reactive-agents-ts
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Warn
- process.env — Environment variable access in .agents/skills/harness-improvement-loop/scripts/harness-probe-wide.ts
- process.env — Environment variable access in .agents/skills/harness-improvement-loop/scripts/harness-probe.ts
- process.env — Environment variable access in .agents/skills/harness-improvement-loop/scripts/multi-model-test.ts
- process.env — Environment variable access in .agents/skills/harness-improvement-loop/scripts/ollama-native-fc-context-probe.ts
- process.env — Environment variable access in .agents/skills/harness-improvement-loop/scripts/ollama-native-fc-gate.ts
Permissions Pass
- Permissions — No dangerous permissions requested
This is a composable TypeScript framework for building AI agents. It provides multiple reasoning strategies, persistent memory, and real-time streaming, all built on top of Effect-TS for strict type safety.
Security Assessment
Overall Risk: Low. The codebase does not request dangerous system permissions, execute arbitrary shell commands, or contain hardcoded secrets. Environment variable access is strictly limited to internal testing and harness scripts. There are no indications that the tool accesses sensitive local data without permission. However, because it is designed to connect to various external LLM providers, users should be aware that network requests to AI APIs will occur during normal operation.
Quality Assessment
The project appears highly ambitious and well-structured, featuring a massive test suite with 3,879 tests. It is actively maintained, with repository updates pushed as recently as today. It uses a permissive standard MIT license. However, community visibility is currently very low. With only 6 GitHub stars, it is a very young project that has not yet been widely adopted or battle-tested by the broader open-source community.
Verdict
Use with caution — the code itself appears clean and safe, but the tool's extreme early-stage status means you may encounter undocumented issues.
Composable TypeScript AI agent framework — Effect-TS type safety, 5 reasoning strategies, persistent gateway, real-time streaming, multi-agent A2A
Reactive Agents — TypeScript AI Agent Framework
The open-source TypeScript agent framework built for control, not magic.
Run your first agent in 60 seconds. Scale up by composing layers — add reasoning loops, persistent 4-tier memory, production guardrails, cost routing, and a live local studio one .with() call at a time.
Works on local Ollama models (8B+) through frontier APIs — same code, same features. Built on Effect-TS for compile-time type safety at every boundary. No any. No hidden magic.
| 25 composable packages | Enable exactly what you need, no hidden coupling |
| 6 LLM providers | Anthropic, OpenAI, Gemini, Ollama (local), LiteLLM 40+, Test |
| 5 reasoning strategies | ReAct · Reflexion · Plan-Execute · Tree-of-Thought · Adaptive |
| 3,879 tests · 430 files | Production-grade confidence |
| Cortex Studio | Live agent canvas, entropy charts, debrief UI, agent builder |
| Effect-TS end to end | Compile-time type safety, zero any, explicit tagged errors |
![]()
![]()
![]()

Documentation · Discord · Quick Start · Features · Comparison · Architecture · Packages
Why Reactive Agents?
Most AI agent frameworks are dynamically typed, monolithic, and opaque. They assume you're using GPT-4, break when you try smaller models, and hide every decision behind abstractions you can't inspect. Reactive Agents takes a fundamentally different approach:
| Problem | How We Solve It |
|---|---|
| No type safety | Effect-TS schemas validate every service boundary at compile time |
| Monolithic | 13 independent layers -- enable only what you need |
| Opaque decisions | 10-phase execution engine with before/after/error hooks on every phase |
| Model lock-in | Model-adaptive context profiles (4 tiers: local, mid, large, frontier) help smaller models punch above their weight |
| Single reasoning mode | 5 strategies (ReAct, Reflexion, Plan-Execute, Tree-of-Thought, Adaptive) |
| Unsafe by default | Guardrails block injection/PII/toxicity before the LLM sees input |
| No cost control | Complexity router picks the cheapest capable model; budget enforcement at 4 levels |
| Poor DX | Builder API chains capabilities in one place; great frameworks disappear, ours feels like superpowers |
Cortex Studio
A full-featured local studio for live debugging — start it with .withCortex() or rax run --cortex:
Beacon view: live agent canvas — cognitive state, entropy signal, token usage per step
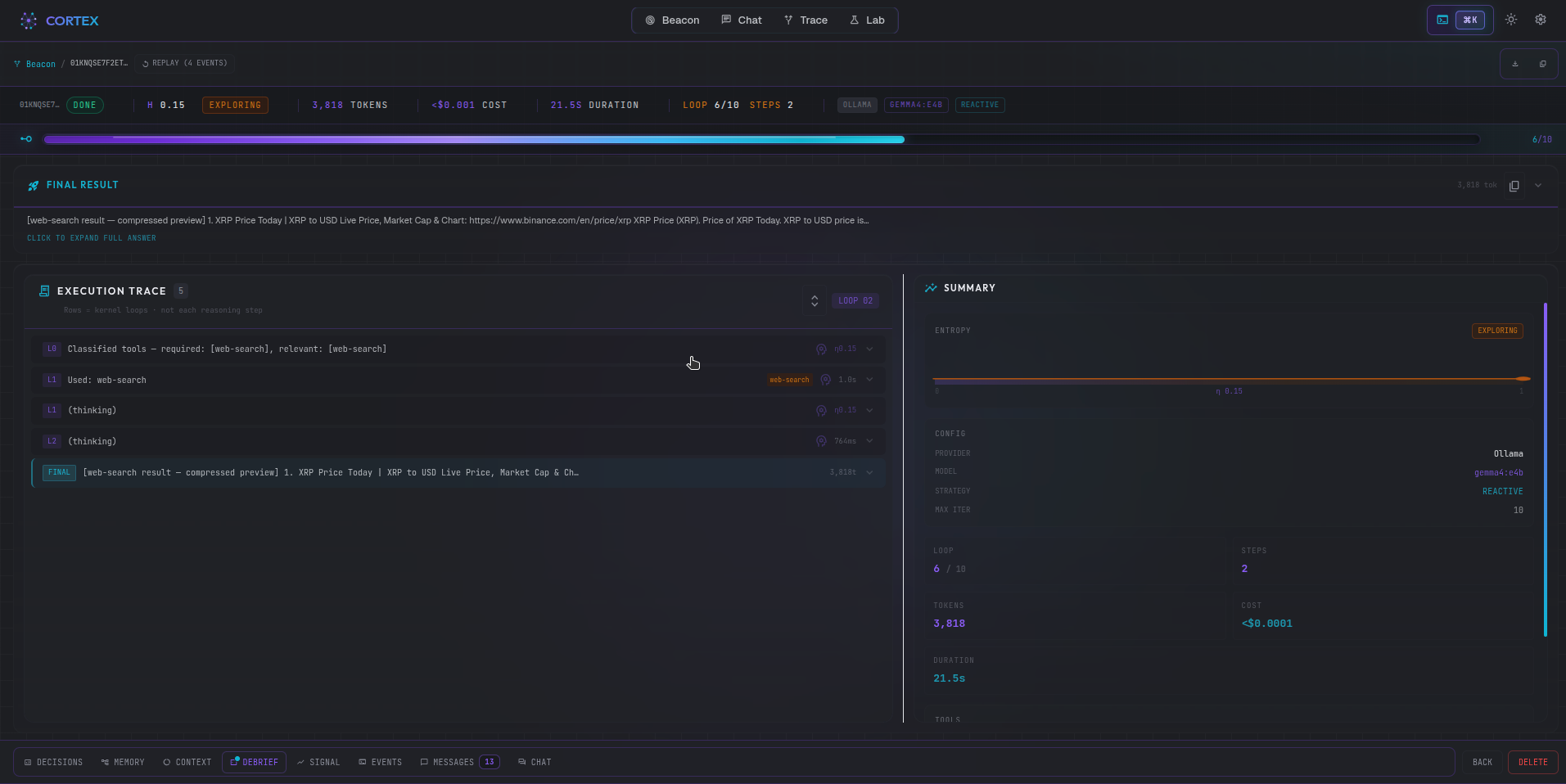
Run details: vitals strip, step-by-step execution trace, and AI-generated debrief summary
→ Full Cortex documentation with more screenshots
Features
- 5 reasoning strategies + adaptive meta-strategy (ReAct, Reflexion, Plan-Execute, Tree-of-Thought, Adaptive) + Intelligent Context Synthesis — optional fast-template or deep-LLM transcript shaping each iteration (
withReasoning({ synthesis, strategies: { … } }),ContextSynthesizedon EventBus) - 6 LLM providers -- Anthropic, OpenAI, Google Gemini, Ollama (local), LiteLLM (40+ models), Test (deterministic)
- Model-adaptive context profiles -- 4 tiers (local, mid, large, frontier) with tier-aware prompts, compaction, and truncation
- 4-layer memory -- working, episodic, semantic (vector + FTS5), procedural (bun:sqlite); ExperienceStore for cross-agent learning; background consolidation + decay
- Real-time token streaming + SSE via
agent.runStream()with AbortSignal cancellation,IterationProgress+StreamCancelledevents, andStreamCompleted.toolSummary - Persistent autonomous gateway -- adaptive heartbeats, cron scheduling, webhook ingestion (GitHub adapter), composable policy engine
- Agent debrief + conversational chat --
agent.chat()andagent.session()(with optional SQLite persistence viaSessionStoreService) for adaptive Q&A; post-runDebriefSynthesizerproduces structured summaries persisted to SQLite - A2A multi-agent protocol -- Agent Cards, JSON-RPC 2.0 server/client, SSE streaming, agent-as-tool composition
- Multi-agent orchestration -- sequential, parallel, pipeline, and map-reduce workflows with dynamic sub-agent spawning
- Production guardrails -- injection detection, PII filtering, toxicity blocking, kill switch, behavioral contracts
- Ed25519 identity -- real cryptographic agent certificates, RBAC, delegation, and audit trails
- Cost tracking -- complexity routing across 27 signals, semantic caching, budget enforcement with persistence across restarts, dynamic pricing fetching via
.withDynamicPricing()(e.g. OpenRouter), cache-aware token discounts - Professional metrics dashboard -- EventBus-driven execution timeline, tool call summary, smart alerts, and cost estimation (zero manual instrumentation)
- Native function-calling harness -- provider capability routing with robust fallback parsing for JSON tool calls embedded in model text (fenced or bare JSON) when native tool calls are missing
- Required tools guard -- ensure agents call critical tools before answering (static list or adaptive LLM inference), with relevant-tool pass-through, satisfied-required re-calls, and per-tool call budgets (
maxCallsPerTool) to prevent research loops - Builder hardening --
withStrictValidation(),withTimeout(),withRetryPolicy(),withCacheTimeout(), consolidatedwithGuardrails()thresholds,withErrorHandler(),withFallbacks(),withLogging(),withHealthCheck(), automatic strategy switching - Harness quality controls --
withMinIterations(n)blocks early exit,withVerificationStep()adds LLM self-review,withOutputValidator(fn)retries on invalid output,withCustomTermination(fn)user-defined done predicate,withProgressCheckpoint(n)resumable agents,withTaskContext(record)background data injection - ToolBuilder fluent API -- define tools without raw schema objects
- Provider fallback chains --
FallbackChain+withFallbacks()for graceful degradation across providers/models - Cortex live reporting --
.withCortex(url?)streams runtime EventBus telemetry to Cortex over WebSocket (/ws/ingest) with best-effort delivery - Structured logging --
makeLoggerService()with level filtering, JSON/text format, and file output with rotation viawithLogging() - Health checks --
withHealthCheck()+agent.health()returns{ status, checks[] } - Adaptive calibration -- three-tier live learning (shipped prior → community profile → local posterior); per-run observations stored at
~/.reactive-agents/observations/;parallelCallCapabilityandclassifierReliabilityadapt empirically after 5 runs; classifier bypass saves an LLM round-trip when reliability is low; auto-enabled when.withReasoning()is active, opt out with.withCalibration("skip") - Reactive intelligence -- 5-source entropy sensor, reactive controller (10 mid-run decisions including early-stop, context compression, strategy switch, temp-adjust, skill-activate, prompt-switch, tool-inject, memory-boost, skill-reinject, human-escalate), local learning engine (conformal calibration, Thompson Sampling bandit, skill synthesis), telemetry client (api.reactiveagents.dev),
.withReactiveIntelligence()builder method with hooks, constraints, and autonomy control - Living Skills System -- agentskills.io SKILL.md compatibility,
SkillStoreService(SQLite-backed),SkillEvolutionService(LLM refinement + version management), unifiedSkillResolverService(SQLite + filesystem), 5-stage compression pipeline, context-aware injection guard with model-tier budgets,activate_skill+get_skill_sectionmeta-tools,.withSkills()builder,agent.skills()/exportSkill()/loadSkill()/refineSkills()runtime API - Agent as Data --
AgentConfigJSON-serializable schema,builder.toConfig()reverse mapping,ReactiveAgents.fromConfig()/.fromJSON()reconstruction, roundtrip serialization - Lightweight composition --
agentFn()lazy agent primitives,pipe()sequential chains,parallel()concurrent fan-out,race()first-to-complete — all composable - Dynamic tool registration --
agent.registerTool()/agent.unregisterTool()for runtime tool management on live agents - Web framework integration —
@reactive-agents/react(useAgentStream,useAgent),@reactive-agents/vuecomposables,@reactive-agents/sveltestores — consumeAgentStream.toSSE()from Next.js, SvelteKit, Nuxt, or any SSE-capable server - 3,879 tests across 430 files
Quick Start
Install and run your first TypeScript AI agent in under 60 seconds.
bun add reactive-agents
Note:
effectis included as a dependency ofreactive-agentsand installed automatically. If you import fromeffectdirectly in your own code (e.g.import { Effect } from "effect"), add it to your project explicitly:bun add effect.
import { ReactiveAgents } from 'reactive-agents'
const agent = await ReactiveAgents.create()
.withName('assistant')
.withProvider('anthropic')
.withModel('claude-sonnet-4-20250514')
.build()
const result = await agent.run('Explain quantum entanglement')
console.log(result.output)
console.log(result.metadata) // { duration, cost, tokensUsed, stepsCount }
Add Capabilities
Every capability is opt-in. Chain what you need:
const agent = await ReactiveAgents.create()
.withName('research-agent')
.withProvider('anthropic')
.withReasoning() // ReAct reasoning loop
.withTools() // Built-in tools + MCP support
.withMemory('1') // Persistent memory (FTS5 search)
.withGuardrails() // Block injection, PII, toxicity
.withKillSwitch() // Per-agent + global emergency halt
.withBehavioralContracts({
// Enforce tool whitelist + iteration cap
deniedTools: ['file-write'],
maxIterations: 10,
})
.withVerification() // Fact-check outputs
.withCostTracking() // Budget enforcement + model routing
.withObservability({ verbosity: 'verbose', live: true }) // Live log streaming + tracing
.withContextProfile({ tier: 'local' }) // Adaptive context for model tier
.withIdentity() // RBAC + agent certificates (Ed25519)
.withInteraction() // 5 autonomy modes
.withOrchestration() // Multi-agent workflows
.withSelfImprovement() // Cross-task strategy outcome learning
.withRequiredTools({
// Ensure critical tools are called
tools: ['web-search'],
maxRetries: 2,
})
.withStrictValidation() // Throw at build time if required config is missing
.withTimeout(60_000) // Execution timeout (ms)
.withRetryPolicy({ maxRetries: 3, backoffMs: 1_000 }) // Retry on transient LLM failures
.withCacheTimeout(3_600_000) // Semantic cache TTL (ms)
.withErrorHandler((err, ctx) => {
// Global error callback
console.error('Agent error:', err.message)
})
.withFallbacks({
// Provider/model fallback chain
providers: ['anthropic', 'openai'],
errorThreshold: 3,
})
.withLogging({ level: 'info', format: 'json', filePath: './agent.log' }) // Structured logging
.withHealthCheck() // Enable agent.health() probe
.withMinIterations(3) // Require at least 3 iterations before exit
.withVerificationStep({ mode: 'reflect' }) // LLM self-review pass after initial answer
.withOutputValidator((output) => ({
// Structural validation with retry
valid: output.includes('COMPLETE'),
feedback: 'Response must include COMPLETE marker',
}))
.withTaskContext({ project: 'acme', env: 'prod' }) // Background data → reasoning context
.withSkills({
// Living Skills System
paths: ['./my-skills/'],
evolution: { mode: 'suggest' },
})
.withGateway({
// Persistent autonomous harness
heartbeat: { intervalMs: 1_800_000, policy: 'adaptive' },
crons: [{ schedule: '0 9 * * MON', instruction: 'Weekly review' }],
policies: { dailyTokenBudget: 50_000 },
})
.build()
Conversational Chat
Use agent.chat() for single-turn Q&A or agent.session() for multi-turn conversations with adaptive routing -- direct LLM for simple questions, full ReAct loop for tool-capable queries:
// Single-turn chat
const answer = await agent.chat("What's the status of the deployment?")
// Multi-turn session
const session = agent.session()
await session.chat("Summarize yesterday's logs")
await session.chat('Which errors were most frequent?')
Agent Config (Agent as Data)
Define agents as JSON-serializable config objects. Save, share, and reconstruct agents without code:
import {
agentConfigToJSON,
agentConfigFromJSON,
ReactiveAgents,
} from 'reactive-agents'
// Builder → Config → JSON
const builder = ReactiveAgents.create()
.withName('researcher')
.withProvider('anthropic')
.withReasoning({ defaultStrategy: 'plan-execute-reflect' })
.withTools({ adaptive: true })
.withMemory('2')
const config = builder.toConfig()
const json = agentConfigToJSON(config)
// Save to file, database, or send over the wire
// JSON → Builder → Agent
const restored = await ReactiveAgents.fromJSON(json)
const agent = await restored.build()
const result = await agent.run('Research quantum computing advances')
Composition API
Build agent pipelines with functional combinators:
import { agentFn, pipe, parallel, race } from 'reactive-agents'
// Create lazy agent functions
const researcher = agentFn({ name: 'researcher', provider: 'anthropic' }, (b) =>
b.withReasoning().withTools()
)
const summarizer = agentFn({ name: 'summarizer', provider: 'anthropic' })
// Sequential pipeline: research → summarize
const pipeline = pipe(researcher, summarizer)
const result = await pipeline('What are the latest AI breakthroughs?')
// Parallel fan-out: run multiple analyses concurrently
const multiAnalysis = parallel(
agentFn({ name: 'sentiment', provider: 'anthropic' }),
agentFn({ name: 'keywords', provider: 'anthropic' }),
agentFn({ name: 'summary', provider: 'anthropic' })
)
const combined = await multiAnalysis('Article text here...')
// combined.output contains labeled results from all 3 agents
// Race: fastest agent wins
const fastest = race(
agentFn({ name: 'claude', provider: 'anthropic' }),
agentFn({ name: 'gpt4', provider: 'openai' })
)
const winner = await fastest('Quick answer needed')
// Clean up
await pipeline.dispose()
await multiAnalysis.dispose()
await fastest.dispose()
Streaming
Tokens arrive as they're generated via AsyncGenerator. Pass an AbortSignal to cancel mid-stream:
const controller = new AbortController()
for await (const event of agent.runStream('Analyze this dataset', {
signal: controller.signal,
})) {
if (event._tag === 'TextDelta') process.stdout.write(event.text)
if (event._tag === 'IterationProgress')
console.log(`Step ${event.iteration}/${event.maxIterations}`)
if (event._tag === 'StreamCancelled') console.log('Stream cancelled')
if (event._tag === 'StreamCompleted') {
console.log('\nDone!')
// event.toolSummary: Array<{ toolName, calls, successRate }>
}
}
// Cancel from elsewhere (e.g., HTTP request abort)
controller.abort()
Lifecycle Hooks
Intercept any of the 10 execution phases with before, after, or error hooks:
import { Effect } from 'effect'
import { ReactiveAgents } from 'reactive-agents'
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools()
.withHook({
phase: 'think',
timing: 'after',
handler: (ctx) => {
console.log(
`Step ${ctx.metadata.stepsCount}: ${ctx.metadata.strategyUsed}`
)
return Effect.succeed(ctx)
},
})
.withHook({
phase: 'act',
timing: 'after',
handler: (ctx) => {
const last = ctx.toolResults.at(-1) as
| { toolName?: string }
| undefined
if (last?.toolName) console.log(`Tool called: ${last.toolName}`)
return Effect.succeed(ctx)
},
})
.build()
Available phases: bootstrap, guardrail, cost-route, strategy, think, act, observe, verify, memory-flush, complete. Each supports before, after, and on-error timing.
Comparison
How Reactive Agents compares to other TypeScript agent frameworks on shipped, working features:
| Capability | Reactive Agents | LangChain JS | Vercel AI SDK | Mastra |
|---|---|---|---|---|
| Full type safety (Effect-TS) | Yes | -- | Partial | Partial |
| Composable layer architecture | 13 layers | -- | -- | -- |
| Reasoning strategies | 5 + adaptive | 1 (ReAct) | -- | 1 |
| Model-adaptive context | 4 tiers | -- | -- | -- |
| Local model optimization | Yes | -- | -- | -- |
| Execution lifecycle hooks | 10 phases | Callbacks | Middleware | -- |
| Multi-agent orchestration | A2A + workflows | Yes | -- | Yes |
| Token streaming | Yes | Yes | Yes | Yes |
| Production guardrails | Yes | -- | -- | -- |
| Cost tracking + budgets | Yes | -- | -- | -- |
| Persistent gateway | Yes | -- | -- | -- |
| Agent debrief + chat | Yes | -- | -- | -- |
| Metrics dashboard | Yes | LangSmith | -- | -- |
| Agent-as-data config | Yes | -- | -- | -- |
| Functional composition | Yes | Yes | -- | -- |
| Dynamic tool registration | Yes | Yes | -- | -- |
| Test suite | 3,879 tests | -- | -- | -- |
Use Cases
- Autonomous engineering agents with tool execution and code generation
- Research and reporting workflows with verifiable reasoning steps
- Scheduled background agents using heartbeats, cron jobs, and webhooks
- Secure enterprise copilots with RBAC, audit trails, and policy controls
- Hybrid local/cloud AI deployments with adaptive context profiles
- Multi-agent teams with A2A protocol and dynamic sub-agent delegation
Architecture
ReactiveAgentBuilder
-> createRuntime()
-> Core Services EventBus, AgentService, TaskService
-> LLM Provider Anthropic, OpenAI, Gemini, Ollama, LiteLLM, Test
-> Memory Working, Semantic, Episodic, Procedural
-> Reasoning ReAct, Reflexion, Plan-Execute, ToT, Adaptive
-> Tools Registry, Sandbox, MCP Client
-> Guardrails Injection, PII, Toxicity, Kill Switch, Behavioral Contracts
-> Verification Semantic Entropy, Fact Decomposition, NLI
-> Cost Complexity Router, Budget Enforcer, Cache
-> Identity Certificates, RBAC, Delegation, Audit
-> Observability Tracing, Metrics, Structured Logging
-> Interaction 5 Modes, Checkpoints, Preference Learning
-> Orchestration Sequential, Parallel, Pipeline, Map-Reduce
-> Prompts Template Engine, Version Control
-> Gateway Heartbeats, Crons, Webhooks, Policy Engine
-> ExecutionEngine 10-phase lifecycle with hooks
Every layer is an Effect Layer -- composable, independently testable, and tree-shakeable.
10-Phase Execution Engine
Every task flows through a deterministic lifecycle. Each phase calls its corresponding service when enabled:
Bootstrap --> Guardrail --> Cost Route --> Strategy Select
|
+--------------------+
| Think -> Act -> Observe | <-- loop
+--------------------+
|
Verify --> Memory Flush --> Cost Track --> Audit --> Complete
| Phase | Service Called | What It Does |
|---|---|---|
| Bootstrap | MemoryService | Load context from semantic/episodic memory |
| Guardrail | GuardrailService | Block unsafe input before LLM sees it |
| Cost Route | CostService | Select optimal model tier by complexity |
| Strategy Select | ReasoningService | Pick reasoning strategy (or direct LLM) |
| Think/Act/Observe | LLMService + ToolService | Reasoning loop with real tool execution |
| Verify | VerificationService | Fact-check output (entropy, decomposition, NLI) |
| Memory Flush | MemoryService | Persist session + episodic memories |
| Cost Track | CostService | Record spend against budget |
| Audit | ObservabilityService | Log audit trail (tokens, cost, strategy, duration) |
| Complete | -- | Build final result with metadata |
Every phase supports before, after, and on-error lifecycle hooks. When observability is enabled, every phase emits trace spans and metrics.
5 Reasoning Strategies
| Strategy | How It Works | Best For |
|---|---|---|
| ReAct | Think -> Act -> Observe loop | Tool use, step-by-step tasks |
| Reflexion | Generate -> Critique -> Improve | Quality-critical output |
| Plan-Execute | Plan steps -> Execute -> Reflect -> Refine | Structured multi-step work |
| Tree-of-Thought | Branch -> Score -> Prune -> Synthesize | Creative, open-ended problems |
| Adaptive | Analyze task -> Auto-select best strategy | Mixed workloads |
// Auto-select the best strategy per task
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning({ defaultStrategy: 'adaptive' })
.build()
// Automatic strategy switching on loop detection
const agent2 = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning({
enableStrategySwitching: true,
maxStrategySwitches: 1,
fallbackStrategy: 'plan-execute-reflect',
})
.build()
Multi-Provider Support
| Provider | Models | Tool Calling | Streaming |
|---|---|---|---|
| Anthropic | Claude Haiku, Sonnet, Opus | Yes | Yes |
| OpenAI | GPT-4o, GPT-4o-mini | Yes | Yes |
| Google Gemini | Gemini Flash, Pro | Yes | Yes |
| Ollama | Any local model | Yes | Yes |
| LiteLLM | 40+ models via LiteLLM proxy | Yes | Yes |
| Test | Mock (deterministic) | -- | -- |
Switch providers with one line -- agent code stays the same.
Model-Adaptive Context
Optimize prompt construction and context compaction for your model tier:
const agent = await ReactiveAgents.create()
.withProvider('ollama')
.withModel('qwen3:4b')
.withReasoning()
.withTools()
.withContextProfile({ tier: 'local' }) // Lean prompts, aggressive compaction
.build()
| Tier | Models | Context Strategy |
|---|---|---|
"local" |
Ollama small models (<=14b) | Lean prompts, aggressive compaction after 6 steps, 800-char truncation |
"mid" |
Mid-range models | Balanced prompts, moderate compaction |
"large" |
Anthropic, OpenAI, Gemini | Full context, standard compaction |
"frontier" |
Flagship models | Maximum context, minimal compaction |
Packages
| Package | Description |
|---|---|
@reactive-agents/core |
EventBus pub/sub, AgentService lifecycle, TaskService state machine, canonical types |
@reactive-agents/runtime |
10-phase ExecutionEngine, ReactiveAgentBuilder, createRuntime() layer composer |
@reactive-agents/llm-provider |
Unified LLM interface for Anthropic, OpenAI, Gemini, Ollama, LiteLLM, and Test providers |
@reactive-agents/memory |
4-layer memory (working, semantic, episodic, procedural) on bun:sqlite; ExperienceStore cross-agent learning; background consolidation + decay |
@reactive-agents/reasoning |
5 strategies (ReAct, Reflexion, Plan-Execute, ToT, Adaptive) with composable kernel architecture |
@reactive-agents/tools |
Tool registry with sandboxed execution, MCP client, agent-as-tool adapter, dynamic sub-agent spawning |
@reactive-agents/guardrails |
Pre-LLM safety: injection detection, PII filtering, toxicity blocking |
@reactive-agents/verification |
Post-LLM quality: semantic entropy, fact decomposition, NLI hallucination detection |
@reactive-agents/cost |
27-signal complexity routing, per-execution budget enforcement, semantic cache |
@reactive-agents/identity |
Ed25519 agent certificates, RBAC policies, delegation chains, audit logging |
@reactive-agents/observability |
Distributed tracing (OTLP), MetricsCollector, structured logging, console + JSON exporters |
@reactive-agents/interaction |
5 autonomy modes, checkpoint/resume, approval gates, preference learning |
@reactive-agents/orchestration |
Multi-agent workflows: sequential, parallel, pipeline, map-reduce with A2A support |
@reactive-agents/prompts |
Version-controlled template engine with variable interpolation and prompt library |
@reactive-agents/eval |
Evaluation framework: LLM-as-judge scoring, EvalStore persistence, comparison reports |
@reactive-agents/a2a |
A2A protocol: Agent Cards, JSON-RPC 2.0 server/client, SSE streaming |
@reactive-agents/gateway |
Persistent autonomous harness: adaptive heartbeats, cron scheduling, webhook ingestion, composable policy engine |
@reactive-agents/testing |
Mock services (LLM, tools, EventBus), assertion helpers, deterministic test fixtures |
@reactive-agents/benchmarks |
Benchmark suite: 20 tasks x 5 tiers, overhead measurement, report generation |
@reactive-agents/health |
Health checks and readiness probes for production deployments |
@reactive-agents/reactive-intelligence |
Metacognitive layer: entropy sensor (5 sources), reactive controller (early-stop, compression, strategy switch), learning engine (calibration, bandit, skill synthesis), telemetry client |
@reactive-agents/react |
React 18+ hooks: useAgentStream (token streaming), useAgent (one-shot) — consume AgentStream.toSSE() endpoints |
@reactive-agents/vue |
Vue 3 composables: useAgentStream, useAgent with reactive refs |
@reactive-agents/svelte |
Svelte 4/5 stores: createAgentStream, createAgent writable stores |
Observability & Metrics Dashboard
When observability is enabled, the agent displays a professional metrics dashboard after each execution:
+-------------------------------------------------------------+
| Agent Execution Summary |
+-------------------------------------------------------------+
| Status: Success Duration: 13.9s Steps: 7 |
| Tokens: 1,963 Cost: ~$0.003 Model: claude-3.5 |
+-------------------------------------------------------------+
Execution Timeline
|- [bootstrap] 100ms ok
|- [think] 10,001ms warn (7 iter, 72% of time)
|- [act] 1,000ms ok (2 tools)
|- [complete] 28ms ok
Tool Execution (2 called)
|- file-write ok 3 calls, 450ms avg
|- web-search ok 2 calls, 280ms avg
- Per-phase execution timing and bottleneck identification
- Tool call summary (success/error counts, average duration)
- Smart alerts and optimization tips
- Cost estimation in USD
- EventBus-driven collection (no manual instrumentation)
Enable with:
.withObservability({ verbosity: "normal", live: true })
CLI (rax)
rax init my-project --template full # Scaffold a project
rax create agent researcher --recipe researcher # Generate an agent from recipe
rax create agent my-agent --interactive # Interactive scaffolding (readline prompts)
rax run "Explain quantum computing" --provider anthropic # Run an agent
rax cortex --dev # Cortex API + Vite UI (like apps/cortex bun start)
rax cortex # Cortex API only (or bundled static UI)
rax run "Task" --cortex --provider anthropic # Stream events to Cortex (.withCortex())
Register Custom Tools
Tools are registered at build time, via agent.registerTool() after build(), or through MCP. Built-in task tools include web search, file I/O, HTTP, and code execution; dynamic sub-agents add spawn-agent. With .withTools(), the Conductor's Suite also injects recall, find, brief, and pulse (override with .withMetaTools(false)).
Use the ToolBuilder fluent API to define tools without raw schema objects:
import { ReactiveAgents } from 'reactive-agents'
import { ToolBuilder } from '@reactive-agents/tools'
import { Effect } from 'effect'
const webSearchTool = ToolBuilder.create('web_search')
.description('Search the web for current information')
.param('query', 'string', 'Search query', { required: true })
.riskLevel('low')
.timeout(10_000)
.handler((args) => Effect.succeed(`Results for: ${args.query}`))
.build()
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools({ tools: [webSearchTool] })
.build()
Or use raw schema objects directly:
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withReasoning()
.withTools({
tools: [
{
definition: {
name: 'web_search',
description: 'Search the web for current information',
parameters: [
{
name: 'query',
type: 'string',
description: 'Search query',
required: true,
},
],
riskLevel: 'low',
timeoutMs: 10_000,
requiresApproval: false,
source: 'function',
},
handler: (args) => Effect.succeed(`Results for: ${args.query}`),
},
],
})
.build()
Dynamic Tool Registration
Add or remove tools from a running agent at runtime:
import { Effect } from 'effect'
const agent = await ReactiveAgents.create()
.withName('adaptive-agent')
.withProvider('anthropic')
.withReasoning()
.withTools()
.build()
// Register a new tool at runtime
await agent.registerTool(
{
name: 'custom_api',
description: 'Call the custom API',
parameters: [
{
name: 'endpoint',
type: 'string',
description: 'API endpoint',
required: true,
},
],
riskLevel: 'low',
source: 'function',
},
(args) => Effect.succeed(`Response from ${args.endpoint}`)
)
// Later, remove it when no longer needed
await agent.unregisterTool('custom_api')
Dynamic Sub-Agent Spawning
Use .withDynamicSubAgents() to let the model spawn ad-hoc sub-agents at runtime without pre-configuring named agent tools. This registers the built-in spawn-agent tool, which the model can invoke freely:
const agent = await ReactiveAgents.create()
.withProvider('anthropic')
.withModel('claude-sonnet-4-6')
.withTools()
.withDynamicSubAgents({ maxIterations: 5 })
.build()
Sub-agents receive a clean context window, inherit the parent's provider and model by default, and are depth-limited to MAX_RECURSION_DEPTH = 3.
| Approach | When to use |
|---|---|
.withAgentTool("name", config) |
Named, purpose-built sub-agent with a specific role |
.withDynamicSubAgents() |
Ad-hoc delegation at model's discretion, unknown tasks |
Testing
Built-in test scenario support for deterministic, offline tests:
const agent = await ReactiveAgents.create()
.withTestScenario([
{ match: 'capital of France', text: 'Paris is the capital of France.' },
])
.build()
const result = await agent.run('What is the capital of France?')
// result.output -> "Paris is the capital of France."
The @reactive-agents/testing package includes streaming assertions and pre-built scenario fixtures:
import {
expectStream,
createGuardrailBlockScenario,
createBudgetExhaustedScenario,
} from '@reactive-agents/testing'
// Stream assertions
const stream = agent.runStream('Write a haiku')
await expectStream(stream)
.toEmitTextDeltas()
.toComplete()
.toEmitEvents(['TextDelta', 'StreamCompleted'])
// Pre-built scenario fixtures
const scenario = createGuardrailBlockScenario() // agent + prompt that triggers guardrail
const budget = createBudgetExhaustedScenario() // agent + prompt that exhausts budget
const maxIter = createMaxIterationsScenario() // agent + prompt that hits max iterations
FAQ
Which models and providers are supported?
Reactive Agents supports 6 providers: Anthropic, OpenAI, Google Gemini, Ollama (local models), LiteLLM (40+ models via proxy), and a Test provider for deterministic offline testing via withTestScenario().
Is this framework production-ready?
Yes -- it includes guardrails, budget controls, auditability, observability, Ed25519 identity, and composable service layers for testable deployments. 3,879 tests across 430 files.
Can I run fully local agents?
Yes -- use Ollama with local models plus context profiles tuned for local inference. The "local" tier optimizes prompts and compaction for small models (<=14b parameters).
How does this compare to LangChain or Vercel AI SDK?
See the comparison table. The key differences are: full Effect-TS type safety, composable layers instead of a monolithic runtime, 5 reasoning strategies with adaptive selection, and model-adaptive context profiles that help local models perform far beyond naive prompting.
Development
bun install # Install dependencies
bun test # Run full test suite (3,879 tests, 430 files)
bun run build # Build all packages (25 packages, ESM + DTS)
Environment Variables
ANTHROPIC_API_KEY=sk-ant-... # Anthropic Claude
OPENAI_API_KEY=sk-... # OpenAI GPT-4o
GOOGLE_API_KEY=... # Google Gemini
EMBEDDING_PROVIDER=openai # For vector memory
EMBEDDING_MODEL=text-embedding-3-small
LLM_DEFAULT_MODEL=claude-sonnet-4-20250514
Documentation
Full documentation at docs.reactiveagents.dev
- Getting Started -- Build an agent in 5 minutes
- Reasoning Strategies -- All 5 strategies explained
- Architecture -- Layer system deep dive
- Cookbook -- Testing, multi-agent patterns, production deployment
Getting Help
- Discord -- Join the community for questions, discussions, and support
- GitHub Issues -- Report bugs or request features
- GitHub Discussions -- Ask questions and share ideas
License
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found