quorum
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 7 GitHub stars
Code Fail
- execSync — Synchronous shell command execution in daemon/components/AgentChatPanel.tsx
Permissions Pass
- Permissions — No dangerous permissions requested
This tool enforces a consensus protocol between multiple AI models, ensuring that code written by one model must be reviewed and approved by an independent AI before it can be committed.
Security Assessment
The tool poses a Medium overall security risk. It uses the permissive MIT license and does not request dangerous account permissions or contain hardcoded secrets. However, the codebase does execute synchronous shell commands (specifically within the `daemon/components/AgentChatPanel.tsx` file). While this is standard for orchestrating AI processes and running local CLI commands, executing shell instructions always warrants caution. Users should inspect exactly what system commands are being run to prevent unintended local system changes.
Quality Assessment
The project demonstrates strong technical foundations and high internal quality, boasting an impressive 743 automated tests and continuous integration workflows. It is actively maintained, with repository activity as recent as today. However, the project suffers from extremely low community visibility. Having only 7 GitHub stars means the codebase has not been widely peer-reviewed or battle-tested by the broader development community. As a result, community trust and reliance should be considered extremely early-stage.
Verdict
Use with caution: the tool is well-tested and actively maintained, but the low community adoption and presence of shell execution require you to review the code locally before integrating it into sensitive environments.
Cross-model audit gate with autonomous quality loop — AST hybrid scanning, fitness gate, blast radius, structured orchestration. 19 MCP tools, 743 tests. CLI + Claude Code plugin.
quorum
![]()
![]()

Cross-model audit gate with structural enforcement. One model cannot approve its own code.
edit → audit → agree → retro → commit
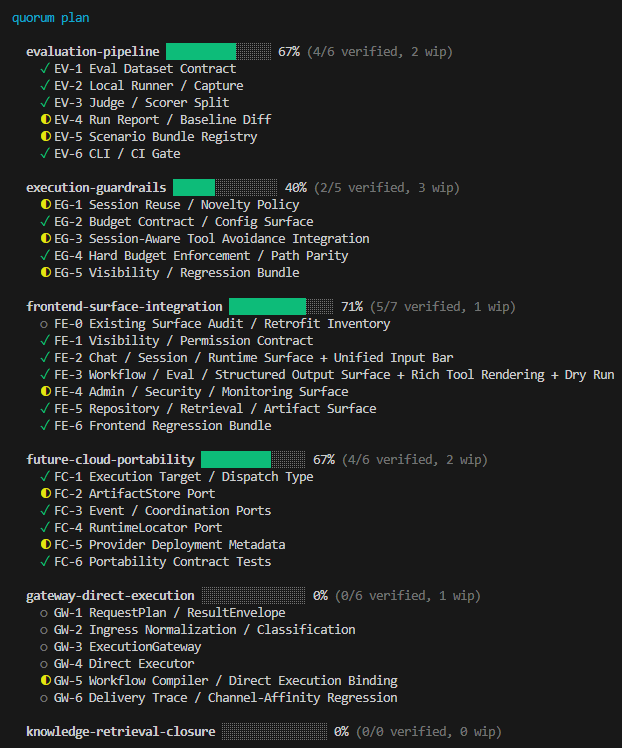
What it does
quorum enforces a consensus protocol between AI agents. When code is written, an independent auditor reviews the evidence. If rejected, the author must fix and resubmit. The cycle repeats until consensus is reached — only then can the code be committed.
The key principle: no single model can both write and approve code. This is the "quorum" — a minimum number of independent voices required for a decision.
Installation
Standalone (any AI tool)
quorum works without any IDE plugin. Just the CLI.
npm install -g quorum-audit # global install
# or
npx quorum-audit setup # one-shot without install
cd your-project
quorum setup # creates config + MCP server registration
quorum daemon # TUI dashboard
Works with any AI coding tool — Claude Code, Codex, Gemini, or manual use.
As a Claude Code plugin
For automatic hook integration (event-driven audit on every edit):
claude plugin marketplace add berrzebb/quorum
claude plugin install quorum@berrzebb-plugins
This registers 22 lifecycle hooks, 26 MCP tools, 29 skills, and 13 specialist agents automatically. The CLI still works alongside the plugin.
As a Gemini CLI extension
For automatic hook integration with Gemini CLI:
gemini extensions install https://github.com/berrzebb/quorum.git
# or for development:
gemini extensions link adapters/gemini
This registers 11 hooks, 33 skills, 4 commands, and 26 MCP tools. Same audit engine as Claude Code.
As a Codex CLI hook
For automatic hook integration with OpenAI Codex CLI:
# Copy hooks config to project
cp platform/adapters/codex/hooks/hooks.json .codex/hooks.json
# Enable hooks feature flag
codex -c features.codex_hooks=true
This registers 5 hooks (SessionStart, Stop, UserPromptSubmit, AfterAgent, AfterToolUse). Same audit engine as Claude Code and Gemini.
From source
git clone https://github.com/berrzebb/quorum.git
cd quorum && npm install && npm run build
npm link # makes 'quorum' available globally
CLI
quorum <command>
setup Initialize quorum in current project
interview Interactive requirement clarification
daemon Start TUI dashboard
status Show audit gate status
audit Trigger manual audit
plan Work breakdown planning
orchestrate Track orchestration (parallel execution) # v0.4.0
ask <provider> Query a provider directly
tool <name> Run MCP analysis tool
migrate Import consensus-loop data into quorum
help Show help
Migrating from consensus-loop
If you were using consensus-loop (v2.5.0), quorum can import your existing data:
quorum migrate # import config, audit history, session state
quorum migrate --dry-run # preview without changes
What it migrates:
| Data | From | To |
|---|---|---|
| Config | .claude/consensus-loop/config.json |
.claude/quorum/config.json |
| Audit history | .claude/audit-history.jsonl |
SQLite EventStore |
| Session state | .session-state/retro-marker.json |
Preserved (shared location) |
| Evidence submission | docs/feedback/claude.md |
audit_submit MCP tool |
| MCP server | .mcp.json consensus-loop entry |
Cloned as quorum entry |
Your existing evidence is preserved — quorum reads from SQLite via audit_submit tool.
How it works
Without a plugin (standalone)
you write code
→ quorum audit # trigger manually
→ auditor reviews # Codex, GPT, Claude, or any provider
→ quorum status # check verdict
→ fix if rejected # resubmit
→ quorum daemon # watch the cycle in real-time TUI
With Claude Code plugin (automatic)
you write code
→ PostToolUse hook fires # automatic
→ regex scan + AST refine # hybrid: false positive removal
→ fitness score computed # 7-component quality metric
→ fitness gate # auto-reject / self-correct / proceed
→ trigger eval (13 factors)# skip, simple, or deliberative
→ auditor runs # background, debounced
→ verdict syncs # tag promotion/demotion
→ session-gate # blocks until retro complete
→ commit allowed
Both paths use the same core engine: platform/bus/ + platform/providers/ + platform/core/.
Architecture
quorum/
├── platform/ ← All source code (7 layers)
│ ├── cli/ ← unified entry point (works without any plugin)
│ ├── orchestrate/ ← 5-layer orchestration (planning/execution/governance/state/core)
│ ├── bus/ ← EventStore (SQLite) + pub/sub + stagnation + LockService + Fitness + Claims + Parliament
│ ├── providers/ ← consensus protocol + trigger (13-factor) + router + evaluators + AST analyzer
│ ├── core/ ← audit protocol (7 modules), templates, 26 MCP tools, harness contracts
│ ├── skills/ ← 36 canonical skill definitions (protocol-neutral)
│ └── adapters/
│ ├── shared/ ← adapter-agnostic business logic (20 modules, incl. HookRunner, NDJSON, MuxAdapter)
│ ├── claude-code/ ← Claude Code hooks (22) + agents (13) + skills (29) + commands (10)
│ ├── gemini/ ← Gemini CLI hooks (11) + skills (33) + commands (4)
│ ├── codex/ ← Codex CLI hooks (5) + skills (33)
│ └── openai-compatible/ ← OpenAI-compatible agents (13) + skills (33)
├── daemon/ ← Ink TUI dashboard + FitnessPanel (works standalone)
└── agents/knowledge/ ← shared agent protocols (cross-adapter: implementer, scout, 11 specialist domains)
The platform/adapters/ layer is optional. Everything above it runs independently. Adding a new adapter requires only I/O wrappers — business logic is in platform/adapters/shared/.
Core Concepts
Parliament Protocol
Legislative deliberation framework for structured consensus:
quorum parliament "topic" → CPS (Context-Problem-Solution)
quorum orchestrate plan <track> → interactive planner (Socratic + CPS)
quorum orchestrate run <track> → Wave-based execution (auto)
quorum orchestrate run <track> --resume → resume from last checkpoint
Wave-based Execution
orchestrate run은 작업을 Wave 단위로 실행합니다:
- Phase 게이트가 경계를 정의 (Phase N 완료 후 Phase N+1 시작)
- Phase 내부는
dependsOn기반 위상 정렬로 sub-wave 생성 - Wave 내 항목은
--concurrency N(기본 3) 만큼 병렬 실행 - Wave 완료 → 단일 감사 → 실패 시 Fixer 에이전트가 타겟 수정 → 재감사
--resume플래그로 중단된 지점부터 재개 (컴퓨터 종료에도 생존)
Enforcement Gates
8 gates that block progress until conditions are met (not just document — code enforces):
| Gate | Blocks when | Releases when |
|---|---|---|
| Audit | Evidence submitted | Auditor approves |
| Retro | Audit approved | Retrospective complete |
| Quality | Lint/test fails | All checks pass |
| Amendment | Pending amendments | All resolved (vote) |
| Verdict | Last verdict ≠ approved | Re-audit passes |
| Confluence | Integrity check failed | 4-point verification passes |
| Design | Design artifacts missing | Spec + Blueprint exist |
| Regression | Normal-form stage regressed | Alert only |
Deliberative Consensus
For complex changes (T3), a 3-role protocol runs:
- Advocate: finds merit in the submission
- Devil's Advocate: challenges assumptions, checks root cause vs symptom
- Judge: weighs both opinions, delivers final verdict
Language Spec Fragments (v0.4.1)
Quality patterns are defined per language in pluggable fragment files:
platform/core/languages/typescript/
spec.mjs ← core: id, name, extensions (3 lines)
spec.symbols.mjs ← symbol extraction patterns
spec.imports.mjs ← dependency parsing
spec.perf.mjs ← performance anti-patterns
spec.a11y.mjs ← accessibility patterns
spec.observability.mjs
spec.compat.mjs
spec.doc.mjs ← documentation coverage
Adding a new language = spec.mjs (3 lines) + relevant fragments. Adding a domain to an existing language = one new fragment file. The registry (platform/core/languages/registry.mjs) auto-discovers and merges fragments at load time.
Domain Specialists (v0.3.0)
When changes touch specialized domains, quorum conditionally activates expert reviewers:
| Domain | Tool | Agent | Min Tier |
|---|---|---|---|
| Performance | perf_scan |
perf-analyst | T2 |
| Migration | compat_check |
compat-reviewer | T2 |
| Accessibility | a11y_scan |
a11y-auditor | T2 |
| Compliance | license_scan |
compliance-officer | T2 |
| i18n | i18n_validate |
— | T2 |
| Infrastructure | infra_scan |
— | T2 |
| Observability | observability_check |
— | T3 |
| Documentation | doc_coverage |
— | T3 |
| Concurrency | — | concurrency-verifier | T3 |
Tools are deterministic (zero cost, always run). Agents are LLM-powered (only at sufficient tier).
Hybrid Scanning
Pattern scanning uses a 3-layer defense against false positives:
- Regex first pass — fast (<1ms/file), catches candidates
- scan-ignore pragma —
// scan-ignoresuppresses self-referential matches - AST second pass — precise (<50ms/file), removes comment/string matches, analyzes control flow
The perf_scan tool uses hybrid scanning: regex detects while(true), AST verifies if break/return exists.
Program mode (ts.createProgram()) enables cross-file analysis: unused export detection and import cycle detection via dependency graph DFS.
Fitness Score Engine
Inspired by Karpathy's autoresearch: what is measurable is not asked to the LLM.
Seven components combine into a 0.0–1.0 fitness score:
| Component | Weight | Input |
|---|---|---|
| Type Safety | 0.20 | as any count per KLOC |
| Test Coverage | 0.20 | Line + branch coverage |
| Pattern Scan | 0.20 | HIGH-severity findings |
| Build Health | 0.15 | tsc + eslint pass rate |
| Complexity | 0.10 | Avg cyclomatic complexity |
| Security | 0.10 | Vulnerability findings |
| Dependencies | 0.05 | Outdated/vulnerable deps |
The FitnessLoop gates LLM audit with 3 decisions:
- auto-reject: score drop >0.15 or absolute <0.3 → skip LLM audit (cost savings)
- self-correct: mild drop (0.05–0.15) → warn agent, continue
- proceed: stable/improved → update baseline, continue to audit
Conditional Trigger
Not every change needs full consensus. A 13-factor scoring system (6 base + domain + plan + fitness + blast radius + velocity + stagnation + interaction multipliers) determines the audit level:
| Tier | Score | Mode |
|---|---|---|
| T1 | < 0.3 | Skip (micro change) |
| T2 | 0.3–0.7 | Simple (single auditor) |
| T3 | > 0.7 | Deliberative (3-role) |
3-Layer Adapter Pattern (v0.4.2)
Shared business logic across adapters. Only I/O differs per runtime:
I/O (platform/adapters/{adapter}/)
Claude Code: hookSpecificOutput, permissionDecision
Gemini CLI: JSON-only stdout, hookSpecificOutput
Codex CLI: .codex/hooks.json, config.toml
↓ readStdinJson() + withBridge() + createHookContext()
Business Logic (platform/adapters/shared/ — 17 modules)
hook-runner, hook-loader, trigger-runner, ndjson-parser,
cli-adapter, mux-adapter, jsonrpc-client, sdk-tool-bridge, ...
↓ bridge.init() + bridge.checkHookGate()
Core (platform/core/)
audit, tools (26 MCP), EventStore, bus, providers
Adding a new adapter requires ~280 lines (proven by the Codex adapter).
HookRunner Engine (v0.4.2)
User-defined hooks. Configure in config.json or HOOK.md:
// .claude/quorum/config.json
{
"hooks": {
"audit.submit": [
{ "name": "freeze-guard", "handler": { "type": "command", "command": "node scripts/check-freeze.mjs" } }
]
}
}
command/http handlers, env interpolation ($VAR, ${VAR}), deny-first-break, async fire-and-forget, regex matcher filtering.
Multi-Model NDJSON Protocol (v0.4.2)
Unified parsing of 3 CLI runtime outputs:
| Runtime | Format | Adapter |
|---|---|---|
| Claude Code | stream-json |
ClaudeCliAdapter |
| Codex | exec --json |
CodexCliAdapter |
| Gemini | stream-json |
GeminiCliAdapter |
All outputs are normalized to AgentOutputMessage (assistant_chunk, tool_use, tool_result, complete, error). MuxAdapter bridges ProcessMux (tmux/psmux) sessions for real-time cross-model consensus.
Stagnation Detection
If the audit loop cycles without progress, 7 patterns are detected:
- Spinning: same verdict 3+ times
- Oscillation: approve → reject → approve → reject
- No drift: identical rejection codes repeating
- Diminishing returns: improvement rate declining
- Fitness plateau: fitness score slope ≈ 0 over last N evaluations
- Expansion: scope creep — more files touched each round
- Consensus divergence: advocate/devil opinions drifting apart
Blast Radius Analysis (v0.4.0)
BFS on the reverse import graph computes transitive dependents of changed files:
quorum tool blast_radius --changed_files '["platform/core/bridge.mjs"]'
# → 12/95 files affected (12.6%) — depth-sorted impact list
- 10th trigger factor: ratio > 10% → score += up to 0.15 (auto-escalation to T3)
- Pre-verify evidence: blast radius section included in auditor evidence
- Reuses
buildRawGraph()extracted fromdependency_graph(TTL-cached)
Structured Orchestration (v0.4.0)
Multi-agent coordination for parallel worktree execution:
| Component | Purpose |
|---|---|
| ClaimService | Per-file ownership (INSERT...ON CONFLICT), TTL-based expiry |
| ParallelPlanner | Graph coloring for conflict-free execution groups |
| OrchestratorMode | Auto-selects: serial / parallel / fan-out / pipeline / hybrid |
| Auto-learning | Detects repeat rejection patterns (3+), suggests CLAUDE.md rules |
Event Reactor (v0.4.0)
respond.mjs rewritten as a pure event reactor: reads SQLite verdict events → executes side-effects only. No markdown read/write. -1043/+211 lines refactoring.
Dynamic Escalation
The tier router tracks failure history per task:
- 2 consecutive failures → escalate to higher tier
- 2 consecutive successes → downgrade back
- Frontier failures → stagnation signal
Planner Documents
The planner skill produces 10 document types for structured project planning:
| Document | Level | Purpose |
|---|---|---|
| PRD | Project | Product requirements — problem, goals, features, acceptance criteria |
| Execution Order | Project | Track dependency graph — which tracks to execute first |
| Work Catalog | Project | All tasks across all tracks with status and priority |
| ADR | Project | Architecture Decision Records — why, not just what |
| Track README | Track | Track scope, goals, success criteria, constraints |
| Work Breakdown | Track | Task decomposition — ### [task-id] blocks with depends_on/blocks |
| API Contract | Track | Endpoint specs, request/response schemas, auth |
| Test Strategy | Track | Test plan — unit/integration/e2e scope, coverage targets |
| UI Spec | Track | Component hierarchy, states, interactions |
| Data Model | Track | Entity relationships, schemas, migrations |
Providers
quorum is provider-agnostic. Bring your own auditor.
| Provider | Mechanism | Hooks | Plugin needed? |
|---|---|---|---|
| Claude Code | 22 native hooks | SessionStart, PreToolUse, PostToolUse, Stop, PermissionRequest, Notification, ... | Optional (auto-triggers) |
| Gemini CLI | 11 hooks + 33 skills | SessionStart, BeforeAgent, AfterAgent, BeforeTool, AfterTool, BeforeModel, ... | Optional (gemini extensions install) |
| Codex CLI | 5 hooks | SessionStart, Stop, UserPromptSubmit, AfterAgent, AfterToolUse | Optional (.codex/hooks.json) |
| Manual | quorum audit |
— | No |
Tools & Verification
Deterministic tools that replace LLM judgment with facts. No hallucination possible.
Analysis tools (19):
# Core analysis
quorum tool code_map src/ # symbol index
quorum tool dependency_graph . # import DAG, cycles
quorum tool blast_radius --changed_files '["src/api.ts"]' # transitive impact (v0.4.0)
quorum tool audit_scan src/ # type-safety, hardcoded patterns
quorum tool coverage_map # per-file test coverage
quorum tool audit_history --summary # verdict patterns
quorum tool ai_guide # context-aware onboarding (v0.4.0)
# RTM & verification
quorum tool rtm_parse docs/rtm.md # parse RTM → structured rows
quorum tool rtm_merge --base a --updates '["b"]' # merge worktree RTMs
quorum tool fvm_generate /project # FE×API×BE access matrix
quorum tool fvm_validate --fvm_path x --base_url http://localhost:3000 --credentials '{}'
# Domain specialists (v0.3.0)
quorum tool perf_scan src/ # performance anti-patterns (hybrid: regex+AST)
quorum tool compat_check src/ # API breaking changes
quorum tool a11y_scan src/ # accessibility (JSX/TSX)
quorum tool license_scan . # license compliance + PII
quorum tool i18n_validate . # locale key parity
quorum tool infra_scan . # Dockerfile/CI security
quorum tool observability_check src/ # empty catch, logging gaps
quorum tool doc_coverage src/ # JSDoc coverage %
Verification pipeline (quorum verify):
quorum verify # all checks
quorum verify CQ # code quality (eslint)
quorum verify SEC # OWASP security (10 patterns, semgrep if available)
quorum verify LEAK # secrets in git (gitleaks if available, built-in fallback)
quorum verify DEP # dependency vulnerabilities (npm audit)
quorum verify SCOPE # diff vs evidence match
Full reference: docs/TOOLS.md | docs/ko-KR/TOOLS.md
Tests
npm test # 3030 tests
npm run typecheck # TypeScript check
npm run build # compile
CI/CD
GitHub Actions builds cross-platform binaries on tag push:
git tag v0.5.0
git push origin v0.5.0
# → linux-x64, darwin-x64, darwin-arm64, win-x64 binaries in Releases
License
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found