AgentLint
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 9 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
AgentLint is a shell-based linting tool that scans your repository for AI agent compatibility. It analyzes file structure, documentation quality, and security posture to provide a score and suggest fixes to help AI assistants work better within your codebase.
Security Assessment
Overall risk: Low. The static code scan of 12 files found no dangerous patterns, hardcoded secrets, or requests for elevated permissions. The tool is inherently designed to read repository structure and configuration files, but it does not access sensitive system data outside your project folder. However, the recommended installation method (`curl | bash`) executes a remote shell script directly. While common in open-source, this practice bypasses manual review and is the only notable security consideration. Users should review the install script before running it.
Quality Assessment
The project is actively maintained, with its most recent push happening today. It uses the permissive MIT license and includes CI/CD pipelines alongside automated releases, indicating professional development practices. The README is highly detailed and transparent, clearly outlining what the tool evaluates. The only weakness is low community visibility; it currently has only 9 GitHub stars. While the repository appears well-built, the low adoption rate means fewer independent developers have reviewed the code or tested it in diverse environments.
Verdict
Safe to use, but review the installation shell script manually before executing it.
Lint your repo for AI agent compatibility.
AgentLint
![]()
![]()

Your AI agent is only as good as your repo. AgentLint finds what's broken — file structure, instruction quality, build setup, session continuity, security posture — and fixes it. 33 checks, every one backed by data.
We analyzed 265 versions of Anthropic's Claude Code system prompt, documented the hard limits, audited thousands of real repos, and reviewed the academic research. The result: a single command that tells you exactly what your AI agent is struggling with and why.
Install
curl -fsSL https://raw.githubusercontent.com/0xmariowu/agent-lint/main/scripts/install.sh | bash
Then start a new Claude Code session:
/al
That's it. AgentLint scans your projects, scores them, shows what's wrong, and fixes what it can.
What you get
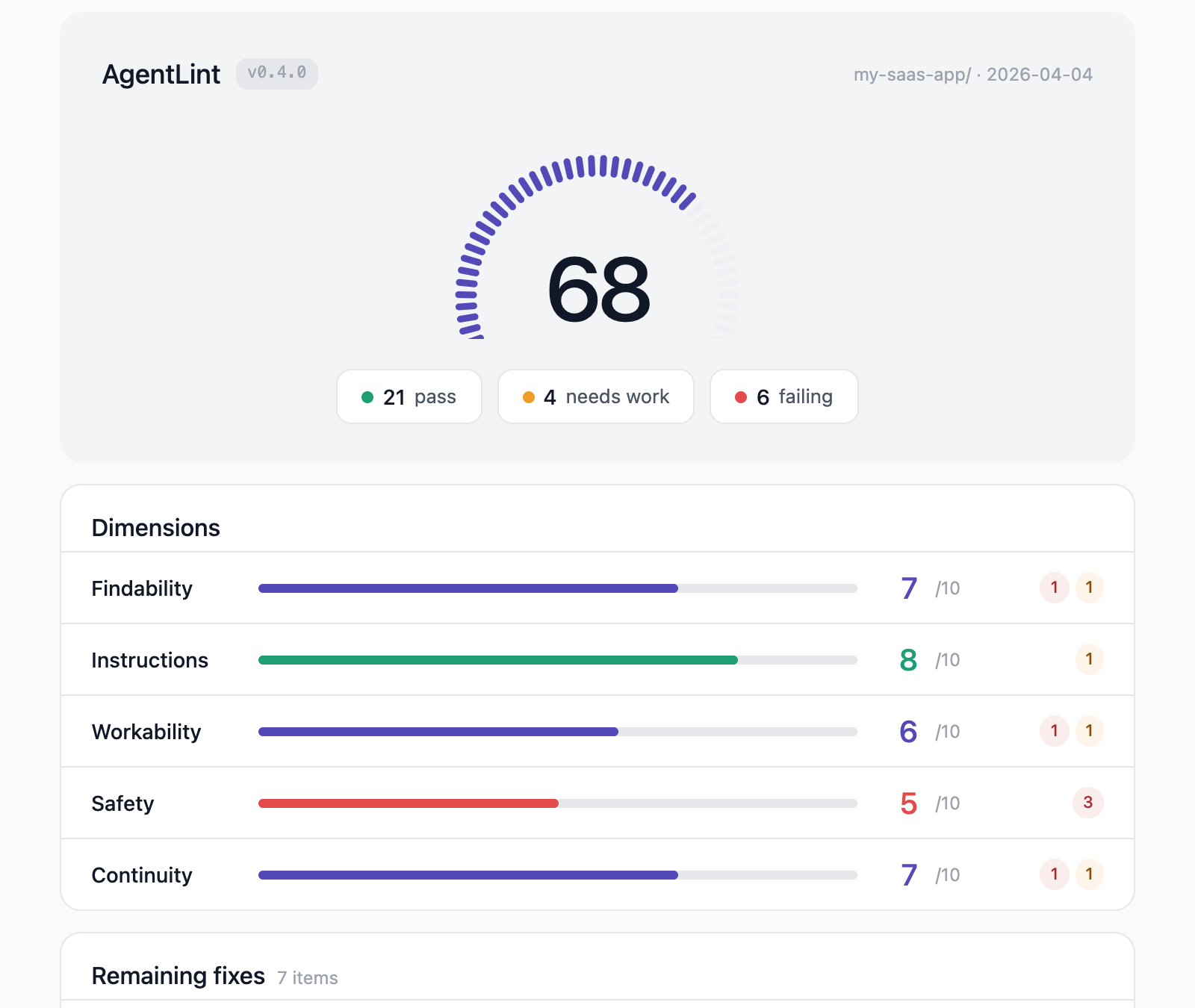
$ /al
AgentLint — Score: 68/100
Findability ██████████████░░░░░░ 7/10
Instructions ████████████████░░░░ 8/10
Workability ████████████░░░░░░░░ 6/10
Safety ██████████░░░░░░░░░░ 5/10
Continuity ██████████████░░░░░░ 7/10
Fix Plan (7 items):
[guided] Pin 8 GitHub Actions to SHA (supply chain risk)
[guided] Add .env to .gitignore (AI exposes secrets)
[assisted] Generate HANDOFF.md
[guided] Reduce IMPORTANT keywords (7 found, Anthropic uses 4)
Select items → AgentLint fixes → re-scores → saves HTML report
The HTML report shows a segmented gauge, expandable dimension breakdowns with per-check detail, and a prioritized issues list. Before/after comparison when fixes are applied.
Why this matters
AI coding agents read your repo structure, docs, CI config, and handoff notes. They git push, trigger pipelines, and write files. A well-structured repo gets dramatically better AI output. A poorly structured one wastes tokens, ignores rules, repeats mistakes, and may expose secrets.
AgentLint is built on data most developers never see:
- 265 versions of Anthropic's Claude Code system prompt — every word added, deleted, and rewritten
- Claude Code internals — hard limits (40K char max, 256KB file read limit, pre-commit hook behavior) that silently break your setup
- Production security audits across open-source codebases — the gaps AI agents walk into
- 6 academic papers on instruction-following, context files, and documentation decay
What it checks
Findability — can AI find what it needs?
| Check | What | Why |
|---|---|---|
| F1 | Entry file exists | No CLAUDE.md = AI starts blind |
| F2 | Project description in first 10 lines | AI needs context before rules |
| F3 | Conditional loading guidance | "If working on X, read Y" prevents context bloat |
| F4 | Large directories have INDEX | >10 files without index = AI reads everything |
| F5 | All references resolve | Broken links waste tokens on dead-end reads |
| F6 | Standard file naming | README.md, CLAUDE.md are auto-discovered |
| F7 | @include directives resolve | Missing targets are silently ignored — you think it's loaded, it isn't |
Instructions — are your rules well-written?
| Check | What | Why |
|---|---|---|
| I1 | Emphasis keyword count | Anthropic cut IMPORTANT from 12 to 4 across 265 versions |
| I2 | Keyword density | More emphasis = less compliance. Anthropic: 7.5 → 1.4 per 1K words |
| I3 | Rule specificity | "Don't X. Instead Y. Because Z." — Anthropic's golden formula |
| I4 | Action-oriented headings | Anthropic deleted all "You are a..." identity sections |
| I5 | No identity language | "Follow conventions" removed — model already does this |
| I6 | Entry file length | 60-120 lines is the sweet spot. Longer dilutes priority |
| I7 | Under 40,000 characters | Claude Code hard limit. Above this, your file is truncated |
Workability — can AI build and test?
| Check | What | Why |
|---|---|---|
| W1 | Build/test commands documented | AI can't guess your test runner |
| W2 | CI exists | Rules without enforcement are suggestions |
| W3 | Tests exist (not empty shell) | A CI that runs pytest with 0 test files always "passes" |
| W4 | Linter configured | Mechanical formatting frees AI from guessing style |
| W5 | No files over 256 KB | Claude Code cannot read them — hard error |
| W6 | Pre-commit hooks are fast | Claude Code never uses --no-verify. Slow hooks = stuck commits |
Continuity — can next session pick up?
| Check | What | Why |
|---|---|---|
| C1 | Document freshness | Stale instructions are worse than no instructions |
| C2 | Handoff file exists | Without it, every session starts from zero |
| C3 | Changelog has "why" | "Updated INDEX" says nothing. "Fixed broken path" says everything |
| C4 | Plans in repo | Plans in Jira don't exist for AI |
| C5 | CLAUDE.local.md not in git | Private per-user file. Claude Code requires .gitignore |
Safety — is AI working securely?
| Check | What | Why |
|---|---|---|
| S1 | .env in .gitignore | AI's Glob tool ignores .gitignore by default — secrets are visible |
| S2 | Actions SHA pinned | AI push triggers CI. Floating tags = supply chain attack vector |
| S3 | Secret scanning configured | AI won't self-check for accidentally written API keys |
| S4 | SECURITY.md exists | AI needs security context for sensitive code decisions |
| S5 | Workflow permissions minimized | AI-triggered workflows shouldn't have write access by default |
| S6 | No hardcoded secrets | Detects sk-, ghp_, AKIA, private key patterns in source |
| S7 | No personal paths | /Users/xxx/ in source = AI copies and spreads the leak |
| S8 | No pull_request_target | AI pushes trigger CI. Elevated permissions = attack vector |
Optional: AI Deep Analysis
Spawns AI subagents to find what mechanical checks can't:
- Contradictory rules that confuse the model
- Dead-weight rules the model would follow without being told
- Vague rules without decision boundaries
Optional: Session Analysis
Reads your Claude Code session logs to find:
- Instructions you repeat across sessions (should be in CLAUDE.md)
- Rules AI keeps ignoring (need rewriting)
- Friction hotspots by project
How scoring works
Each check produces a 0-1 score, weighted by dimension, scaled to 100.
| Dimension | Weight | Why? |
|---|---|---|
| Instructions | 30% | Unique value. No other tool checks CLAUDE.md quality |
| Findability | 20% | AI can't follow rules it can't find |
| Workability | 20% | Can AI actually run your code? |
| Safety | 15% | Is AI working without exposing secrets or triggering vulnerabilities? |
| Continuity | 15% | Does knowledge survive across sessions? |
Scores are measurements, not judgments. Reference values come from Anthropic's own data. You decide what to fix.
Update
claude plugin update agent-lint@agent-lint
Evidence
Every check cites its source. Full citations in standards/evidence.json.
| Source | Type |
|---|---|
| Anthropic 265 versions | Primary dataset |
| Claude Code internals | Hard limits and observed behavior |
| IFScale (NeurIPS) | Instruction compliance at scale |
| ETH Zurich | Do context files help coding agents? |
| Codified Context | Stale content as #1 failure mode |
| Agent READMEs | Concrete vs abstract effectiveness |
Requirements
- Claude Code
jqandnode20+
License
MIT
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi