AgentFly
Health Gecti
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 114 GitHub stars
Code Basarisiz
- rm -rf — Recursive force deletion command in .github/workflows/cpu_tests.yml
- rm -rf — Recursive force deletion command in examples/board_game/train_chess.sh
- rm -rf — Recursive force deletion command in examples/train_scripts/alfworld/train_alfworld_ray.sh
- rm -rf — Recursive force deletion command in examples/train_scripts/context/context_run_swe.sh
- rm -rf — Recursive force deletion command in examples/train_scripts/context/test_context_run.sh
Permissions Gecti
- Permissions — No dangerous permissions requested
AgentFly is a framework designed for training scalable large language model (LLM) agents using reinforcement learning. It specializes in multi-turn interactions, asynchronous tool execution, and multimodal capabilities.
Security Assessment
The tool does not request inherently dangerous permissions or contain hardcoded secrets. However, the automated security scan flagged several instances of recursive force deletion (`rm -rf`) commands. These are located within a GitHub Actions workflow (`cpu_tests.yml`) and various shell scripts used for training examples (e.g., Chess, ALFWorld). In automation scripts, `rm -rf` is typically used to clean up temporary directories or logs. While not actively malicious, these commands carry a risk of unintended data deletion if a script fails or is modified improperly. There is no evidence of unwanted network requests or sensitive data harvesting in the scan. Overall risk rating: Medium.
Quality Assessment
The project appears to be highly active and well-maintained, with its most recent push occurring today. It utilizes the permissive Apache-2.0 license, making it suitable for open-source and commercial use. Backed by 114 GitHub stars, it demonstrates a solid early stage of community trust and adoption among developers.
Verdict
Use with caution—while the framework is active, licensed, and generally safe, administrators should review the `rm -rf` cleanup commands in the example shell scripts before executing them locally to prevent accidental data loss.
Scalable and extensible reinforcement learning for LM agents.
🪽AgentFly: Training scalable LLM agents with RL (multi-turn, async tools/rewards, multimodal)


AgentFly is an extensible framework for building LLM agents with reinforcement learning. It supports multi-turn training by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, it implemented asynchronous execution of tool calls and reward computations, and design a centralized resource management system for scalable environment coordination. A suite of prebuilt tools and environments are provided.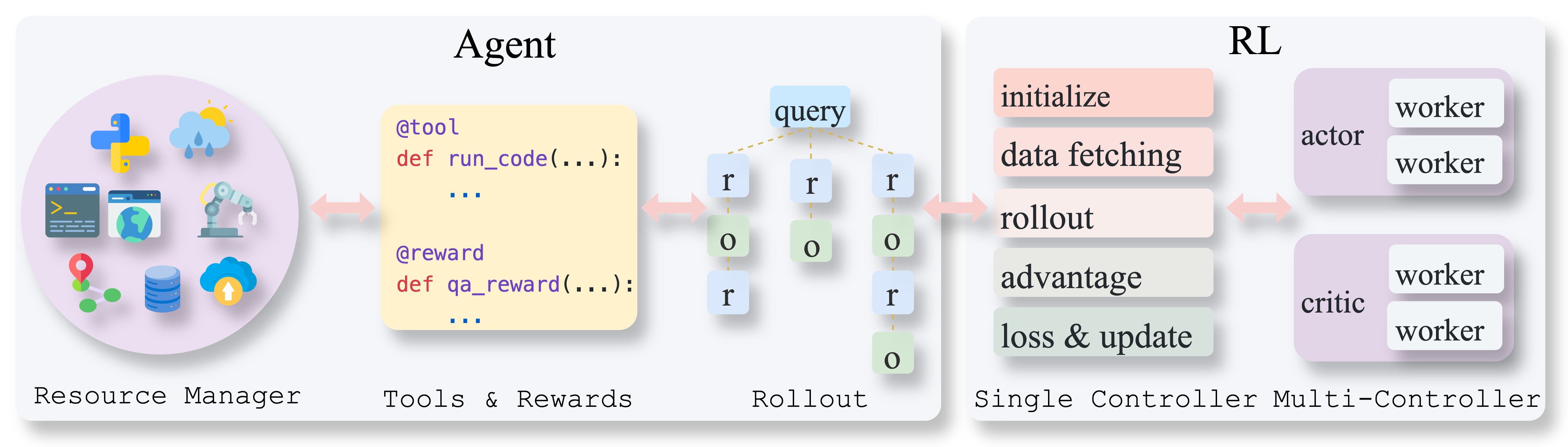
News
3/2026 Resource System: Added a resource system for better environment and container management, and integrated SWE like tasks training.
12/2025 Method-Based Tool: Support using @tool for a class method
12/2025 Verl Update: Updated verl to 0.6.x version.
08/2025 Multi-Modal (Vision) Agent Training Support: Thanks to the powerful template system, AgentFly now supports training vision-language agents! 🎉 Train agents that can see and understand visual content, including GUI automation and image-based QA. See our predefined training examples for ready-to-use scripts.
08/2025 Chat Template System: A flexible framework for creating conversation templates with multi-model support, vision capabilities, and tool integration. Learn more →
Installation
Option 1: One-line Installation:
bash install.sh # Assume conda with python3.12.x
Option 2: Customized Installation
Please refer to installation.md for custmoized installation.
Tasks
| Task | Model | Report | Status |
|---|---|---|---|
| SearchR1 | Qwen2.5 | report | ✅ |
| WebShop | Qwen2.5 | report | ✅ |
| ScienceWorld | Qwen3-4B-Instruct | report | ✅ |
| SWE | Qwen3-32B | report | ✅ (on going) |
| SimuScene | SFT DeepSeek-R1-Distill-Qwen | report | ✅ |
Quick Start
# Really small example to build an agent and run
import asyncio
from agentfly.agents import HFAgent
from agentfly.tools import calculator
async def main():
messages = [{"role": "user", "content": "What is the result of 1 + 1?"}]
agent = HFAgent(
model_name_or_path="Qwen/Qwen2.5-3B-Instruct",
tools=[calculator],
template="qwen2.5",
backend_config={"backend": "async_vllm"},
)
await agent.run(
messages=messages,
max_turns=3,
num_chains=1,
)
trajectories = agent.trajectories
print(trajectories)
asyncio.run(main())
Features
1. Multi-Chain Agent Rollout and Multi-Turn Training
To support algorithms like GRPO, Reinforce++, we design multi-chain inference, enabling agents to solve one task with multiple paths at the same time. We build RL computation and update LLMs in multi-turn manner by applying token masks. The training is based on verl.
2. Simple Tool and Reward Integration
Define tools and rewards, which can be used directly by agents.
@tool(name=...)
def customized_tool(...):
...
@reward(name=...)
def customized_reward(...):
...
agent = HFAgent(
model_name_or_path=model_name,
tools=[customized_tool],
reward=customized_reward,
backend_config={"backend": "async_vllm"},
)
3. Easy Development
Decoupled agent and training module. Simply customize your own agent, which can directly be applied to training.
Training
Run Example Training
Suppose you are in a compute node (with 8 GPUs). We have prepared training scripts for different tasks and tools in examples/train_scripts/. The scripts can download prepared datasets and run training.
Run RL training of code_interpreter:
bash examples/train_scripts/train_example.sh
Customized Training
To customize your own training, you need to prepare: 1. Datasets. 2. Define or use existing tools. 3. Define or use existing rewards. 3. Define your own agents or use an existing type of agent.
1. Data Format:
Data should be a json file, which contain a list of dicts with the following keys:
[
{
"question": ...
"optional_field1": ...
"optional_field2": ...
...
}
]
During training, question will be used to format the input messages, while other fields can be used in reward function. An example message that are put into the agent looks like this:
{
"messages": [
{"role": "user", "content": [{"type": "text", "text": question}]}
]
"optional_field1": ...
"optional_field2": ...
...
}
2. Tools & Rewards
You can use any existing tool, which is in documentation, or define a tool by decorating it with @tool. The output should eighther be a string, or a dictionary containing observation as a key.
@tool(name="customized_tool")
def customized_tool(arg1, arg2):
# tool logic here
Define your reward function or use an existing one. The reward function can accept prediction and trajectory as the argument, which is the agent's final response and the whole trajectory. Other fields will also be given if you defined them in dataset. To use them, simply put these fields as arguments in reward function.
@reward(name="customized_reward")
def customized_reward(prediction, trajectory, optional_field1, optional_field2):
# calculate reward
...
For stateful tools and rewards that hold environment instances, please refer to documentation.
3. Agents
You can use existing agents, or customize an agent. To customize an agent, the agent class must inherit BaseAgent, which handles tool calling, chain rollout. You can custom the generate and parse function. Refer to documentation for more details.
class CustomizedAgent(BaseAgent):
def __init__(self,
**kwargs
)
super().__init__(**kwargs)
async def generate_async(self, messages_list: List[List[Dict]], **args):
return await self.llm_engine.generate_async(messages_list, **args)
def parse(self, responses: List(str), tools):
# parse responses into tool calls
...
Demo
The following shows an example of WebShop agent.
What does the training look like. During training, the resource system will dynamically allocate environments.
Monitoring training on WANDB. Items include number of turns for each step, numer of tool calls, allocated environments.
https://github.com/user-attachments/assets/b8f42534-8d40-48a0-a264-f378e479bb3a
Contribute & Discussion
Cite
If you used our code or find it helpful, please cite:
@misc{wang2025agentfly,
title={AgentFly: Extensible and Scalable Reinforcement Learning for LM Agents},
author={Renxi Wang and Rifo Ahmad Genadi and Bilal El Bouardi and Yongxin Wang and Fajri Koto and Zhengzhong Liu and Timothy Baldwin and Haonan Li},
year={2025},
eprint={2507.14897},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2507.14897},
}
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi