SimpleMem
Health Gecti
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 20 days ago
- Community trust — 3247 GitHub stars
Code Uyari
- network request — Outbound network request in MCP/frontend/app.js
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
SimpleMem: Efficient Lifelong Memory for LLM Agents
Efficient Lifelong Memory for LLM Agents
Store, compress, and retrieve long-term memories with semantic lossless compression. Works across Claude, Cursor, LM Studio, and more.
Works with any AI platform that supports MCP or Python integration

Claude Desktop |

Cursor |

LM Studio |

Cherry Studio |

PyPI Package |
+ Any MCP Client |



🔥 News
- [02/09/2026] 🚀 Cross-Session Memory is Here — Outperforming Claude-Mem by 64%! SimpleMem now supports persistent memory across conversations. On the LoCoMo benchmark, SimpleMem achieves a 64% performance boost over Claude-Mem. Your agents can now recall context, decisions, and learnings from previous sessions automatically. View Cross-Session Documentation →
- [01/20/2026] SimpleMem is now available on PyPI! 📦 Install directly via
pip install simplemem. View Package Usage Guide → - [01/19/2026] Added Local Memory Storage for SimpleMem Skill! 💾 SimpleMem Skill now supports local memory storage within Claude Skills.
- [01/18/2026] SimpleMem now supports Claude Skills! 🚀 Use SimpleMem in claude.ai for long-term memory across conversations. Register at mcp.simplemem.cloud, configure your token, and import the skill!
- [01/14/2026] SimpleMem MCP Server is now LIVE and Open Source! 🎉 Cloud-hosted memory service at mcp.simplemem.cloud. Integrates with LM Studio, Cherry Studio, Cursor, Claude Desktop via Streamable HTTP MCP protocol. View MCP Documentation →
- [01/08/2026] 🔥 Join our Discord and WeChat Group to collaborate and exchange ideas!
- [01/05/2026] SimpleMem paper was released on arXiv!
📑 Table of Contents
- 🌟 Overview
- 🎯 Key Contributions
- 🚀 Performance Highlights
- 📦 Installation
- 🐳 Run with Docker
- ⚡ Quick Start
- 🧠 Cross-Session Memory
- 🔌 MCP Server
- 📊 Evaluation
- 📝 Citation
- 📄 License
- 🙏 Acknowledgments
🌟 Overview
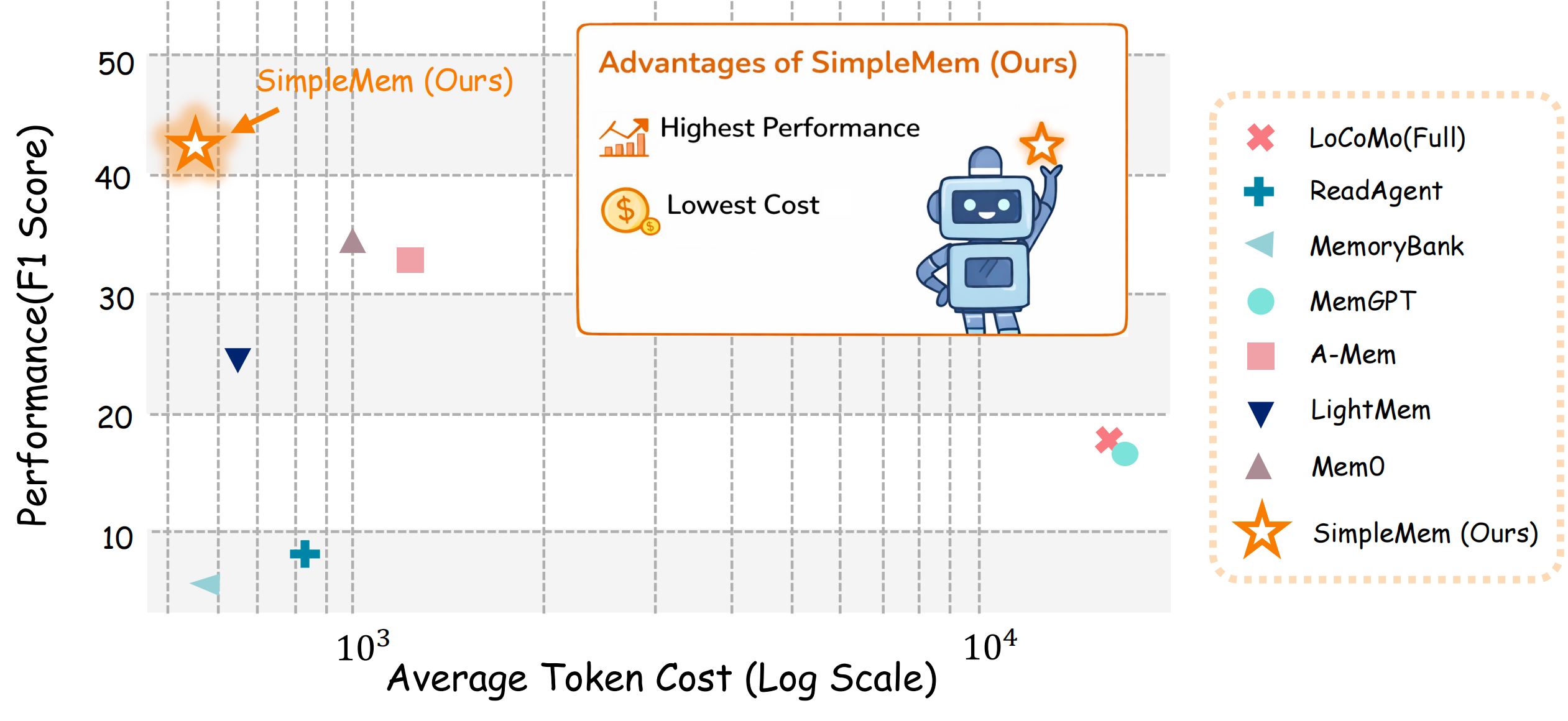
SimpleMem achieves superior F1 score (43.24%) with minimal token cost (~550), occupying the ideal top-left position.
SimpleMem is an efficient memory framework based on semantic lossless compression that addresses the fundamental challenge of efficient long-term memory for LLM agents. Unlike existing systems that either passively accumulate redundant context or rely on expensive iterative reasoning loops, SimpleMem maximizes information density and token utilization through a three-stage pipeline:
🔍 Stage 1Semantic Structured Compression Distills unstructured interactions into compact, multi-view indexed memory units |
🗂️ Stage 2Online Semantic Synthesis Intra-session process that instantly integrates related context into unified abstract representations to eliminate redundancy |
🎯 Stage 3Intent-Aware Retrieval Planning Infers search intent to dynamically determine retrieval scope and construct precise context efficiently |
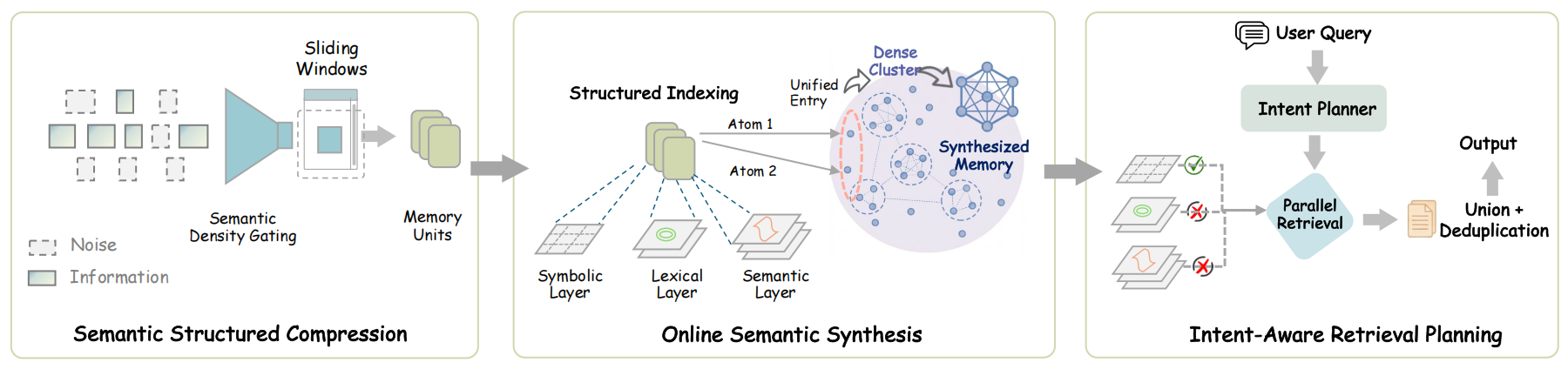
The SimpleMem Architecture: (1) Semantic Structured Compression filters low-utility dialogue and converts informative windows into compact, context-independent memory units. (2) Online Semantic Synthesis consolidates related fragments during writing, maintaining a compact and coherent memory topology. (3) Intent-Aware Retrieval Planning infers search intent to adapt retrieval scope and query forms, enabling parallel multi-view retrieval and token-efficient context construction.
🏆 Performance Comparison
Speed Comparison Demo
SimpleMem vs. Baseline: Real-time speed comparison demonstration
LoCoMo-10 Benchmark Results (GPT-4.1-mini)
| Model | ⏱️ Construction Time | 🔎 Retrieval Time | ⚡ Total Time | 🎯 Average F1 |
|---|---|---|---|---|
| A-Mem | 5140.5s | 796.7s | 5937.2s | 32.58% |
| LightMem | 97.8s | 577.1s | 675.9s | 24.63% |
| Mem0 | 1350.9s | 583.4s | 1934.3s | 34.20% |
| SimpleMem ⭐ | 92.6s | 388.3s | 480.9s | 43.24% |
💡 Key Advantages:
- 🏆 Highest F1 Score: 43.24% (+26.4% vs. Mem0, +75.6% vs. LightMem)
- ⚡ Fastest Retrieval: 388.3s (32.7% faster than LightMem, 51.3% faster than Mem0)
- 🚀 Fastest End-to-End: 480.9s total processing time (12.5× faster than A-Mem)
🎯 Key Contributions
1️⃣ Semantic Structured Compression
SimpleMem applies an implicit semantic density gating mechanism integrated into the LLM generation process to filter redundant interaction content. The system reformulates raw dialogue streams into compact memory units — self-contained facts with resolved coreferences and absolute timestamps. Each unit is indexed through three complementary representations for flexible retrieval:
| 🔍 Layer | 📊 Type | 🎯 Purpose | 🛠️ Implementation |
|---|---|---|---|
| Semantic | Dense | Conceptual similarity | Vector embeddings (1024-d) |
| Lexical | Sparse | Exact term matching | BM25-style keyword index |
| Symbolic | Metadata | Structured filtering | Timestamps, entities, persons |
✨ Example Transformation:
- Input: "He'll meet Bob tomorrow at 2pm" [❌ relative, ambiguous]
+ Output: "Alice will meet Bob at Starbucks on 2025-11-16T14:00:00" [✅ absolute, atomic]
2️⃣ Online Semantic Synthesis
Unlike traditional systems that rely on asynchronous background maintenance, SimpleMem performs synthesis on-the-fly during the write phase. Related memory units are synthesized into higher-level abstract representations within the current session scope, allowing repetitive or structurally similar experiences to be denoised and compressed immediately.
✨ Example Synthesis:
- Fragment 1: "User wants coffee"
- Fragment 2: "User prefers oat milk"
- Fragment 3: "User likes it hot"
+ Consolidated: "User prefers hot coffee with oat milk"
This proactive synthesis ensures the memory topology remains compact and free of redundant fragmentation.
3️⃣ Intent-Aware Retrieval Planning
Instead of fixed-depth retrieval, SimpleMem leverages the reasoning capabilities of the LLM to generate a comprehensive retrieval plan. Given a query, the planning module infers latent search intent to dynamically determine retrieval scope and depth:
$${ q_{\text{sem}}, q_{\text{lex}}, q_{\text{sym}}, d } \sim \mathcal{P}(q, H)$$
The system then executes parallel multi-view retrieval across semantic, lexical, and symbolic indexes, and merges results through ID-based deduplication:
|
🔹 Simple Queries
|
🔸 Complex Queries
|
📈 Result: 43.24% F1 score with 30× fewer tokens than full-context methods.
🚀 Performance Highlights
📊 Benchmark Results (LoCoMo)
🏆 Cross-Session Memory Comparison| System | LoCoMo Score | vs SimpleMem |
|---|---|---|
| SimpleMem | 48 | — |
| Claude-Mem | 29.3 | +64% |
| Task Type | SimpleMem F1 | Mem0 F1 | Improvement |
|---|---|---|---|
| MultiHop | 43.46% | 30.14% | +43.8% |
| Temporal | 58.62% | 48.91% | +19.9% |
| SingleHop | 51.12% | 41.3% | +23.8% |
| Metric | SimpleMem | Mem0 | Notes |
|---|---|---|---|
| Average F1 | 25.23% | 23.77% | Competitive with 99× smaller model |
📦 Installation
📝 Notes for First-Time Users
- Ensure you are using Python 3.10 in your active environment, not just installed globally.
- An OpenAI-compatible API key must be configured before running any memory construction or retrieval, otherwise initialization may fail.
- When using non-OpenAI providers (e.g., Qwen or Azure OpenAI), verify both the model name and
OPENAI_BASE_URLinconfig.py. - For large dialogue datasets, enabling parallel processing can significantly reduce memory construction time.
📋 Requirements
- 🐍 Python 3.10
- 🔑 OpenAI-compatible API (OpenAI, Qwen, Azure OpenAI, etc.)
🛠️ Setup
# 📥 Clone repository
git clone https://github.com/aiming-lab/SimpleMem.git
cd SimpleMem
# 📦 Install dependencies
pip install -r requirements.txt
# ⚙️ Configure API settings
cp config.py.example config.py
# Edit config.py with your API key and preferences
⚙️ Configuration Example
# config.py
OPENAI_API_KEY = "your-api-key"
OPENAI_BASE_URL = None # or custom endpoint for Qwen/Azure
LLM_MODEL = "gpt-4.1-mini"
EMBEDDING_MODEL = "Qwen/Qwen3-Embedding-0.6B" # State-of-the-art retrieval
🐳 Run with Docker
The MCP Server can be run in Docker for a consistent, isolated environment. Data (LanceDB and user DB) is persisted in a host volume.
Prerequisites
- Docker and Docker Compose
Quick run
# From the repository root
docker compose up -d
- Web UI: http://localhost:8000/
- REST API: http://localhost:8000/api/
- MCP (SSE): http://localhost:8000/mcp/sse?token=<TOKEN>
Data is stored in ./data on the host (created automatically).
Custom configuration
- Copy the environment template and edit it:
cp .env.example .env # Edit .env: set JWT_SECRET_KEY, ENCRYPTION_KEY, LLM_PROVIDER, model URLs, etc. - Run with the env file:
docker compose --env-file .env up -d
Using Ollama on the host
When LLM_PROVIDER=ollama and Ollama runs on your machine (not in Docker), set in .env:
LLM_PROVIDER=ollama
OLLAMA_BASE_URL=http://host.docker.internal:11434/v1
On Linux, host.docker.internal is enabled automatically via the Compose file.
Useful commands
docker compose logs -f simplemem # Follow logs
docker compose down # Stop and remove containers
📖 For self-hosting the MCP server (Docker or bare metal), see MCP Documentation.
⚡ Quick Start
🧠 Understanding the Basic Workflow
At a high level, SimpleMem works as a long-term memory system for LLM-based agents. The workflow consists of three simple steps:
- Store information – Dialogues or facts are processed and converted into structured, atomic memories.
- Index memory – Stored memories are organized using semantic embeddings and structured metadata.
- Retrieve relevant memory – When a query is made, SimpleMem retrieves the most relevant stored information based on meaning rather than keywords.
This design allows LLM agents to maintain context, recall past information efficiently, and avoid repeatedly processing redundant history.
🎓 Basic Usage
from main import SimpleMemSystem
# 🚀 Initialize system
system = SimpleMemSystem(clear_db=True)
# 💬 Add dialogues (Stage 1: Semantic Structured Compression)
system.add_dialogue("Alice", "Bob, let's meet at Starbucks tomorrow at 2pm", "2025-11-15T14:30:00")
system.add_dialogue("Bob", "Sure, I'll bring the market analysis report", "2025-11-15T14:31:00")
# ✅ Finalize atomic encoding
system.finalize()
# 🔎 Query with intent-aware retrieval (Stage 3: Intent-Aware Retrieval Planning)
answer = system.ask("When and where will Alice and Bob meet?")
print(answer)
# Output: "16 November 2025 at 2:00 PM at Starbucks"
🚄 Advanced: Parallel Processing
For large-scale dialogue processing, enable parallel mode:
system = SimpleMemSystem(
clear_db=True,
enable_parallel_processing=True, # ⚡ Parallel memory building
max_parallel_workers=8,
enable_parallel_retrieval=True, # 🔍 Parallel query execution
max_retrieval_workers=4
)
💡 Pro Tip: Parallel processing significantly reduces latency for batch operations!
❓ Common Setup Issues & Troubleshooting
If you encounter issues while setting up or running SimpleMem for the first time, check the following common cases:
1️⃣ API Key Not Detected
- Ensure your API key is correctly set in
config.py - For OpenAI-compatible providers (Qwen, Azure, etc.), verify that
OPENAI_BASE_URLis configured correctly - Restart your Python environment after updating the key
2️⃣ Python Version Mismatch
- SimpleMem requires Python 3.10
- Check your version using:
python --version
🧠 Cross-Session Memory
SimpleMem-Cross extends SimpleMem with persistent cross-conversation memory capabilities. Agents can recall context, decisions, and observations from previous sessions — enabling continuity across conversations without manual context re-injection.
Key Features
| Feature | Description |
|---|---|
| Session Lifecycle | Full session management with start/record/stop/end lifecycle |
| Automatic Context Injection | Token-budgeted context from previous sessions injected at session start |
| Event Collection | Record messages, tool uses, file changes with automatic redaction |
| Observation Extraction | Heuristic extraction of decisions, discoveries, and learnings |
| Provenance Tracking | Every memory entry links back to source evidence |
| Consolidation | Decay, merge, and prune old memories to maintain quality |
Quick Example
from cross.orchestrator import create_orchestrator
async def main():
orch = create_orchestrator(project="my-project")
# Start session — previous context is injected automatically
result = await orch.start_session(
content_session_id="session-001",
user_prompt="Continue building the REST API",
)
print(result["context"]) # Relevant context from previous sessions
# Record events during the session
await orch.record_message(result["memory_session_id"], "User asked about JWT")
await orch.record_tool_use(
result["memory_session_id"],
tool_name="read_file",
tool_input="auth/jwt.py",
tool_output="class JWTHandler: ...",
)
# Finalize — extracts observations, generates summary, stores memories
report = await orch.stop_session(result["memory_session_id"])
print(f"Stored {report.entries_stored} memory entries")
await orch.end_session(result["memory_session_id"])
orch.close()
Architecture
Agent Frameworks (Claude Code / Cursor / custom)
|
+--------------+--------------+
| |
Hook/Lifecycle Adapter HTTP/MCP API (FastAPI)
| |
+--------------+--------------+
|
CrossMemOrchestrator
|
+-----------------+------------------+
| | |
Session Manager Context Injector Consolidation
(SQLite) (budgeted bundle) (decay/merge/prune)
| | |
+---------+-------+ |
| |
Cross-Session Vector Store (LanceDB) <--+
Module Reference
| Module | Description |
|---|---|
cross/types.py |
Pydantic models, enums, records |
cross/storage_sqlite.py |
SQLite backend for sessions, events, observations |
cross/storage_lancedb.py |
LanceDB vector store with provenance |
cross/hooks.py |
Lifecycle hooks (SessionStart/ToolUse/End) |
cross/collectors.py |
Event collection with 3-tier redaction |
cross/session_manager.py |
Full session lifecycle orchestration |
cross/context_injector.py |
Token-budgeted context builder |
cross/orchestrator.py |
Top-level facade and factory |
cross/api_http.py |
FastAPI REST endpoints |
cross/api_mcp.py |
MCP tool definitions |
cross/consolidation.py |
Memory maintenance worker |
📖 For detailed API documentation, see Cross-Session README
🔌 MCP Server
SimpleMem is available as a cloud-hosted memory service via the Model Context Protocol (MCP), enabling seamless integration with AI assistants like Claude Desktop, Cursor, and other MCP-compatible clients.
🌐 Cloud Service: mcp.simplemem.cloud — or self-host the MCP server locally using Docker.
Key Features
| Feature | Description |
|---|---|
| Streamable HTTP | MCP 2025-03-26 protocol with JSON-RPC 2.0 |
| Multi-tenant Isolation | Per-user data tables with token authentication |
| Hybrid Retrieval | Semantic search + keyword matching + metadata filtering |
| Production Optimized | Faster response times with OpenRouter integration |
Quick Configuration
{
"mcpServers": {
"simplemem": {
"url": "https://mcp.simplemem.cloud/mcp",
"headers": {
"Authorization": "Bearer YOUR_TOKEN"
}
}
}
}
📖 For detailed setup instructions and self-hosting guide, see MCP Documentation
📊 Evaluation
🧪 Run Benchmark Tests
# 🎯 Full LoCoMo benchmark
python test_locomo10.py
# 📉 Subset evaluation (5 samples)
python test_locomo10.py --num-samples 5
# 💾 Custom output file
python test_locomo10.py --result-file my_results.json
🔬 Reproduce Paper Results
Use the exact configurations in config.py:
- 🚀 High-capability: GPT-4.1-mini, Qwen3-Plus
- ⚙️ Efficient: Qwen2.5-1.5B, Qwen2.5-3B
- 🔍 Embedding: Qwen3-Embedding-0.6B (1024-d)
📝 Citation
If you use SimpleMem in your research, please cite:
@article{simplemem2025,
title={SimpleMem: Efficient Lifelong Memory for LLM Agents},
author={Liu, Jiaqi and Su, Yaofeng and Xia, Peng and Zhou, Yiyang and Han, Siwei and Zheng, Zeyu and Xie, Cihang and Ding, Mingyu and Yao, Huaxiu},
journal={arXiv preprint arXiv:2601.02553},
year={2025},
url={https://github.com/aiming-lab/SimpleMem}
}
📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
🙏 Acknowledgments
We would like to thank the following projects and teams:
- 🔍 Embedding Model: Qwen3-Embedding - State-of-the-art retrieval performance
- 🗄️ Vector Database: LanceDB - High-performance columnar storage
- 📊 Benchmark: LoCoMo - Long-context memory evaluation framework
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi