scholar-lab-radar
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 17 GitHub stars
Code Fail
- rm -rf — Recursive force deletion command in setup/install.sh
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Profile a research lab over the last N years — collect every paper from OpenAlex, build a temporal knowledge graph (ontology), and synthesize a grounded evolution report. A Claude Code skill (sibling to scholar-megasearch).
scholar-lab-radar
Profile a research lab over the last N years for Claude Code.
One skill that collects every paper from OpenAlex, structures it into a temporal knowledge graph (ontology), and synthesizes a grounded report of the lab's evolution.
한국어 README · SKILL.md · Ontology




One sentence: name a professor (or a school/department), and get back a temporal
knowledge graph of their lab's papers plus a grounded report of what they work on, who
the members are, and how the focus has shifted.
- 🛰️ Whole lab in one sweep — every paper by the confirmed PI over the chosen years, from OpenAlex (free, no key), deduped with abstracts, topics, citations, references, and authorships.
- 🕸️ Temporal knowledge graph (ontology) — typed entities (Paper · Researcher · Topic · Theme · Method · Venue · Institution · Funder) and time-stamped relations, so trends and lineage are graph queries, not flat tags.
- 📈 Focus-shift detection (기조 변화) — topic × year matrix with emerging / declining research lines, every claim grounded in paper counts.
- 👥 Member roster & roles — co-authorship reveals likely members, long-term collaborators, and rising first-authors (current students/stars) — inferred and labeled honestly.
- 🧩 Two-layer design — deterministic Python builds the graph + metrics (reproducible); the LLM only names research themes/methods and writes the narrative, always grounded.
- 🎞️ Interactive graph, played over time — a self-contained
graph.html: click any node for its details, filter by type, and drag a year slider (or hit ▶ play) to watch the lab's graph assemble year by year. - 🧭 Modes —
professor,lab,department,compare(two labs),applicant(lab × your interests).
Why It Exists
Sizing up a lab is tedious and shallow. You skim a Google Scholar profile (a flat list),
maybe an OpenAlex page (metrics), and try to guess from titles what the group actually
works on now, whether it has pivoted, and who the key people are. A prospective student
comparing advisors, a researcher scouting collaborators, or a PI writing a tenure packet
all hit the same wall.
scholar-lab-radar treats "understand this lab" as a graph problem: resolve the PI,
collect the whole corpus, and structure it into a temporal ontology where Topics,
Themes, Methods, members, and citations are typed and dated. The output isn't a chat reply
— it's a knowledge graph on disk plus a report whose every trend ("ethics of AI rose from
1% to 9% of output") is backed by counts you can audit.
How It Works
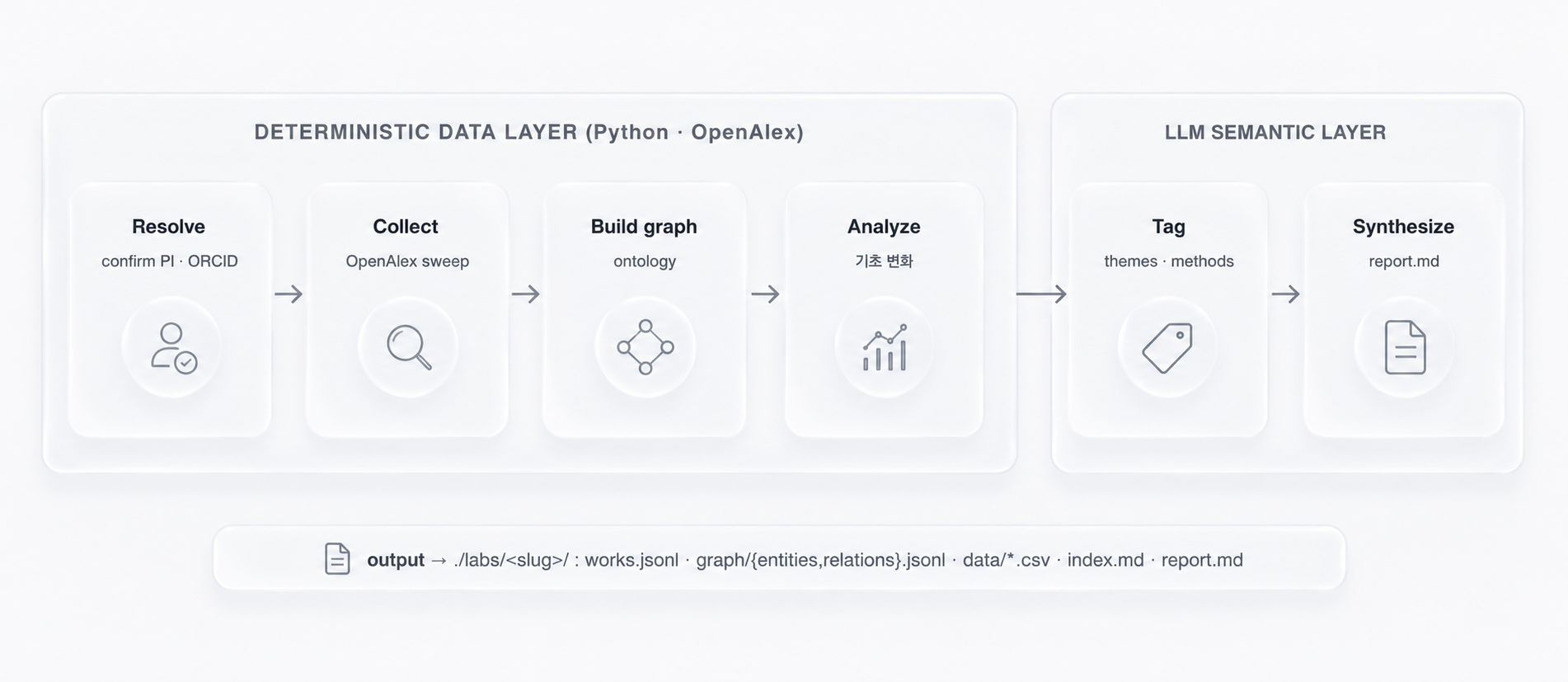
The data layer is deterministic Python over OpenAlex; the semantic layer (research
themes, methods, datasets, and the prose narrative) is the only part the LLM touches, and it
is grounded in the graph's counts.
The ontology
OpenAlex's 4-level Topic taxonomy is the spine (a controlled vocabulary that stops the LLM
from drifting); lab-specific Themes are layered on top. Every relation carries a year, so
the graph is a time series — focus shift, theme lineage, and method diffusion are all queries
over it. See references/ontology.md.
Focus-shift detection
analyze.py splits the year span in half and compares each topic's share of primary-topic
papers, early vs late. Topics whose share grows are emerging; those that shrink are
declining — reported with the raw paper counts so a reader can judge the signal.
A typical run
A 5-year sweep on a single PI looks roughly like this (illustrative):
lab: "Yoshua Bengio" (ORCID 0000-0002-9322-3515), 2020–2024
works: 213 unique researchers: ~1000 distinct co-authors
graph: ~3,800 relations topics: 12 primary lines tracked
emerging: Ethics & Social Impacts of AI 1% → 9% (1 → 5 papers)
declining: Domain Adaptation / Few-Shot 11% → 2% (17 → 1 papers)
output: ./labs/yoshua-bengio_2020-2024/
A full worked example (Geoffrey Hinton, 2020–2024 — graph, metrics, per-paper cards,
and the synthesized narrative) is committed underexamples/geoffrey-hinton_2020-2024/.
Install
git clone https://github.com/TaewoooPark/scholar-lab-radar.git
cd scholar-lab-radar
bash setup/install.sh [email protected] # email used for the OpenAlex polite pool
The script installs the skill into ~/.claude/skills/. The scripts are standard-library
Python only — no venv, no keys, no MCP required.
Requirements
| Python | 3.9+ (standard library only) |
| Network | access to api.openalex.org |
| Claude Code | the skill is triggered from within a session |
Usage
Inside Claude Code, trigger the skill in natural language:
profile Yoshua Bengio's lab over the last 5 years
이 교수 연구실 최근 10년 논문 흐름이랑 기조 변화 분석해줘
Or invoke it as a slash command — pass the PI, optionally an ORCID / institution / year
range / mode:
/scholar-lab-radar Geoffrey Hinton orcid=... years=2015-2025
/scholar-lab-radar compare "Lab A" vs "Lab B"
/scholar-lab-radar applicant <professor> interests="diffusion models, RL"
Or run the scripts directly:
S=~/.claude/skills/scholar-lab-radar/scripts
python3 $S/resolve.py author "Yoshua Bengio" --orcid 0000-0002-9322-3515 --mailto you@x
python3 $S/collect.py --author A5086198262 --from 2020 --to 2024 -o ./labs/bengio --mailto you@x
python3 $S/build_graph.py ./labs/bengio
python3 $S/analyze.py ./labs/bengio
Modes
| Mode | Corpus | Status |
|---|---|---|
| professor (default) | the confirmed PI's authored works | ✅ v0.1.0 |
| lab | PI + inferred members' works | ✅ recipe (v0.3.0) |
| compare | two labs side by side (advisor comparison) | ✅ v0.3.0 (compare.py) |
| applicant | a lab × your interests → alignment + who to contact | ✅ recipe (v0.3.0) |
| department | an institution + topic scoping | documented |
Outputs
Everything lands under ./labs/<slug>/ in the working directory:
labs/<slug>/
├── works.jsonl # normalized corpus (one work per line)
├── meta.json # run params + counts
├── graph/
│ ├── entities.jsonl # typed nodes: Paper, Researcher, Topic, Venue, …
│ └── relations.jsonl # typed, time-stamped edges
├── data/
│ ├── topics_by_year.csv # topic × year matrix
│ └── roster.csv # member roster with roles + active spans
├── papers/<year>-<slug>.md # per-paper tagged metadata (semantic layer)
├── index.md # structured dashboard
├── report.md # synthesized lab report
└── graph.html # interactive graph — click nodes, filter by type, year-slider time-lapse
Ontology
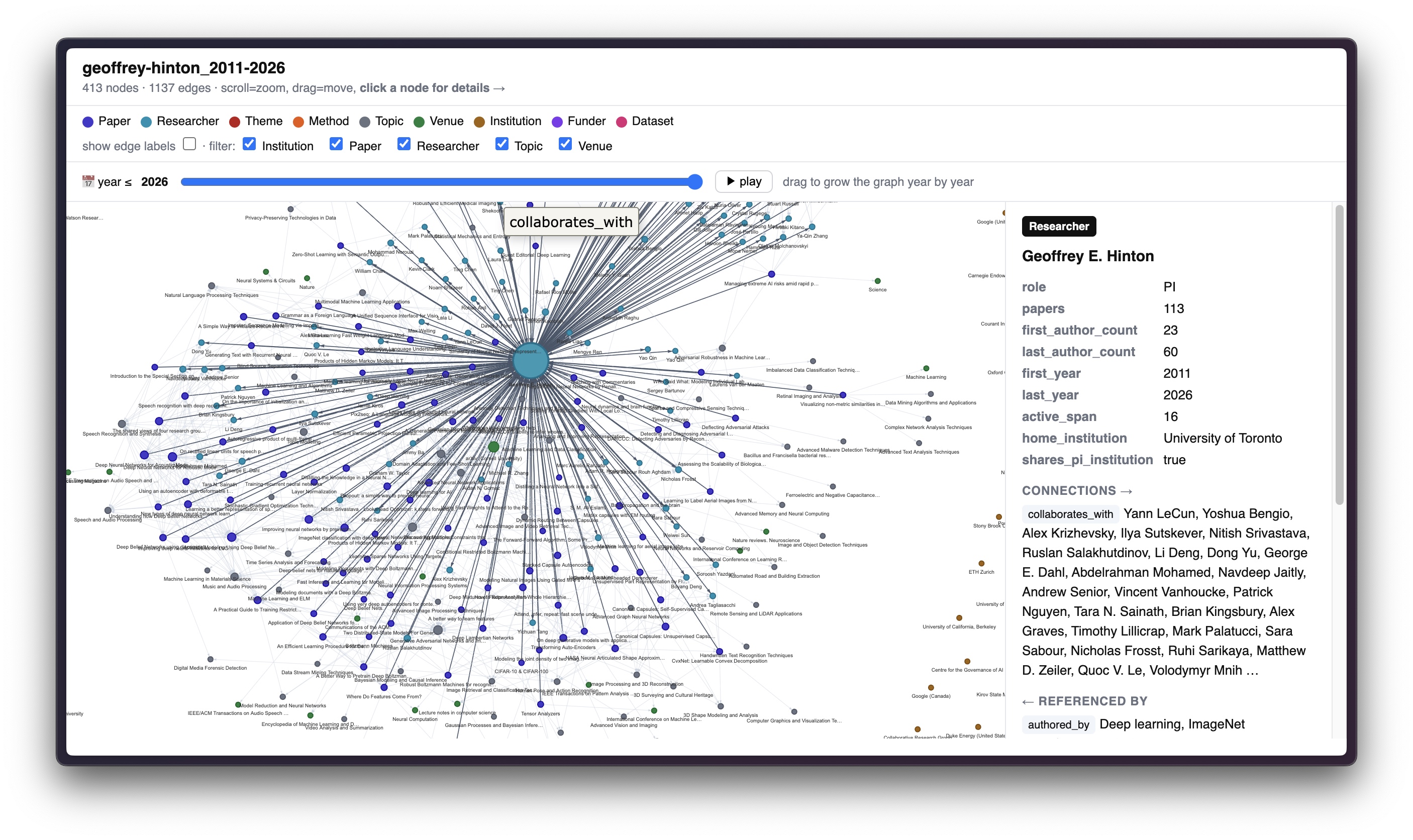
A live slice of the ontology — the interactive graph.html viewer (Geoffrey Hinton, 2011–2026): nodes typed & colored, the year slider that grows the graph over time, and a node's full ontology record (attributes + typed relations) in the detail panel.
| Entity | Key attributes |
|---|---|
| Paper | title, year, venue, doi, citations, oa, pi_position |
| Researcher | name, orcid, role, active span, first/last-author counts |
| Topic | OpenAlex taxonomy: domain → field → subfield → topic (the spine) |
| Theme | lab-specific research thread (LLM, on top of Topics) |
| Method / Dataset | normalized, LLM-extracted |
| Venue · Institution · Funder | metadata nodes |
| Relation | s → o |
|---|---|
authored_by |
Paper → Researcher (+ position) |
has_topic · explores |
Paper → Topic / Theme |
uses_method · evaluates_on |
Paper → Method / Dataset |
published_in · funded_by |
Paper → Venue / Funder |
cites |
Paper → Paper (internal lineage) |
collaborates_with |
Researcher → Researcher (PI ego network) |
advised_by · evolved_from · diffused_to |
inferred (member / theme / method) |
Full schema and the per-paper Markdown frontmatter are inskills/scholar-lab-radar/references/ontology.md;
the exact OpenAlex queries are inreferences/sources.md.
Repository Layout
scholar-lab-radar/
├── README.md · README.ko.md · LICENSE
├── setup/install.sh # installs the skill into ~/.claude/skills/
└── skills/
└── scholar-lab-radar/ # the skill
├── SKILL.md
├── references/{ontology.md, sources.md}
└── scripts/{resolve, collect, build_graph, analyze, tag_ingest, infer, export_jsonld, compare, viz, oa}.py
This repository contains only original MIT-licensed work. No third-party services are
vendored — the scripts call OpenAlex (and optionally other open APIs) at run time.
Notes & Limitations
- Author disambiguation is the make-or-break step. The corpus is exactly the confirmed
PI author id(s); a wrong id taints the whole report. Always confirm — prefer ORCID, and
merge ids when OpenAlex splits a person. - "Lab" is not a data entity.
professormode = the PI's authored works; members are
inferred from co-authorship + affiliation and labeled as inferred, never declared. - OpenAlex coverage varies — older work, some fields, non-English output, and books are
less complete, and abstracts can be missing. Stated in the report's caveats. - Small samples are noisy. Trend claims are always shown with their paper counts so a
reader can judge whether a "shift" is real. - Honest synthesis. The report states what was actually collected and which disambiguation
was chosen; nothing is invented to fill a gap.
Attribution
- OpenAlex — the primary data source (openalex.org), a fully
open index released under CC0. Cite OpenAlex when you publish derived analysis. - ORCID, Crossref, Unpaywall, Semantic Scholar, Papers With Code — optional
enrichment via their public APIs; their data carries its own terms.
Original work in this repository is released under the MIT License — this covers
our code only, not the third-party services or the data they return.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found