ddddocr
Health Warn
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 312 GitHub stars
Code Pass
- Code scan — Scanned 10 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
This tool is a Rust-based CAPTCHA recognition library and OCR API server, designed for easy deployment across multiple platforms. It also includes support for the AI MCP protocol to allow tool-based interactions.
Security Assessment
The overall risk is rated as Low. The automated code scan checked 10 files and found no dangerous patterns, hardcoded secrets, or requests for excessive system permissions. The server natively makes network requests because it operates as an API, meaning it will listen on local ports. However, since it is an OCR server intended to process images, you should ensure it is deployed in a secure, isolated network environment. Depending on how you use it, the images sent to the server for processing could potentially contain sensitive visual data.
Quality Assessment
The project appears to be highly maintained and active, with its last push occurring less than a day ago. It has garnered over 300 GitHub stars, indicating a solid level of community trust and real-world usage. One notable drawback is that the automated scan flagged the repository for missing a license file, even though the README claims to use the Apache 2.0 license. Developers should manually verify the license in the repository before adopting it for commercial purposes to avoid any legal ambiguity.
Verdict
Safe to use, though commercial users should manually verify the repository's license status before integration.
ddddocr rust 版本,ocr_api_server rust 版本,二进制版本,验证码识别,不依赖 opencv 库,跨平台运行,AI MCP 支持,a simple OCR API server, very easy to deploy。
简介
ddddocr rust 版本。
ocr_api_server rust 版本。
二进制版本,验证码识别,不依赖 opencv 库,跨平台运行。
a simple OCR API server, very easy to deploy。
![]()


![]()
一个容易使用的通用验证码识别 rust 库
·
报告Bug
·
提出新特性
目录
环境支持
| 系统 | CPU | GPU | 备注 |
|---|---|---|---|
| Windows 64位 | √ | ? | 部分版本 Windows 需要安装 vc 运行库 |
| Windows 32位 | √ | ? | 不支持静态链接,部分版本 Windows 需要安装 vc 运行库 |
| Linux 64 / ARM64 | √ | ? | 可能需要升级 glibc 版本, 升级 glibc 版本 |
| Linux 64 / MUSL | √ | ? | 不需要 glibc,静态链接 |
| Linux 32 | × | ? | |
| Macos X64 | √ | ? | M1/M2/M3 ... 芯片参考 #67 |
安装步骤
lib.rs 实现了 ddddocr。
main.rs 实现了 ocr_api_server。
model 目录是模型与字符集。
依赖本库 ddddocr = {git = "https://github.com/86maid/ddddocr.git", branch = "master"}
开启 cuda 特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["cuda"] }
支持静态和动态链接,默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如有更多问题,请跳转至疑难杂症部分。
如果你不想从源代码构建,这里有编译好的二进制版本。
还可以使用配置好的 Github Action 进行构建。
使用文档
OCR 识别
内容识别
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写or通过设置结果范围圈定大小写)、数字以及部分特殊字符。
let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
let res = ocr.classification(image).unwrap();
println!("{:?}", res);
旧模型
let image = std::fs::read("target.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification_old().unwrap();
let res = ocr.classification(image).unwrap();
println!("{:?}", res);
支持识别透明黑色 png 格式的图片,使用 png_fix 参数
classification_with_png_fix(image, true);
颜色过滤
支持以下预设颜色:red(红色)、blue(蓝色)、green(绿色)、yellow(黄色)、orange(橙色)、purple(紫色)、cyan(青色)、black(黑色)、white(白色)、gray(灰色)。
let ddddocr = ddddocr_classification().unwrap();
// 只保留绿色
println!(
"{}",
ddddocr
.classification_with_filter(include_bytes!("../image/4.png"), "green")
.unwrap()
);
// 只保留红色和绿色
println!(
"{}",
ddddocr
.classification_with_filter(include_bytes!("../image/4.png"), ["red", "green"])
.unwrap()
);
// HSV 范围,每个元素是一个 (min_hsv, max_hsv) 的元组。
println!(
"{}",
ddddocr
.classification_with_filter(
include_bytes!("../image/4.png"),
[((40, 50, 50), (80, 255, 255))]
)
.unwrap()
);
参考例图




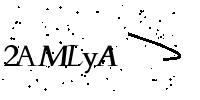




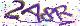


目标检测
let image = std::fs::read("target.png").unwrap();
let mut det = ddddocr::ddddocr_detection().unwrap();
let res = det.detection(image).unwrap();
println!("{:?}", res);
参考例图
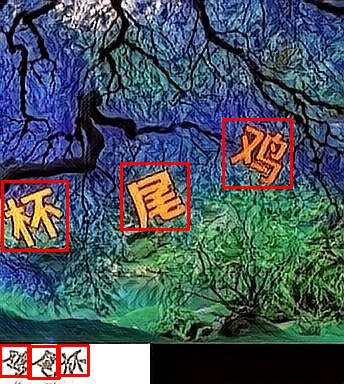

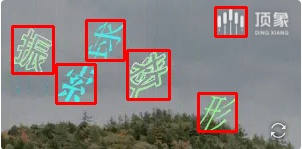


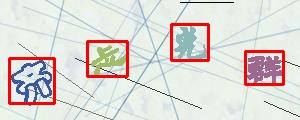

以上只是目前我能找到的点选验证码图片,做了一个简单的测试。
滑块匹配
算法非深度神经网络实现。
算法1
小滑块为单独的png图片,背景是透明图,如下图:

然后背景为带小滑块坑位的,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);
如果小图无过多背景部分,则可以使用 simple_slide_match,通常为 jpg 或者 bmp 格式的图片
let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::simple_slide_match(target_bytes, background_bytes).unwrap();
println!("{:?}", res);
算法2
一张图为带坑位的原图,如下图:

一张图为原图,如下图:

let target_bytes = std::fs::read("target.png").unwrap();
let background_bytes = std::fs::read("background.png").unwrap();
let res = ddddocr::slide_comparison(target_bytes, background_bytes).unwrap();
println!("{:?}", res);
OCR 概率输出
为了提供更灵活的 ocr 结果控制与范围限定,项目支持对ocr结果进行范围限定。
可以通过在调用 classification_probability 返回全字符表的概率。
当然也可以通过 set_ranges 设置输出字符范围来限定返回的结果。
| 参数值 | 意义 |
|---|---|
| 0 | 纯整数 0-9 |
| 1 | 纯小写字母 a-z |
| 2 | 纯大写字母 A-Z |
| 3 | 小写字母 a-z + 大写字母 A-Z |
| 4 | 小写字母 a-z + 整数 0-9 |
| 5 | 大写字母 A-Z + 整数 0-9 |
| 6 | 小写字母 a-z + 大写字母A-Z + 整数0-9 |
| 7 | 默认字符库 - 小写字母a-z - 大写字母A-Z - 整数0-9 |
如果值为 string 类型,请传入一段不包含空格的文本,其中的每个字符均为一个待选词,例如:"0123456789+-x/="
let image = std::fs::read("image.png").unwrap();
let mut ocr = ddddocr::ddddocr_classification().unwrap();
// 数字 3 对应枚举 CharsetRange::LowercaseUppercase,不用写枚举
// ocr.set_ranges(3);
// 设置全局字符集
ocr.set_ranges("0123456789+-x/=");
// 或者,单次识别的字符集
// ocr.classification_probability_with_ranges(image, "0123456789+-x/=");
let result = ocr.classification_probability(image).unwrap();
println!("识别结果: {}", result.get_text());
println!("识别可信度: {}", result.get_confidence());
// 哦呀,看来数据有点儿太多了,小心卡死哦!
println!("概率: {}", result.json());
自定义 OCR 训练模型导入
支持导入 dddd_trainer 训练后的自定义模型。
use ddddocr::*;
let mut ocr = Ddddocr::with_model_charset(
"myproject_0.984375_139_13000_2022-02-26-15-34-13.onnx",
"charsets.json",
)
.unwrap();
let image_bytes = std::fs::read("888e28774f815b01e871d474e5c84ff2.jpg").unwrap();
let res = ocr.classification(&image_bytes).unwrap();
println!("{:?}", res);
ocr_api_server 例子
运行方式
Usage: ddddocr.exe [OPTIONS]
Options:
--address <ADDRESS>
监听地址。 [default: 0.0.0.0:8000]
--mcp
mcp 协议支持,与 only_mcp 互斥。
--only-mcp
仅开启 mcp 协议,不开启普通路由,与 mcp 互斥。
--ocr
开启内容识别,与 old 互斥。
--old
开启旧版模型内容识别,与 ocr 互斥。
--det
开启目标检测。
--slide
开启滑块和坑位识别。
--ocr-charset-range <OCR_CHARSET_RANGE>
全局默认字符集,用于概率识别, 如果 API 未提供字符集,则使用此参数, 当值为 0~7 时,表示选择内置字符集, 其他值表示自定义字符集,例如 "0123456789+-x/=", 如果未设置,则使用完整字符集,不做限制。
--ocr-path <OCR_PATH>
内容识别模型以及字符集路径, 如果你开启了 features 的 inline-model 选项(默认开启),则不用管这个选项,除非你想使用自定义模型, 模型 model/common.onnx 和字符集 model/common.json 要同名。 [default: model/common.onnx]
--det-path <DET_PATH>
目标检测模型路径, 如果你开启了 features 的 inline-model 选项(默认开启),则不用管这个选项,除非你想使用自定义模型。 [default: model/common_det.onnx]
--acme <ACME>
输入你的域名,自动获取 SSL 证书, 即 https 的支持。
-h, --help
Print help
运行例子
# 启动所有功能
ddddocr.exe --address 0.0.0.0:8000 --ocr --det --slide --mcp
# 查看所有选项
ddddocr.exe --help
API 说明
| 端点 | 方法 | 说明 |
|---|---|---|
/ocr |
POST | 执行OCR识别 |
/det |
POST | 执行目标检测 |
/slide-match |
POST | 滑块匹配算法 |
/slide-comparison |
POST | 滑块比较算法 |
/status |
GET | 获取当前服务状态 |
/docs |
GET | Swagger UI 文档 |
API 测试例子,完整的测试请看 test_api.py 文件
--> 200 GET /status
curl -X GET "http://127.0.0.1:8000/status"
{"code":200,"msg":"success","data":{"service_status":"running","enabled_features":["ocr","det","slide"]}}
--> 200 POST /ocr
curl -X POST "http://127.0.0.1:8000/ocr"
-H "Content-Type: application/json"
-d '{"image": "base64 image"}'
{"code":200,"msg":"success","data":{"text":"九乘六等于?","probability":null}}
--> 200 POST /det
curl -X POST "http://127.0.0.1:8000/det"
-H "Content-Type: application/json"
-d '{"image": "base64 image"}'
{"code":200,"msg":"success","data":{"bboxes":[[80,3,98,21],[56,6,76,25],[31,7,51,26],[2,2,21,22],[100,0,127,18]]}}
--> 200 POST /slide-match
curl -X POST "http://127.0.0.1:8000/slide-match"
-H "Content-Type: application/json"
-d '{"target_image": "base64 image", "background_image": "base64 image", "simple_target": true}'
{"code":200,"msg":"success","data":{"target":[215,45,261,91],"target_x":0,"target_y":45}}
--> 200 POST /slide-comparison
curl -X POST "http://127.0.0.1:8000/slide-comparison"
-H "Content-Type: application/json"
-d '{"target_image": "base64 image", "background_image": "base64 image"}'
{"code":200,"msg":"success","data":{"x":144,"y":76}}
MCP 协议支持
本项目支持 MCP(Model Context Protocol)协议,使 AI Agent 能够直接调用 ddddocr 服务。
版本:2025-11-25
端点:POST /mcp
方法:initialize tools/list tools/call
工具调用请求
{
"jsonrpc": "2.0",
"id": 0,
"method": "tools/call",
"params": {
"name": "ocr",
"arguments": {"image": "image_b64", "color_filter": "green"},
},
}
工具调用响应
{
"jsonrpc": "2.0",
"id": 0,
"result": {
"content": [
{
"type": "text",
"text": "{\"probability\":null,\"text\":\"等于?\"}"
}
],
"isError": false
}
}
疑难杂症
强烈推荐用 Github Action 进行构建。
关于使用 cuda 的问题。
cuda 和 cuDNN 都需要安装好。
CUDA 12 构建需要 cuDNN 9.x。
CUDA 11 构建需要 cuDNN 8.x。
不确定 cuda 10 是否有效。
默认使用静态链接,构建时将会自动下载链接库,请设置好代理,cuda 特性不支持静态链接(会自己下载动态链接库)。
如果要指定静态链接库的路径,可以设置环境变量 ORT_LIB_LOCATION,设置后将不会自动下载链接库。
例如,库路径为 onnxruntime\build\Windows\Release\Release\onnxruntime.lib,则 ORT_LIB_LOCATION 设置为 onnxruntime\build\Windows\Release。
默认开启 download-binaries 特性,自动下载链接库。
下载不了大部分是网络问题,开启代理后,记得重启 vscode,重启终端,以便代理能够使用 https_proxy 环境变量。
自动下载的链接库存放在 C:\Users\<用户名>\AppData\ort.pyke.io。
开启动态链接特性 ddddocr = { git = "https://github.com/86maid/ddddocr.git", branch = "master", features = ["load-dynamic"] }
开启 load-dynamic 特性后,可以使用 Ddddocr::set_onnxruntime_path 指定 onnxruntime 动态链接库的路径。
开启 load-dynamic 特性后,构建时将不会自动下载 onnxruntime 链接库。
请手动下载 onnxruntime 链接库,并将其放置在程序运行目录下(或系统 API 目录),这样无需再次调用 Ddddocr::set_onnxruntime_path。
windows 静态链接失败,请安装 vs2022。
linux musl 要用 docker 编译。
linux x86-64 静态链接失败,请安装 gcc11 和 g++11,ubuntu ≥ 20.04。
linux arm64 静态链接失败,需要 glibc ≥ 2.35 (Ubuntu ≥ 22.04)。
macOS 静态链接失败,需要 macOS ≥ 10.15。
cuda 在执行 cargo test 的时候可能会 painc (exit code: 0xc000007b),这是因为自动生成的动态链接库是在 target/debug 目录下,需要手动复制到 target/debug/deps 目录下(cuda 目前不支持静态链接)。
动态链接需要 1.18.x 版本的 onnxruntime。
更多疑难杂症,请跳转至 ort.pyke.io。
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found