cognirepo
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool provides local cognitive infrastructure for AI coding agents. It creates a persistent semantic memory, knowledge graph, and repository intelligence layer to reduce token usage and help AI tools remember context across sessions.
Security Assessment
The light code audit scanned 12 files and found no dangerous patterns, hardcoded secrets, or dangerous permission requests. The tool operates entirely locally, leveraging a FAISS vector store and a local AST index to analyze codebases without requiring external API keys. However, it does profile user behavior and track session history, which means it collects and stores data about your coding habits and conversations locally. No shell command executions or suspicious network requests were detected. Overall risk is rated as Low.
Quality Assessment
The project is very new and has low community visibility, currently sitting at only 6 GitHub stars. Despite this low traction, the repository is under active development with a very recent last push and is properly licensed under the permissive MIT license. The inclusion of automated CI and security workflows indicates good baseline coding standards and ongoing maintenance effort from the creator.
Verdict
Safe to use, though you should expect an early-stage project with limited community validation.
Local cognitive infrastructure for AI coding agents — semantic memory, repository intelligence, and MCP tools to reduce token usage.
CogniRepo
Persistent memory and context for any AI tool. Not a chatbot — infrastructure.
![]()
![]()
![]()
![]()
![]()
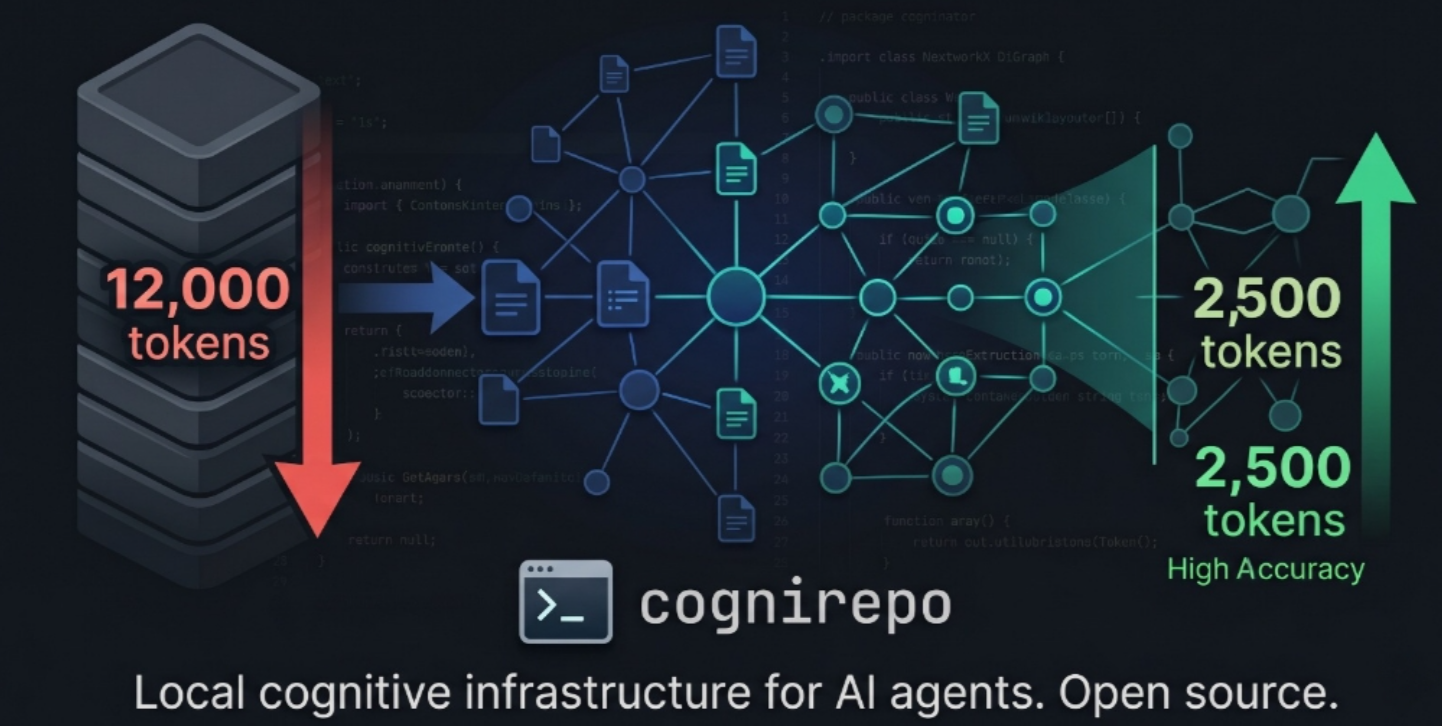
What it does
Every AI conversation starts from zero. Claude, Cursor, Gemini — none of them remember
what you fixed yesterday, which files relate to which features, or what decisions were made
last sprint. CogniRepo fixes that.
It sits between your codebase and any AI tool, providing:
- Semantic memory — FAISS vector store with sentence-transformer embeddings. Store
decisions, docs, architecture notes. Retrieve them with natural language. - Episodic log — append-only event journal. Know what happened before that error.
- Knowledge graph — NetworkX DiGraph linking functions, classes, files, imports,
inheritance chains, call relationships, and concepts. All queryable. - AST reverse index — O(1) symbol lookup across your entire codebase in any supported language.
- User behavior profiling — tracks how you prompt so Claude adapts its response
style without you having to re-explain preferences every session. - Error tracking — records errors with prevention hints so Claude avoids
repeating the same mistake across sessions. - Session history — persists conversation exchanges so any session can resume
where the last one ended. - Architectural summaries — auto-generated on first init; built entirely from
the local AST index (no API key needed). File → directory → repo summary tree,
embedded into FAISS for semantic search. - Multi-model orchestration — classify query complexity → build context → route to the
right model. Claude for deep reasoning, Gemini Flash for quick lookups. All automatic.
Every AI tool that connects gets the same accumulated project knowledge. Memory persists
across sessions, across tools, across time.
Why it helps — measured numbers
Benchmarked across 6 real open-source repos (FastAPI, Flask, Celery, Ansible, Moby/Docker, Kubernetes) using 30 structured prompts tested against Claude, Gemini, and Cursor/Codex.
| Metric | Value | Notes |
|---|---|---|
| Token reduction — Python repos | 50–84% | FastAPI FA-2: 12 000 → 2 500 · FA-4: 2 000 → 450 · FL-4: 8 000 → 1 250 |
| Token reduction — average (all tested) | ~60% | Across FA/FL/CE/AN where both baselines were captured |
| Token reduction — complex dynamic codebases | 20–35% | Celery CE-4/CE-5; deep async/dynamic-dispatch patterns reduce gains |
| Symbol lookup latency | < 1 ms | vs. grep at 2–8 s on large repos |
| Accuracy vs. baseline | equal or better in 100% of tests | No regression observed; FA-2 accuracy improved Moderate → High |
| Cross-agent context handoff | ✅ validated | CE-4: Claude primed index, Gemini CLI consumed it — 35% token saving, same accuracy |
| Dynamic dispatch coverage | honest gap | CE-3 (APScheduler beat dispatch) returned NA for both; CogniRepo does not fabricate call chains |
| Go/multi-language coverage | partial | Moby MO-2 showed 67% savings; MO-3-5 / K8-* incomplete pending Go grammar improvements |
Honest limits: CogniRepo adds the most value on Python repos with clear static structure.
Dynamic dispatch patterns (Celery beat, plugin registries), deep Go codebases, and Ansible's
22-level variable precedence chains reduce retrieval confidence. The tool reports uncertainty
rather than hallucinating call chains.
Run cognirepo benchmark on your own codebase to reproduce. See docs/METRICS.md.
How it works
User / AI Tool
│
├── MCP stdio (Claude Desktop, Gemini CLI, Cursor)
│
tools/ ← single entry point to memory engine
│
┌─────────┼─────────────────────────────────────┐
▼ ▼ ▼
memory/ retrieval/hybrid.py graph/knowledge_graph.py
FAISS 3-signal merge: NetworkX DiGraph
episodic vector + graph + behaviour 7 node types:
embeddings FILE, FUNCTION, CLASS,
indexer/ast_indexer.py CONCEPT, QUERY, SESSION,
tree-sitter multi-language ERROR
+ stdlib ast fallback 9 edge types:
CALLS, CALLED_BY,
graph/behaviour_tracker.py DEFINED_IN, CO_OCCURS,
per-symbol hit counts IMPORTS, INHERITS,
user behavior profile SIMILAR_TO, RELATES_TO,
error pattern tracking QUERIED_WITH
session history
│
.cognirepo/ (Fernet encrypted if storage.encrypt: true)
Quick start
Requirements
- Python 3.11+
- API key (optional — only needed for
cognirepo ask):ANTHROPIC_API_KEY,GEMINI_API_KEY,OPENAI_API_KEY, orGROK_API_KEY.
Indexing, memory, summarization, and all MCP tools work fully offline.
Install
pip install cognirepo
# For multi-language indexing (JS, TS, Java, Go, Rust, C++):
pip install cognirepo[languages]
# For encryption at rest:
pip install cognirepo[security]
Run
# Interactive wizard — asks about encryption, languages, Claude/Gemini/Cursor MCP, org:
cognirepo init
# → automatically indexes the repo after setup
# → prompts to generate architectural summaries (requires LLM API key)
# Non-interactive (CI / scripting):
cognirepo init --no-index
# INDEX FIRST — MCP tools return nothing until this runs:
cognirepo index-repo . # index your codebase (required before MCP tools work)
cognirepo index-repo . --daemon # index and run watcher in background
# Check everything is working:
cognirepo status # shows symbol count, graph nodes, signal warmth
cognirepo doctor # full health check
# Query through multi-model orchestrator:
cognirepo ask "why is auth slow?"
# Manage background watchers:
cognirepo list # show all running watcher daemons
cognirepo list -n <PID> --view # tail the log of a specific watcher
cognirepo list -n <PID> --stop # stop a watcher
First-time setup:
cognirepo init+cognirepo index-repo .must complete before
MCP tools (context_pack,lookup_symbol,who_calls, etc.) return data.
Connect your AI tools
Claude Code / Claude Desktop (recommended — project-scoped)
Run cognirepo init inside your project — it asks if you want to configure Claude and
automatically writes .claude/CLAUDE.md and .claude/settings.json with the correct
project-locked connector.
Each project gets its own isolated connector named cognirepo-<project>:
{
"mcpServers": {
"cognirepo-myproject": {
"command": "cognirepo",
"args": ["serve", "--project-dir", "/abs/path/to/myproject"],
"env": {}
}
}
}
The --project-dir flag locks the MCP server to that project's .cognirepo/ directory.
When Claude has multiple projects open simultaneously, each connector reads only its own
memories — never mixing data across projects or teams.
Cursor / Copilot
cognirepo export-spec
cp adapters/cursor_mcp_config.json .cursor/mcp.json
# Restart Cursor — CogniRepo tools appear in the tool selector
Docker
cp .env.example .env # add your API keys
docker compose up mcp # MCP stdio server
MCP Tools — complete reference
All 22 tools are available to Claude, Cursor, and any MCP-compatible client.
Core retrieval
| Tool | Description | When to use |
|---|---|---|
context_pack(query, max_tokens=2000) |
Token-budget code + memory context | Every session — FIRST call before any file read |
lookup_symbol(name) |
O(1) symbol lookup → file + line | Before grepping for a function |
who_calls(function_name) |
Trace callers + dynamic dispatch fallback | Impact analysis, refactoring |
search_token(word) |
Word-level reverse index across names, docs, comments | Finding where a concept lives |
retrieve_memory(query, top_k=5) |
Semantic similarity search over stored memories | Before answering — pull past context |
search_docs(query) |
Full-text search in all .md files |
Documentation lookups |
semantic_search_code(query, language=None) |
Vector search over code symbols only | Code-specific semantic queries |
subgraph(entity, depth=2) |
Local knowledge graph neighbourhood | Understand symbol relationships |
graph_stats() |
Node/edge count and graph health | Check if graph has data |
episodic_search(query, limit=10) |
BM25 keyword search in event history | Find past decisions or incidents |
dependency_graph(module, direction="both") |
Import/dependency relationships | Module coupling analysis |
explain_change(target, since="7d") |
What changed in a file/function + git cross-ref | Understanding recent changes |
architecture_overview(scope="root") |
Pre-computed LLM architectural summaries | Big-picture questions |
User & session intelligence
| Tool | Description | When to use |
|---|---|---|
get_user_profile() |
User's interaction style: depth pref, question types, vocabulary | Call at session start — calibrates Claude's response style |
get_session_history(limit=10) |
Recent conversation exchanges across sessions | Resuming context from prior sessions |
Error tracking & prevention
| Tool | Description | When to use |
|---|---|---|
get_error_patterns(min_count=1) |
Recurring errors with prevention hints | Before proposing a fix — check if it has failed before |
record_error(error_type, message, file_path, query_context) |
Log an error for future avoidance | After any error Claude or user encounters |
Memory & storage
| Tool | Description | When to use |
|---|---|---|
store_memory(text, source="") |
Persist a memory to the FAISS index | After solving bugs, recording decisions |
log_episode(event, metadata={}) |
Append event to episodic journal | Track milestones, incidents, deployments |
Cross-repo (organization)
| Tool | Description | When to use |
|---|---|---|
org_search(query) |
Search memories across all org repos | Multi-repo context queries |
cross_repo_search(query, scope="project") |
Project-scoped or org-scoped search | Finding shared components |
list_org_context() |
Org metadata + sibling repos | Understanding repo relationships |
Knowledge graph — what gets indexed
The knowledge graph is significantly richer than a simple call graph.
Node types
| Type | Description |
|---|---|
FILE |
Every indexed source file |
FUNCTION |
Function and method definitions with docstrings |
CLASS |
Class definitions with base classes |
CONCEPT |
Semantic concepts extracted from docstrings and identifiers |
QUERY |
Recorded query nodes (for retrieval scoring) |
SESSION |
Conversation session nodes |
ERROR |
Recurring error pattern nodes |
MEMORY |
Cross-agent memory nodes (synced from Claude/Gemini) |
Edge types
| Type | Direction | Description |
|---|---|---|
DEFINED_IN |
symbol → file | Symbol lives in this file |
CALLS / CALLED_BY |
bidirectional | Function call relationships with purpose labels |
IMPORTS |
file → file | Python import dependencies |
INHERITS |
class → parent | Inheritance hierarchy |
CO_OCCURS |
file ↔ file | Files edited together (behavioural co-edit signal) |
RELATES_TO |
concept → symbol | Semantic concept linkage |
QUERIED_WITH |
query → symbol | Retrieval tracking for scoring |
SIMILAR_TO |
symbol ↔ symbol | Semantically similar symbols |
IMPORTS and INHERITS edges are built automatically during index-repo from Python AST.
Use subgraph("MyClass", depth=2) or dependency_graph("mymodule") to query them.
User behavior profiling
CogniRepo tracks how you interact across sessions and builds a profile that Claude uses to
calibrate its responses — without you having to repeat preferences every session.
What gets tracked
- Depth preference — inferred from average query length:
concise/medium/detailed - Question types — distribution across:
why,what,how,fix,explain,where,refactor,add - Domain vocabulary — top terms that appear frequently in your queries
- Code focus — percentage of queries referencing code identifiers (symbols, functions)
- Sample queries — last 3 queries for Claude to infer framing style
Accessing your profile
# MCP tool (Claude calls automatically at session start):
get_user_profile()
# CLI:
cognirepo user-prefs
Example profile output
{
"depth_preference": "detailed",
"top_question_type": "how",
"question_type_distribution": {"how": 12, "why": 8, "fix": 5},
"top_terminology": ["auth", "token", "session", "middleware", "validate"],
"code_focus_percent": 73,
"framing_hints": "prefers detailed responses; often asks 'how' questions; domain vocabulary: auth, token, session",
"total_queries_tracked": 47
}
Claude receives framing_hints at session start and adjusts response length, code density,
and terminology accordingly. The profile accumulates over time — more accurate the more you use it.
Error tracking & prevention
CogniRepo logs every error that occurs during sessions — whether it's a Python exception,
a failed build step, or a tool call that went wrong. Errors are stored with:
- Dedup signature — prevents the same error from inflating the count
- Prevention hint — a targeted suggestion to avoid the same error class
- Occurrence context — last 5 occurrences with file path and error message
- Query context — the query or action that triggered the error
Logging errors
# MCP tool (Claude calls after errors):
record_error("TypeError", "expected str got int", "config/parser.py", "fix config loading")
Viewing error patterns
# MCP tool:
get_error_patterns()
Returns:
[
{
"error_type": "TypeError",
"count": 7,
"files": ["config/parser.py", "api/handlers.py"],
"last_seen": "2026-04-22T10:30:00Z",
"prevention_hint": "Wrong type — validate inputs at function boundary.",
"recent_context": "expected str got int in parse_config"
}
]
Built-in prevention hints
| Error class | Prevention hint |
|---|---|
NameError |
Undefined variable — check imports and scope before use |
ImportError |
Import failed — verify package is installed and module path is correct |
AttributeError |
Object missing attribute — check type, None-guard, or spelling |
TypeError |
Wrong type — validate inputs at function boundary |
KeyError |
Missing dict key — use .get() with default or check existence first |
IndexError |
List out of range — guard with len() check before access |
OSError |
File/IO error — always guard file ops with try/except OSError |
SyntaxError |
Syntax error — run a linter before committing |
Timeout |
Timeout — add explicit timeout parameter and retry logic |
AssertionError |
Assertion failed — review invariants; do not use assert in prod |
Session history
Every cognirepo ask exchange is persisted to .cognirepo/sessions/.
Sessions are indexed by UUID and retrievable via:
# List recent sessions:
cognirepo sessions
# MCP tool — Claude calls at session start to resume context:
get_session_history(limit=5)
Each entry returns: session ID, created timestamp, message count, model used, and
the last user/assistant exchange for quick context scan.
Architectural summaries
cognirepo init automatically prompts to run cognirepo summarize after the first index.
This produces a 3-level LLM summary of the entire codebase:
- Level 1 — repo-wide summary (what the project does, key modules, entry points)
- Level 2 — per-directory summaries (what each package is responsible for)
- Level 3 — per-file summaries (what each file contains, key functions/classes)
Summaries are stored in .cognirepo/index/summaries.json and served via thearchitecture_overview MCP tool — zero token cost for Claude to understand the big picture.
# Auto-prompted on first init. Run manually anytime:
cognirepo summarize
# Fully local — no API key required. Reads from ast_index.json, runs in < 1 second.
# File summaries are also embedded into FAISS for semantic architecture queries.
Multi-model orchestration
cognirepo ask automatically picks the right model for each query:
| Tier | Score | Default model | Use case |
|---|---|---|---|
| QUICK | ≤2 | local resolver | Single-token / trivial — zero API, fastest path |
| STANDARD | ≤4 | Haiku | Quick lookup, factual, single symbol |
| COMPLEX | ≤9 | Sonnet | Moderate reasoning |
| EXPERT | >9 | Opus | Cross-file, architectural, ambiguous — full context, best model |
cognirepo ask "where is verify_token defined?" # → QUICK, answered locally
cognirepo ask "why is auth slow?" # → EXPERT, Claude with full context
cognirepo ask --verbose "explain the circuit breaker" # show tier/score/signals
Provider fallback chain: Grok → Gemini → Anthropic → OpenAI.
All errors are logged to .cognirepo/errors/<date>.log — no raw tracebacks shown to users.
Language support
| Language | Extensions | Install |
|---|---|---|
| Python | .py |
built-in |
| JavaScript / TypeScript | .js .ts .jsx .tsx |
cognirepo[languages] |
| Java | .java |
cognirepo[languages] |
| Go | .go |
cognirepo[languages] |
| Rust | .rs |
cognirepo[languages] |
| C / C++ | .c .cpp .h |
cognirepo[languages] |
Full details and roadmap: docs/LANGUAGES.md
Storage layout
.cognirepo/
config.json ← project settings (project_id, model, retrieval weights)
vector_db/
semantic.index ← FAISS flat index for semantic memory
ast.index ← FAISS IndexIDMap2 for code symbols
ast_metadata.json ← parallel metadata for ast.index rows
graph/
graph.pkl ← NetworkX DiGraph (optionally Fernet-encrypted)
behaviour.json ← per-symbol hit counts, user profile, error patterns
index/
ast_index.json ← reverse symbol index + file records
manifest.json ← git SHA + platform info for integrity checks
summaries.json ← LLM architectural summaries (Level 1–3)
memory/
episodic.json ← append-only event journal
sessions/
<uuid>.json ← conversation session files
current.json ← pointer to most-recent session
errors/
<date>.log ← daily error logs (full tracebacks, never shown to users)
learnings/
learnings.json ← structured learnings: decisions, bugs, prod issues
Everything under .cognirepo/ is .gitignored by default — never committed.
Fernet encryption is opt-in at storage.encrypt: true in config.json.
CLI reference
# Setup
cognirepo init # scaffold + configure; auto-indexes + auto-summarizes
cognirepo setup-env # interactive API key wizard
cognirepo test-connection # test API key connectivity
cognirepo migrate-config # migrate deprecated config keys
# Indexing
cognirepo index-repo [path] # AST-index a codebase
cognirepo summarize # generate LLM architectural summaries (auto-prompted on init)
cognirepo seed --from-git # seed behaviour weights from git history
cognirepo verify-index # verify AST index integrity
cognirepo coverage # per-directory symbol counts
# Querying
cognirepo ask <query> # route through multi-model orchestrator
cognirepo retrieve-memory <q> # similarity search
cognirepo search-docs <q> # full-text search in .md files
cognirepo log-episode <event> # append episodic event
cognirepo history # print recent episodic events
cognirepo sessions # list recent conversation sessions
# Memory management
cognirepo store-memory <text> # save a semantic memory
cognirepo user-prefs # view/set global user preferences
cognirepo prune [--dry-run] # prune low-score memories
# Health & monitoring
cognirepo prime # generate session bootstrap brief
cognirepo status # live retrieval signal weights + index health
cognirepo doctor [--fix] # full health check; --fix auto-repairs common issues
cognirepo benchmark # run quantitative value benchmarks
# Organization
cognirepo org create <name> # create local organization
cognirepo org link <org> [path] # link repo to organization
cognirepo org list # list organizations
# Daemon management
cognirepo list # list MCP servers, running daemons
cognirepo watch # manage background file-watcher daemon
Future Plans
Priorities drawn from the v0.3.0 benchmark findings and community feedback.
Near-term (v0.3.0)
- Go call-graph indexing — tree-sitter-go grammar is loaded but call extraction is incomplete; Moby/Kubernetes tests (MO-3-5, K8-*) could not be completed without it. Adding Go-aware
who_callsand IMPORTS edges is the single highest-impact unblocked item. cognirepo ask— multi-model orchestrator (QUICK/STANDARD/COMPLEX/EXPERT tiers). Initial implementation stubbed in v0.2.0; orchestrator logic is implemented inorchestrator/and being wired to a working API key flow in v0.3.0.- Incremental re-index on save — file-watcher daemon exists (
cognirepo watch) but re-index on write is not yet debounced correctly; large repos see spurious full re-indexes. - CLAUDE.md mandatory-call relaxation — benchmark feedback (Moby tests) flagged that forcing
context_packbefore every file read adds latency under memory pressure. Will add a--fastmode that skips the tool-first gate for files under 50 lines.
Medium-term (v0.4.0)
- Kubernetes / 2M-LOC scale validation — K8-1 through K8-5 test suite not yet completed. Goal: full scheduling-decision trace at < 8 000 tokens with CogniRepo vs. > 50 000 without.
- Plugin-registry pattern detection — Ansible AN-3/AN-4 (22-level variable precedence, strategy plugins) and Celery CE-3 (dynamic dispatch) returned NA. Plan: static heuristic pass that detects
register,entry_points, and__init_subclass__patterns and annotates them asDYNAMIC_DISPATCHnodes in the graph. - BM25 over symbol names — current keyword search uses exact-word reverse index; adding BM25 TF-IDF ranking over symbol names and docstrings would improve partial-match recall (e.g.
HttpClientmatchinghttp_client). - Cross-session memory warm-up — Ansible benchmark noted episodic/memory retrieval is low-value on fresh sessions.
cognirepo primeexists but is not run automatically oninit; will make it opt-in default.
Longer-term
cognirepo askstreaming REPL — full interactive session with tier routing, session persistence, and sub-agent delegation.- Ruby, PHP, C#, Swift grammar support — tree-sitter grammars exist; need
_TS_FUNCTION_TYPES/_TS_CLASS_TYPESmappings and call-extraction rules per language. - Similarity edges in knowledge graph —
EdgeType.SIMILAR_TOis declared but never populated. Embedding-distance clustering would connect semantically related symbols across files. - VS Code / JetBrains extension — surface
lookup_symbol,context_pack, andwho_callsdirectly in the editor sidebar without requiring an MCP-capable host.
Documentation
| Document | Description |
|---|---|
| docs/ARCHITECTURE.md | System design, component responsibilities, data flow |
| docs/architecture/SPECIFICATION.md | Technical spec, complexity signals, storage layout |
| docs/USAGE.md | Complete CLI, MCP, and Docker reference |
| docs/METRICS.md | Quantitative benchmarks: token reduction, lookup speedup, recall |
| CONTRIBUTING.md | How to add adapters, tools, and language support |
| SECURITY.md | Vulnerability reporting, data handling, trust model |
| docs/LANGUAGES.md | Language support details and roadmap |
License
CogniRepo is licensed under the MIT License.
- Free to use, study, modify, and distribute
- Use in proprietary products and commercial services — no restrictions
- No requirement to open-source your application
See LICENSE for full details.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi