llm-ops
Health Warn
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
学习大模型相关技术原理以及实战经验(大模型工程化、大模型应用落地) 丐版dify. 立即上线你的agent 应用.
AI 智能体开发平台技术栈
api 概览
《LLMOps平台:AI应用构建器》是新一代 AI 原生应用开发服务平台,可在平台上搭建基于 AI 模型的各类问答应用、工作 流应用,从解决简单的问答到处理复杂的逻辑任务。还可将 AI 应用一键发布到对应的社交平台、Web网页、可供第三方调用的MCP服务,甚至是基于平台的开放 API 进行二次开发。
🛠️ 核心技术栈
1. AI 与 基础
- Prompt 提示词: 提示词工程与优化
- LangChain / LangGraph: 大模型应用开发框架
- RAG 知识库与优化: 检索增强生成技术
- 向量数据库: embeddings 存储与检索
- LLM 提供商: 对接各大模型接口
- 微调基础: Fine-tuning
2. Agent 与 协议
- 单/多 Agent: 智能体架构设计
- Workflow 工作流: 业务流程编排
- MCP 协议: Model Context Protocol 标准
- Celery 消息队列: 异步任务处理
3. 全栈开发
- 前端: VUE / TypeScript / acro
- 后端: Flask (Python)
- 部署: 本地/云服务部署
- 数据库: postgres / Weaviate
️ LLMOps 平台能力
平台核心功能
- 可视化编排 + 智能化定制: 拖拽式开发界面
- 工作流编排: 复杂逻辑图形化构建
- 自定义插件: 扩展系统功能
- 对接知识库: 快速接入 RAG 能力
- 一键发布到多平台: 多渠道部署
- 多 LLM 模型快速接入: 支持模型切换
- 单/多 Agent 定制开发: 灵活配置智能体
- 将 Agent 发布为 MCP 服务: 标准化服务输出
- 多模态: 支持图文音视频处理
🚀 实现场景
基于自研llm平台编排的各类 AI 应用:
智能客服系统: 自动化客户支持
PPT 自动生成工具: 文档转演示文稿
env config
OPENAI_API_KEY=<your-api-key>
OPENAI_API_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
FLASK_ENV=development
FLASK_DEBUG=1
# sql congig
SQLALCHEMY_DATABASE_URI=postgresql://postgres:postgres@localhost:5432/llmops?client_encoding=utf8
SQLALCHEMY_POOL_SIZE=30
SQLALCHEMY_POOL_RECYCLE=3600
SQLALCHEMY_ECHO=True
WTF_CSRF_ENABLED=False
#### LangSmith
# https://smith.langchain.com/
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_API_KEY=<your-api-key>
LANGSMITH_PROJECT="llmops" # project name
# redis
REDIS_HOST=127.0.0.1
REDIS_PORT=6379
REDIS_DB=0
REDIS_PASSWORD=
REDIS_USERNAME=
REDIS_USE_SSL=False
#celery
CELERY_BROKER_DB=1
CELERY_RESULT_BACKEND_DB=1
CELERY_TASK_IGNORE_RESULT=False
CELERY_RESULT_EXPIRES=3600
CELERY_BROKER_CONNECTION_RETRY_ON_STARTUP=True
# 高德工具
GAODE_API_KEY=
# 谷歌serper搜索 https://serper.dev/api-keys
SERPER_API_KEY=
# 腾讯云
COS_SECRET_ID=
COS_SECRET_KEY=
COS_BUCKET=
COS_REGION=
COS_SCHEME=https
COS_DOMAIN=
EMBEDDING_MODEL=qwen3-embedding:0.6b
OLLAMA_BASE_URL=http://127.0.0.1:11434
docker postgres
docker run --name postgres-dev -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -d postgres
docker Weaviate
docker run -d --name weaviate-dev -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.35.3
docker redis
docker run --name redis-dev -d -p 6379:6379 redis
embedding local
开发环境使用ollama运行qw3-embedding:0.6b, 根据实际情况选择模型
run project
# celery 异步任务处理
celery -A app.http.app.celery worker -l info --pool eventlet --logfile storage/log/celery.log
# dev
uv run python app\http\app.py
初始化生成迁移脚本
flask --app app.http.app db init
flask --app app.http.app db migrate
# -m "msg"
# 升级
flask --app app.http.app db upgrade
#回退
flask --app app.http.app db downgrade
数据库关系图
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ UploadFile │◄────│ Document │◄────│ Segment │
│ (上传文件) │ 1:1 │ (文档) │ 1:N│ (片段) │
└─────────────────┘ └────────┬────────┘ └────────┬────────┘
│ │
│ │
┌────────────┘ │
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Dataset │◄────────────────│ KeywordTable │
│ (知识库) │ 1:1 │ (关键词表) │
└────────┬────────┘ └─────────────────┘
│
│ N:M
▼
┌─────────────────┐
│ AppDatasetJoin │
│(应用-知识库关联) │
└─────────────────┘
│
▼
┌─────────────────┐
│ App │
│ (AI应用) │
└─────────────────┘
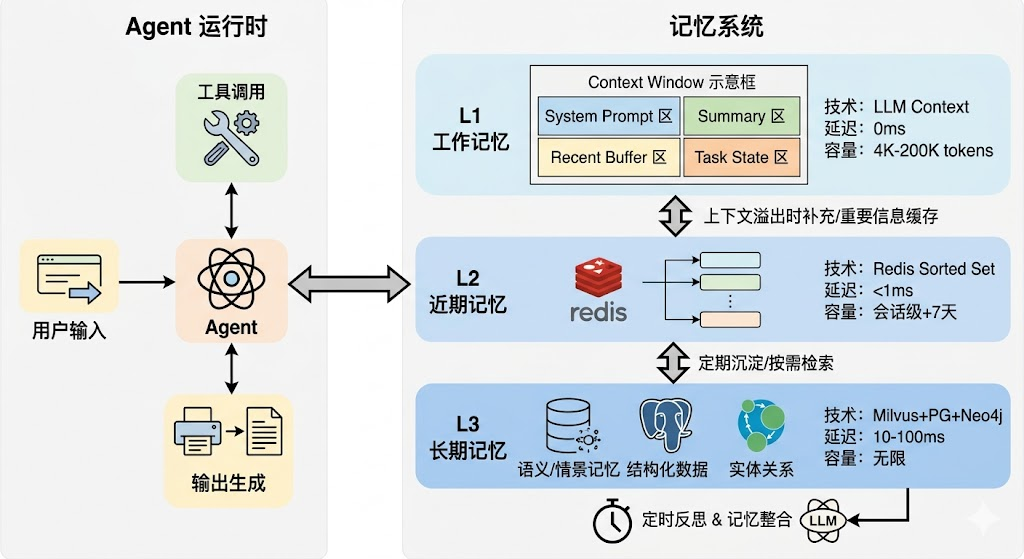
Agent 概念和运行流程
在 LLM 应用中,如果我们知道用户输入所需的工具使用特定顺序时,使用 LCEL 表达式构建链应用非常有用,但是对于某一些特例,我们使用工具的次数与顺序取决于输入,在这种情况下,我们希望让 LLM 本身决定使用工具的次数和顺序,而 Agent 智能体 能做到这一点。
在 LangChain 中,Agent 是一个核心概念,它代表了一种能够利用语言模型(LLM)和其他工具来执行复杂任务的系统,Agent 设计的目的是为了处理那些语言模型可能无法直接解决的问题,尤其是当这些任务涉及到多个步骤或者需要外部数据源的情况。
无论一个 Agent 设计得多么复杂,使用什么架构,最基础的工作流程其实都非常简单,只有 5 个步骤:
输入理解:Agent 首先解析用户输入,理解其意图和需求。
计划定制:基于对输入的理解,Agent 会制定一个执行计划,决定使用哪些工具和执行的顺序。
工具调用:Agent 按照计划调用相应的工具,执行必要的操作。
结果整合:收集所有工具返回的结果,进行整合和解析,形成最终的输出。
反馈循环:如果任务没有完成或者需要进一步的消息,Agent 可以迭代上述过程直到满足条件为止。
┌─────────────┐ ┌─────┐ ┌─────────────┐ ┌─────────┐
│ 初始问题 │────▶│ LLM │────▶│ 格式化输出 │────▶│选择工具 │
└─────────────┘ └──┬──┘ └─────────────┘ └────┬────┘
│ │
函数调用 工具列表
│
←───────────────────────────────────┘
│ 观察/循环执行 │
│ (直到最终完成条件满足) ↓
▼ ┌──────────────┐
┌──────────┐ │ 工具执行结果 │
│ LLM │ ◀────────────────────┤ │
│(再次调用) │ └──────────────┘
└──────────┘ │
│ │ 最终调用
│ ↓
└────────────────────────►┌──────────────┐
│ 最终答案 │
└──────────────┘
PARSING Error
he words “dog”, “cat” and “banana” are all pretty common in English, so they’re part of the pipeline’s vocabulary, and come with a vector. The word “afskfsd” on the other hand is a lot less common and out-of-vocabulary – so its vector representation consists of 300 dimensions of
0, which means it’s practically nonexistent. If your application will benefit from a large vocabulary with more vectors, you should consider using one of the larger pipeline packages or loading in a full vector package, for example,en_core_web_lg, which includes 685k unique vectors.
pip install en_core_web_sm-3.8.0-py3-none-any.whl
参考文档
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found