meta-kb
Health Gecti
- License — License: NOASSERTION
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 11 GitHub stars
Code Uyari
- network request — Outbound network request in scripts/ingest-article.ts
- network request — Outbound network request in scripts/ingest-arxiv.ts
- network request — Outbound network request in scripts/ingest-twitter.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
This project is a self-improving knowledge base and compilation pipeline that uses LLMs to synthesize markdown wikis about large language model systems. It evaluates raw data to generate and maintain a comprehensive repository of articles and claims.
Security Assessment
The overall risk is Low. The tool does not request dangerous system permissions, execute hidden shell commands, or contain hardcoded secrets. The scan did flag several outbound network requests within the ingestion scripts (specifically for Twitter, arXiv, and general articles). However, these network calls are entirely expected and safe given the tool's stated purpose of fetching external sources and cloning repositories to compile its wiki.
Quality Assessment
The project appears to be actively maintained, with its most recent push occurring today. While the automated license check returned a "NOASSERTION" status, the README explicitly states that the code is covered by the MIT license and the wiki content by CC BY-SA 4.0. Community trust is modest but present at 11 GitHub stars, which is reasonable for a highly specialized, experimental agent pipeline.
Verdict
Safe to use.
A self-improving LLM knowledge base about self-improving LLM knowledge bases
meta-kb
A self-improving LLM knowledge base about self-improving LLM knowledge systems.

Browse the wiki
Start here: The Landscape of LLM Knowledge Systems
| The State of LLM Knowledge Bases | The State of Agent Memory |
| The State of Context Engineering | The State of Agent Systems |
| The State of Self-Improving Systems | Landscape Comparison Table |
| Knowledge Graph | Compilation Pipeline |
|---|---|
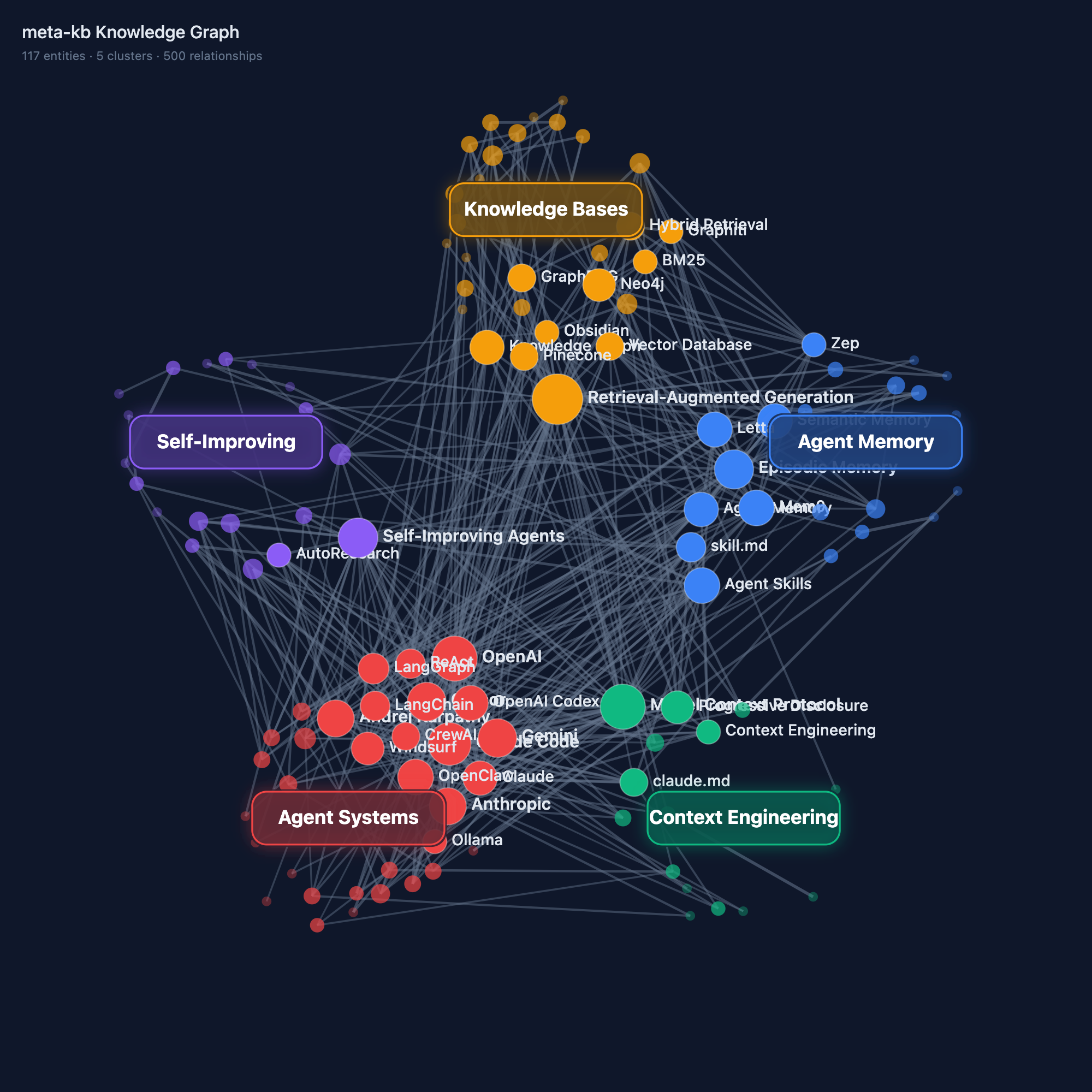 |
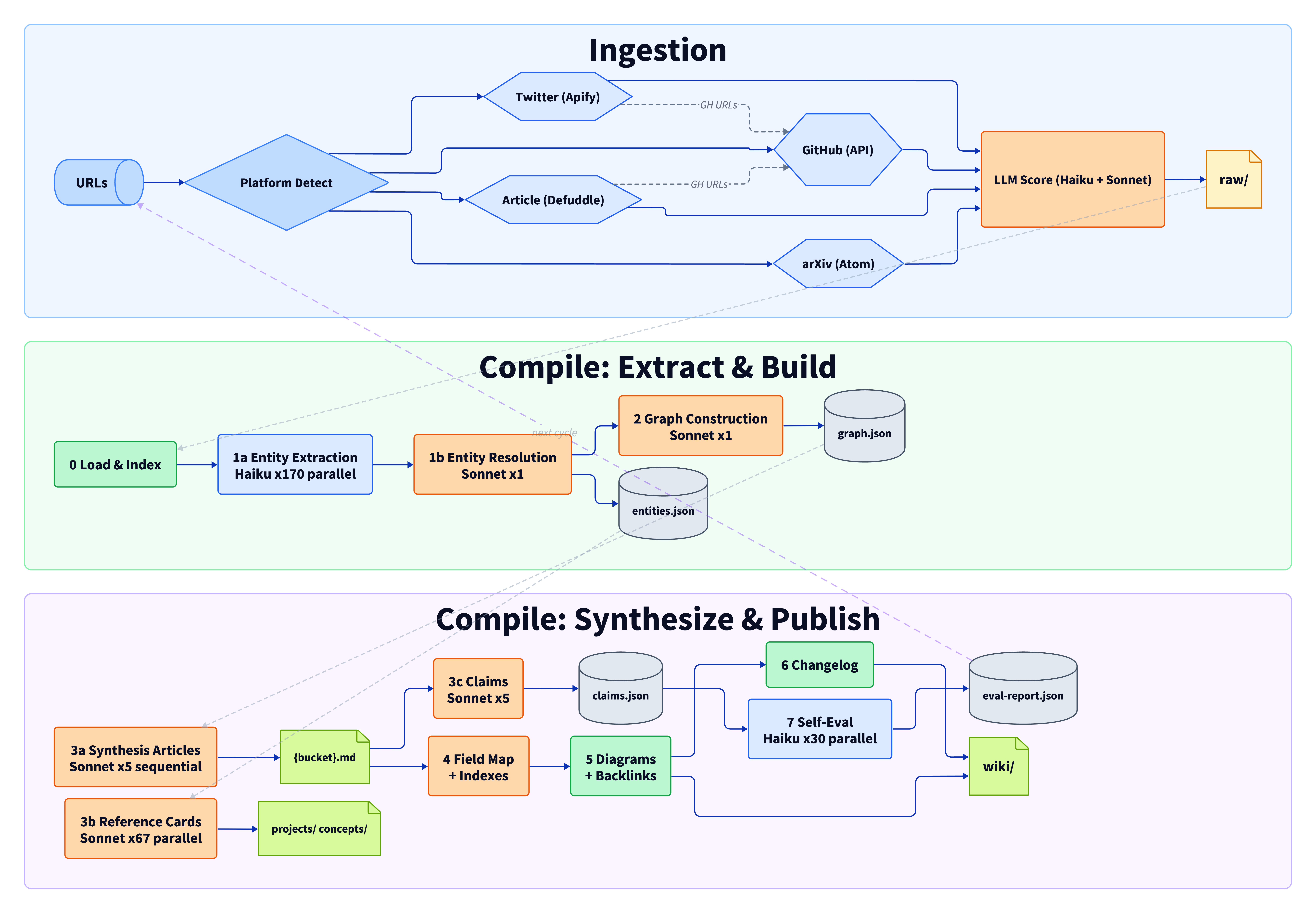 |
How it works
Inspired by Andrej Karpathy's tweet about using LLMs to compile and maintain markdown wikis from raw sources. This repo applies that pattern to the topic of LLM knowledge systems itself, then adds a self-improvement loop. The repo IS the demo.
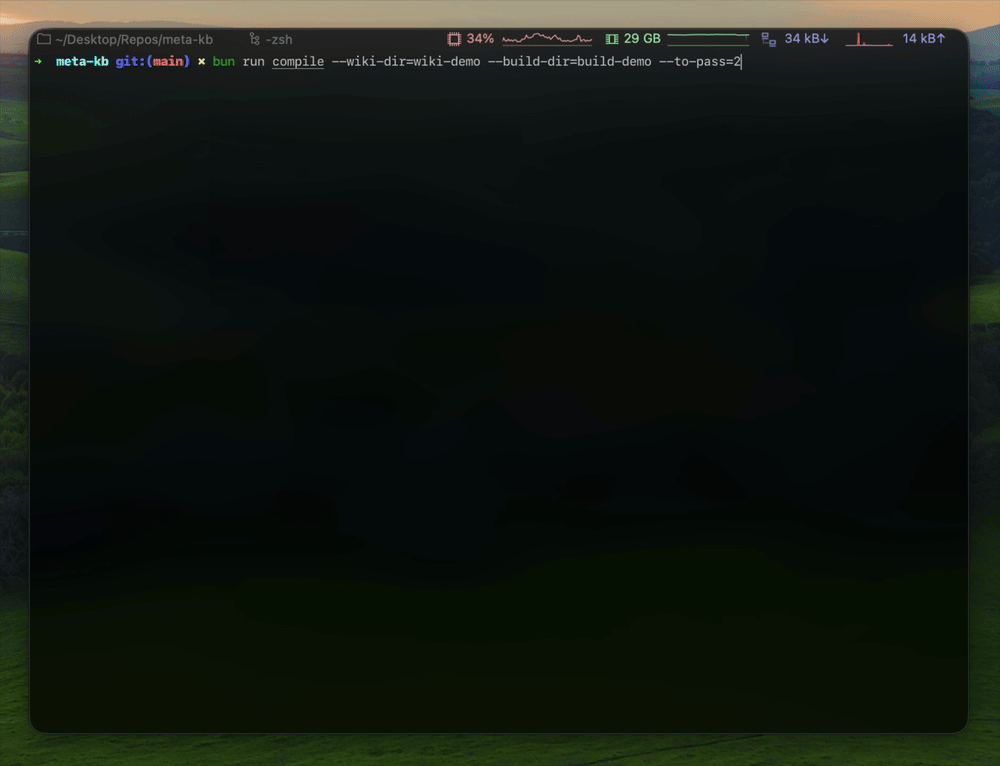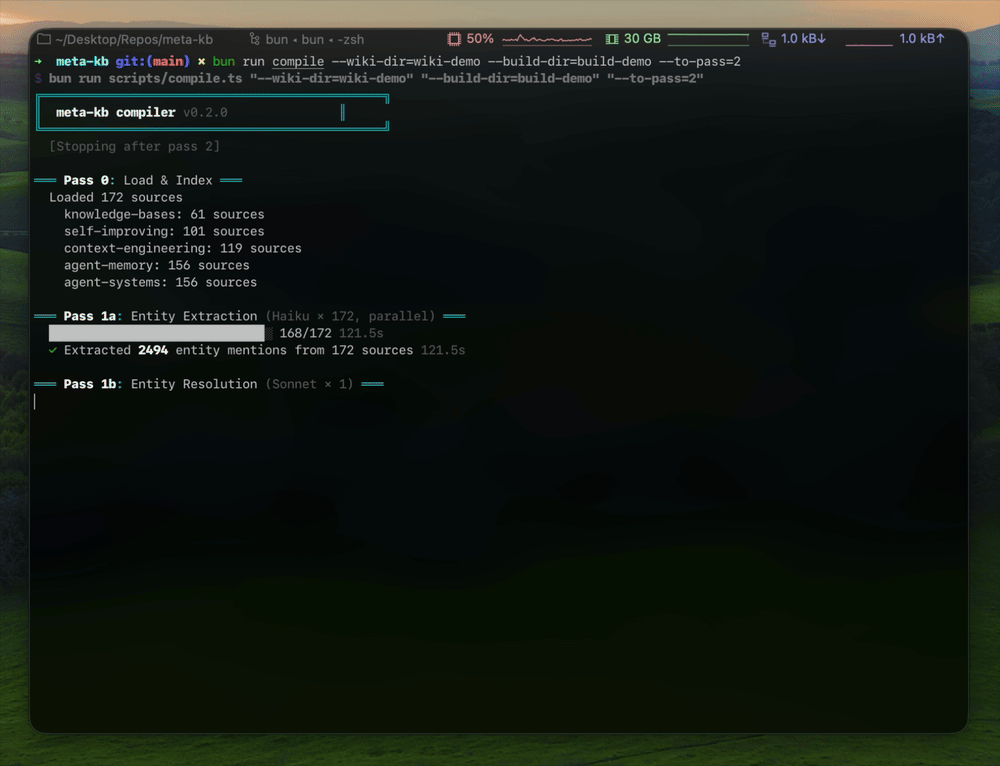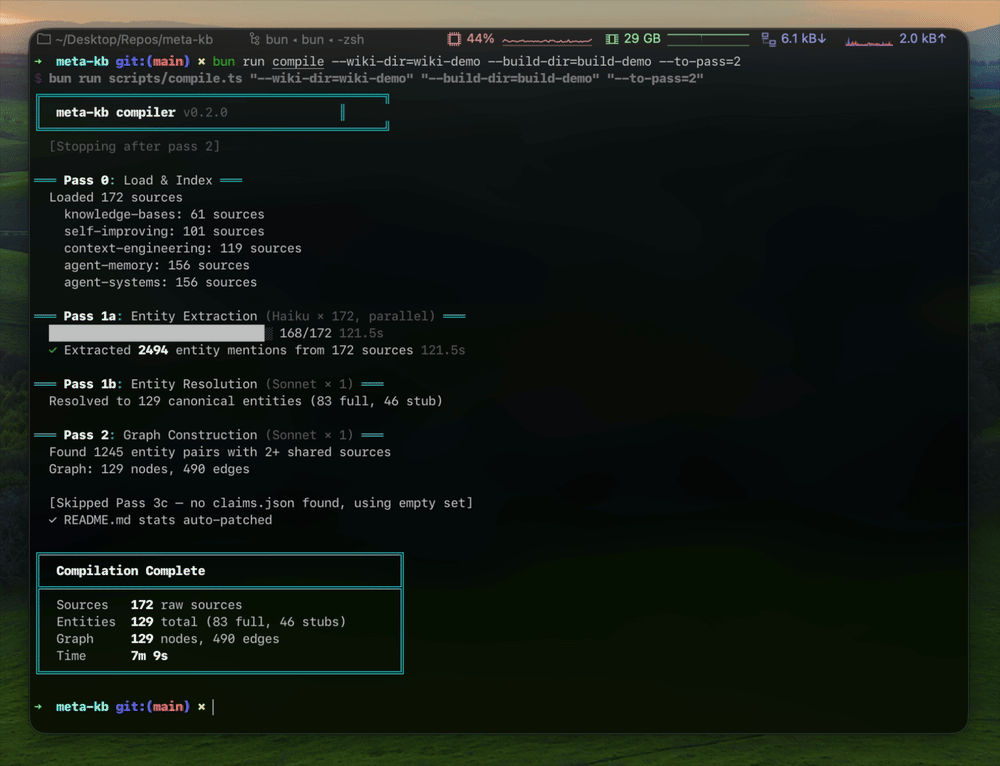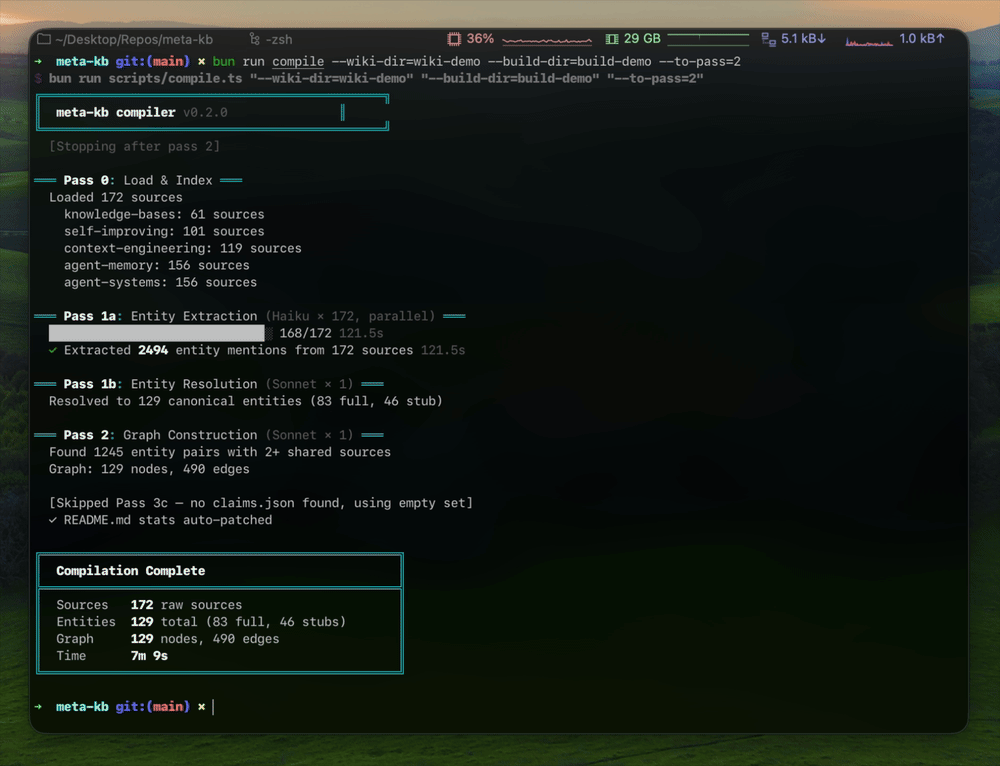
- Self-improving — the compiler extracts atomic claims, verifies each against its cited source, and auto-fixes source attribution errors. The Karpathy loop (eval → analyze failures → update prompts → recompile) improved accuracy from 63.9% → 78.6% → 80.0% across three iterations.
- Incremental —
bun run compile --incrementaldetects source changes via content hashing, recompiles only affected buckets and entities.--statusshows pending changes without compiling. - Deep research — the pipeline clones repos, reads 15-25 source files, fetches docs, and synthesizes architecture-level analysis.
- Dual compilation — both a deterministic script pipeline and an agent-native skill graph produce the same output.
- Neutral — all projects (including the author's own) receive the same depth and the same criticism.
How it was built: METHODOLOGY.md | System Design
Fork this for your own topic
This is a general-purpose knowledge compiler. To build your own wiki on any topic:
- Fork this repo and clear
raw/andwiki/ - Edit one file —
config/domain.tsdefines your topic, audience, taxonomy buckets, and scoring calibration - Add sources —
bun run ingest <url>scores automatically, or add.mdfiles manually - Compile —
bun run compilegenerates the full wiki
Both compilation paths read from config/domain.ts, so they adapt automatically to your topic.
Example topics: ML papers survey, security research tracker, startup playbook, programming language ecosystem map, open-source alternatives directory.
Contributing
The easiest contribution is a new source — PR a .md file into raw/ or open an issue with a URL. See CONTRIBUTING.md for details.
Setup
bun install
cp .env.example .env # add your ANTHROPIC_API_KEY
Environment variables:
ANTHROPIC_API_KEY— for compilation and scoringAPIFY_API_TOKEN— for Twitter scraping (ingestion only)GITHUB_TOKEN— for GitHub API (ingestion only)XQUIK_API_KEY— for X article extraction (optional, ingestion only)
Adding sources
bun run ingest <url1> [url2] ... # ingest sources (auto-detects platform)
bun run research <url1> [url2] ... # deep-research specific repos or papers
bun run research --all # deep-research all unresearched sources
The ingestion script detects platform (GitHub, arXiv, X/Twitter, general articles), supports awesome-list detection and X article extraction via Xquik. Each source gets taxonomy tags (via Haiku), a 4-dimension relevance score (via Sonnet), and a key insight extraction automatically. To re-score all sources (e.g., after changing config/domain.ts), run bun run rescore.
Deep research goes further — cloning repos, reading 15-25 key source files, fetching documentation, then synthesizing structured analysis (architecture, design tradeoffs, failure modes, benchmarks) into raw/deep/. See the deep-research skill for the full methodology.
Two ways to compile
Path A: Skill graph (agent-native)
Ask any AI coding agent: "Compile the wiki from raw sources."
The compile-wiki skill orchestrates a 6-phase pipeline using subagents — each phase has its own skill with focused context. Synthesis articles and reference cards compile in parallel via subagents. Works with Claude Code, Codex, Cursor, or any agent that can read .claude/skills/.
For incremental updates after ingesting new sources, use the incremental-compile skill — it detects what changed and only regenerates affected articles.
Path B: Script pipeline (deterministic)
bun run compile # raw/ → build/ → wiki/
bun run lint # verify structural integrity
bun run diagrams # generate D2 + D3 visualizations
Both paths produce the same output structure. Run both for a comparison diff between agent-native and deterministic compilation.
Stats
- Sources: 126 curated (24 tweets, 66 repos, 13 papers, 23 articles) + 52 deep research files
- Wiki: 149 articles (5 synthesis, 77 project cards, 66 concept explainers, field map, indexes)
- Deep research: 144K words of source-code-level analysis
- Self-eval: 206 atomic claims extracted, 80% accuracy (30 sampled, 24 passed per compilation)
- Compiled by: Script pipeline with Opus for synthesis articles, Sonnet for reference cards
Roadmap
- Incremental recompilation —
bun run compile --incrementalskips unchanged sources, regenerates only dirty buckets/entities - Prompt surgery + Opus synthesis — randomized opening instructions, hardened "takes" prompts, banned-words enforcement, Opus for synthesis articles, restored 15 entity cards, link validation fixing 53 broken links
- Source acquisition — fill coverage gaps in Knowledge Bases (33 sources) and Agent Systems (23 sources), add historical retrospectives and production case studies
- Cross-article synthesis — sequential compilation with evidence registry to eliminate cross-article repetition, question-routing ROOT.md layer
- Claims-first migration — invert pipeline to raw → claims → articles for better attribution accuracy and reliable incremental recompilation
- Temporal claim decay — auto-expire time-sensitive claims (star counts, benchmarks) and flag articles for refresh
See DESIGN.md for the full architectural vision and evaluation findings.
License
Code: MIT. Wiki content: CC-BY-SA 4.0. See LICENSE.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi