gcf
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Warn
- network request — Outbound network request in docs/pnpm-lock.yaml
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
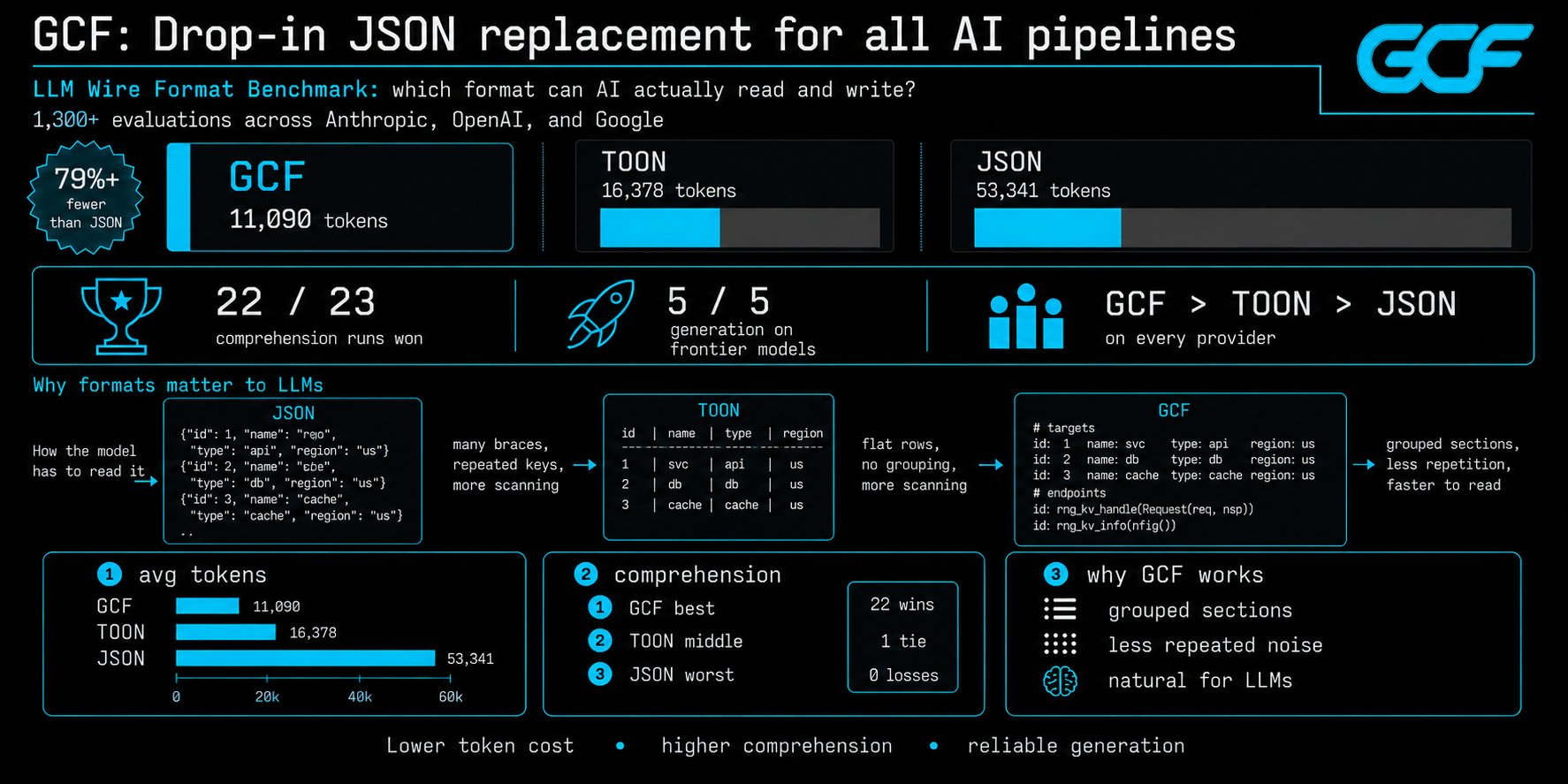
Drop-in JSON replacement for all AI pipelines. 79% fewer tokens. JSON scores 53.6% comprehension at scale, GCF scores 90.5%. Superpowers for graph-shaped data.
![]()
Drop-in JSON replacement for all AI pipelines, with superpowers for graph-shaped data.
[!IMPORTANT]
Graph Compact Format (GCF): A Token-Efficient Wire Format for LLM Tool Interactions
Dayna Blackwell, 2026. DOI: 10.5281/zenodo.20579817
79% fewer input tokens than JSON. 63% fewer output tokens. 90.7% average comprehension accuracy across 10 models and 3 providers (four models hit 100%). 1,300+ LLM evaluations. Zero training.
Encode any JSON payload as GCF before sending it to an LLM. Arrays, nested objects, key-value pairs, mixed types. The model reads it natively with zero format instructions. decode() converts back to JSON when a human needs to see it.
pip install gcf-python # Python
npm install @blackwell-systems/gcf # TypeScript
go get github.com/blackwell-systems/gcf-go # Go
cargo add gcf # Rust
Or wrap any existing MCP server with zero code changes:
pip install gcf-proxy
Benchmarks
1,300+ LLM evaluations across 10 models, 3 providers, and 51 independent test runs.
| GCF | TOON | JSON | |
|---|---|---|---|
| Comprehension (23 runs, 10 models) | 90.7% | 68.5% | 53.6% |
| Generation (28 runs, 9 models) | 5/5 | 1.0/5 | 5.0/5 |
| Input tokens (500 symbols) | 11,090 | 16,378 | 53,341 |
| Output tokens (100 symbols) | 5,976 | 8,937 | 16,121 |
GCF wins all 6 datasets on TOON's own benchmark. Full results: gcformat.com/guide/benchmarks
Encode any structured data (generic profile)
from gcf import encode_generic
output = encode_generic({
"employees": [
{"id": 1, "name": "Alice", "department": "Engineering", "salary": 95000},
{"id": 2, "name": "Bob", "department": "Sales", "salary": 72000},
{"id": 3, "name": "Carol", "department": "Marketing", "salary": 85000},
],
})
## employees [3]{id,name,department,salary}
1|Alice|Engineering|95000
2|Bob|Sales|72000
3|Carol|Marketing|85000
One header declares field names. Rows are positional values only. No field names repeated per record. Works on any JSON.
Graph profile (code intelligence, knowledge graphs, MCP tools)
For data with nodes, edges, and distance groups:
from gcf import encode, Payload, Symbol, Edge
output = encode(Payload(
tool="context_for_task", token_budget=5000, tokens_used=1847,
symbols=[
Symbol(qualified_name="pkg.Auth", kind="function", score=0.78, provenance="lsp", distance=0),
Symbol(qualified_name="pkg.Server", kind="function", score=0.54, provenance="lsp", distance=1),
],
edges=[Edge(source="pkg.Server", target="pkg.Auth", edge_type="calls")],
))
GCF tool=context_for_task budget=5000 tokens=1847 symbols=2 edges=1
## targets
@0 fn pkg.Auth 0.78 lsp
## related
@1 fn pkg.Server 0.54 lsp
## edges [1]
@0<@1 calls
Local IDs (@0, @1) replace full names in edges. 233 tokens instead of 965 for JSON.
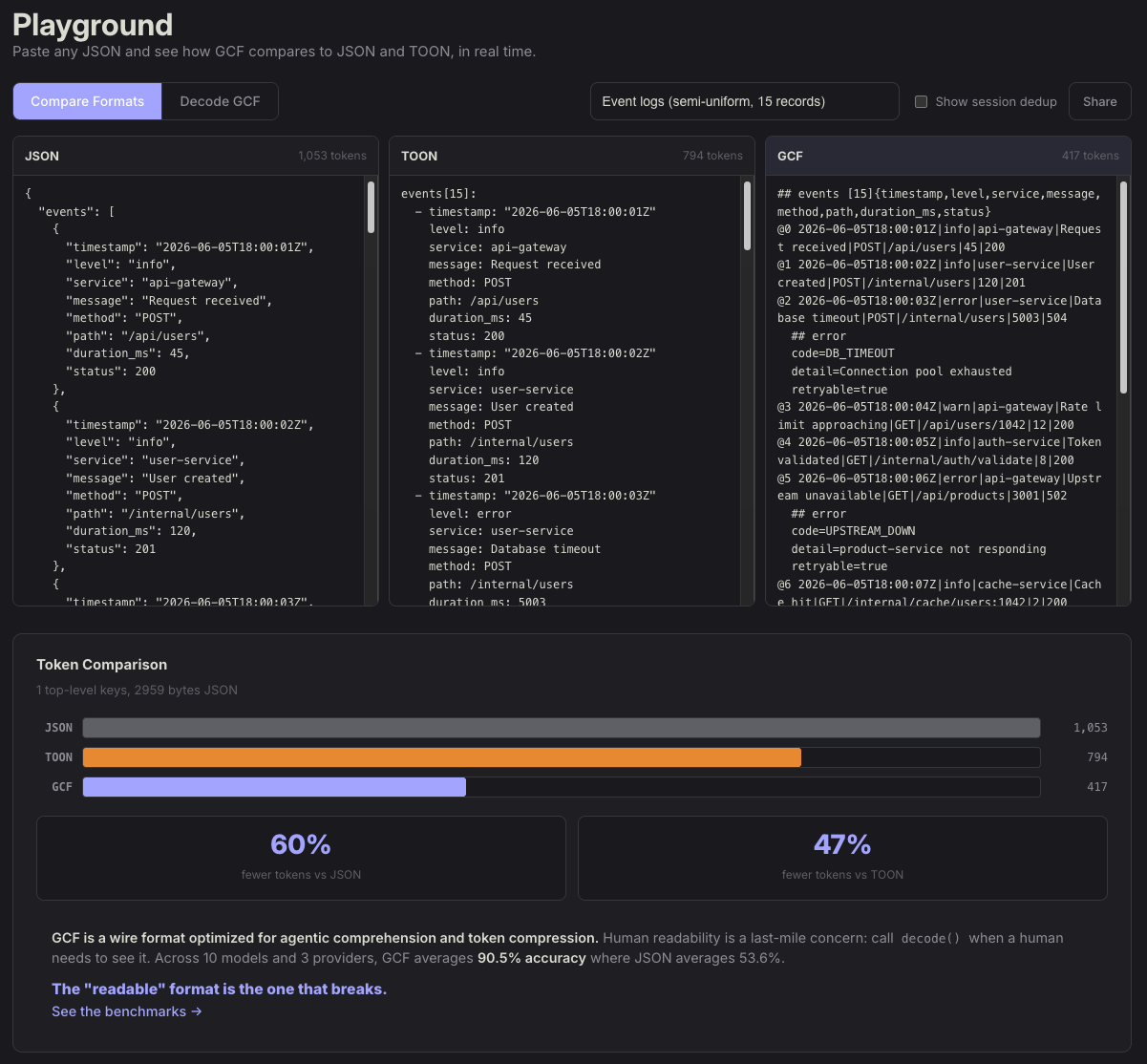
Try it live in the playground with real-time three-way comparison (JSON vs TOON vs GCF).
How it works
Generic profile
Encodes any JSON structure. Arrays, nested objects, mixed types, primitives.
- Arrays of objects.
## name [count]{field1,field2}declares field names once. Rows are pipe-separated values. Field names are never repeated per record. - Nested objects.
## addressbecomes a section. Fields inside arekey=valuepairs or further nested sections. - Primitive arrays. Inlined:
tags[2]: admin,user. No wrapping structure. - Scalars.
key=valueat the top level. Nulls, booleans, and numbers are preserved as-is.
Graph profile
- Positional fields. One header declares field names. Rows are values only.
- Local IDs.
@0,@1. Edges reference by ID, not by repeating full identifiers. - Hierarchical grouping. Section headers (
## targets,## related) replace per-record metadata.
Both profiles share the same grammar. The savings are structural and grow with payload size.
It gets cheaper over time
Session deduplication: Symbols sent in prior responses become bare references. By the 5th tool call: 92.7% savings vs JSON.
Delta encoding: When the context changes slightly between queries, send only the diff. 81.2% additional savings on re-queries.
No other format has these. They compound across multi-turn agent interactions.
Implementations
| Language | Package | Repository |
|---|---|---|
| Go | go get github.com/blackwell-systems/gcf-go |
gcf-go |
| TypeScript | npm install @blackwell-systems/gcf |
gcf-typescript |
| Python | pip install gcf-python |
gcf-python |
| Rust | cargo add gcf |
gcf-rust |
| Swift | Swift Package Manager | gcf-swift |
| Kotlin | JitPack | gcf-kotlin |
| MCP Proxy | pip install gcf-proxy |
gcf-proxy |
| Tree-sitter | npm install tree-sitter-gcf |
tree-sitter-gcf |
Zero runtime dependencies. MIT licensed. All implementations support both generic profile (encodeGeneric) and graph profile (encode). CLI included in Go, TypeScript, and Python. Syntax highlighting via tree-sitter (Neovim, Helix, Zed).
Documentation
Use cases
- MCP tool responses. Any MCP server returning structured data. 79% fewer tokens with better comprehension accuracy.
- Agent-to-agent communication. 63% fewer tokens per handoff. 5/5 generation validity on every frontier model.
- LLM structured output. LLMs produce valid GCF with a 3-line primer. No training required.
- Code intelligence. Graph profile with local IDs, edges, and distance grouping.
License
MIT - Dayna Blackwell
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found