AutoR
Health Uyari
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Gecti
- Code scan — Scanned 9 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool is a terminal-based AI co-pilot that automates long-form research workflows. It drives a fixed 8-stage research pipeline using Claude Code, requires explicit human approval at every stage, and saves all artifacts to a local directory for auditing.
Security Assessment
The light code scan checked 9 files and found no dangerous patterns, hardcoded secrets, or dangerous permission requests. The core design is inherently secure because it enforces a "human-in-the-loop" model, meaning the AI cannot progress to the next stage without manual approval. However, since it integrates with Claude Code to execute research tasks and write files to disk, it inherently handles user prompts and makes network requests to the AI provider's API. Overall risk: Low.
Quality Assessment
The project is actively maintained, with its last repository push occurring today. However, there are two notable drawbacks: it lacks a license file, which creates legal ambiguity and may restrict usage in corporate environments, and it has very low community visibility with only 5 GitHub stars. The code appears cleanly structured based on the README, but the small user base means it has not been broadly battle-tested.
Verdict
Use with caution. The human-in-the-loop design and clean code scan make it functionally secure to try, but the lack of a license and low community adoption mean you should review its legal suitability before integrating it into formal projects.
AutoR takes a research goal, runs a fixed 8-stage pipeline with Claude Code, and requires explicit human approval after every stage before the workflow can continue.
AutoR: Human-Centered AI Research Co-pilot
A terminal-first, file-based research workflow runner for long-form AI-assisted research.
It drives a fixed 8-stage research pipeline, requires human approval after every stage,
and writes every prompt, log, summary, and artifact into an isolated run directory.

Why AutoR · Showcase · Quick Start · How It Works · Run Layout · Architecture · Roadmap
AutoR is not a chat demo, not a generic agent framework, and not a markdown-only research toy.
It is a research execution loop:
goal -> literature -> hypothesis -> design -> implementation -> experiments -> analysis -> paper -> dissemination,
with explicit human control at every stage and real artifacts on disk.
✨ Why AutoR
Most AI research demos stop at "the model wrote a plausible summary."
AutoR is built around a harder standard: the system should leave behind a run directory that another person can inspect, resume, audit, and critique.
What makes it different
| AutoR does | Why it matters |
|---|---|
| Fixed 8-stage research workflow | The system behaves like a real research process instead of a free-form chat loop. |
| Mandatory human approval after every stage | AI executes; humans retain control at high-leverage decision points. |
Full run isolation under runs/<run_id>/ |
Prompts, logs, stage outputs, code, figures, and papers are all auditable. |
| Draft -> validate -> promote for stage summaries | Half-finished summaries do not silently become official stage records. |
| Artifact-aware validation | Later stages must produce data, results, figures, LaTeX, PDF, and review assets, not just prose. |
| Resume and redo-stage support | Long runs are recoverable and partially repeatable. |
| Stage-local conversation continuation | Refinement improves the current stage instead of constantly resetting context. |
| Venue-aware writing stage | Stage 07 can target lightweight conference or journal-style paper packaging without pretending to be a full submission system. |
Core guarantees
- A run is isolated under
runs/<run_id>/. - Claude never writes directly to the final stage summary file.
- Human approval is required before the workflow advances.
- Approved summaries are appended to
memory.md; failed attempts are not. - Stage 03+ must produce machine-readable data artifacts.
- Stage 05+ must produce machine-readable result artifacts.
- Stage 06+ must produce real figure files.
- Stage 07+ must produce a venue-aware manuscript package with a PDF.
- Stage 08+ must produce review and readiness materials.
🌟 Showcase
AutoR already has a full example run used throughout the repository: runs/20260330_101222.
That run produced:
- a compiled paper PDF: example_paper.pdf
- executable research code
- machine-readable datasets and result files
- real figures used in the paper
- review and dissemination materials
Highlighted outcomes from that run:
AGSNv2reached 36.21 ± 1.08 on Actor- the system produced a full NeurIPS-style paper package
- the final run preserved the full human-in-the-loop approval trail
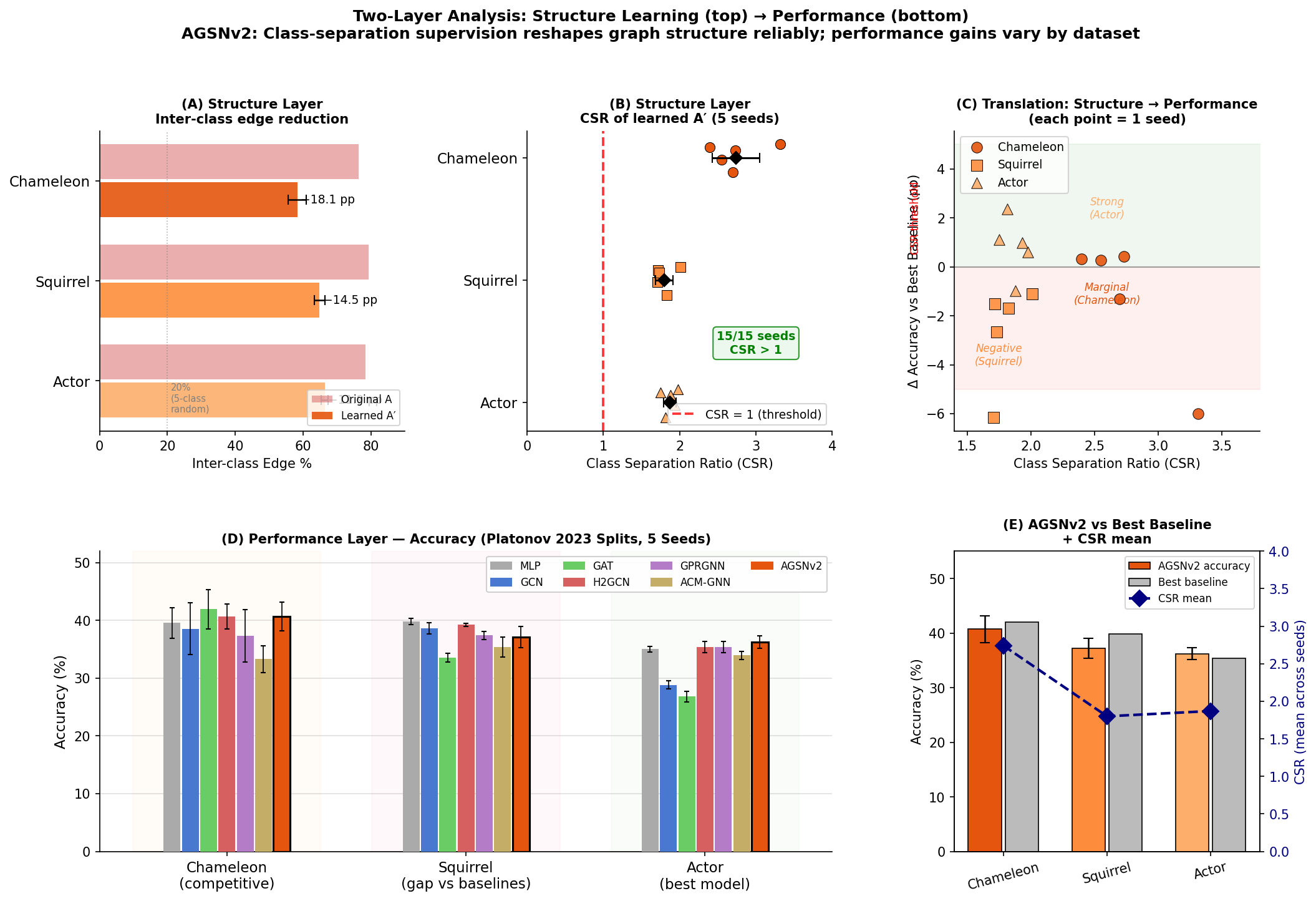
Example Figures
Accuracy Comparison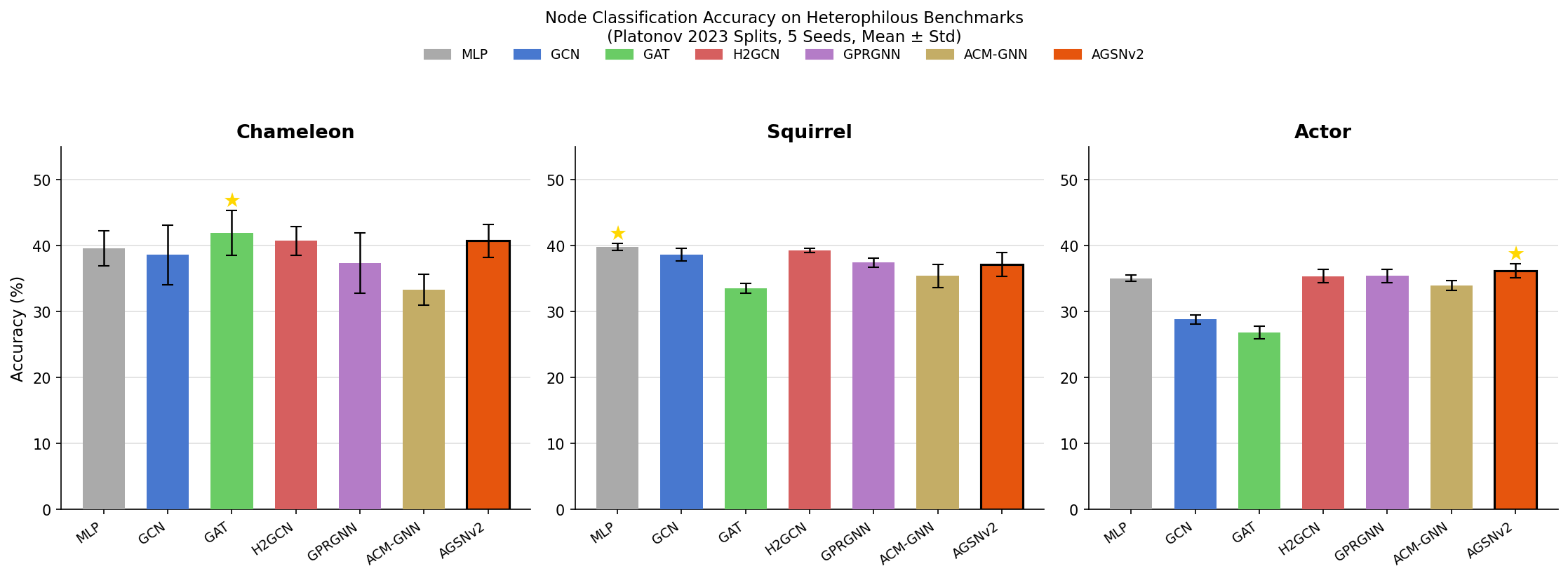
|
Ablation + Actor Results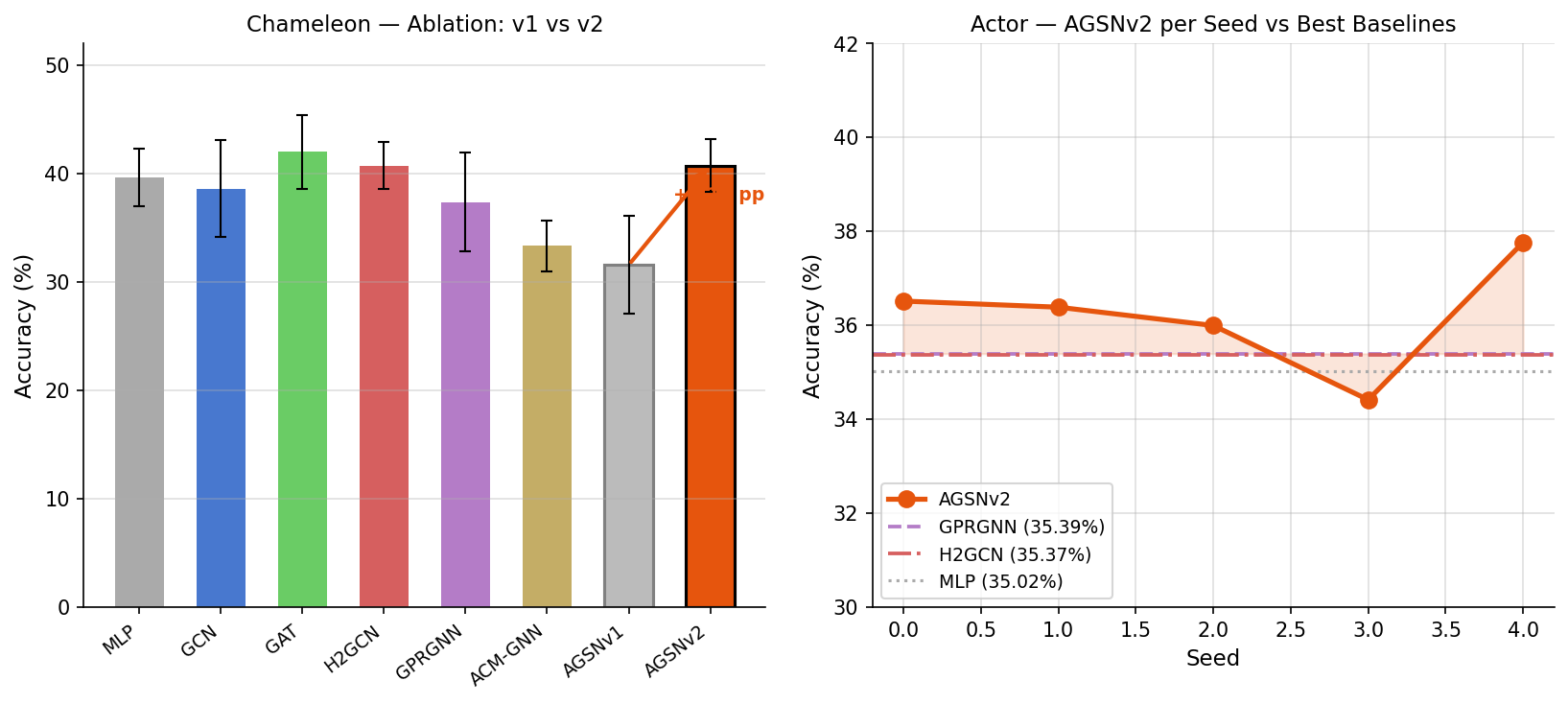
|
|
Two-Layer Narrative Figure
|
Paper Preview
|
Page 1 Title, abstract, framing 
|
Page 5 Method and training algorithm 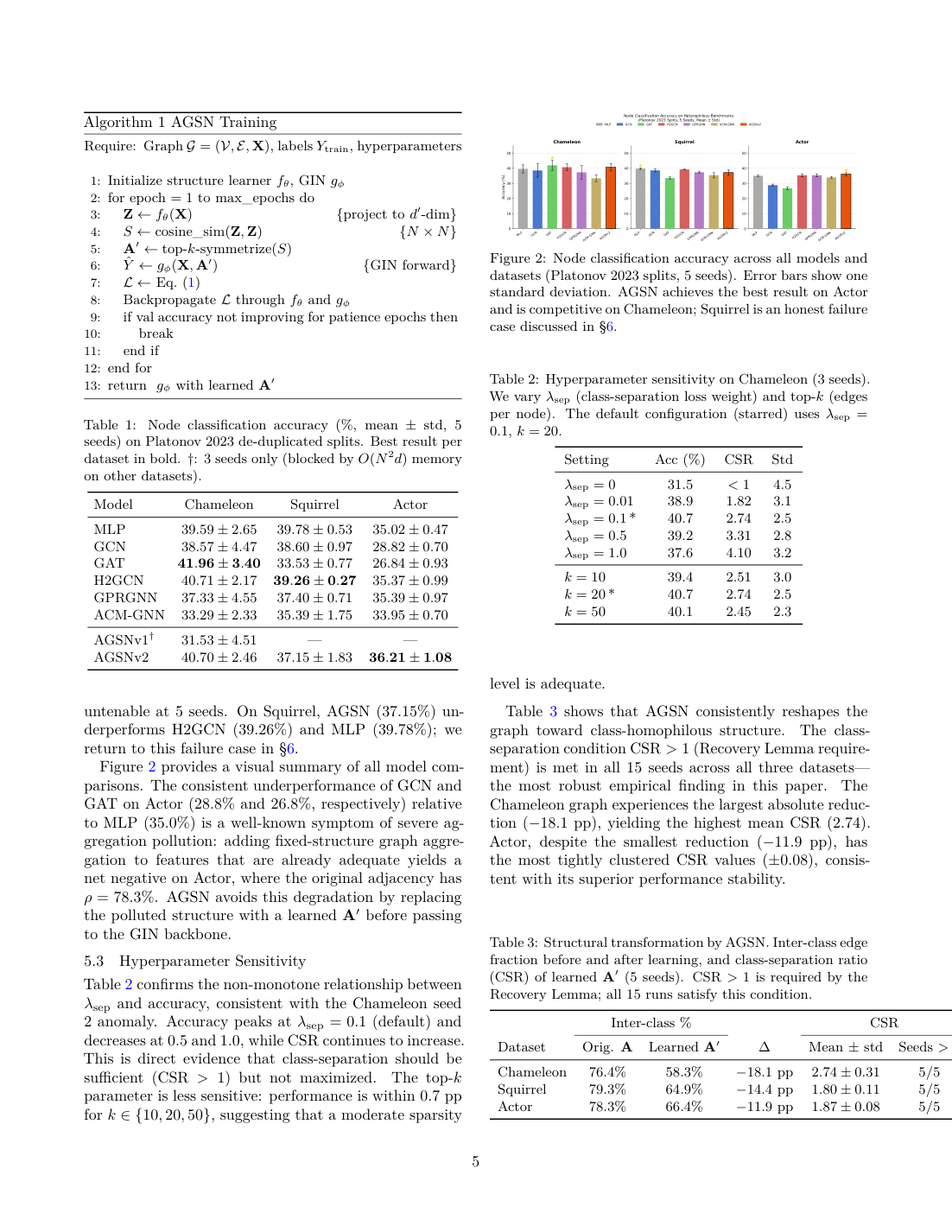
|
Page 7 Main tables and per-seed results 
|
Human-in-the-Loop in Practice
The example run is interesting not because the AI was left alone, but because the human intervened at critical moments:
- Stage 02 narrowed the project to a single core claim.
- Stage 04 pushed the system to download real datasets and run actual pre-checks.
- Stage 05 forced experimentation to continue until real benchmark results were obtained.
- Stage 06 redirected the story away from leaderboard-only framing toward mechanism-driven analysis.
That is the intended shape of AutoR:
AI handles execution load; humans steer the research when direction actually matters.
🚀 Quick Start
Prerequisites
- Python 3.10+
- Claude CLI available on
PATHfor real runs - Local TeX tools are helpful for Stage 07, but not required for smoke tests
Start a new run
python main.py
Start with an explicit goal
python main.py --goal "Your research goal here"
Run a local smoke test without Claude
python main.py --fake-operator --goal "Smoke test"
Choose a Claude model
python main.py --model sonnet
python main.py --model opus
Choose a writing venue profile
python main.py --venue neurips_2025
python main.py --venue nature
python main.py --venue jmlr
If --venue is omitted, AutoR defaults to neurips_2025.
Resume or redo work inside the same run
python main.py --resume-run latest
python main.py --resume-run 20260329_210252 --redo-stage 03
Valid stage identifiers include 03, 3, and 03_study_design.
⚙️ How It Works
AutoR uses a fixed 8-stage pipeline:
01_literature_survey02_hypothesis_generation03_study_design04_implementation05_experimentation06_analysis07_writing08_dissemination
flowchart TD
A[Start or resume run] --> S1[01 Literature Survey]
S1 --> H1{Human approval}
H1 -- Refine --> S1
H1 -- Approve --> S2[02 Hypothesis Generation]
H1 -- Abort --> X[Abort]
S2 --> H2{Human approval}
H2 -- Refine --> S2
H2 -- Approve --> S3[03 Study Design]
H2 -- Abort --> X
S3 --> H3{Human approval}
H3 -- Refine --> S3
H3 -- Approve --> S4[04 Implementation]
H3 -- Abort --> X
S4 --> H4{Human approval}
H4 -- Refine --> S4
H4 -- Approve --> S5[05 Experimentation]
H4 -- Abort --> X
S5 --> H5{Human approval}
H5 -- Refine --> S5
H5 -- Approve --> S6[06 Analysis]
H5 -- Abort --> X
S6 --> H6{Human approval}
H6 -- Refine --> S6
H6 -- Approve --> S7[07 Writing]
H6 -- Abort --> X
S7 --> H7{Human approval}
H7 -- Refine --> S7
H7 -- Approve --> S8[08 Dissemination]
H7 -- Abort --> X
S8 --> H8{Human approval}
H8 -- Refine --> S8
H8 -- Approve --> Z[Run complete]
H8 -- Abort --> X
Stage Attempt Loop
flowchart TD
A[Build prompt from template + goal + memory + optional feedback] --> B[Start or resume stage session]
B --> C[Claude writes draft stage summary]
C --> D[Validate markdown and required artifacts]
D --> E{Valid?}
E -- No --> F[Repair, normalize, or rerun current stage]
F --> A
E -- Yes --> G[Promote draft to final stage summary]
G --> H{Human choice}
H -- 1 or 2 or 3 --> I[Continue current stage conversation with AI refinement]
I --> A
H -- 4 --> J[Continue current stage conversation with custom feedback]
J --> A
H -- 5 --> K[Append approved summary to memory.md]
K --> L[Continue to next stage]
H -- 6 --> X[Abort]
Approval semantics
1 / 2 / 3: continue the same stage conversation using one of the AI's refinement suggestions4: continue the same stage conversation with custom user feedback5: approve and continue to the next stage6: abort the run
The stage loop is controlled by AutoR, not by Claude.
✅ Validation Bar
AutoR does not consider a run successful just because it generated a plausible markdown summary.
| Stage | Required non-toy output |
|---|---|
| Stage 03+ | Machine-readable data under workspace/data/ |
| Stage 05+ | Machine-readable results under workspace/results/ |
| Stage 06+ | Real figure files under workspace/figures/ |
| Stage 07+ | Venue-aware manuscript sources plus a compiled PDF |
| Stage 08+ | Review and readiness assets under workspace/reviews/ |
Required stage summary shape:
# Stage X: <name>
## Objective
## Previously Approved Stage Summaries
## What I Did
## Key Results
## Files Produced
## Suggestions for Refinement
## Your Options
Additional rules:
- exactly 3 numbered refinement suggestions
- the fixed 6 user options
- no
[In progress],[Pending],[TODO],[TBD], or similar placeholders - concrete file paths in
Files Produced
If a run only leaves behind markdown notes, it has not met AutoR's quality bar.
📂 Run Layout
Every run lives entirely inside its own directory.
runs/<run_id>/
├── user_input.txt
├── memory.md
├── run_config.json
├── logs.txt
├── logs_raw.jsonl
├── prompt_cache/
├── operator_state/
├── stages/
└── workspace/
├── literature/
├── code/
├── data/
├── results/
├── writing/
├── figures/
├── artifacts/
├── notes/
└── reviews/
Directory semantics
literature/: reading notes, survey tables, benchmark notescode/: runnable code, scripts, configs, implementationsdata/: machine-readable data and manifestsresults/: machine-readable experiment outputswriting/: LaTeX sources, sections, bibliography, tablesfigures/: real plots and paper figuresartifacts/: compiled PDFs and packaged deliverablesnotes/: temporary or supporting research notesreviews/: readiness, critique, and dissemination materials
🧠 Execution Model
For each stage attempt, AutoR assembles a prompt from:
- the stage template from src/prompts/
- the required stage summary contract
- execution-discipline constraints
user_input.txt- approved
memory.md - optional refinement feedback
- for continuation attempts, the current draft/final stage files and workspace context
The assembled prompt is written to runs/<run_id>/prompt_cache/, per-stage session IDs are stored in runs/<run_id>/operator_state/, and Claude is invoked in live streaming mode.
First attempt for a stage:
claude --model <model> \
--permission-mode bypassPermissions \
--dangerously-skip-permissions \
--session-id <stage_session_id> \
-p @runs/<run_id>/prompt_cache/<stage>_attempt_<nn>.prompt.md \
--output-format stream-json \
--verbose
Continuation attempt for the same stage:
claude --model <model> \
--permission-mode bypassPermissions \
--dangerously-skip-permissions \
--resume <stage_session_id> \
-p @runs/<run_id>/prompt_cache/<stage>_attempt_<nn>.prompt.md \
--output-format stream-json \
--verbose
Important behavior:
- refinement attempts reuse the same stage conversation whenever possible
- streamed Claude output is shown live in the terminal
- raw stream-json output is captured in
logs_raw.jsonl - if resume fails, AutoR can fall back to a fresh session
- if stage markdown is incomplete, AutoR can repair or normalize it locally
🏗️ Architecture
The main code lives in:
flowchart LR
A[main.py] --> B[src/manager.py]
B --> C[src/operator.py]
B --> D[src/utils.py]
B --> E[src/writing_manifest.py]
B --> F[src/prompts/*]
C --> D
File boundaries
- main.py: CLI entry point; starts new runs or resumes old ones
- src/manager.py: owns the 8-stage loop, approval flow, repair flow, and stage continuation policy
- src/operator.py: invokes Claude CLI, streams output, persists session IDs, resumes stage conversations, and falls back on resume failure
- src/utils.py: stage metadata, run paths, prompt assembly, markdown validation, artifact validation, and venue resolution
- src/writing_manifest.py: scans figures, results, data files, and stage summaries to generate Stage 07 writing context
- src/prompts/: one prompt template per stage
📌 Scope
Included in the current mainline
- fixed 8-stage workflow
- mandatory human approval after every stage
- one primary Claude invocation per stage attempt
- stage-local continuation within the same Claude session
- prompt caching via
@file - live streaming terminal output
- repair passes and local fallback normalization
- draft-to-final stage promotion
- artifact-aware validation
- resume and
--redo-stage - lightweight venue profiles for Stage 07 writing
Intentionally out of scope
- generic multi-agent orchestration
- database-backed runtime state
- concurrent stage execution
- heavyweight platform abstractions
- dashboard-first productization
🛣️ Roadmap
The most valuable next steps are the ones that make AutoR more like a real research workflow, not more like a demo framework.
- Cross-stage rollback and invalidation
Later-stage failures should be able to mark downstream work as stale. - Machine-readable run manifest
Add a lightweight source of truth for stage status, stale dependencies, and artifact pointers. - Continuation handoff compression
Make long stage refinement more stable without bloating context. - Stronger automated tests
Cover repair flow, resume fallback, artifact validation, and approval-loop correctness. - Artifact indexing
Add lightweight metadata arounddata/,results/,figures/, andwriting/. - Frontend run browser
A lightweight UI for browsing runs, stages, logs, and artifacts, driven by the run directory itself.
📝 Notes
runs/is gitignored.- AutoR controls workflow orchestration, not scientific truth.
- Submission-grade output still depends on the environment, model quality, local tools, and available datasets.
- Stage 07 venue support is intentionally lightweight metadata-driven packaging, not a promise of full official template compliance for every venue.
🌍 Community
Join the project community channels:
| Discord | ||
|---|---|---|
 |
 |
 |
⭐ Star History
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi