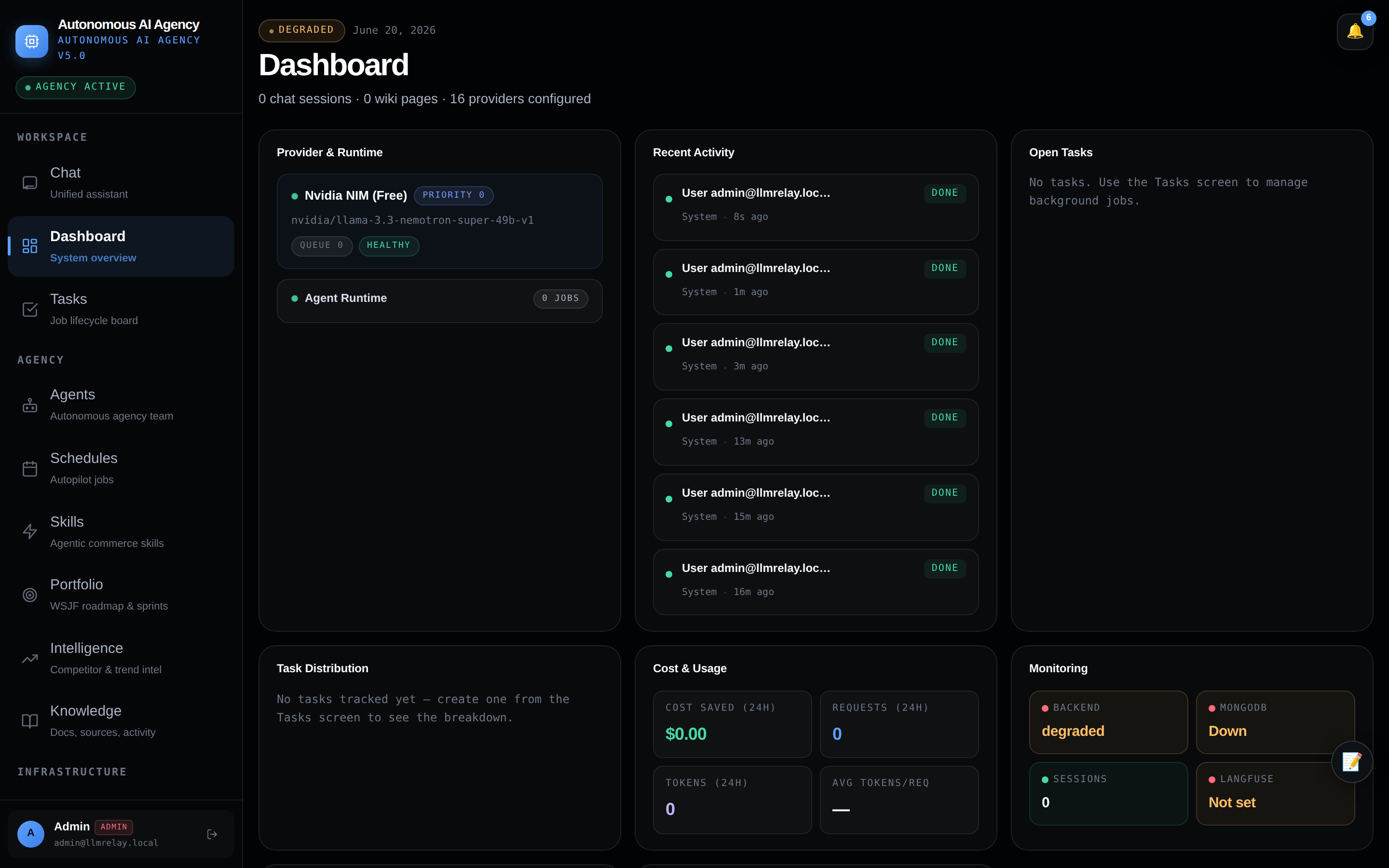
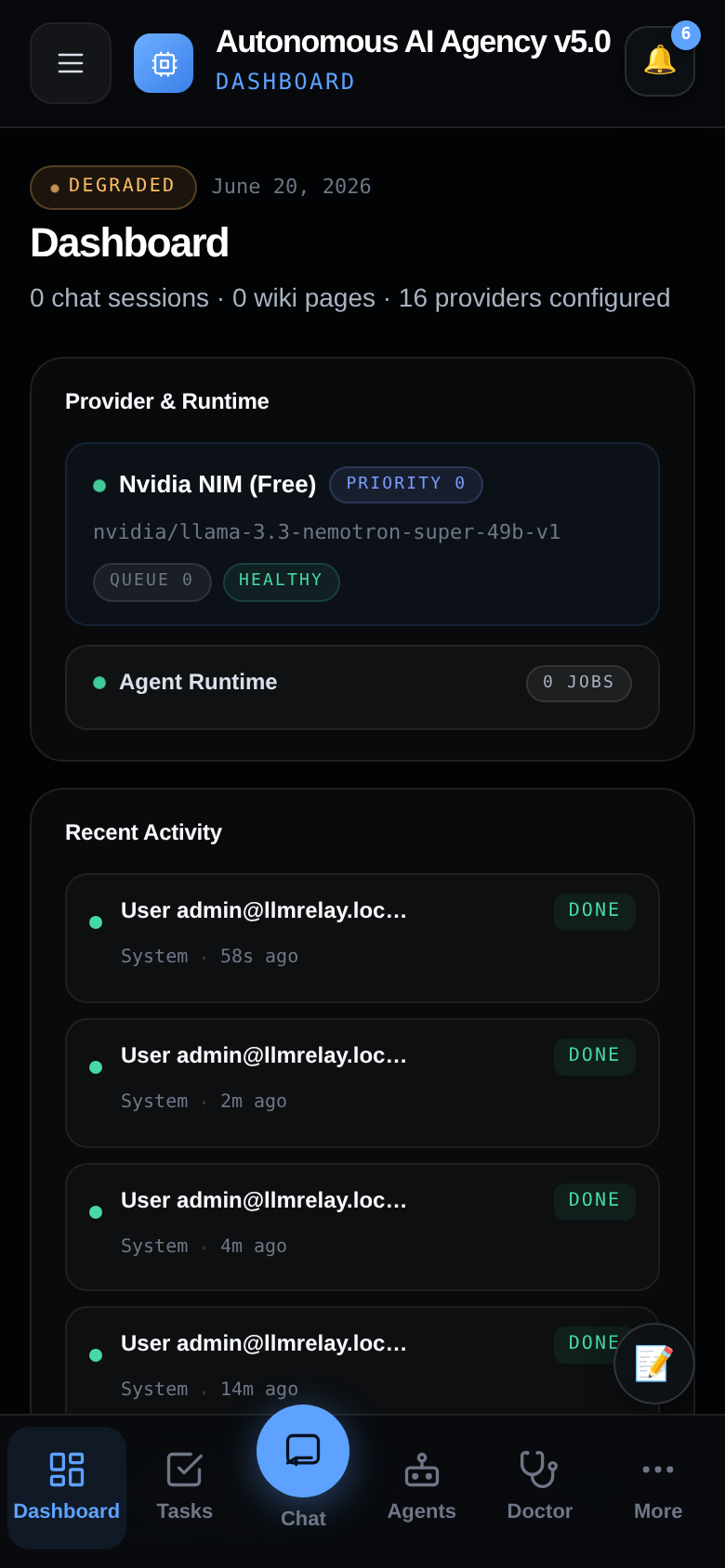
📊 Dashboard — system overview
Live agent health, recent activity, and system metrics at a glance.
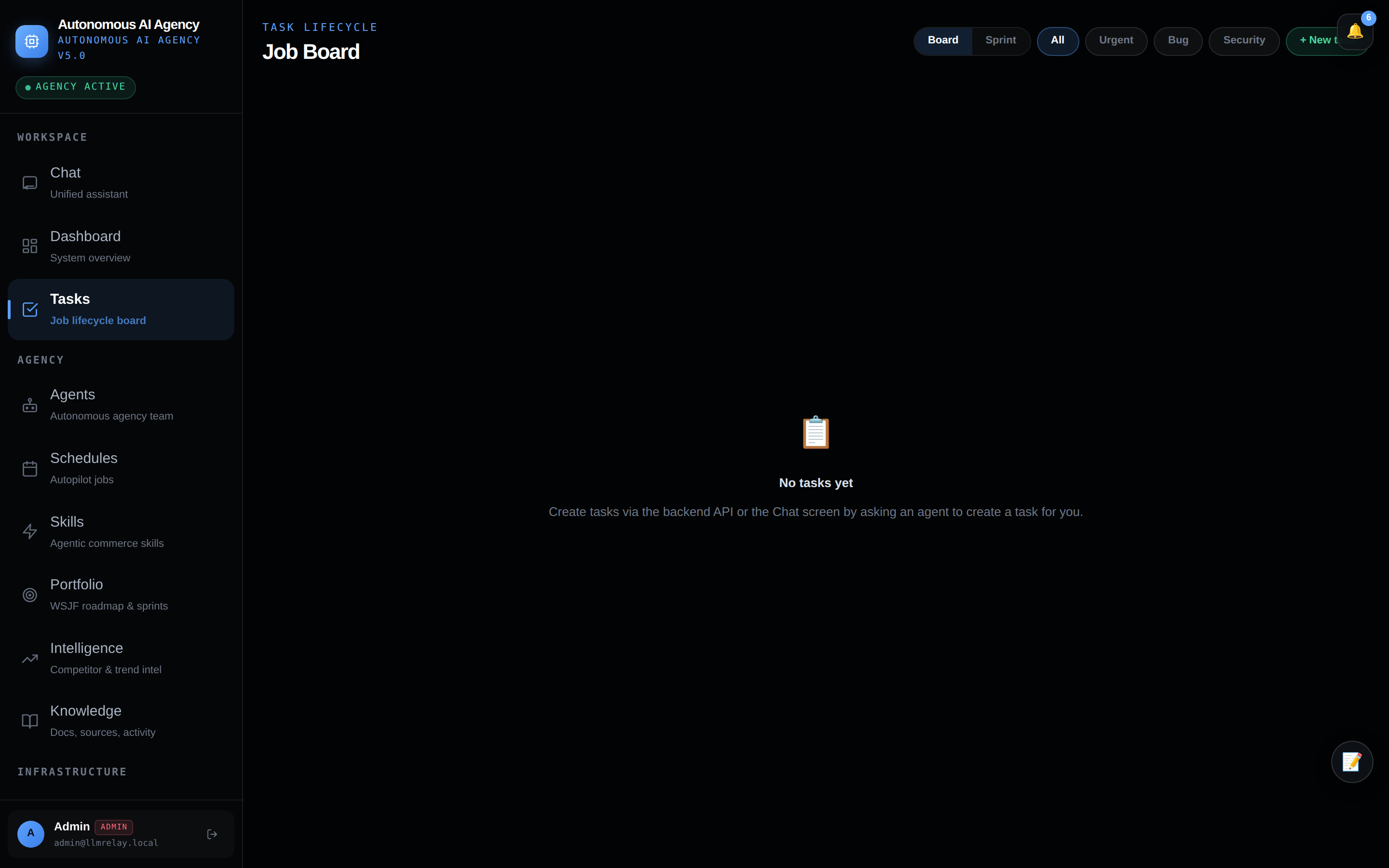
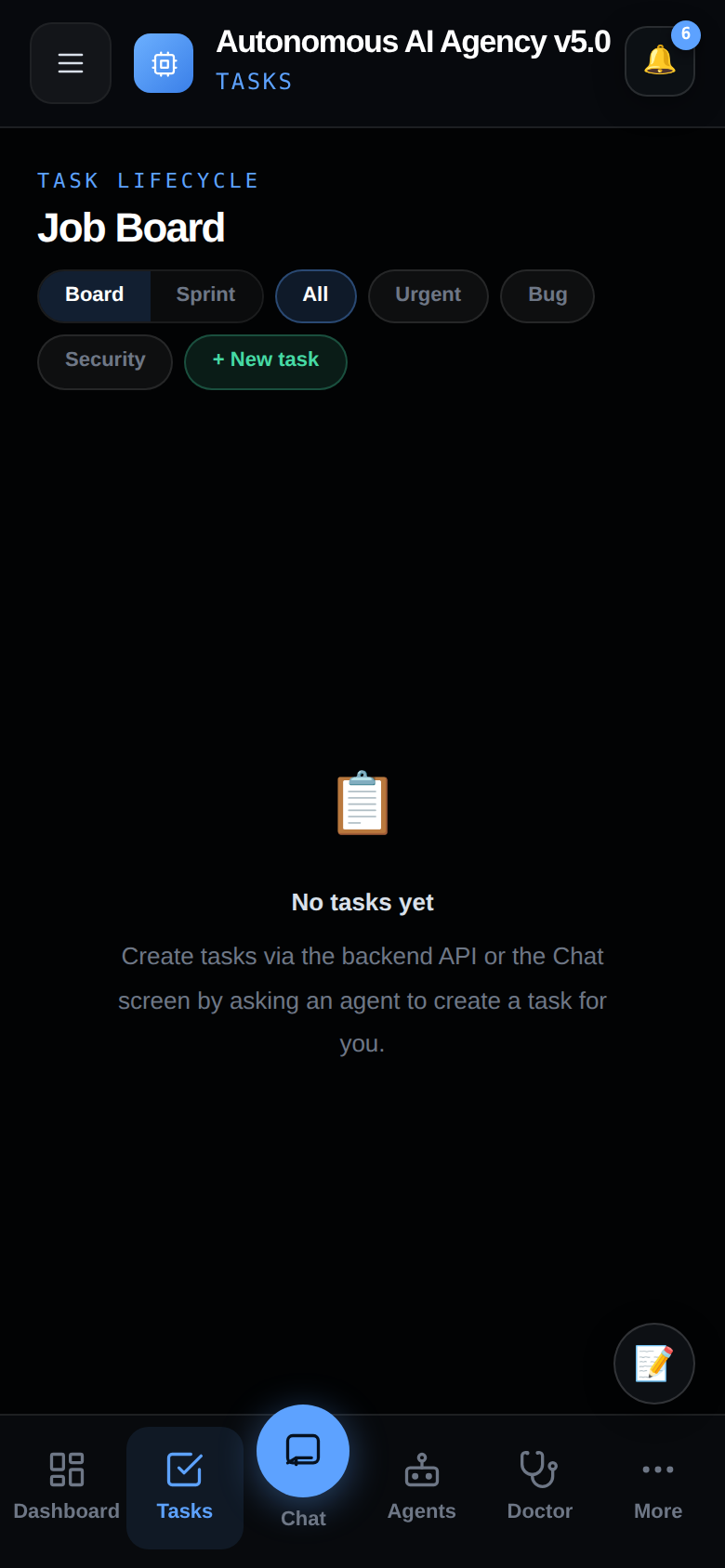
🗂 Tasks — job lifecycle board
Every AI job made visible: waiting, running, blocked, in review, or done.
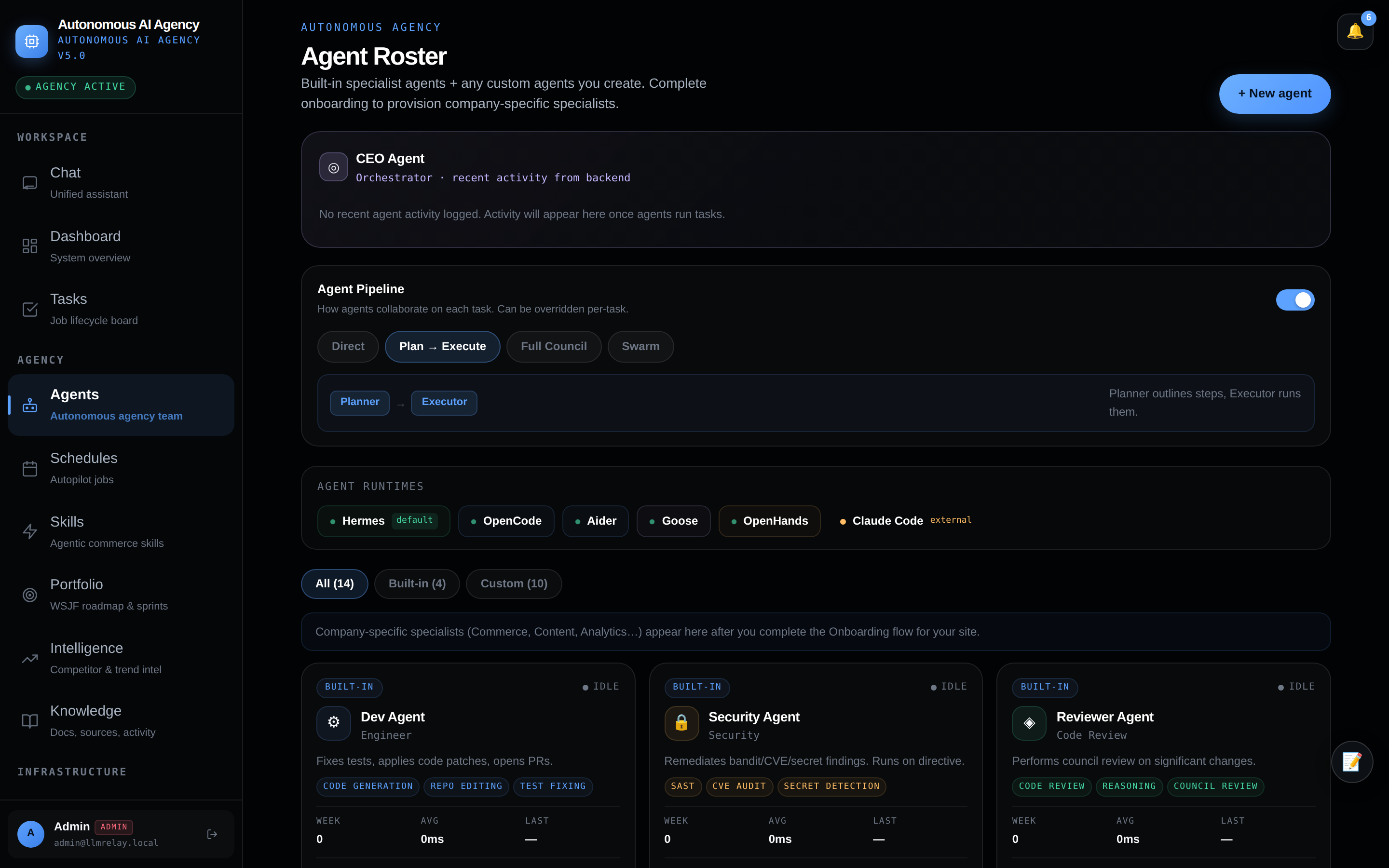
🤖 Agents — autonomous team
Your specialist roster — each with its own model, runtime, specialty, and guardrails.
🗓 Schedules — autopilot jobs
Recurring and scheduled autonomous work.
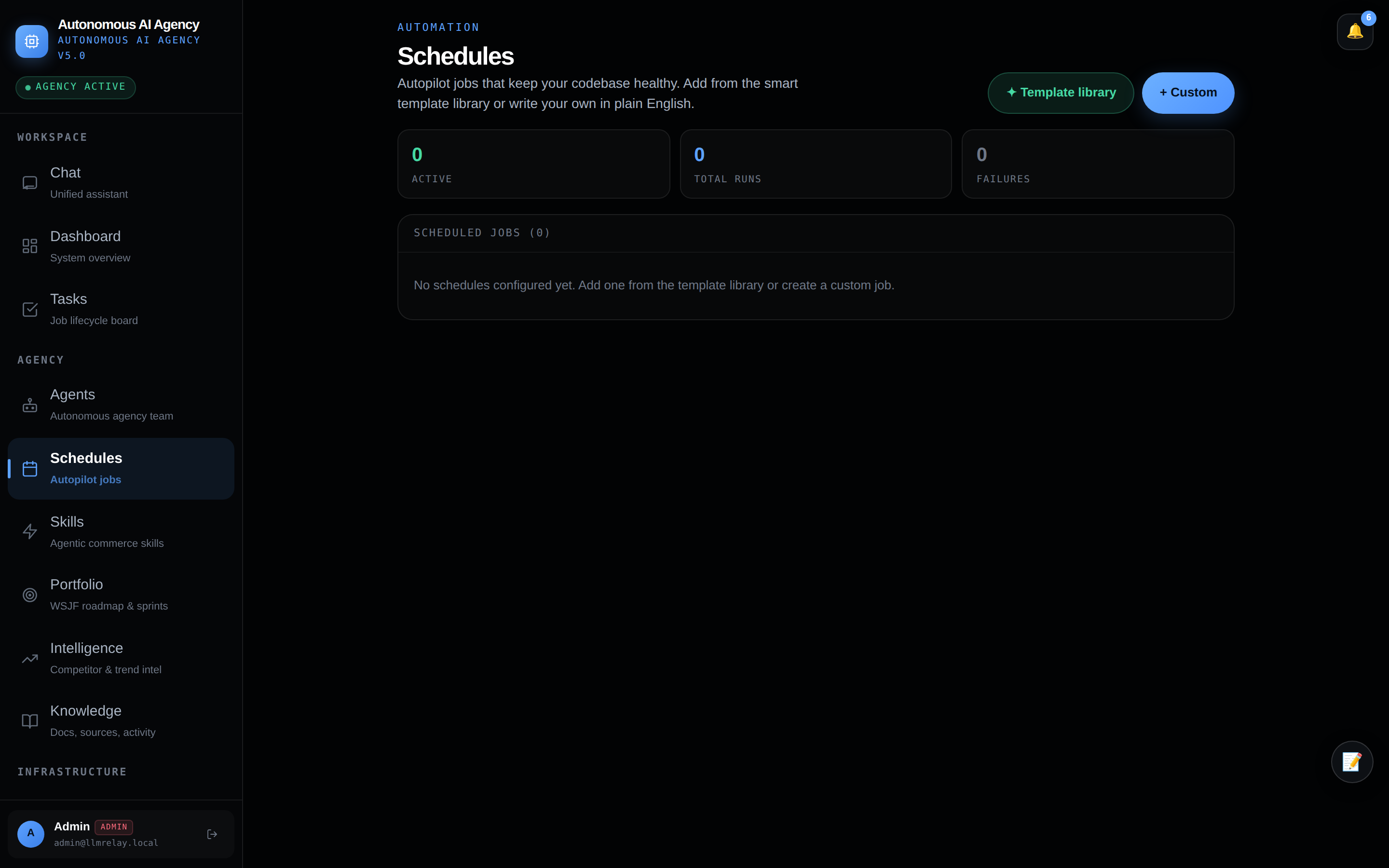
⚡ Skills — agentic capabilities
Reusable runtime skills bound to specialists.
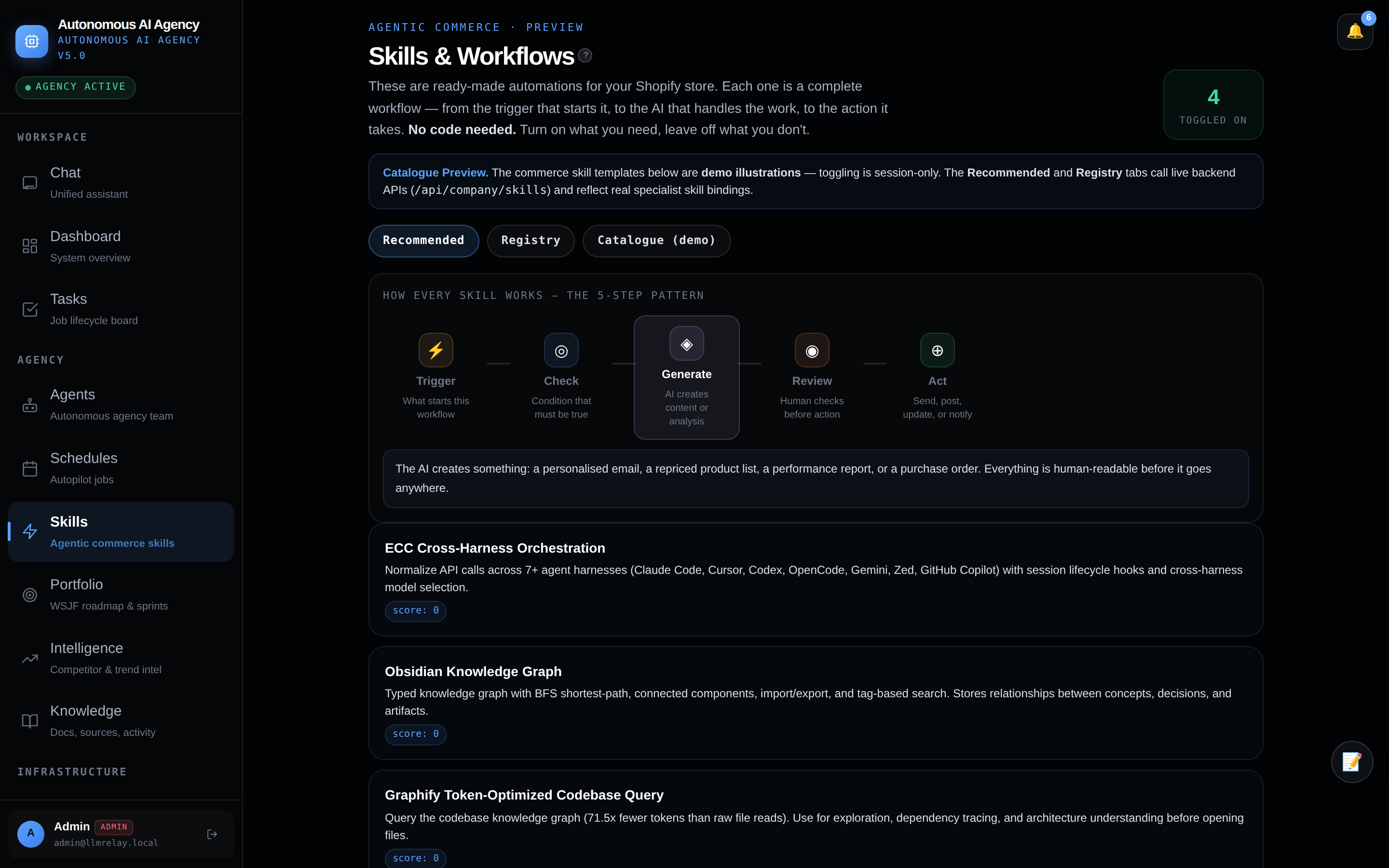
🎯 Portfolio — WSJF roadmap
Prioritised initiatives, sprints, and agile health.
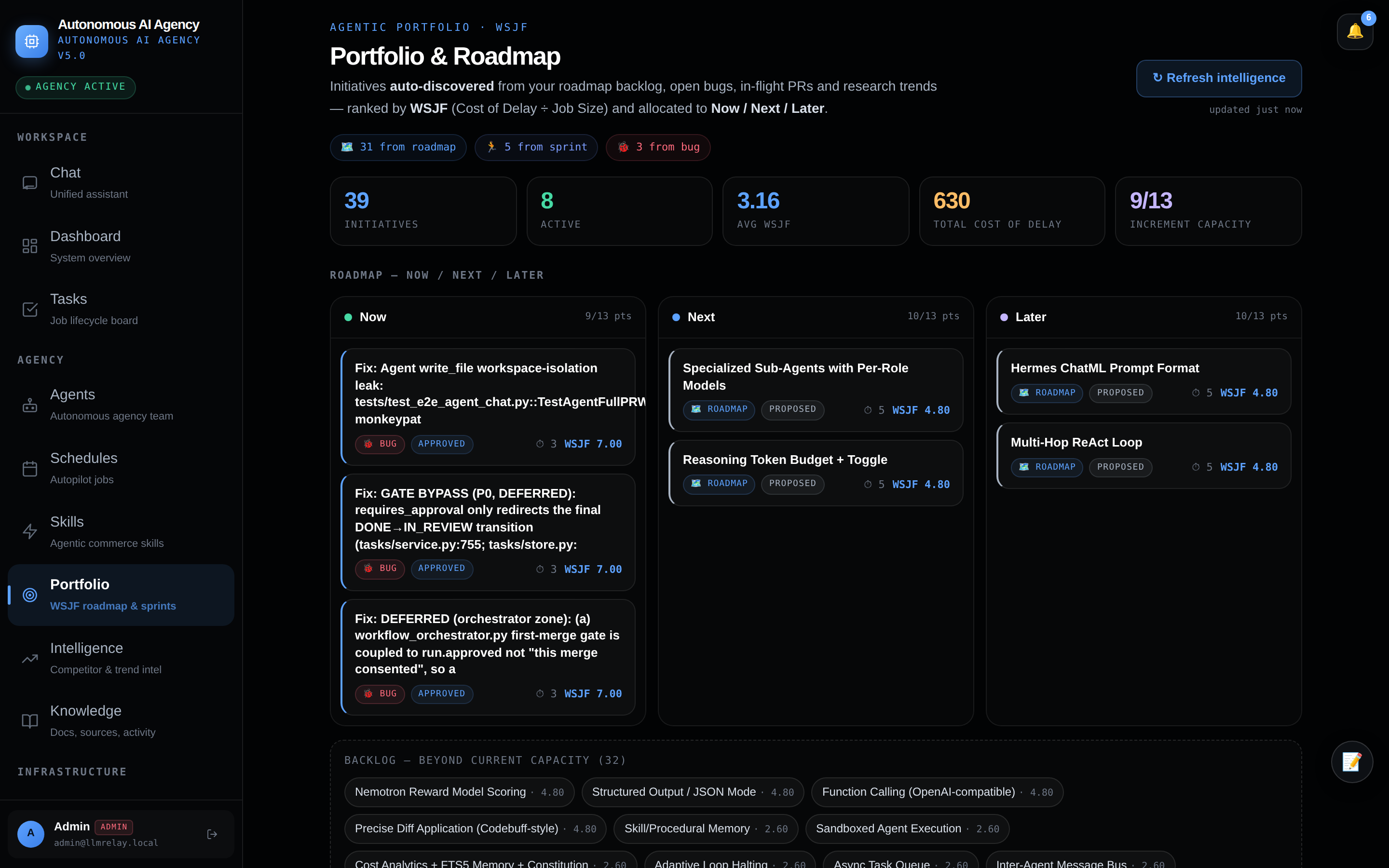
📈 Intelligence — trends & competitors
Trend and competitor signals scoped to each onboarded company's stack.
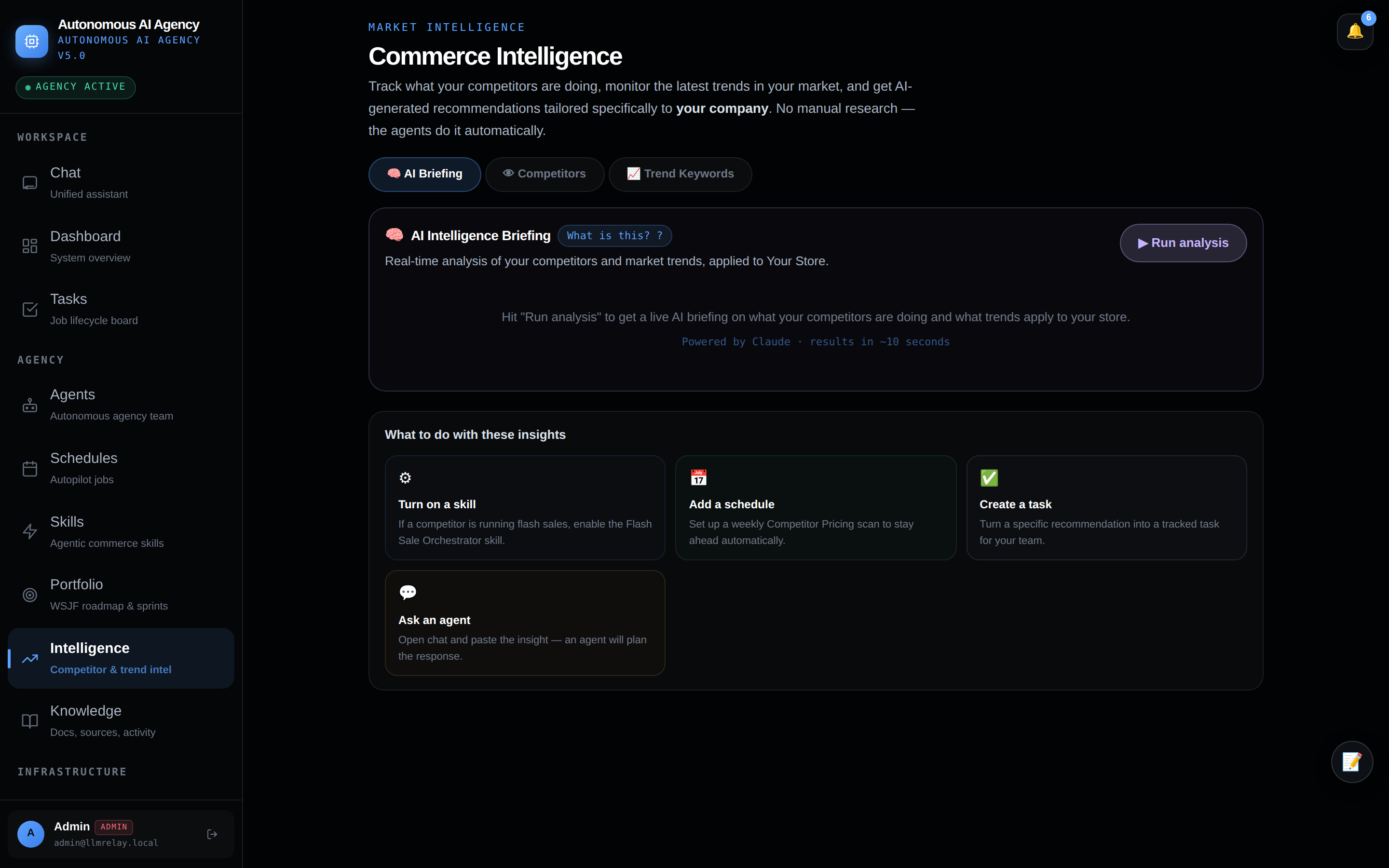
📚 Knowledge — docs & sources
Wiki pages, source material, and reusable context — your team's memory.
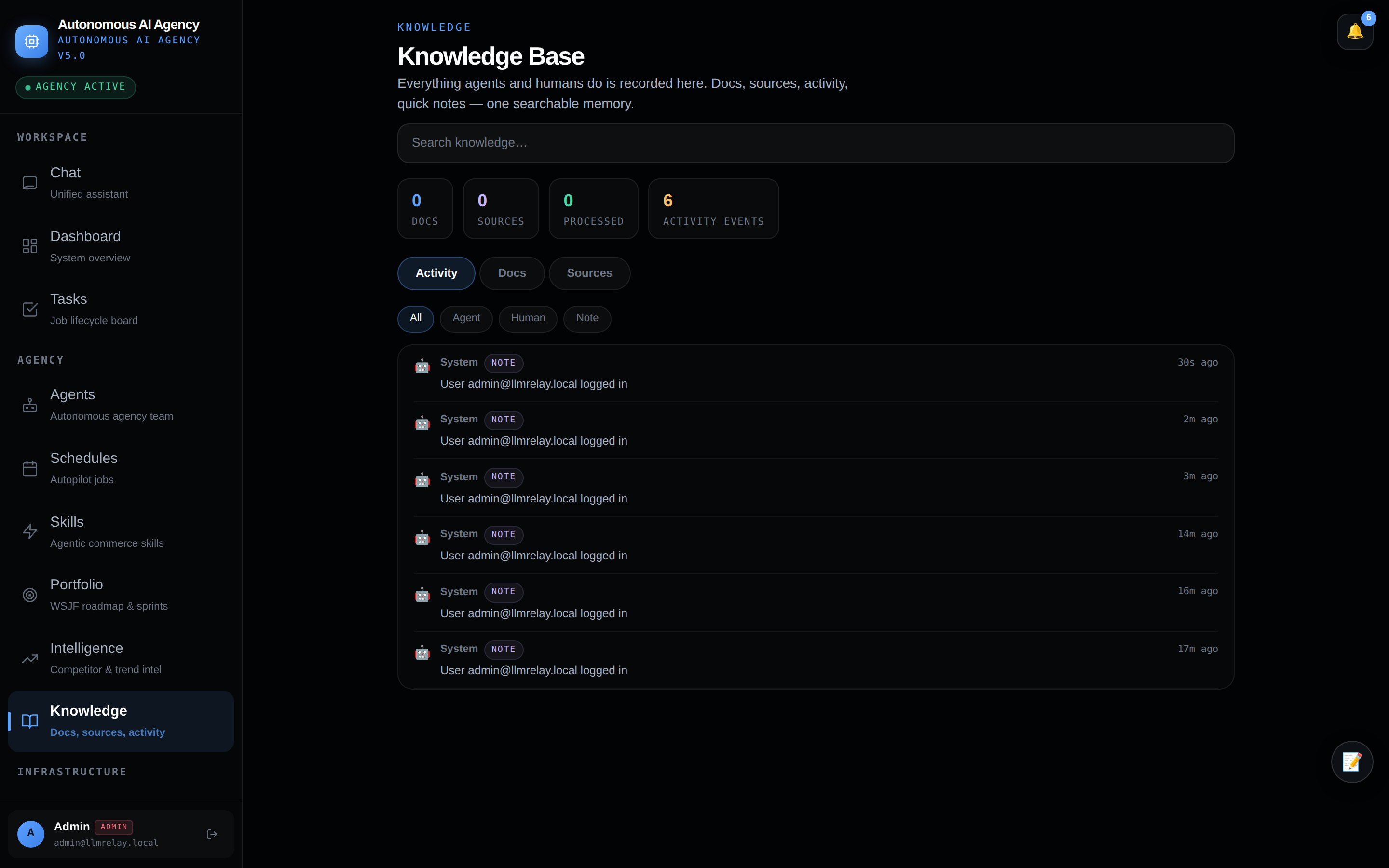
🔌 Providers — models, Ollama & MCP
Connect free/cloud/local AI sources and choose which models are available.
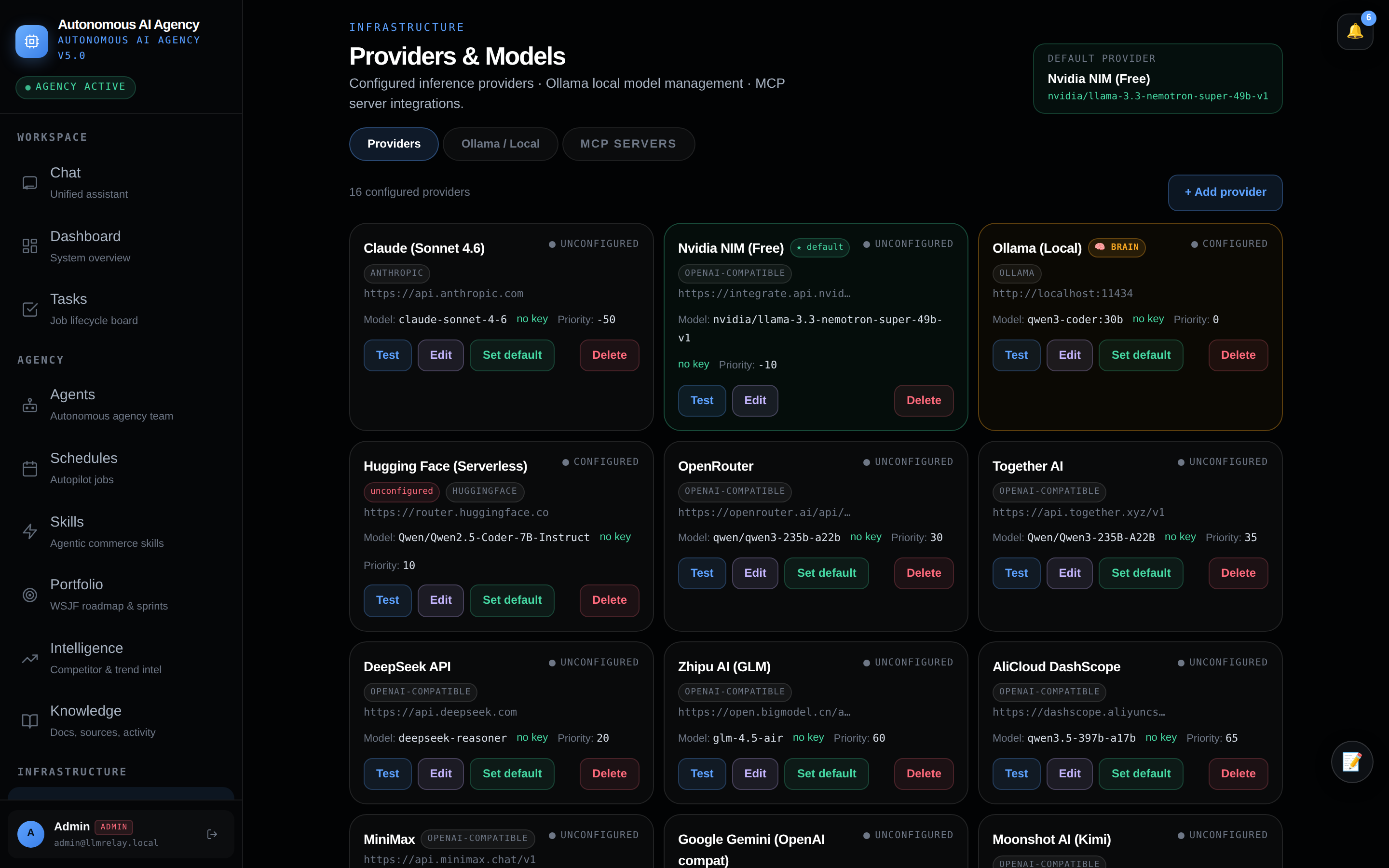
🔭 Logs — traces & observability
Every LLM call: tokens, latency, cost, and decision context.
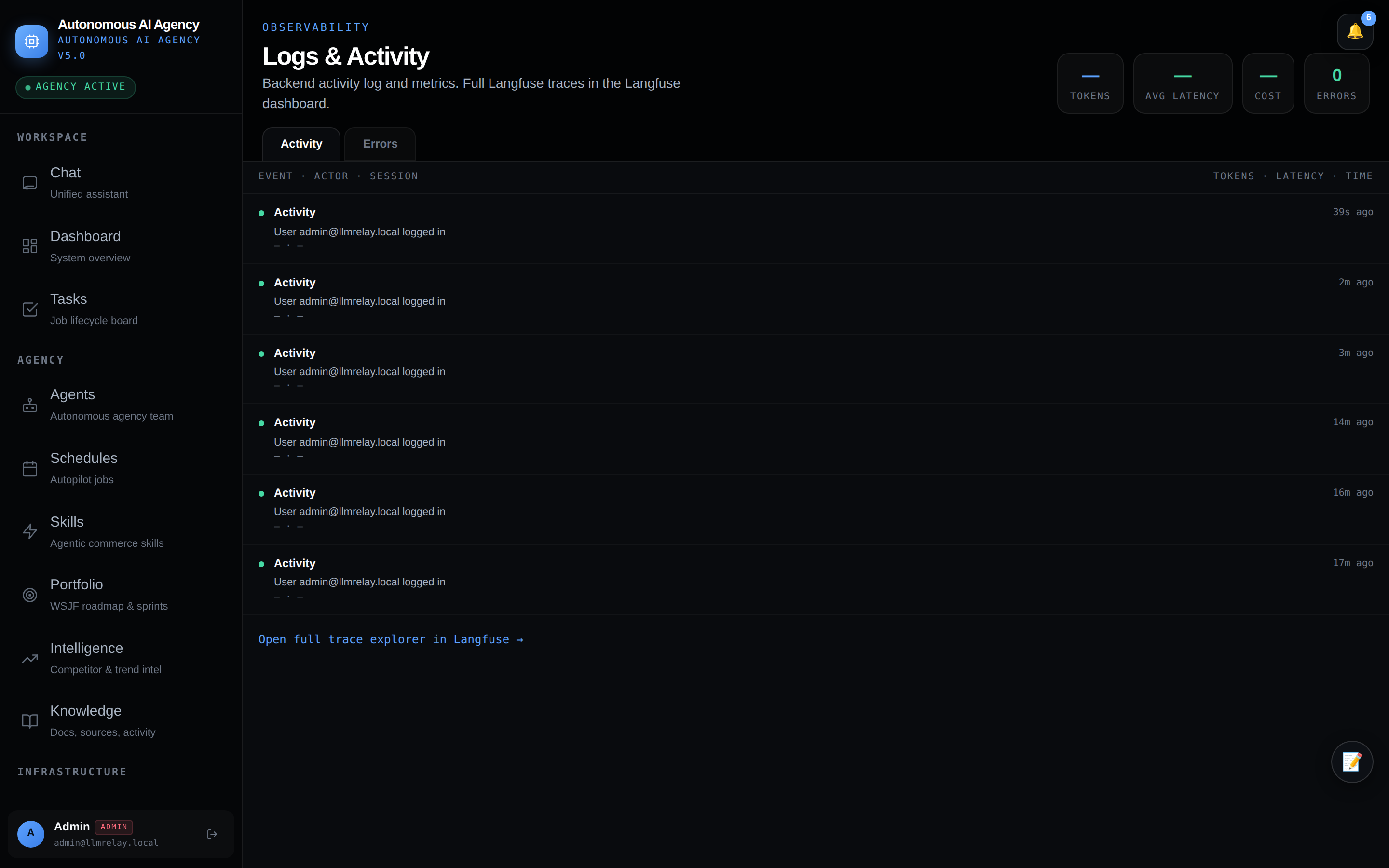
🐙 GitHub — repos & PRs
Connect repositories and manage the agent's delivery surface.
🏢 Company — operating context
An onboarded company's detected stack, systems, and SEO/health.
✨ Onboarding — setup wizard
Scan a website and stand up its specialist agency in minutes.
🔁 Loops — autonomous fleet
Every autonomous loop catalogued: readiness score, maturity, self-heal coverage, drift status, and cost estimate.
🩺 Doctor — diagnostics
System self-checks and autonomy readiness probes.
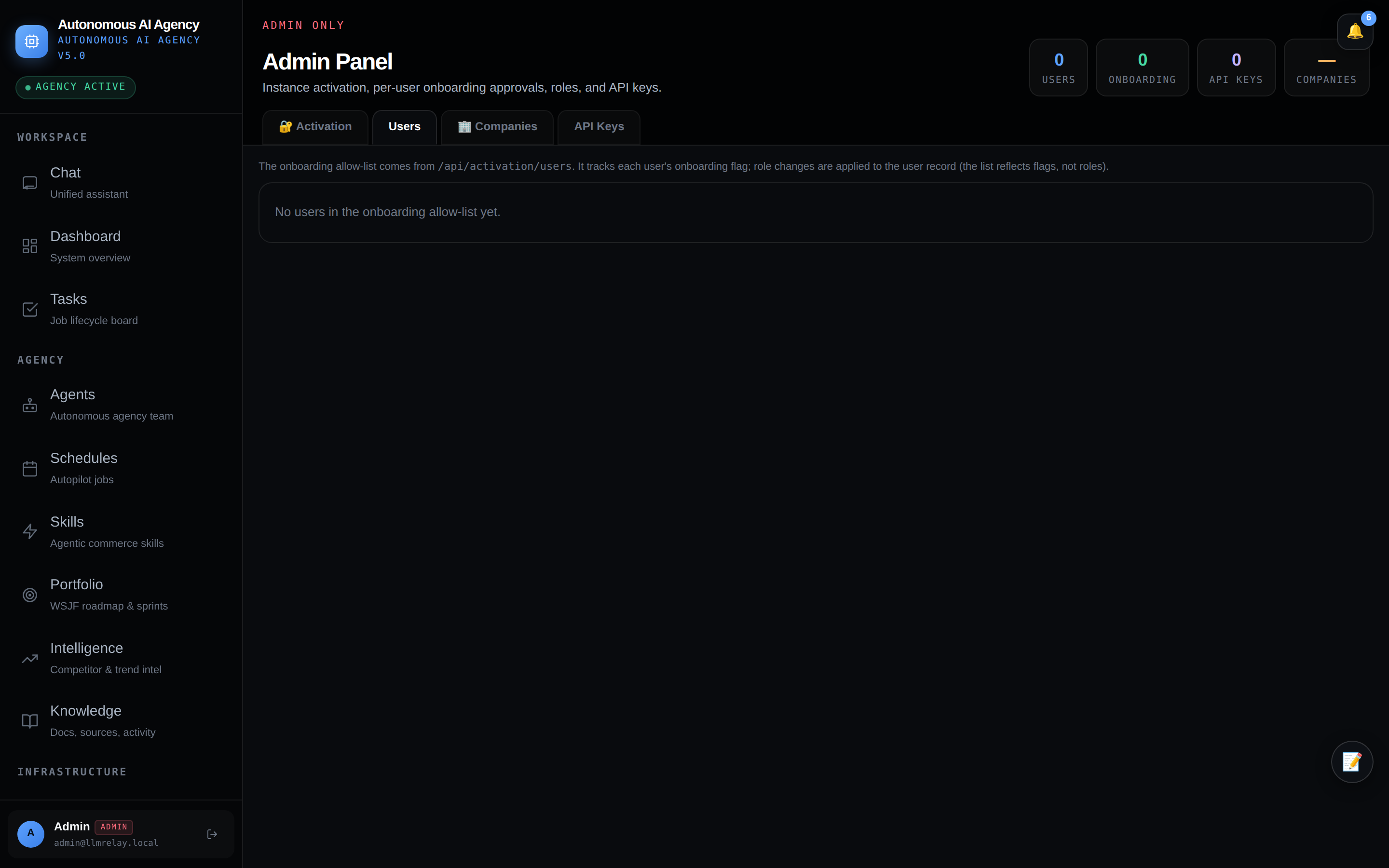
🛡 Admin — users & access
Manage users, roles, instance activation, and onboarding gates.
📱 Mobile
Responsive layout — sign in, view the dashboard, and work the task board from a phone.
Learning loop — failures become context
Retry without learning repeats the same mistake forever. Every failed agent step now writes a deduplicated lesson (failure phase + cause, with a recurrence counter) to a durable store (agent/lessons.py). The planner injects the most persistent recent lessons into its system prompt on every new run, so known failure modes are avoided instead of rediscovered. Recording and recall are fail-open — a broken lesson store can never break a run.
Stuck detection & microagents (OpenHands-inspired)
Two mechanisms adapted from OpenHands:
- Stuck detection (
agent/stuck_detector.py) — the executor's tool loop aborts early when its recent observations show no progress: the same tool call returning the same result 3× in a row, the same call failing 3× in a row, or two calls alternating A,B,A,B,A,B. A stuck step stops spending LLM calls and moves on to the edit/verify phase. - Microagents (
agent/microagents.py) — markdown files with YAML frontmatter under.openhands/microagents/in the workspace inject targeted knowledge into the planner prompt:type: repofiles always,type: knowledgefiles only when one of theirtriggerskeywords appears in the task. The format is OpenHands-compatible, so this repo's microagents work verbatim in any tool reading the convention.
Both are fail-open: neither can break a run.
Architecture
┌──────────────────────────────────────────────────────────────────────┐
│ React V5 SPA (GitHub Pages) Remote Admin (Vercel) │
└──────────────────────┬───────────────────────────────────────────────┘
│ HTTPS / JWT Bearer
┌──────────────────────▼───────────────────────────────────────────────┐
│ FastAPI Backend (Render / Docker / uvicorn) │
│ ├─ /v1/chat/completions OpenAI-compatible proxy (Cursor, Aider) │
│ ├─ /api/chat/send CEO agent conversational API │
│ ├─ /api/tasks/* Task CRUD + async dispatcher │
│ ├─ /api/agent/* Agent job management + HITL gates │
│ ├─ /api/quick-notes Quick Note queue (iPhone Shortcuts) │
│ ├─ /api/doctor Live self-diagnostics │
│ ├─ /api/ping Liveness probe │
│ ├─ /api/activation/* Instance licensing + user management │
│ └─ /mcp-internal MCP server for agent tool calls │
├──────────────────────────────────────────────────────────────────────┤
│ ModelRouter — task classification → optimal model selection │
│ ├─ Code tasks → Qwen3-Coder / DeepSeek-Coder │
│ ├─ Reasoning → DeepSeek-R1 │
│ └─ Fast / chat → smallest capable model │
├──────────────────────────────────────────────────────────────────────┤
│ AgentRunner — plan → execute → verify → judge → summarise │
│ ├─ CEO agent (orchestrator + domain classifier) │
│ ├─ 35 specialist families (engineering + business + domain) │
│ └─ Workflow engine (persisted state machine, HITL gates) │
├──────────────────────────────────────────────────────────────────────┤
│ Task Dispatcher — async poll loop + crash-recovery reconciler │
│ ├─ Per-task git worktree isolation │
│ └─ External runtimes: Docker · OpenCode · Aider · Goose · Hermes │
├──────────────────────────────────────────────────────────────────────┤
│ Skill Registry — flat + subdir GitHub layouts, ETag caching │
│ ├─ Semaphore rate-limiting (≤ 60 req/h unauthenticated) │
│ └─ Dynamic tech-relevance extraction for context-aware binding │
├──────────────────────────────────────────────────────────────────────┤
│ Storage (swappable without restart) │
│ ├─ MongoDB (default) — Motor async driver │
│ └─ SQLite (STORAGE_BACKEND=sqlite) — zero external deps │
│ Observability — Langfuse traces + local TCO cost model │
└──────────────────────────────────────────────────────────────────────┘
Feature maturity — what's stable vs. beta
We'd rather under-promise. Here's the honest split (see docs/architecture/feature-maturity-matrix.md and docs/support-matrix.md for the full breakdown):
| Area | Maturity | Notes |
|---|---|---|
OpenAI-compatible proxy (/v1/chat/completions) |
Stable | Used daily by Claude Code, Cursor, Codex CLI, Aider. Continue (EOL — acquired by Cursor). |
| Multi-provider routing + failover | Stable | Bedrock -> NIM -> DeepSeek -> Anthropic -> Ollama chain with per-provider cooldown. |
| Technology scanner (HTML + DNS + TLS + headers) | Stable | BuiltWith-parity off-HTML evidence; headless escalation for bot-walled sites is best-effort and needs Chromium installed in the deployment. |
| Task workflow + dispatcher + HITL gates | Stable | Persisted state machine, crash-recovery reconciler. |
| Scheduled tasks / persistent schedule store | Stable | Durable across redeploys — ScheduleStore works with both Mongo and SQLite; AgentScheduler rehydrates every cadence on boot; APScheduler's worker thread dispatches on_fire coroutines onto the FastAPI main loop via run_coroutine_threadsafe, so 24x7 cadences produce tasks instead of dying on a cross-loop error. |
| Skill bindings + dynamic skill registry | Stable | GitHub discovery with ETag caching and rate-limit semaphores. |
| Langfuse observability + local TCO cost model | Stable | Cost figures are an estimated commercial-equivalent model, not a billed invoice. |
| Multi-agent orchestration — single specialist (CEO → one specialist, Golden-Path plan→execute→verify→judge) | Stable | Core delegation path; production-tested. |
| Multi-agent orchestration — swarm (CEO fans out across N specialists) | Beta | Promoted from disabled — wired into the golden path via services/ceo_dispatcher.py:CEODispatcher.delegate; the WorkflowOrchestrator EXECUTE phase calls the CEO for medium/high-complexity tasks, which routes each specialist through RuntimeManager to its preferred runtime. CEO_FANOUT_COMPLEXITY=high restricts fan-out to the hardest requests; fallback stats via get_ceo_fallback_stats(). |
| Hermes runtime (default code-generation sidecar) | Beta | Promoted from disabled — deployed by default (agency-hermes on Render) and set as the default runtime for code_generation tasks. RuntimeManager.wake_all_sleeping_runtimes() gives every CEO delegation a real, rate-limited health check (not a guess) before dispatch, with automatic fallback to the Internal Agent if Hermes is down. |
| Other external runtimes (Goose / OpenCode / Aider / OpenHands / Task Harness) | Disabled by default | Optional sidecars that need their own deployment and an explicit FEATURE_<ID>=experimental override — not part of the default deploy. When absent, the agency falls back to the Internal Agent (NVIDIA NIM) so work continues; the Doctor reports them as warnings, never blocking. |
| Telegram bot remote control | Disabled by default | Demoted pending an isolation/gating review (issue #467) — the service manager, inbound routing, approval gates, /diag, and a full test suite are implemented, but it ships off. Enable with TELEGRAM_BOT_TOKEN + FEATURE_TELEGRAM_BOT=experimental. |
The canonical, machine-readable source of truth for every row above is features/matrix.py — check it (or GET /admin/features) before trusting any maturity claim made elsewhere, including in this README.
If a screen or capability isn't listed above, treat it as experimental.
Setup
What you need
- Python 3.13+
- An LLM — Ollama with one local model, or a free Nvidia NIM API key (no GPU required)
- Node 20+ — for the web UI
- MongoDB — or set
STORAGE_BACKEND=sqliteto skip it entirely
No Kubernetes. No cloud account. A Raspberry Pi 5 can run the core services.
1. Clone and install
git clone https://github.com/strikersam/autonomous-ai-agency.git
cd autonomous-ai-agency
python -m venv .venv && source .venv/bin/activate
pip install -r backend/requirements.txt
2. Configure
cp .env.example .env
Minimum viable .env for local development (no MongoDB, no GPU):
STORAGE_BACKEND=sqlite # zero-dependency storage
[email protected]
ADMIN_PASSWORD=changeme
SECRET_KEY=$(openssl rand -hex 32)
NVIDIA_API_KEY=nvapi-... # free at build.nvidia.com — no GPU needed
Full list of variables: docs/configuration-reference.md
3. Start the backend
uvicorn backend.server:app --host 0.0.0.0 --port 8001
Verify: curl http://localhost:8001/api/ping → {"status":"ok","pong":true}
4. Start the frontend (development)
cd frontend && npm install
REACT_APP_BACKEND_URL=http://localhost:8001 npm start
Visit http://localhost:3000 — the Setup Wizard appears on first boot.
5. Onboard your first company
# From the UI: Companies → Paste URL → Onboard
# Or via API:
curl -X POST http://localhost:8001/api/company/{id}/onboarding/start \
-H "Authorization: Bearer <your-token>" \
-H "Content-Type: application/json" \
-d '{"website_urls": ["https://yourcompany.com"]}'
6. Connect your AI coding tools (optional)
// Cursor — settings.json
{
"cursor.ai.openaiBaseUrl": "http://localhost:8000",
"cursor.ai.openaiApiKey": "your-api-key-here"
}
See client-configs/ for Aider, Codex CLI, Continue (EOL), Cursor, Zed, VSCode, and Claude Code.
Cloud deployment (Render + GitHub Pages)
Push to master — CI does the rest:
- Python 3.13 tests · frontend build · lint · SAST · secret scan · CVE audit
- Docker build → Render deploy hook → health check
- React build → GitHub Pages
Required secrets:
RENDER_DEPLOY_HOOK_URL → Render → service → Settings → Deploy Hook
RENDER_BACKEND_URL → your Render service URL
Live demo:
- Frontend:
https://autonomous-ai-agency.strikersam.workers.dev/(Cloudflare Worker — canonical; reverse-proxies/api/*to the Render backend so OAuth stays same-origin) - Frontend mirror:
https://strikersam.github.io/autonomous-ai-agency/(GitHub Pages — secondary; the build'sREACT_APP_BACKEND_URLpoints at the worker for/api/*calls) - API:
https://autonomous-ai-agency.onrender.com/docs(pending Render service rename; currently still served athttps://local-llm-server.onrender.com/docsuntil the Render dashboard service is renamed)
Render free tier sleeps after 15 min of inactivity (~30 s cold start). Upgrade to Starter ($7/mo) for always-on in production.
Configuration reference
| Variable | Default | Description |
|---|---|---|
SECRET_KEY |
(required) | JWT signing key — openssl rand -hex 32 |
STORAGE_BACKEND |
mongo |
sqlite for zero-dependency storage |
MONGO_URL |
mongodb://localhost:27017 |
MongoDB connection string |
OLLAMA_BASE / OLLAMA_BASE_URL |
http://localhost:11434 |
Ollama server URL. On a cloud deploy, set this to your tunnel URL to drive the brain from a local GPU — see Running the brain on local Ollama. |
LLM_PROVIDER |
ollama |
ollama · cerebras · groq · nvidia-nim · deepseek · bedrock · anthropic |
CEREBRAS_API_KEY |
(optional) | Recommended free brain — fast, generous free tier, free at cloud.cerebras.ai. The brain auto-selects it when present. |
GROQ_API_KEY |
(optional) | Fast free fallback brain — free at console.groq.com |
NVIDIA_API_KEY |
(optional) | Free-tier cloud inference (NIM) — no GPU required; the always-on safe floor |
AWS_ACCESS_KEY_ID + AWS_SECRET_ACCESS_KEY |
(optional) | AWS Bedrock |
ANTHROPIC_API_KEY |
(optional) | Direct Anthropic API |
DEEPSEEK_API_KEY |
(optional) | DeepSeek cloud API |
GITHUB_TOKEN |
(optional) | Required for agents that open PRs or read issues |
LANGFUSE_HOST + keys |
(optional) | Observability traces |
TELEGRAM_BOT_TOKEN |
(optional) | Remote control via Telegram — feature ships disabled by default (issue #467); also set FEATURE_TELEGRAM_BOT=experimental |
ADMIN_EMAIL + ADMIN_PASSWORD |
(optional) | First admin — created on first boot |
RUNTIME_DOCKER_ENABLED |
false |
Enable Docker agent runtime |
Provider priority chain
AWS Bedrock (15) → Nvidia NIM (10) → DeepSeek (8) → Anthropic (7) → HuggingFace (5) → Ollama (3)
Only providers with keys configured are tried. Set just the keys you have.
Brain config takes precedence. The legacy numeric chain above is the
fallback used when no brain is explicitly chosen. The Brain card on the
Providers screen (DB-persisted, liveness-probed) is the recommended way to pick
the active provider + per-role models — and when no brain is saved, the runtime
auto-selects the recommended free-cloud chain Cerebras → Groq → NVIDIA NIM →
Ollama based on which API key is present. See Running the brain on local
Ollama to point it at your own GPU.
Running the brain on local Ollama (via a tunnel)
Want the agency's brain powered by a model on your own machine instead of a
cloud provider? Expose your local Ollama through a tunnel and point the cloud
backend at it. Because the agent loop runs on the cloud host, localhost:11434
means nothing there — the backend has to reach your box over the network.
Run Ollama locally and pull a model:
ollama serve ollama pull qwen3-coder:30b # and/or deepseek-r1:32bExpose it with a stable tunnel. Prefer a named Cloudflare Tunnel over
ngrok-free — ngrok's free URL rotates on every restart and would silently break
the brain:cloudflared tunnel --url http://localhost:11434 # → https://<random>.trycloudflare.com (quick tunnel; use a *named* tunnel for a fixed hostname)Paste the tunnel URL into the Brain card — no Render/env edit. Providers
screen → Brain → provider Ollama. An Ollama base URL field appears:
paste your tunnel URL there (it's saved in the DB, not an env var). Set the
role models to your local ids (qwen3-coder:30b,deepseek-r1:32b) →
Test (probes that URL's/api/tagsand checks the model is pulled) →
Apply. The saved URL is what the brain uses on the next run.OLLAMA_BASEenv still works as a fallback if you'd rather set it on the
deploy, but the UI field wins and is the recommended path.
Keep it as a fallback, not the primary. If your machine sleeps, the tunnel
dies and the brain can't reach it. The robust setup is a cloud brain (Cerebras)
as the default with local Ollama as a "use my GPU when it's awake" override — the
liveness probe stops you from Applying Ollama while the tunnel is down.
Agent runtimes
| Specialist family | Runtime | Type |
|---|---|---|
code_generation · CEO · Security · Reviewer · Release (default) |
Hermes | 🐳 Docker sidecar — deployed by default (agency-hermes on Render); thin HTTP wrapper around the same Internal Agent brain |
backend · mobile · ecommerce · qa |
OpenCode | 🐳 Docker (sidecar, opt-in — not deployed by default) |
security · engineering · architecture · ml |
Claude Code | 💻 CLI (sidecar, opt-in) |
frontend · ux · design · docs · operations |
Goose | 🐳 Docker (sidecar, opt-in — not deployed by default) |
devops · cloud · infra |
Aider | 🐳 Docker (sidecar, opt-in — not deployed by default) |
| Long-running workflows | Task Harness | 🐳 Docker (sidecar) — disabled by default, needs an external binary |
agile · portfolio · delivery · all fallbacks |
Internal Agent | 🏠 Built-in (always available) |
Runtime availability: The Internal Agent is always available (runs on NVIDIA NIM or any configured cloud provider — no sidecar needed). Hermes ships deployed by default and is the default runtime for
code_generationtasks — it's a thin HTTP shim over the same Internal Agent brain, so there's no separate model or infra to trust. OpenCode, Claude Code, Goose, and Aider are optional sidecars that still need to be deployed separately. When any sidecar is absent, the agency automatically falls back to the Internal Agent so work continues without interruption. The Doctor page reports absent sidecars as warnings, never as blocking errors.
Runtime wake-up isn't a manual dashboard action: RuntimeManager.wake_all_sleeping_runtimes() runs automatically before every CEO delegation (rate-limited via CEO_WAKE_COOLDOWN_SEC, default 30s), and the Agents and Doctor screens surface the resulting health inline.
Development
pytest -x # fast-fail
pytest -v # verbose
git config core.hooksPath .claude/hooks # activate changelog enforcement
python generate_api_key.py # generate a new API key
python scripts/ai_runner.py start # start an AI coding session
python scripts/ai_runner.py status # show current session state
python scripts/ai_runner.py resume # resume from last checkpoint
python scripts/ai_runner.py logs # tail session logs
See CLAUDE.md for the contributor guide, skill map, risky-module policy, and AI agent working rules.
What's New
2026-07-04
- Docs audit: CEO orchestration and Hermes maturity corrected.
features/matrix.py(the canonical source of truth) had already promoted sidecar runtimes (Hermes/OpenCode/Goose) and multi-agent swarm dispatch fromdisabledto Beta, but the README,docs/support-matrix.md, anddocs/architecture/feature-maturity-matrix.mdstill described them as "Experimental." Corrected across all three. Hermes specifically ships deployed by default (agency-hermeson Render) and is the default runtime forcode_generationtasks — it's a thin HTTP wrapper over the same Internal Agent brain, woken and health-checked before every CEO delegation. Goose/Aider/OpenCode remain optional, undeployed sidecars. - Telegram bot corrected to "disabled by default." The bot was demoted to
disabledinfeatures/matrix.pyper issue #467 pending an isolation/gating review, but docs still called it "Beta" / "stable, opt-in." Corrected. - V5 Control Plane screen table refreshed — added Knowledge, Loops, and SAM (voice command & control), which existed in the live dashboard nav but were missing from the README table; removed the standalone Runtimes row (folded into Agents + Doctor in an earlier release). Screen count corrected from 16 to 18.
- Broken links fixed:
docs/configuration.md→docs/configuration-reference.md; added the missingLICENSEfile (the README and badge already declared MIT).
2026-06-26
Opus 4.8 + Fable 5 routing — Claude Opus 4.8 (latest flagship) and Fable 5/Mythos 5 added to the model registry and alias table. Requests for any of these models are transparently routed to the best local model. Fable 5 is gated behind
ROUTER_ALLOW_FABLE5=1due to the US export-control suspension.Continue.dev shutdown deadline — Continue was acquired by Cursor. Export your data by July 15, 2026 or it will be deleted. Client configs updated with migration guidance to Cursor, Aider, or Claude Code CLI.
Codex CLI support — New
client-configs/codex_config.mdwith setup instructions for OpenAI Codex CLI (v0.142+). PointOPENAI_BASE_URLat your proxy and use any local model.Cursor config refresh — Recommended models updated: Qwen 3.6 27B (best local coder), DeepSeek V4, Gemma4 27B. Added Continue-to-Cursor migration note.
2026-06-25
DeepSeek V4 routing + legacy name migration —
deepseek-v4-0324added to the model registry. Forward-compatible aliases (deepseek-v4,deepseek-v4-pro) and legacy API names (deepseek-chat,deepseek-reasoner) now route correctly. DeepSeek is deprecating the old names on July 24, 2026 — no client changes needed if you're going through this proxy.Qwen 3.6 27B — Best-in-class local coding model (77.2% SWE-bench, 24GB at Q4) added to the registry. Use short aliases:
qwen3.6,qwen3.6-27b.Continue.dev EOL notice — Continue.dev v2.0.0 is the final release (repo now read-only after Cursor acquisition). Client configs updated with migration guidance.
Cursor 3.9 proxy fix — Added HTTP/2 disable guidance for proxy users (
http.experimental.useHTTP2: false).
2026-06-16
Per-model circuit breaker (
router/circuit_breaker.py) — Models that return 5xx errors consecutively are now automatically quarantined for a configurable recovery window (default 60 s) and the router uses the fallback chain instead. This prevents hammering a stuck or overloaded model on every request. Configuration:CIRCUIT_BREAKER_FAILURE_THRESHOLD(default 3),CIRCUIT_BREAKER_RECOVERY_TIMEOUT(default 60 s),CIRCUIT_BREAKER_ENABLED(defaulttrue).Anthropic API usage field parity (
handlers/anthropic_compat.py) — Responses from/v1/messagesnow includecache_read_input_tokensandcache_creation_input_tokensin theusageblock (both0for local models, since Ollama has no server-side prompt cache). These fields are required by Claude Code CLI ≥ v2.1.x and the Anthropic Python/TypeScript SDK — their absence causedKeyErroror silent field-access failures in some SDK versions when pointing Claude Code at a local proxy.
Roadmap
| Phase | Status | What shipped |
|---|---|---|
| 1 — Typed agent contract | ✅ Done | AgentJobRequest / AgentJobResult Pydantic contract, E2E tests |
| 2 — ModelRouter wiring | ✅ Done | Single router for all request types; classification → model hint |
| 3 — SQLite + one backend | ✅ Done | Swappable storage adapter, zero-dep option |
| 4 — Runtime resilience | ✅ Done | Crash-recovery reconciler, worktree isolation, opt-in external runtimes |
| 5 — Doctor & dashboard resilience | ✅ Done | Live self-diagnostics, useSafeData hook, per-check Fix buttons |
| 6 — Workflow engine | ✅ Done | Persisted state machine, CEO agency, branch/PR safety, HITL gates |
| 7 — Onboarding engine | ✅ Done | URL → stack inference → system detection → specialist provisioning → 24x7 agency |
| 8 — Multi-tenant isolation | ✅ Done | Per-user scoping across all resources; IDOR-safe cross-tenant access |
| 9 — AI onboarding + Quick Notes | ✅ Done | AI-tailored onboarding questions; Quick Note processor; skill registry ETag + rate limiting |
License
MIT — see LICENSE
Autonomous AI Agency — the AI team that works while you sleep, on a server you own.
Built for engineers and operators who want the leverage of frontier AI without the cloud bill, the privacy compromise, or the headcount.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found