af-deep-research
Health Gecti
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 71 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Autonomous AI backend for deep research AI applications.
AF Deep Research
Autonomous research backend for AI applications.
![]()
Early Preview · APIs may change. Feedback welcome.
A research API that questions itself. Submit a query. The system spawns parallel agents, evaluates what it found against quality thresholds, generates new sub-queries when gaps are detected, and runs another cycle. The architecture orchestrates ~10,000 logical agent invocations per research. This is an AI backend, not a chat interface. Built on top of agentfield runtime for orchestrating the agents.
One-Call DX
Trigger it with the af CLI (requires af ≥ 0.1.87) — it streams live progress and prints the result:
af call meta_deep_research.execute_deep_research --in '{"query": "What companies are investing in AI chips?"}'
Prefer raw HTTP? Hit the API directly with curl:
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "What companies are investing in AI chips?"}}'
Returns a structured research package — entities, relationships, evidence, and a full cited document:
{
"entities": [
{"name": "NVIDIA", "type": "Company", "summary": "Dominant AI chip maker, 80%+ datacenter GPU share"},
{"name": "Sequoia Capital", "type": "Investor", "summary": "Early NVIDIA investor, major AI fund"},
{"name": "H100", "type": "Technology", "summary": "Flagship AI training GPU, $30k+ ASP"}
],
"relationships": [
{"source": "AMD", "target": "NVIDIA", "type": "Competes_With"},
{"source": "Sequoia Capital", "target": "NVIDIA", "type": "Invests_In"},
{"source": "Microsoft", "target": "OpenAI", "type": "Partners_With"}
],
"article_evidence": [{"facts": ["NVIDIA datacenter revenue reached $18.4B in Q4"], "quotes": ["We are seeing unprecedented demand - Jensen Huang"]}],
"document": {"sections": ["...full hierarchical report with inline citations..."]},
"metadata": {"iterations_completed": 3, "total_entities": 47, "total_relationships": 89, "final_quality_score": 0.91}
}
~10,000 agent invocations. Self-correcting research loops. One API call.
Quick start
git clone https://github.com/Agent-Field/af-deep-research.git && cd af-deep-research
cp .env.example .env # Add OPENROUTER_API_KEY + at least one search provider key
docker compose up --build
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "What companies are investing in AI chips?"}}'
Returns execution_id. Stream progress via SSE, fetch results when complete.
Open localhost:8080/ui to watch the workflow live.
Run locally (without Docker)
You can run AF Deep Research directly as a Python app without the AgentField control plane managing async dispatch. It will execute synchronously.
1. Create a virtual environment and install dependencies:
python -m venv .venv && source .venv/bin/activate
pip install -e .
2. Set a writable working directory:
By default, AF Deep Research writes workspace files to /workspaces, which requires root access. Override this with the PR_AF_WORKDIR environment variable:
export PR_AF_WORKDIR=/tmp/pr-af-workdir
3. Configure your environment and start the agent:
cp .env.example .env # Add OPENROUTER_API_KEY + at least one search provider key
python3 main.py
4. Submit a query (in a separate terminal):
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "What companies are investing in AI chips?"}}'
Output
The API returns a research package with five components:
| Component | Contents |
|---|---|
entities |
Typed objects: Company, Investor, Founder, Technology, Market_Trend, Metric |
relationships |
Edges: Competes_With, Invests_In, Partners_With, Founded_By, Acquires |
article_evidence |
Facts and quotes with source article IDs |
document |
Hierarchical sections with inline citations and bibliography |
metadata |
iterations_completed, total_entities, total_relationships, final_quality_score |
{
"entities": [
{"name": "NVIDIA", "type": "Company", "summary": "Dominant AI chip maker, 80%+ datacenter GPU share"},
{"name": "Jensen Huang", "type": "Founder", "summary": "CEO of NVIDIA since 1993"},
{"name": "Sequoia Capital", "type": "Investor", "summary": "Early NVIDIA investor, major AI fund"},
{"name": "H100", "type": "Technology", "summary": "Flagship AI training GPU, $30k+ ASP"},
{"name": "AI Chip Market", "type": "Market_Trend", "summary": "Projected $300B by 2030"}
]
}
{
"relationships": [
{"source": "AMD", "target": "NVIDIA", "type": "Competes_With", "description": "Direct competition in AI accelerators"},
{"source": "Sequoia Capital", "target": "NVIDIA", "type": "Invests_In", "description": "Series A investor, 1993"},
{"source": "NVIDIA", "target": "Mellanox", "type": "Acquires", "description": "$7B acquisition for networking"},
{"source": "Microsoft", "target": "OpenAI", "type": "Partners_With", "description": "$10B strategic investment"}
]
}
{
"article_evidence": [{
"article_id": 1,
"facts": [
"NVIDIA datacenter revenue reached $18.4B in Q4",
"H100 backlog extends into late 2025"
],
"quotes": ["We are seeing unprecedented demand - Jensen Huang"]
}]
}
{
"document_title": "AI Chip Investment Landscape",
"executive_summary": "The AI chip market is experiencing...",
"sections": [
{"title": "Market Dynamics", "content": "The accelerator market reached $45B [1]..."},
{"title": "Competitive Landscape", "content": "NVIDIA maintains 80%+ share [2]..."}
],
"source_notes": [
{"citation_id": 1, "title": "AI Chip Report 2024", "domain": "reuters.com"}
]
}
{
"metadata": {
"iterations_completed": 3,
"total_entities": 47,
"total_relationships": 156,
"total_sources": 89,
"final_quality_score": 0.82
}
}
How it works
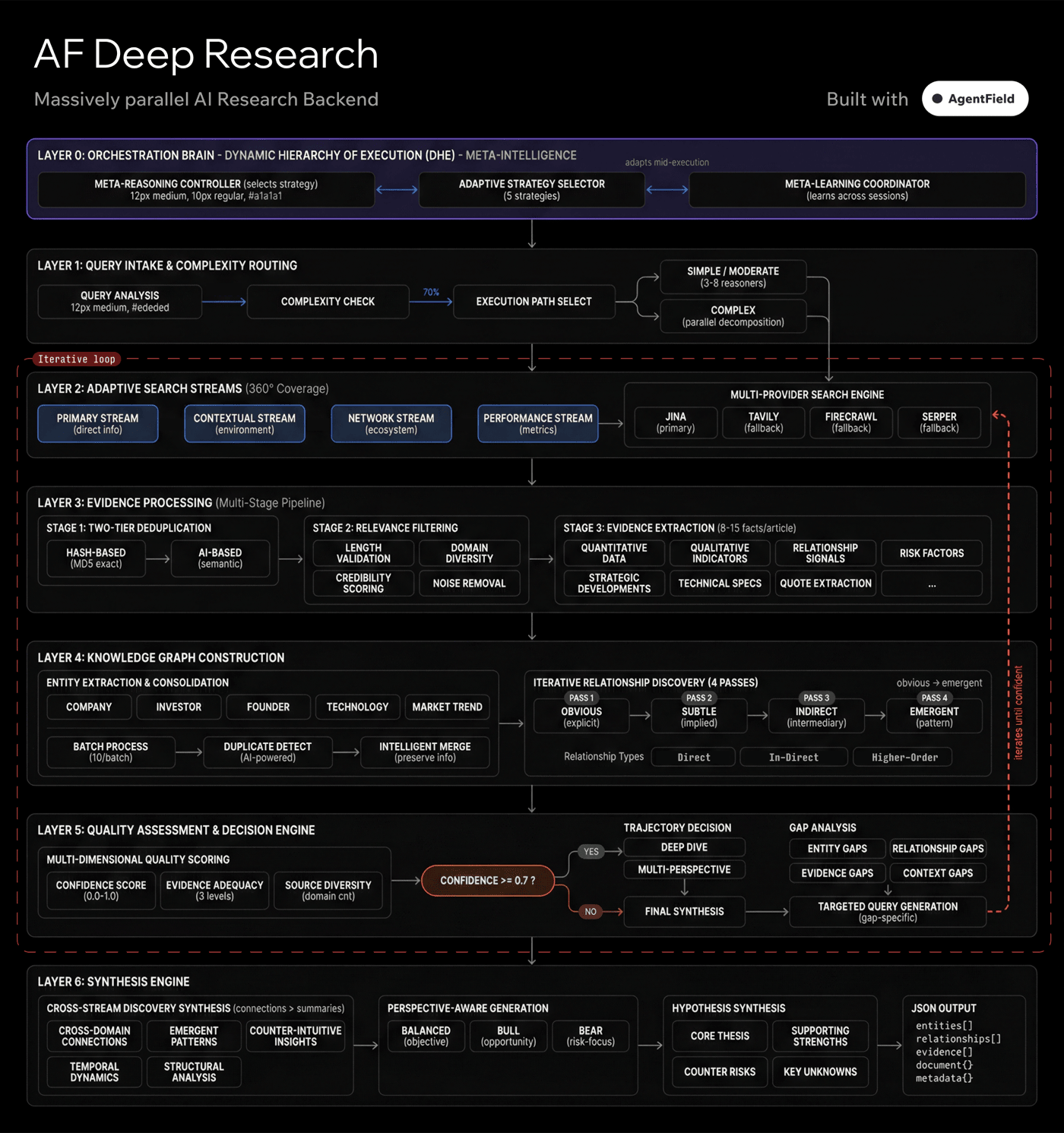
What makes this different
Traditional research: one query → retrieve → summarize → done.
This system: fan out → filter down → synthesize → find gaps → fan out again.
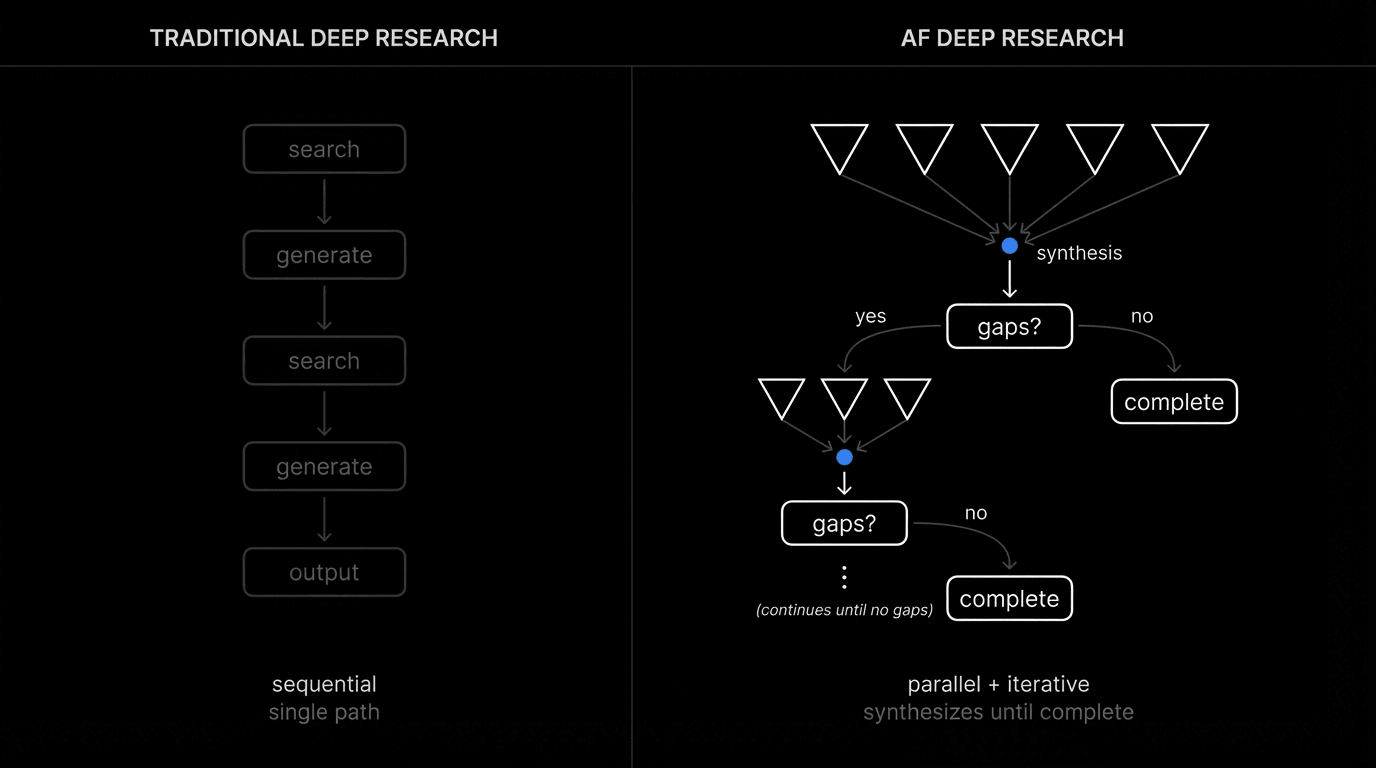
Multiple parallel streams explore different angles simultaneously. Each stream filters aggressively—only hyper-relevant evidence survives. Cross-stream synthesis finds patterns. Gap analysis identifies what's missing. New targeted streams spawn. The cycle repeats until quality threshold is met.
| Perplexity / ChatGPT | AF Deep Research | |
|---|---|---|
| Research process | One-shot generation | Self-correcting loops that ask "what am I missing?" |
| Search coverage | Single query | Multiple parallel streams, each exploring a different angle |
| What you get back | Prose with inline links | Structured JSON: typed entities, mapped relationships, cited evidence |
| Context quality | Everything retrieved goes to the LLM | Two-tier filtering so only hyper-relevant content reaches the model |
| Relationship discovery | Mentioned if obvious | Multi-pass extraction: explicit → implied → indirect → emergent patterns |
| Scaling | Fixed behavior | Width and depth scale with query complexity |
| Integration | Copy-paste from chat | REST API, SSE streaming, webhook-ready |
| Deployment | SaaS only | Self-host with local LLMs, air-gapped option |
From research to action: Contract-AF uses the same recursive multi-agent pattern to analyze legal contracts — agents spawn agents at runtime based on what they discover.
Why it works
Context pollution kills quality. When you dump 50 web pages into an LLM, important facts get buried and the model hallucinates connections. We filter aggressively—hash dedup, semantic dedup, relevance scoring—so only the best evidence reaches synthesis.
Width AND depth. Traditional tools go broad OR deep. This system scales both:
research_scopecontrols parallel streams,research_focuscontrols analysis depth. Simple queries get fewer streams; complex queries spawn more.Quality-driven, not count-driven. The system doesn't run exactly 3 iterations. After each pass it asks: what entities are missing? what relationships are unclear? what claims lack evidence? If gaps exist and are addressable, it continues. If quality threshold is met, it stops.
Cross-stream patterns. The synthesis layer doesn't summarize streams separately—it finds connections between them. A market trend that explains a technical pivot. A team background that validates a GTM strategy.
API
Submit: POST /api/v1/execute/async/meta_deep_research.execute_deep_research
Stream progress: GET /api/ui/v1/workflows/{execution_id}/notes/events (SSE)
Fetch results: GET /api/v1/executions/{execution_id}
Accessing response data
response = fetch_results(execution_id)
# Graph data
entities = response["research_package"]["entities"]
relationships = response["research_package"]["relationships"]
# Evidence for audits
evidence = response["research_package"]["article_evidence"]
# Document for rendering
sections = response["research_package"]["document"]["sections"]
bibliography = response["research_package"]["document"]["source_notes"]
# Quality gates
if response["metadata"]["final_quality_score"] < 0.7:
trigger_human_review()
Parameters
| Parameter | What it does |
|---|---|
research_focus |
Depth (1-5). Higher goes deeper. |
research_scope |
Breadth (1-5). Higher casts wider net. |
max_research_loops |
How many iterative cycles to run. |
tension_lens |
balanced, bull, or bear perspective. |
source_strictness |
strict, mixed, or permissive source filtering. |
Set tension_lens: "bear" for risk-focused analysis. Set source_strictness: "strict" to filter to reputable sources only.
Examples
Investment research pipeline
# Risk analysis for due diligence
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "Rivian competitive position and financial risks", "tension_lens": "bear"}}'
# Response feeds into: risk scoring model, portfolio dashboard, analyst report generator
Knowledge graph builder
# Extract entities and relationships for graph database
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "AI chip supply chain: manufacturers, suppliers, customers"}}'
# entities[] → Neo4j nodes
# relationships[] → Neo4j edges
# Now queryable: "Show me all companies 2 hops from NVIDIA"
Competitive intelligence system
# Track competitor moves across multiple dimensions
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "How is AMD positioning against NVIDIA in datacenter AI?", "research_scope": 5}}'
# article_evidence[] → feed alerting system
# document → auto-generate weekly competitor brief
Compliance research
# Audit-ready research with source tracking
curl -X POST http://localhost:8080/api/v1/execute/async/meta_deep_research.execute_deep_research \
-H "Content-Type: application/json" \
-d '{"input": {"query": "ESG practices of major lithium mining companies", "source_strictness": "strict"}}'
# Each fact links to source_notes[] with URL, title, domain
# Audit trail shows exactly where each claim came from
Local LLMs
To keep everything on your network:
OLLAMA_BASE_URL=http://host.docker.internal:11434
DEFAULT_MODEL=ollama/llama3.2
Model optionsNo telemetry. Your data stays on your infrastructure.
| Model | Cost |
|---|---|
deepseek-chat-v3.1 |
$0.15/0.75 per 1M tokens |
claude-sonnet-4 |
$3/$15 per 1M tokens |
ollama/llama3.2 |
Free (local) |
ollama/qwen2.5:72b |
Free (local) |
The stack
Runs on AgentField, open-source infrastructure for production AI agents. Workflows run for 16+ minutes without timeout. Progress streams via SSE. Results persist. Audit trails are cryptographically signed for compliance.
Links
Contribute
This is an early preview. We're actively developing and want feedback. File issues, open PRs, or come chat in Discord.
Also built on AgentField
Contract-AF — Legal contract risk analyzer. Agents spawn agents at runtime. Adversarial review catches what solo LLMs miss.
Reactive Atlas — Turn any MongoDB collection into an AI intelligence layer. Config-driven, zero application code.
Built by AgentField · Apache 2.0 · See what else we're building →
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi