goldenmatch
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 39 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Polyglot entity-resolution + data-quality toolkit. Zero-config auto-config (negative-evidence + Path Y) hits DQbench composite 91.04 (T3 53.8% → 85.5%). Holds 0.96 DBLP-ACM, 0.94 Febrl3, 0.97 NCVR. GoldenCheck → GoldenFlow → GoldenMatch → GoldenPipe. MCP per package, multi-arch containers, Airflow DAGs, browser workbench.
🟡 Golden Suite
A polyglot data-quality and entity-resolution toolkit. Polished, opinionated, AI-native.
GoldenCheck profiles → GoldenFlow standardizes → GoldenMatch deduplicates → GoldenPipe orchestrates. With InferMap for schema mapping and a Rust extension layer for Postgres / DuckDB.


![]()
![]()




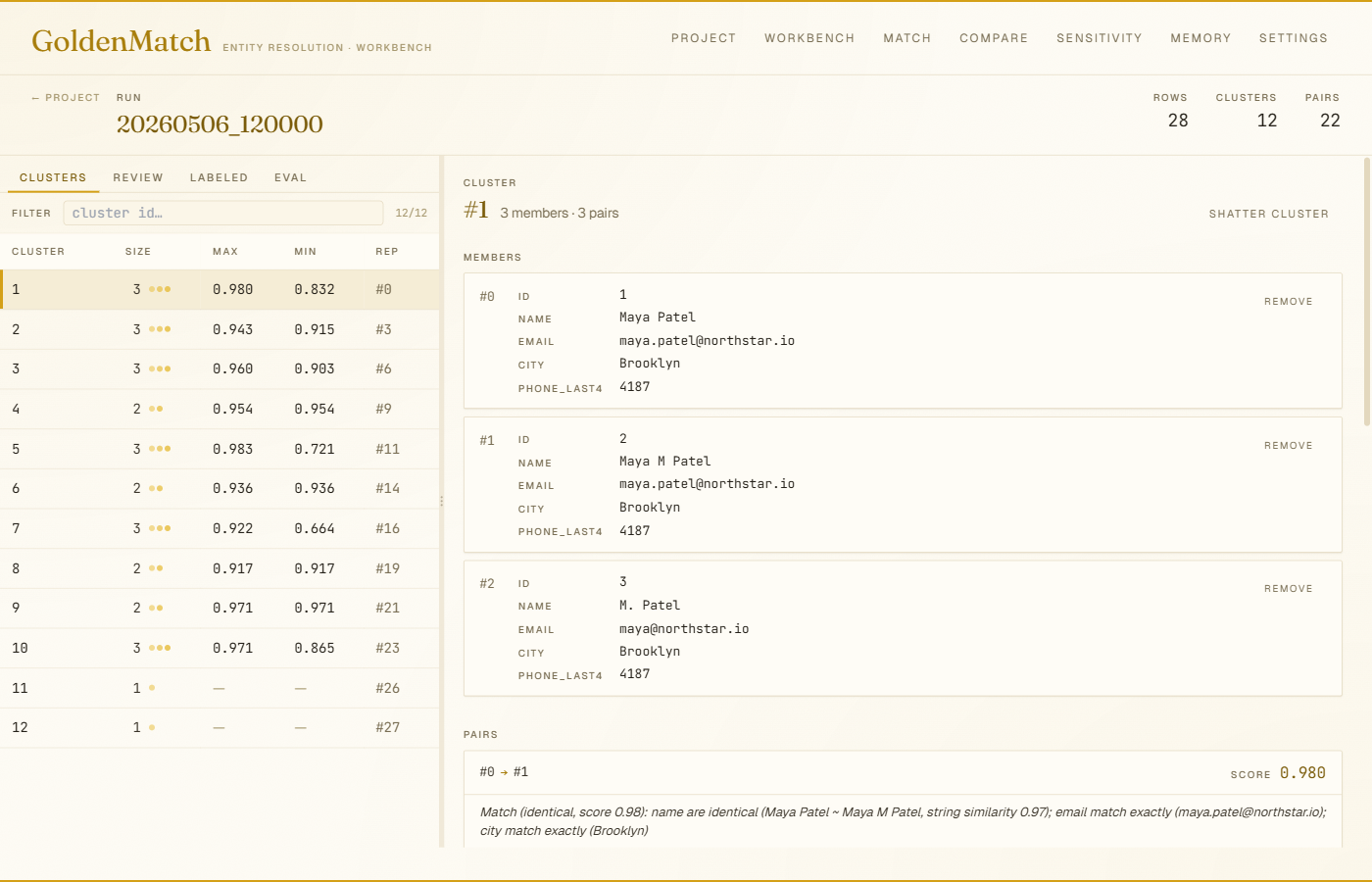
Pair drilldown in the web workbench: cluster members, field-level diff, and a one-line NL explanation per pair. pip install goldenmatch[web] then goldenmatch serve-ui <project>. More screenshots →
# Headline package: dedupe a CSV in 30 seconds
pip install goldenmatch && goldenmatch dedupe customers.csv
# TypeScript / Edge runtimes
npm install goldenmatch
🆕 Unreleased — 5M records in ~50 min on commodity hardware — Chunked mode now actually delivers on its "1M to 100M+" promise. The streaming
scan_csv().slice()reader + Polars-native cross-chunk join (B) + block-keyed bucketed index (C) + DuckDB pair-store backend (D) replace a broken eager-read + Python-double-loop path that OOM-killed at 3h+ on the pre-fix 5M dispatch. Measured: 5M records, 50 min wall, 11.9 GB peak RSS, 618,817 multi-member clusters, no OOM on a 4c/16GB GitHub runner. Passbackend="chunked"with an explicit blocking config. PRs #233/#234/#235.v1.12.0 — Negative evidence on exact matchkeys (Path Y) — NE penalties now filter adversarial collision pairs at the
exact_emaillevel, not just inside the weighted matchkey scoring loop. DQbench composite 91.04 (was 66.99 at v1.11). T2 F1 69.0% → 97.5%, T3 F1 53.8% → 85.5%.v1.8.0 — Introspective auto-config controller — Iterates on stage-emitted complexity signals (block-size dist, score histogram, transitivity, borderline mass) and refines its config via heuristic rules until convergence. Zero-config beats hand-tuned on DBLP-ACM (F1 0.964 vs 0.918 ceiling), NCVR (0.972), Febrl3 (0.944). Cross-run memory at
~/.goldenmatch/autoconfig_memory.db, LLM policy fallback (GOLDENMATCH_AUTOCONFIG_LLM=1), standardization auto-detection. Built by Ben Severn.
Why a suite?
Each tool stands alone, but they compose into a single pipeline:
flowchart LR
raw([raw rows])
golden([golden records])
subgraph orchestration ["GoldenPipe orchestrates"]
direction LR
infermap[InferMap]
goldencheck[GoldenCheck]
goldenflow[GoldenFlow]
goldenmatch[GoldenMatch]
infermap --> goldencheck --> goldenflow --> goldenmatch
end
raw --> infermap
goldenmatch --> golden
| Step | Role |
|---|---|
| InferMap | schema mapping — auto-aligns columns across heterogeneous sources |
| GoldenCheck | profile + validate — encoding, format, anomaly detection |
| GoldenFlow | standardize + transform — phone, date, address, categorical normalization |
| GoldenMatch | dedupe + cluster + survivorship — fuzzy / exact / probabilistic / LLM |
| GoldenPipe | orchestrator — declarative YAML pipeline wiring the four steps |
- Zero-config defaults that admit when they're unsure — every step has a self-verifying preflight + postflight; results carry an inspectable report instead of failing silently.
- 97.2% F1 on DBLP-ACM out of the box for entity resolution. DQBench ER score: 95.30.
- Learning Memory — corrections persist across runs and re-anchor across row reorders, so the system stops needing the same correction twice (GoldenMatch v1.6.0; off by default).
- Privacy-preserving record linkage — match across organizations without sharing raw data (PPRL, 92.4% F1 on FEBRL4).
- AI-native by design — every package ships an MCP server, a REST API, and an A2A agent surface. 36+ MCP tools across the suite, including
auto_configure+controller_telemetryfor v1.7-v1.12 introspection. - AutoConfigController visible everywhere (v1.7-v1.12 surface-parity arc) — web
ControllerPanel, TUICtrl+A, CLIgoldenmatch autoconfig, REST/autoconfig+/controller/telemetry, Postgresgoldenmatch_autoconfig+gm_telemetry, DuckDB UDFs, MCP/A2A telemetry tools. One JSON shape across every interface. - Polyglot parity — Python and TypeScript implementations track the same scorer outputs to 4-decimal precision via a parity harness.
- Production paths — Postgres sync, daemon mode, lineage tracking, review queues, dbt integration, GitHub Actions, and a Rust extension layer for Postgres / DuckDB.
The Suite
| Package | Lang | What it does | Install |
|---|---|---|---|
| GoldenMatch 🟡 | Python · TS | Zero-config entity resolution. Fuzzy + exact + probabilistic + LLM. Headline package. | pip install goldenmatch · npm i goldenmatch |
| GoldenCheck | Python · TS types | Data-quality scanning: encoding, Unicode, format validation, anomaly detection. | pip install goldencheck |
| GoldenFlow | Python · TS | Transforms & standardizers: phone, date, address, categorical normalization. | pip install goldenflow |
| GoldenPipe | Python | Orchestrator that wires Check → Flow → Match into one declarative pipeline. | pip install goldenpipe |
| InferMap | Python · TS | Schema mapping engine — auto-aligns columns across heterogeneous sources. | pip install infermap · npm i infermap |
| goldenmatch-extensions | Rust | Postgres extension (pgrx) + DuckDB UDFs. SQL-native fuzzy matching. | source build |
| dbt-goldencheck | dbt | dbt package — data-quality tests for warehouse models. | dbt deps |
| goldencheck-action | YAML | GitHub Action — fail PRs that introduce data-quality regressions. | Marketplace |
Headline pitch and the deepest docs live in packages/python/goldenmatch/README.md (910 lines, full feature list, CLI, architecture, benchmarks).
Choose your path
| I want to... | Go here |
|---|---|
| Deduplicate a CSV right now | packages/python/goldenmatch |
| Use from Claude Desktop / Code | packages/python/goldenmatch — MCP |
| Edit rules in a browser, label pairs, compare runs | packages/python/goldenmatch — Web UI |
| Build AI agents that deduplicate | ER Agent / A2A wiki page |
| Profile data quality before matching | packages/python/goldencheck |
| Standardize messy fields (phone, date, address) | packages/python/goldenflow |
| Run the full pipeline declaratively | packages/python/goldenpipe |
| Map columns across schemas | packages/python/infermap |
| Write TypeScript / Node.js / Edge | packages/typescript/goldenmatch |
| Match in Postgres / DuckDB SQL | packages/rust/extensions |
| Add data-quality gates to dbt | packages/dbt/goldencheck |
| Block bad data in GitHub PRs | packages/actions/goldencheck |
| Run as Airflow DAGs | examples/airflow/ — 12 drop-in DAGs |
| Run from a single MCP container | docker run ghcr.io/benzsevern/goldensuite-mcp:latest |
| Pull every Suite container | GitHub Packages |
Quick examples
Python — dedupe in 30 seconds
import goldenmatch as gm
# Zero-config
result = gm.dedupe("customers.csv")
print(result) # DedupeResult(records=5000, clusters=847, match_rate=12.0%)
result.golden.write_csv("deduped.csv")
# Or be explicit
result = gm.dedupe("customers.csv",
exact=["email"],
fuzzy={"name": 0.85, "zip": 0.95},
blocking=["zip"],
threshold=0.85)
TypeScript — edge-safe core
import { dedupe } from "goldenmatch";
const result = dedupe(rows, {
fuzzy: { name: 0.85 },
blocking: ["zip"],
threshold: 0.85,
});
console.log(result.stats); // { totalRecords, totalClusters, matchRate, ... }
Runs in browsers, Vercel Edge, Cloudflare Workers, Deno. 478 tests, strict TypeScript (noUncheckedIndexedAccess, exactOptionalPropertyTypes).
Web workbench — browser UI for matching
pip install 'goldenmatch[web]'
goldenmatch serve-ui my-project # opens http://localhost:5050
Edit rules with live validation, preview against a sampled slice, label pairs
(mirrored into Learning Memory automatically), compare runs (CCMS), sweep
parameters, browse the corrections store. Single-process localhost workbench
shipped as the optional [web] extra.
Composed pipeline
import goldenpipe as gp
pipeline = gp.Pipeline.from_yaml("pipeline.yaml") # check → flow → match
result = pipeline.run("customers.csv")
result.report.write_html("report.html")
More: examples/ has runnable demos for every Suite scenario:
Python (quickstart, full pipeline, customer 360, PPRL, review workflow, MCP client) ·
TypeScript (quickstart, Vercel Edge route, MCP client) ·
Airflow DAGs (12 production-shaped pipelines).
Install variants
GoldenMatch ships fat optional extras so you only pay for what you use:
pip install goldenmatch # core (CSV in, CSV out)
pip install goldenmatch[embeddings] # + sentence-transformers, FAISS
pip install goldenmatch[llm] # + Claude / OpenAI for LLM boost
pip install goldenmatch[postgres] # + Postgres sync
pip install goldenmatch[snowflake] # + Snowflake connector
pip install goldenmatch[bigquery] # + BigQuery connector
pip install goldenmatch[databricks] # + Databricks connector
pip install goldenmatch[salesforce] # + Salesforce connector
pip install goldenmatch[duckdb] # + DuckDB out-of-core backend
pip install goldenmatch[ray] # + Ray distributed backend (50M+ rows)
pip install goldenmatch[quality] # + GoldenCheck integration
pip install goldenmatch[transform] # + GoldenFlow integration
pip install goldenmatch[mcp] # + MCP server for Claude Desktop
pip install goldenmatch[agent] # + A2A agent (aiohttp)
pip install goldenmatch[web] # + localhost browser workbench (FastAPI + React)
goldenmatch setup # interactive wizard: GPU, API keys, database
Sister packages compose: pip install goldenpipe[full] brings in Check + Flow + Match together.
Remote MCP Server
GoldenMatch is hosted as an MCP server on Smithery — connect from any MCP client without installing anything.
{
"mcpServers": {
"goldenmatch": {
"url": "https://goldenmatch-mcp-production.up.railway.app/mcp/"
}
}
}
35+ MCP tools across the suite: deduplicate, match, explain, review, link privately, configure, scan quality, transform, synthesize golden records, and manage Learning Memory corrections.
Container images
Every Suite package ships as a multi-arch container image (linux/amd64 + linux/arm64) on GitHub Container Registry. Pull anonymously, no auth needed:
# One container, every Suite tool — the convenience option
docker run -p 8300:8300 ghcr.io/benzsevern/goldensuite-mcp:latest
# Per-package containers — narrower deployments
docker run -p 8200:8200 ghcr.io/benzsevern/goldenmatch-mcp:latest
docker run -p 8100:8100 ghcr.io/benzsevern/goldencheck-mcp:latest
docker run -p 8150:8150 ghcr.io/benzsevern/goldenflow-mcp:latest
docker run -p 8250:8250 ghcr.io/benzsevern/goldenpipe-mcp:latest
docker run -p 8400:8400 ghcr.io/benzsevern/infermap-mcp:latest
# Postgres + extension preinstalled
docker run -e POSTGRES_PASSWORD=secret ghcr.io/benzsevern/goldenmatch-extensions:latest
Tags:
:latest— currentmain:main-<sha7>— every push to main, immutable:vX.Y.Zand:vX.Y— pushed when a<package>-vX.Y.Ztag is created
See packages/python/goldensuite-mcp/README.md for the aggregator's tool-collision behaviour.
Airflow
12 drop-in DAGs at examples/airflow/, grouped by lifecycle stage:
| Group | DAGs |
|---|---|
| Core pipeline | daily_dedupe, incremental_match, warehouse_native (Snowflake), customer_360 (multi-source) |
| Privacy | pprl_linkage (two-party PPRL) |
| Onboarding & monitoring | schema_align_and_load, schema_drift_alarm, quality_gate |
| Feedback loop | review_worker, active_learning |
| Operationalize | reverse_etl (Salesforce/HubSpot), backfill |
TaskFlow API, Airflow 2.7+ (compatible with 3.x). Each DAG has tunable knobs at the top, idempotent retries, and is marker-protected against double-processing. Drop the file you want into your Airflow dags/ folder.
Repository layout
goldenmatch/
├── packages/
│ ├── python/
│ │ ├── goldenmatch/ # entity resolution — headline package
│ │ ├── goldencheck/ # data quality scanning
│ │ ├── goldenflow/ # transforms & standardizers
│ │ ├── goldenpipe/ # orchestrator
│ │ └── infermap/ # schema mapping
│ ├── typescript/
│ │ ├── goldenmatch/ # full TS port (edge-safe core)
│ │ ├── goldencheck/ # TS implementation
│ │ ├── goldencheck-types/ # shared TS types
│ │ ├── goldenflow/ # TS transforms
│ │ └── infermap/ # TS schema mapping
│ ├── rust/
│ │ └── extensions/ # Postgres pgrx + DuckDB UDFs (own Cargo workspace)
│ ├── python/goldensuite-mcp/ # aggregator MCP server (one container, all tools)
│ ├── dbt/goldencheck/ # dbt package
│ └── actions/goldencheck/ # GitHub Action
├── examples/
│ ├── python/ # 6 runnable Python scripts (quickstart → MCP)
│ ├── typescript/ # 3 TS scripts (quickstart, Vercel Edge, MCP)
│ └── airflow/ # 12 drop-in Airflow DAGs
├── docs/superpowers/ # design specs and implementation plans
├── justfile # install / test / lint / build, all languages
├── pyproject.toml # uv workspace (root)
├── package.json # per-package npm (Windows-symlink-safe; no root workspace)
└── .github/workflows/ci.yml
Why no root Cargo or npm workspace?
- Cargo:
packages/rust/extensions/is itself a Cargo workspace (thepostgrescrate is excluded for pgrx-specific build requirements). Cargo doesn't allow nested workspaces sharing members. Cargo commands run from insidepackages/rust/extensions/. - npm: A real npm workspace causes Windows symlink issues for some users. Each TypeScript package installs independently. The root
package.jsonprovides convenience scripts (install:all,test:all,build:all) but isn't a workspace.
Build / test / lint everything
just install # uv sync + per-package npm install + cargo fetch
just test # all languages
just lint
just build
Reproducing benchmarks
Published GoldenMatch numbers (DQbench composite 91.04, DBLP-ACM 0.9641 F1, Febrl3 0.9443 F1, NCVR 0.9719 F1) map back to a single committed runner: scripts/run_benchmarks.py. See docs/reproducing-benchmarks.md for per-number commands, dataset URLs, expected output (with tolerance), variance notes (deterministic vs LLM-augmented), and a copy-pasteable one-click reproduction snippet for the DQbench composite. The same runner powers the weekly benchmarks.yml workflow.
Scale envelope
"How big can this handle?" is answered in docs/scale-envelope.md: per-backend ranges (Polars in-memory < 500K, DuckDB out-of-core 500K - 50M, Ray distributed >= 50M), block-size failure modes, candidate-pair math, and a single-page decision tree for picking a backend.
Contributing
- Feature work goes on
feature/<name>branches; merge via squash PR. - PR title format:
feat: <description>,fix: <description>,docs: <description>. - Tests must pass on all three languages where the change applies; the parity harness in
packages/typescript/goldenmatch/tests/parity/enforces 4-decimal-tolerance Python ↔ TypeScript scorer parity. - See
docs/superpowers/specs/for design rationale on architectural decisions.
TypeScript dev setup (pnpm + Turborepo)
The TypeScript packages live in a single pnpm workspace orchestrated by Turborepo. From the repo root:
corepack enable # one-time, picks up [email protected] from package.json
pnpm install # installs all workspace packages
pnpm turbo run build test typecheck lint # full pipeline (cached after first run)
pnpm --filter goldenmatch test # single package
Windows: enable Developer Mode for pnpm. pnpm install creates symlinks under node_modules/. Settings → For Developers → Developer Mode → On. If you see EPERM: operation not permitted, symlink ... during install, Dev Mode is off.
If corepack enable fails (often needs an admin shell on Windows), the fallback is npm i -g [email protected] — functionally equivalent.
History
This repository was formed on 2026-05-01 by folding 8 sibling repos into the existing goldenmatch repo using git filter-repo. Full commit history is preserved for every source. See docs/superpowers/specs/2026-05-01-goldenmatch-monorepo-fold-in-design.md for the design rationale and docs/superpowers/plans/2026-05-01-goldenmatch-monorepo-fold-in.md for the step-by-step migration plan.
Author & License
Built by Ben Severn.
MIT — see LICENSE.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found