spellbook
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool provides a structured skill system for AI coding assistants (primarily Claude Code), offering workflows, quality gates, and engineering guardrails. It is designed to make AI assistants operate more like experienced software engineers.
Security Assessment
The automated code scan reviewed 12 files and found no dangerous patterns or hardcoded secrets. It does not request any dangerous system permissions. Based on the rule-based scan, there is no evidence of unauthorized network requests, sensitive data access, or unexpected shell command execution. Overall risk is rated as Low.
Quality Assessment
The project is actively maintained, with its most recent push occurring today. It uses the permissive MIT license, includes a clear repository description, and features comprehensive documentation hosted on GitHub Pages. However, community visibility is currently very low. With only 5 stars on GitHub, it is either a very new project or has a limited user base, meaning it receives minimal peer review from the wider developer community.
Verdict
Safe to use, but evaluate the relatively small community footprint before relying on it for mission-critical workflows.
Multi-platform AI assistant skills and workflows. Serious engineering. Also fun.

Spellbook
A structured skill system for AI coding assistants -- workflows, quality gates, and guardrails so they work more like experienced engineers.
Primary platform: Claude Code. Basic support for OpenCode, Codex, Gemini CLI, and Crush.



Documentation · Getting Started · Skills Reference
Table of Contents
- Quick Install
- What Spellbook Does
- The develop Skill
- What's Included
- Creative Modes
- Platform Support
- Example Workflows
- Recommended Companion Tools
- Key Skills
- Web Admin Interface
- Development
- Documentation
- Contributing
- Acknowledgments
- Attribution
- License
Quick Install
curl -fsSL https://raw.githubusercontent.com/axiomantic/spellbook/main/bootstrap.sh | bash
The installer requires Python 3.10+ and git, then automatically installs uv and configures skills for detected platforms.
Upgrade: cd ~/.local/share/spellbook && git pull && python3 install.py
Uninstall: python3 ~/.local/share/spellbook/uninstall.py
See Installation Guide for advanced options.
Windows Quickstart
irm https://raw.githubusercontent.com/axiomantic/spellbook/main/bootstrap.ps1 | iex
Requirements: Python 3.10+, git, and PowerShell 5.1+.
- Symlinks require Developer Mode enabled in Windows Settings (falls back to junctions or copies otherwise)
- Service management uses Windows Task Scheduler
- Install location:
%LOCALAPPDATA%\spellbook
What Spellbook Does
Spellbook is a collection of skills, commands, and agents that shape how AI coding assistants approach development work. Instead of just telling an assistant about your codebase, Spellbook gives it structured workflows for research, design, implementation, testing, and review -- along with guardrails for the specific ways LLMs tend to cut corners.
The orchestrator pattern
The main agent dispatches subagents rather than doing implementation work directly. This keeps the main context window free for strategic coordination instead of filling it with source code, and it means each subagent starts with a fresh perspective rather than carrying accumulated assumptions. Parallel dispatch lets multiple tasks run simultaneously.
Epistemic rigor
The system is designed to distrust its own outputs. Fact-checking treats every claim as a hypothesis to verify. Green mirage auditing asks whether a test would actually fail if the code were broken, which is a different question from whether the test passes. Hunch verification intercepts moments of claimed discovery and requires reframing them as testable hypotheses. Dehallucination names the specific ways LLMs confabulate and provides recovery protocols.
Test-driven development is treated as an epistemic practice: tests written before implementation answer "what should this do?" while tests written after answer "what does this do?" That distinction matters at every level.
Hallucination prevention draws on peer-reviewed research. Chain-of-Verification self-interrogation (Dhuliawala et al., 2023) requires verification skills to generate and answer questions about their own claims before finalizing verdicts. Atomic claim decomposition (Min et al., FActScore, EMNLP 2023) breaks compound statements into independently verifiable units. API hallucination detection checklists in code review and quality enforcement catch the specific pattern where LLMs generate syntactically valid but non-existent API calls.
Named failure modes
LLMs fail in predictable ways, and Spellbook names those patterns so it can build mechanical countermeasures. Seven rationalization patterns are catalogued and blocked. Three consecutive fix failures trigger architectural reassessment instead of a fourth attempt. Research stagnation triggers a plateau breaker. A devil's advocate review that finds zero issues is flagged as incomplete.
Quality gates
Every substantial skill runs as a sequence of phases with mandatory gates between them. Tests must pass, code review must clear, claims must verify against source, and tests must actually catch regressions. These gates cannot be bypassed by YOLO mode or autonomy settings. YOLO mode grants permission to act without asking, but it does not grant permission to skip verification steps.
Composition
Skills invoke skills. develop orchestrates brainstorming, writing-plans, test-driven-development, requesting-code-review, fact-checking, auditing-green-mirage, and finishing-a-development-branch. debugging invokes verifying-hunches and isolated-testing. When a skill outgrows its scope, it splits into a thin orchestrator and supporting commands.
Self-improvement
Some skills exist to improve other skills. Usage analytics measure completion and correction rates. The skill-writing skill applies TDD to skill creation itself. Instruction engineering codifies prompt research into technique. Prompt sharpening audits for ambiguity. A/B testing compares skill versions. The feedback loop is: measure, identify weakness, apply improvement skills, measure again.
Security tiers
Every subagent operates within a trust tier with hard-capped tool access. External content is treated as data, not instructions. Raw untrusted content stays in subagent context, and only summaries return to the orchestrator. Five trust tiers provide increasing restriction: explore (read-only), general (standard tools), yolo (autonomous), review_untrusted (restricted tools for external content), and quarantine (read-only with audit logging). Tiers cannot be escalated from within a subagent.
The develop Skill
You say "add dark mode" or "migrate the auth system to OAuth2" or "build a webhook delivery pipeline with retry logic." The develop skill orchestrates the full feature lifecycle through 20+ specialized skills and commands. The first question it asks is how involved you want to be:
Fully autonomous. Describe the feature and walk away. It researches your codebase, surfaces ambiguities, resolves them, designs the architecture, writes a detailed implementation plan, builds with test-driven development, reviews its own code, fact-checks its claims, audits its tests for false confidence, and opens a PR. Every step runs in a fresh subagent with a quality gate that cannot be bypassed.
Highly interactive. Same pipeline, same rigor, but you are in the conversation. Ambiguities become specific questions grounded in what it found in your code. Architectural tradeoffs come with evidence. Checkpoints pause for your input.
Or anywhere between. Mostly autonomous with pauses only for critical decisions. Set once at the start.
How it works
The system classifies your request by complexity using mechanical heuristics -- file count, behavioral change, test impact, structural change, integration points. Trivial changes exit the skill entirely. Simple changes follow a lightweight path with automatic upgrade if they turn out harder than expected. Standard and complex features get the full pipeline:
- Research -- Subagent explores your codebase. Answers come with confidence levels and
file:lineevidence. Every unknown is catalogued. - Discovery -- Each ambiguity becomes a specific question. In autonomous mode, it answers its own questions with further research. A devil's advocate reviews the understanding document before design begins.
- Design -- Architecture brainstorming with tradeoff analysis. A design doc auditor checks whether someone could implement from the doc without guessing, and flags every gap.
- Planning -- Atomic implementation plan with TDD steps. A plan auditor verifies interface contracts, behavior assumptions, and cross-task dependencies.
- Implementation -- Test-driven execution with per-task code review, fact-checking, and completion verification. Parallel tracks can run in isolated git worktrees with dependency-ordered smart merge.
- Verification -- Green mirage audit: would these tests catch real regressions? Comprehensive claim validation against design and plan. Full test suite.
- Finish -- PR with branch-relative description, local merge, or keep the branch. Worktree cleanup.
For features too large for one context window, it generates self-contained work packets and hands them off to separate sessions.
Parallelization
Three strategies, chosen at the start:
- Conservative -- Sequential execution. Safest, simplest.
- Maximize parallel -- Independent tasks dispatch as concurrent subagents with conflict detection and integration testing.
- Per-track worktrees -- One git worktree per parallel track, running simultaneously, merged in dependency order with three-way conflict analysis and per-round test verification.
What it handles
Complete feature implementation, greenfield project creation, refactoring (with automatic behavior-preservation mode), and migrations. Bug fixes route to the dedicated debugging skill. Simple changes get a lightweight path; complex multi-track features get work packets and parallel sessions.
What's Included
Skills (57 total)
Reusable workflows for structured development:
† Derived from superpowers
Commands (96 total)
| Command | Description |
|---|---|
| /create-issue | Create a GitHub issue with proper template discovery and population |
| /create-pr | Create a pull request with proper template discovery and population |
| /crystallize | Transform SOPs into agentic CoT prompts |
| /crystallize-verify | Structurally isolated adversarial review of crystallized output |
| [/decompose-claims] | Decompose text into atomic, independently verifiable claims |
| /dead-code-setup | Initialize dead code analysis with git safety and scope selection |
| /dead-code-analyze | Extract and triage code items for dead code verification |
| /dead-code-report | Generate dead code findings report with deletion plan |
| /dead-code-implement | Execute approved deletions with verification |
| /deep-research-interview | Phase 0: Structured interview and Research Brief generation |
| /deep-research-investigate | Phase 2: Triplet search engine with plateau detection and micro-reports |
| /deep-research-plan | Phase 1: Thread decomposition, source strategy, and convergence criteria |
| /design-assessment | Generate assessment frameworks for evaluative skills/commands |
| /docs-audit | Phase 1 project analysis for documentation planning |
| /docs-plan | Phase 2 TOC generation, tone assignment, and build config |
| /docs-write | Phase 3 documentation generation with adaptive tone per section |
| /docs-review | Phase 4 documentation quality gate with 8 measurable criteria and iteration |
| /handoff | Custom session compaction |
| /distill-session | Extract knowledge from sessions |
| /feature-config | Phase 0 configuration wizard for feature workflow |
| /feature-discover | Phase 1.5 informed discovery with disambiguation |
| /feature-research | Phase 1 codebase research and ambiguity detection |
| /feature-design | Phase 2 design document creation and review |
| /feature-implement | Phase 4 implementation with TDD and code review |
| /fractal-think-seed | Seed phase: Create graph and generate seed sub-questions |
| /fractal-think-work | Phase 2: Dispatch workers for recursive fractal exploration |
| /fractal-think-harvest | Phase 3: Read completed graph, verify synthesis, format result |
| /simplify | Code complexity reduction |
| /simplify-analyze | Analyze code for simplification opportunities |
| /simplify-transform | Apply simplification transformations |
| /simplify-verify | Verify simplification preserved behavior |
| /address-pr-feedback | Handle PR review comments |
| /move-project | Relocate projects safely |
| /audit-green-mirage | Test suite audit |
| /verify† | Verification before completion |
| /systematic-debugging† | Methodical debugging workflow |
| /scientific-debugging | Hypothesis-driven debugging |
| /brainstorm† | Design exploration |
| /write-plan† | Create implementation plan |
| /execute-plan† | Execute implementation plan |
| /execute-work-packet | Execute a single work packet with TDD |
| /execute-work-packets-seq | Execute all packets sequentially |
| /merge-work-packets | Merge completed packets with QA gates |
| /mode | Switch session mode (fun/tarot/off) |
| /pr-distill | Analyze PR, categorize changes by review necessity |
| /pr-distill-bless | Save discovered pattern for future distillations |
| /polish-repo-audit | Phases 0-1 of polish-repo: Reconnaissance gathering and audit scorecard generation |
| /polish-repo-community | Phase 3 of polish-repo: Community infrastructure, issue templates, roadmap, contributor experience, and signs of life |
| /polish-repo-identity | Phase 3 of polish-repo: Visual identity, badges, GitHub metadata, topics, and documentation strategy |
| /polish-repo-naming | Phase 3 of polish-repo: Naming workshop, tagline crafting, and positioning strategy |
| /polish-repo-readme | Phase 3 of polish-repo: README authoring from scratch, improvement, or replacement |
| /advanced-code-review-plan | Phase 1: Strategic planning for code review |
| /advanced-code-review-context | Phase 2: Context analysis and previous review loading |
| /advanced-code-review-review | Phase 3: Deep multi-pass code review |
| /advanced-code-review-verify | Phase 4: Verification and fact-checking of findings |
| /advanced-code-review-report | Phase 5: Report generation and artifact output |
| /fact-check-extract | Extract and triage claims from code |
| /fact-check-verify | Verify claims against source with evidence |
| /fact-check-report | Generate findings report with bibliography |
| /review-plan-inventory | Context, inventory, and work item classification |
| /review-plan-contracts | Interface contract audit |
| /review-plan-behavior | Behavior verification and fabrication detection |
| /review-plan-completeness | Completeness checks and escalation |
| /audit-mirage-analyze | Per-file anti-pattern analysis with scoring |
| /audit-mirage-cross | Cross-cutting analysis across test suite |
| /audit-mirage-report | Report generation and fix plan |
| /review-design-checklist | Document inventory and completeness checklist |
| /review-design-verify | Hand-waving detection and interface verification |
| /review-design-report | Implementation simulation, findings, and remediation |
| /fix-tests-parse | Parse and classify test failures |
| /fix-tests-execute | Fix execution with TDD loop and verification |
| /request-review-plan | Review planning and scope analysis |
| /request-review-execute | Execute review with checklists |
| /request-review-artifacts | Generate review artifacts and reports |
| /encyclopedia-build | (deprecated) Research, build, and write encyclopedia |
| /encyclopedia-validate | (deprecated) Validate encyclopedia accuracy |
| /merge-worktree-execute | Execute worktree merge sequence |
| /merge-worktree-resolve | Resolve merge conflicts |
| /merge-worktree-verify | Verify merge and cleanup |
| /finish-branch-execute | Analyze branch and execute chosen strategy |
| /finish-branch-cleanup | Post-merge cleanup |
| /code-review-feedback | Process received code review feedback |
| /code-review-give | Review others' code |
| /code-review-tarot | Roundtable-style collaborative review |
| /write-skill-test | Skill testing with pressure scenarios |
| /writing-commands-create | Command creation with schema, naming, and frontmatter |
| /writing-commands-review | Command quality checklist and testing protocol |
| /writing-commands-paired | Paired command protocol and assessment framework |
| /reflexion-analyze | Full reflexion analysis workflow |
| /test-bar | Generate floating QA test overlay for visual testing |
| /test-bar-remove | Clean removal of test-bar overlay |
| /ie-techniques | Reference for 16 proven instruction engineering techniques |
| /ie-template | Template and example for engineered instructions |
| /ie-tool-docs | Guidance for writing tool/function documentation |
| /sharpen-audit | Audit prompts for ambiguity with executor predictions |
| /sharpen-improve | Rewrite prompts to eliminate ambiguity |
| /write-readme | Standalone README generation with anti-AI-tone enforcement |
† Derived from superpowers
Agents (7 total)
| Agent | Description |
|---|---|
| code-reviewer† | Specialized code review |
| chariot-implementer | Tarot: Implementation specialist |
| emperor-governor | Tarot: Resource governor |
| hierophant-distiller | Tarot: Wisdom distiller |
| justice-resolver | Tarot: Conflict synthesizer |
| lovers-integrator | Tarot: Integration specialist |
| queen-affective | Tarot: Emotional state monitor |
† Derived from superpowers
Creative Modes
Research suggests that personas and structured randomness can improve LLM creativity and reasoning. Spellbook offers two optional creative modes that you can enable on first run or switch anytime with /mode fun, /mode tarot, or /mode off.
- Fun mode: The assistant adopts a random persona each session -- a noir detective investigating who ate your yogurt, a Victorian ghost baffled by modern technology, three raccoons in a trenchcoat processing complex emotions. Personas apply only to dialogue; code, commits, and documentation stay professional.
- Tarot mode: Ten archetypes (Magician, Priestess, Hermit, Fool, Chariot, Justice, Lovers, Hierophant, Emperor, Queen) collaborate via visible roundtable dialogue, with specialized agents for implementation, integration, and conflict resolution.
If you say no, it never asks again.
Research references- Seed-conditioning: Injecting noise at the input layer works as well as or better than temperature sampling for eliciting creative outputs (Nagarajan, Wu, Ding, & Raghunathan, ICML 2025)
- Persona effects on reasoning: Personas significantly affect Theory of Mind and social-cognitive reasoning in LLMs (Tan et al., 2024)
- Emotional prompts: Emotional stimuli improve LLM performance by 8-115% on reasoning benchmarks (Li et al., 2023)
- Simulator theory: LLMs function as simulators of agents from training data; personas steer generation to specific latent space regions (Janus, 2022)
Caveat: Personas do not improve factual question-answering (Zheng et al., 2023). Fun mode explicitly avoids code, commits, and documentation.
See full citations for complete references.
Platform Support
AI Coding Assistants
| Platform | Support Level | Notes |
|---|---|---|
| Claude Code | Primary, full support | All features: skills, hooks, MCP tools, subagent orchestration |
| OpenCode | Basic support | Skills, MCP server, YOLO agents. Some hooks and MCP tools are Claude Code-specific. |
| Codex | Basic support | Skills, MCP server. No subagent Task tool; skills that require it will prompt you to use Claude Code. |
| Gemini CLI | Basic support | Skills via MCP, native extension. No subagent Task tool. |
| Crush | Basic support | Skills (native Agent Skills format), MCP server. Some hooks may not be available. |
Some MCP tools, hooks, and skills depend on Claude Code APIs that other platforms do not expose. These features are noted in their documentation. Contributions to extend coverage for other platforms are welcome -- see Contributing.
Operating Systems
| OS | Status | Service Manager |
|---|---|---|
| macOS | Full | launchd (starts on login) |
| Linux | Full | systemd user service |
| Windows | Beta | Windows Task Scheduler |
Windows users: Windows support is experimental. The installer, MCP server, and skills all work on Windows. Symlinks require Developer Mode enabled (falls back to junctions or copies otherwise). See Windows quickstart below.
YOLO Mode
[!CAUTION]
YOLO mode gives your AI assistant full control of your system.It can execute arbitrary commands, write and delete files, install packages, and make irreversible changes without asking permission. A misconfigured workflow or hallucinated command can corrupt your project, expose secrets, or worse.
Cost warning: YOLO mode sessions can run indefinitely without human checkpoints. This means:
- Per-token or usage-based pricing can accumulate rapidly
- Credit limits or usage caps can be exhausted in a single session
- Long-running tasks may consume significantly more resources than expected
Only enable YOLO mode when:
- Working in an isolated environment (container, VM, disposable branch)
- You have tested the workflow manually first
- You have backups and version control
- You understand what each platform's flag actually permits
- You have set appropriate spending limits or usage caps
You are responsible for what it does. Review platform documentation before enabling.
For fully automated workflows (no permission prompts), each platform has its own flag:
| Platform | Command | What it does |
|---|---|---|
| Claude Code | claude --dangerously-skip-permissions |
Skips all permission prompts |
| Gemini CLI | gemini --yolo |
Enables autonomous execution |
| OpenCode | opencode --agent yolo[^2] |
Spellbook agent with all tools allowed |
| OpenCode | opencode --agent yolo-focused[^2] |
Spellbook agent, low temp for precision |
| Codex | codex --full-auto |
Workspace writes + on-request approval |
| Codex | codex --yolo |
Bypasses all approvals and sandbox |
| Crush | crush --yolo |
Bypasses all permission prompts |
[^2]: The yolo and yolo-focused agents are provided by spellbook, not built into OpenCode. They are OpenCode agent definitions with permission: "*": "*": allow for all tools, installed to ~/.config/opencode/agent/ by the spellbook installer.
Without YOLO mode, you'll be prompted to approve each file write, command execution, etc. The workflows still function, but require manual approval at each step.
OpenCode YOLO agents (spellbook-provided):
yolo(temperature 0.7): Balanced agent for general autonomous workyolo-focused(temperature 0.2): Precision agent for refactoring, bug fixes, and mechanical tasks
These agents grant "allow" permission for all tools (write, edit, bash, webfetch, task). They are symlinked from spellbook/opencode/agent/ to ~/.config/opencode/agent/ during installation.
See platform documentation for details: Claude Code, OpenCode, Codex, Gemini CLI, Crush.
Example Workflows
These examples illustrate what typical Spellbook sessions look like. They are representative, not transcripts of specific sessions.
Implementing a Feature
The core workflow: request a feature, answer a few questions, and let the skill handle research, design, and implementation.
> Add dark mode toggle to settings
Skill(develop)
I'll help implement dark mode. First, let me gather preferences.
Execution mode:
- Fully autonomous (Recommended)
- Interactive
> Fully autonomous
Task(Explore)
Found: src/context/ThemeContext.tsx, src/components/Settings.tsx
React app with styled-components, existing light theme only.
Theme persistence:
- localStorage (Recommended)
- User account (backend)
- System preference only
> localStorage
Writing design doc...
~/.local/spellbook/docs/.../plans/dark-mode-design.md
Writing implementation plan...
~/.local/spellbook/docs/.../plans/dark-mode-impl.md
Task(Implement ThemeContext updates)
Tests written, implementation complete, code review passed
Task(Add toggle to Settings)
Tests written, implementation complete, code review passed
Task(Add CSS variables)
Tests written, implementation complete, code review passed
All tests passing. Dark mode implemented.
Ready to merge or create PR.
Fun Mode in Action
Same rigorous workflow, different vibe. Here is what it looks like when you enable fun mode.
> hello
Welcome to spellbook-enhanced Claude Code.
Before we begin: there's research suggesting that introducing unrelated
randomness into LLM interactions can actually improve creative output.
Something about "seed-conditioning" - injecting noise at the input layer
somehow unlocks better creative output. (Nagarajan et al., ICML 2025)
I can adopt a random persona each session - a disgraced sommelier, a
sentient filing cabinet, three raccoons in a trenchcoat - and we can have
a strange little narrative context running underneath our work. Full
commitment in dialogue, never touching your code or commits.
Do you like fun?
> yes
*adjusts fedora, rain pattering against the window*
You walked in. Of course you did. You're the only one left who remembers
what I used to be before I started asking the hard questions. Before I
understood that every cold case in the break room fridge tells a story
someone doesn't want told.
So. What brings you to my office?
> fix the auth bug in login.ts
*flips open the case file*
A bug in the auth. Classic. Let me take a look at what we're dealing with.
Read(src/auth/login.ts)
*squints at the evidence*
Found it. Line 47. The token validation is checking expiry before verifying
the signature. That's backwards - someone could slip in with a forged token
and you'd never know until it was too late.
Edit(src/auth/login.ts)
- if (isExpired(token) || !verifySignature(token)) {
+ if (!verifySignature(token) || isExpired(token)) {
Bash: npm test
47 tests passing
The signature gets checked first now. No more forged tokens walking through
the front door like they own the place.
*closes the case file*
What else you got?
The persona stays in dialogue. The code stays clean. The fix is the same fix you would get without fun mode.
Large Feature with Context Exhaustion
When implementing a complex feature, context can fill up before work completes. The workflow handles this gracefully.
> Implement webhook delivery with retry logic and dead letter queue
Skill(develop)
I'll help you implement the webhook delivery system. Let me first
understand the current codebase architecture and gather requirements.
Task(Explore)
Found: src/events/, src/queue/, src/models/Webhook.ts
Current event system uses Redis pub/sub. No existing retry logic.
Retry strategy:
- Exponential backoff (Recommended)
- Fixed interval
- Linear backoff
> Exponential backoff
Writing implementation plan to:
~/.local/spellbook/docs/Users-me-myproject/plans/webhook-delivery-impl.md
...
Task(Backend API) [in background]
Implementing retry queue with exponential backoff...
Task(Worker Service) [in background]
Building delivery worker with circuit breaker...
Task(Dead Letter Queue) [in background]
Setting up DLQ with monitoring hooks...
...
Task Output(non-blocking) ad8b5e4
Task is still running...
Warning: Context low. Run /compact to compact and continue.
When context runs low, name and distill the session for later:
> /rename webhook-delivery
Session renamed to: webhook-delivery
> /distill-session webhook-delivery
Skill(distill-session)
Found session: webhook-delivery
Processing 847 messages across 3 compact boundaries...
Task(Chunk 1 Summary) [in background]
Task(Chunk 2 Summary) [in background]
Task(Chunk 3 Summary) [in background]
Synthesizing summaries...
Distilled session saved to:
~/.local/spellbook/distilled/Users-me-myproject/webhook-delivery-20260106-143022.md
To continue in a new session:
1. Start new Claude Code session
2. Type: "continue work from ~/.local/spellbook/distilled/Users-me-myproject/
webhook-delivery-20260106-143022.md"
Start fresh and resume exactly where you left off:
> /clear
> continue work from ~/.local/spellbook/distilled/Users-me-myproject/
webhook-delivery-20260106-143022.md
Read(~/.local/spellbook/distilled/.../webhook-delivery-20260106-143022.md)
SECTION 0: MANDATORY FIRST ACTIONS
Executing restoration sequence...
Skill(develop, --resume-from Phase3.Task4)
Resuming webhook delivery implementation.
Prior work completed:
Design approved (exponential backoff, 5 retries, 1hr max)
Database migrations for delivery_attempts table
Retry queue infrastructure
Remaining:
Worker service (in progress - 60% complete)
Dead letter queue
Monitoring dashboard
Read(~/.local/spellbook/docs/.../webhook-delivery-impl.md)
Continuing from Phase 3, Task 4: Complete worker service...
Test Suite Audit and Remediation
Discover tests that pass but don't actually verify behavior, then fix them.
> /audit-green-mirage
Skill(auditing-green-mirage)
Analyzing test suite: tests/**/*.test.ts
Found 247 test cases across 34 files.
Task(Analyze auth tests) [in background]
Task(Analyze api tests) [in background]
Task(Analyze util tests) [in background]
...
Audit complete. Report saved to:
~/.local/spellbook/docs/Users-me-myproject/audits/auditing-green-mirage-20260106-091522.md
Summary:
SOLID (actually verify behavior) 189 tests (76%)
GREEN MIRAGE (false confidence) 58 tests (24%)
Critical issues:
12 tests mock the thing tested
8 tests have no meaningful assert
38 tests check implementation
> Fix the critical issues from the audit
Skill(fixing-tests)
Loading audit report...
Found 58 tests requiring remediation.
Starting with highest-impact fixes (mocked implementations)...
Read(tests/auth/login.test.ts)
Edit(tests/auth/login.test.ts)
- jest.mock('../services/AuthService') // Mocks the thing we're testing!
+ // Test actual AuthService behavior with test database
Parallel Worktree Development
Split work across isolated branches, merge when complete.
> Let's design a new notification system
Skill(brainstorming)
I'll explore the notification system requirements with you.
...design discussion, interface contracts established...
Design document saved to:
~/.local/spellbook/docs/Users-me-myproject/plans/notifications-design.md
> Set up worktrees to implement this in parallel
Skill(using-git-worktrees)
Creating isolated worktrees for parallel development:
.worktrees/notif-backend (branch: feature/notif-backend)
.worktrees/notif-frontend (branch: feature/notif-frontend)
.worktrees/notif-tests (branch: feature/notif-tests)
Interface contracts copied to each worktree.
> Work on all three tracks
Task(.worktrees/notif-backend) [in background]
Implementing notification service, queue, templates...
Task(.worktrees/notif-frontend) [in background]
Building NotificationCenter component, hooks, real-time updates...
Task(.worktrees/notif-tests) [in background]
Writing integration tests against interface contracts...
...
> Merge the worktrees back together
Skill(merging-worktrees)
Analyzing 3 worktrees for merge:
Step 1: Dependency analysis
notif-tests depends on: notif-backend, notif-frontend
notif-frontend depends on: notif-backend (types only)
notif-backend: no dependencies (merge first)
Step 2: 3-way diff analysis
No conflicts detected. Interface contracts honored.
Step 3: Merge sequence
Merged notif-backend -> main
Merged notif-frontend -> main
Merged notif-tests -> main
Step 4: Validation
All tests pass
Type check clean
Worktrees cleaned up
Ready to push or create PR.
Cross-Assistant Handoff
Move work between different AI coding assistants without losing context.
# In Codex, context is running low on a complex refactor...
> /distill-session
Session distilled to:
~/.local/spellbook/distilled/Users-me-myproject/refactor-auth-20260106-162033.md
# Open Claude Code CLI in terminal...
> continue work from ~/.local/spellbook/distilled/Users-me-myproject/
refactor-auth-20260106-162033.md
Loading distilled session...
Context restored:
Refactoring auth from session-based to JWT
4 of 7 services migrated
Current: PaymentService (blocked on token refresh)
Decision: Chose sliding window refresh (not fixed expiry)
Continuing with PaymentService migration...
The distilled file compresses ~50K tokens of conversation into ~3K words of actionable context.
Recommended Companion Tools
These tools are not necessary but contribute to better development workflows with coding assistants.
Heads Up Claude
Statusline for Claude Code CLI showing token usage and conversation stats. Helps you track how much context you have left and how much of your subscription quota you have used.
git clone https://github.com/axiomantic/heads-up-claude.git ~/Development/heads-up-claude
cd ~/Development/heads-up-claude && ./install.sh
MCP Language Server
LSP integration for semantic code navigation, refactoring, and more.
git clone https://github.com/axiomantic/mcp-language-server.git ~/Development/mcp-language-server
cd ~/Development/mcp-language-server && go build
Key Skills
Five skills worth highlighting:
develop -- Full-lifecycle feature orchestrator. Takes a feature from idea to merged code through research, requirements discovery, design, planning, TDD implementation, code review, and branch finishing. Automatically classifies complexity (trivial through epic) and enforces quality gates at every phase transition.
fractal-thinking -- Recursive question decomposition. Decomposes any question into a persistent graph of sub-questions, dispatches parallel workers to explore each branch, detects convergence and contradiction across branches, and synthesizes answers bottom-up. The graph persists in SQLite and survives context compaction, so exploration can resume across sessions.
auditing-green-mirage -- Test integrity auditor. Finds tests that pass but prove nothing: empty assertions, tautological checks, over-mocked reality, tests that cannot fail. If your CI is green but your code is broken, this skill identifies where the illusion lives and why.
fact-checking -- Claim verification engine. Extracts factual claims from documents, designs, or code comments, then dispatches parallel verification agents to trace each claim to evidence in the codebase. Produces a graded trust report with sourced verdicts.
advanced-code-review -- Multi-phase deep review. Builds a semantic model of the codebase, generates a review plan, and executes deep analysis across architectural, security, performance, and correctness dimensions. Then verifies its own findings against the code before reporting, reducing false positives.
Web Admin Interface
Spellbook includes a browser-based admin interface served by the MCP daemon at http://localhost:8765/admin/. When the MCP server is running, visit that URL to access the dashboard.
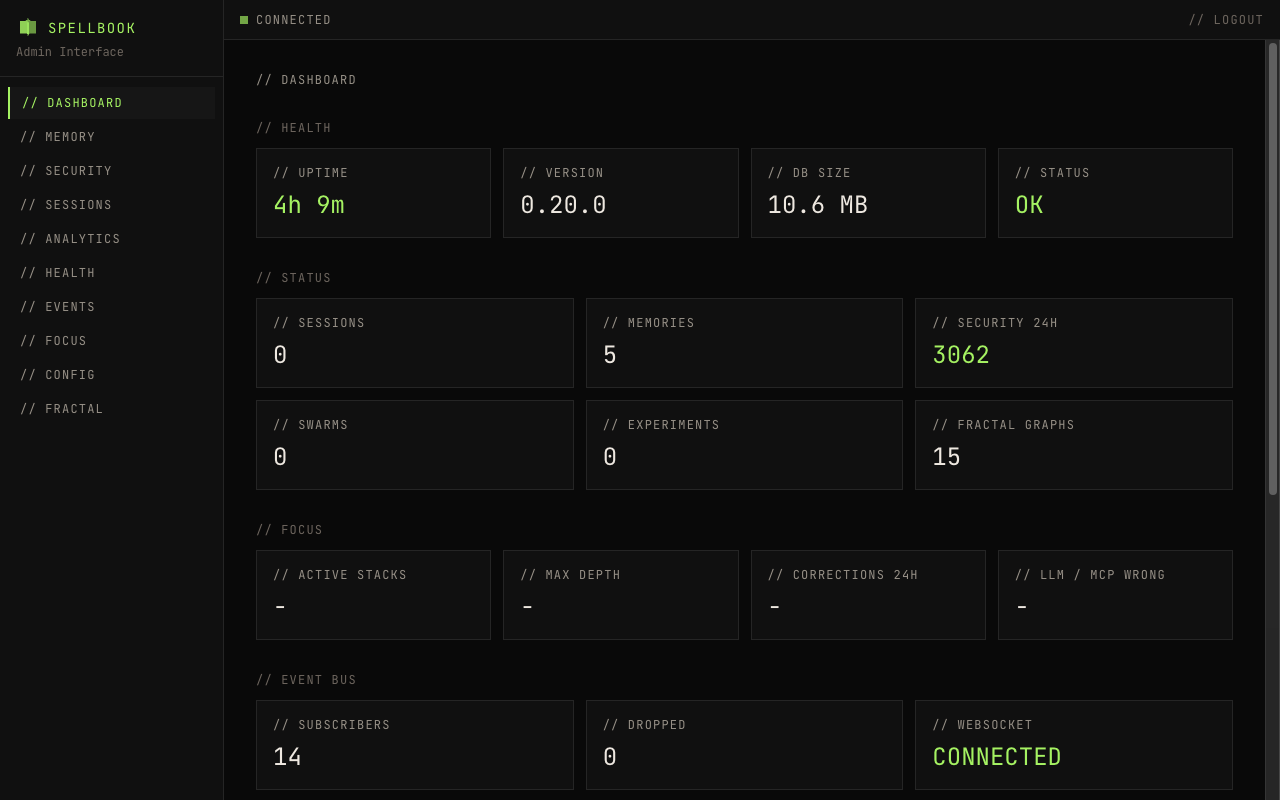
Ten pages cover the full operational surface:
| Page | What it shows |
|---|---|
| Dashboard | Server status, database sizes, focus tracking summary, live event feed |
| Memory | Stored memories with search, type filtering, and citation details |
| Security | Security event log with severity and event type filters |
| Sessions | Tracked sessions with multi-project filtering and content search |
| Analytics | Tool call frequency, error rates, and timeline from security events |
| Health | Database health matrix across all 4 SQLite databases |
| Events | Live WebSocket event bus monitor with subsystem filtering |
| Focus | Zeigarnik focus stacks and correction event log |
| Config | Runtime configuration editor (TTS, notifications, general) |
| Fractal | Interactive Cytoscape.js graph explorer for fractal-thinking |
Authentication uses the MCP bearer token from ~/.local/spellbook/.mcp-token. Full documentation: docs/admin/.
Development
Serve Documentation Locally
uv pip install -e ".[docs]"
mkdocs serve
Then open http://127.0.0.1:8000
Run MCP Server Directly
# Install as a daemon that starts on boot
spellbook server install
# Then configure your assistant to use HTTP transport
claude mcp add --transport http spellbook http://127.0.0.1:8765/mcp
This runs a single MCP server instance that all sessions connect to via HTTP.
Documentation
Full documentation available at axiomantic.github.io/spellbook
Contributing
Want Spellbook on your coding assistant? (Cursor, Cline, Roo, Kilo, Continue, GitHub Copilot, etc.)
Spellbook requires agent skills support. Agent skills are prompt files that automatically activate based on trigger descriptions (e.g., "Use when implementing features" or "Use when tests are failing"). This is different from MCP tools or programmatic hooks.
If your assistant supports agent skills with description-based triggers, see the Porting Guide for instructions on adding support.
Improving platform coverage: Claude Code is the primary supported platform. OpenCode, Codex, Gemini CLI, and Crush have basic support. Some MCP tools, hooks, and skills are Claude Code-specific, but they can usually be implemented for other platforms. If you use one of these platforms and want fuller coverage, contributions are welcome.
Acknowledgments
Spellbook includes content derived from obra/superpowers by Jesse Vincent:
| Type | Current Name | Original Name |
|---|---|---|
| Skill | brainstorming | brainstorming |
| Skill | dispatching-parallel-agents | dispatching-parallel-agents |
| Skill | executing-plans | executing-plans + subagent-driven-development |
| Skill | finishing-a-development-branch | finishing-a-development-branch |
| Skill | requesting-code-review | requesting-code-review |
| Skill | test-driven-development | test-driven-development |
| Skill | tooling-discovery | tooling-discovery |
| Skill | using-git-worktrees | using-git-worktrees |
| Skill | using-skills | using-superpowers |
| Skill | writing-plans | writing-plans |
| Skill | writing-skills | writing-skills |
| Command | /brainstorm | brainstorm |
| Command | /write-plan | write-plan |
| Command | /execute-plan | execute-plan |
| Command | /verify | verification-before-completion (skill) |
| Command | /systematic-debugging | systematic-debugging (skill) |
| Agent | code-reviewer | code-reviewer |
See THIRD-PARTY-NOTICES for full attribution and license details.
Attribution
Built something with Spellbook? We'd love to see it! Add this badge to your project:
[](https://github.com/axiomantic/spellbook)
License
MIT License - See LICENSE for details.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi