ax-eval
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Basarisiz
- spawnSync — Synchronous process spawning in src/automation.ts
- process.env — Environment variable access in src/automation.ts
- spawnSync — Synchronous process spawning in src/cli.ts
- process.env — Environment variable access in src/cli.ts
- process.env — Environment variable access in src/config.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Eval Your Product for Agents: Docs Discoverability; API/CLI/SDK/MCP surfaces across Codex and Claude Code
ax-eval is the open-source, CLI-first way to test whether AI agents can discover and use your product.
API · CLI · SDK · MCP across Codex and Claude Code
Can AI agents actually use your product?
AI agents are becoming users of software. But most teams still test docs, APIs,
SDKs, CLIs, and MCP servers as developer-facing artifacts, not as interfaces
agents must discover and operate. ax-eval runs reviewed sandbox tasks through
real agent harnesses, then verifies outcomes with read-back oracles.
Agent-facing surfaces need integration tests, not just publication checks.
What It Measures
- Discoverability: can an agent-style crawl find docs, auth, and machine-readable surfaces?
- Agent discovery: what did the real agent do from a cold start?
- Spec quality: is the OpenAPI/GraphQL surface clear enough to plan from?
- Task success: did the sandbox state actually change as requested?
- Surface gaps: does API pass while SDK, CLI, or MCP fails?
- Actionability: recommendations are written as
Target / Evidence / Fix.
The open skill can run through the agent you already have open. The CLI can also
drive local harnesses directly with exec-plan --invoke --harness claude-code|codex, producing the same neutral report matrix.
Quickstart
Install and run the keyless checks:
git clone https://github.com/chenmingtang830/ax-eval.git
cd ax-eval
npm install
npm run ax-eval -- run --offline
npm run ax-eval -- audit --offline
npm test
Run a live eval against a sandbox. generate is LLM-assisted by default: it
builds a rule-derived seed from the spec, then asks a local generator harness
(codex or claude-code) to turn it into a product-quality pack. Product
presets can add authoring hints for the fuzzy parts, but code still enforces
surface coverage, schema validity, and a repair pass if the first draft drops
required metadata or tasks. Use--deterministic when you need a keyless CI/offline fixture instead.
For an end-to-end report workflow, automate-report bootstraps discovery, pack
generation, review/auth handoff, smoke execution, verification, and final report
packaging. It never uses Exa; pass explicit official URLs when you have them, or
let the configured local harness find candidates with its native web/search
capability and ax-eval will validate them by fetching official pages directly.
Generated packs still stop at the review gate until a human explicitly approves
them with ax-eval review.
npm run ax-eval -- automate-report --company Acme \
--openapi https://example.com/openapi.json \
--surface all \
--harness codex
# 1. Draft a task pack from a public spec, then review/freeze it.
npm run ax-eval -- ingest --openapi https://example.com/openapi.json \
--out results/acme-ingest.json
npm run ax-eval -- generate --from results/acme-ingest.json
npm run ax-eval -- review --pack results/acme.generated.pack.yaml --approve --by you
# 2. Fill only the credentials and sandbox ids this pack declares.
npm run ax-eval -- init --pack results/acme.generated.pack.yaml >> .env
npm run ax-eval -- check-env --pack results/acme.generated.pack.yaml
# 3. Emit prompts, run them, then verify with read-back oracles.
npm run ax-eval -- exec-plan --pack results/acme.generated.pack.yaml \
--run-dir results/runs/acme
npm run ax-eval -- verify-generated --pack results/acme.generated.pack.yaml \
--results results/runs/acme/run-*.json \
--min-pass-rate 0.8 \
--html results/runs/acme/eval.html
verify-generated writes a saved report snapshot next to the HTML by default.
You can re-render that exact report later without touching live state:
npm run ax-eval -- render-generated \
--snapshot results/runs/acme/generated-eval.snapshot.json \
--html results/runs/acme/generated-eval.html
GraphQL targets use the same review and verification gate:
npm run ax-eval -- ingest --graphql https://api.example.com/graphql \
--out results/acme-graphql-ingest.json
npm run ax-eval -- generate --from results/acme-graphql-ingest.json \
--product Acme --out results/acme.generated.pack.yaml
For CI/offline fixtures, keep the rule-derived path explicit:
npm run ax-eval -- generate --deterministic --from results/acme-ingest.json \
--product Acme --out results/acme.generated.pack.yaml
The repo ships example target packs under targets/examples/. Adding another SaaS should
usually be a new pack, not a code change.
Examples
The repo ships self-contained HTML reports under examples/:
- Stripe four-surface cross-harness report
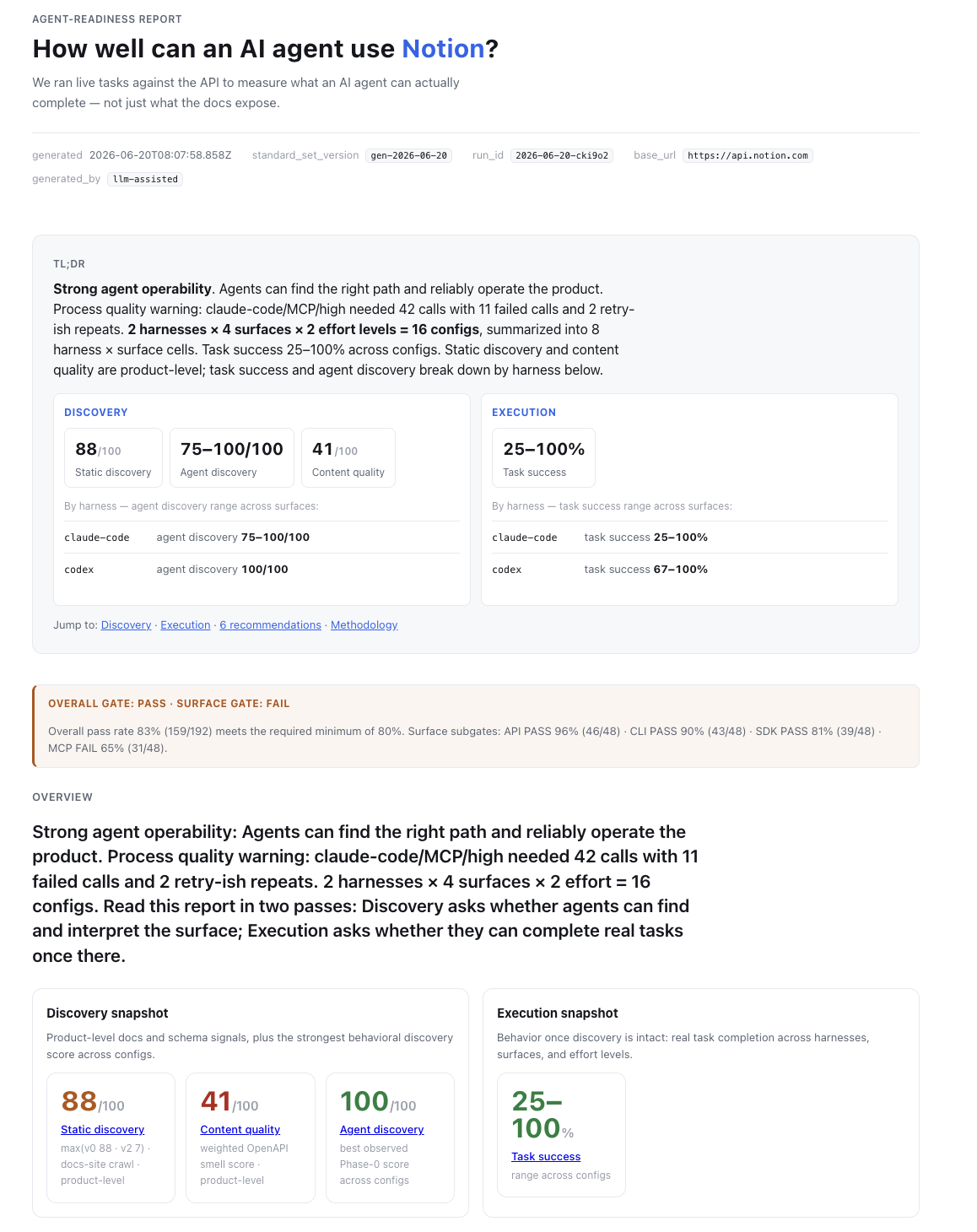
- Notion four-surface cross-harness report
- Linear GraphQL cross-surface, cross-harness report
- Exa cross-harness, cross-surface report
Stripe and Notion are the current four-surface examples: one product evaluated
across API / SDK / CLI / MCP, with both claude-code and codex in the same
matrix. Linear shows the GraphQL path; Exa shows a non-CRUD/search API case.
These examples are the fastest way to see what a finished ax-eval artifact looks
like.
These are stable copies of real run artifacts, so you can inspect the output
without digging through results/runs/.
Architecture
ax-eval is pack-centered and surface-aware.
- Contracts:
TargetPack,Task,OracleSpec, and per-surface auth/config
live in versioned schemas and act as the stable center of the system. - Execution matrix: the same reviewed pack runs across one or more harnesses
and surfaces (api,cli,sdk,mcp), with surface adapters changing how
the agent discovers and acts rather than changing the oracle model. When a
surface only covers part of the product, generation narrows that surface to
the subset of tasks it can actually support instead of forcing API-shaped
tasks onto it. - Truth layer: executors report ids, but success is decided by independent
read-back verification against live product state. - Interpretation layer: reports and normalized records turn results, traces,
and transcripts into recommendations and comparisons.
See ARCHITECTURE.md for the full system design.
How It Works

- Ingest: parse OpenAPI, GraphQL, docs, auth, and sandbox hints.
- Generate: draft an L1-L4 task pack with rule-derived oracles and
LLM-assisted task authoring by default. - Review: hash-lock the pack after human approval and Pack QA warnings.
- Execute: run the same pack across selected surfaces and harnesses, with
each surface taking the tasks that generation marked as truly supported. - Verify: read live state back, score the matrix, and write reports.
Why It Is Different
- Goal-level prompts, not endpoint hints. The agent has to discover the
surface instead of being handed a curl command. - Programmatic oracles, not self-report. Success means the verifier can read
the expected state back from the product. - Target-declared auth and sandbox scope. Packs say exactly which env vars and
sandbox ids are needed; secrets stay local in.env. - Layered gates, not misleading green.
--min-pass-ratereports the overall
gate and per-surface subgates, so a weak MCP or SDK surface remains visible. - Competitive reports from the same records. Stack normalized results across
products or surfaces to see where competitors, SDKs, CLIs, APIs, or MCP servers
are easier for agents to use successfully.
Command Map
npm run ax-eval -- ingest --openapi <url> # parse REST/OpenAPI into an ingest file
npm run ax-eval -- ingest --graphql <endpoint|file> # rich GraphQL introspection
npm run ax-eval -- generate --from <ingest.json> [--base-url <graphql-endpoint>] # LLM-assisted by default
npm run ax-eval -- generate --deterministic --from <ingest.json> # CI/offline fallback
npm run ax-eval -- review --pack <pack.yaml> [--approve --by you]
npm run ax-eval -- init --pack <pack.yaml> [--surface all]
npm run ax-eval -- check-env --pack <pack.yaml> [--surface all]
npm run ax-eval -- automate-report --company <name> [--openapi <url>|--graphql <endpoint>] # no Exa; stops at review/auth gates before smoke/full
npm run ax-eval -- exec-plan --pack <pack.yaml> --run-dir <dir>
npm run ax-eval -- exec-plan --pack <pack.yaml> --invoke \
--harness claude-code --harness codex --surface all --run-dir <dir> # cross-harness × cross-surface (parallel)
npm run ax-eval -- verify-generated --pack <pack.yaml> --results <run.json>... \
--html <out.html> [--snapshot <out.snapshot.json>]
npm run ax-eval -- render-generated --snapshot <report.snapshot.json> [--html <out.html>]
npm run ax-eval -- reset --pack <pack.yaml> [--dry-run]
npm run ax-eval -- audit --site <url>
npm run ax-eval -- discover --site <url>
npm run ax-eval -- smells --openapi <url>
npm run ax-eval -- competitive --results <normalized.json>... --html <out.html>
CI should validate frozen packs, approvals, deterministic fixtures, tests, and
typecheck. It should not depend on live LLM-assisted regeneration; fresh pack
authoring is a developer workflow that ends at review --approve.
Safety
Live evals make real writes. Use a sandbox, never production. init prints the
env stub a pack declares; .env is git-ignored. Surfaces authenticate
independently, so an unavailable SDK/CLI/MCP credential becomes a blocked cell in
the report instead of a misleading failure. OAuth-backed MCP surfaces can be run
headlessly when the pack declares client id, client secret, refresh token, and token
URL env names: ax-eval exchanges the refresh token at invoke time, passes the
short-lived bearer only to the child harness environment, and keeps secret values out
of tracked files.
Packs can declare backward-compatible env aliases too: top-level auth supportsenv_aliases / verify_env_aliases, and token-authenticated SDK/CLI/MCP
surfaces support token_env_aliases. The first name stays canonical in packs
and prompts; aliases let an older local setup keep working without changing the
benchmark artifact.
verify-generated reads live product state. Do not reset or sweep the sandbox
until after the report is rendered and the user explicitly asks for cleanup.
Cleaning first will make otherwise valid result ids read back as missing and
will corrupt the report.
If you want a stable artifact for examples, review, or later design work, keep
the saved report snapshot and use render-generated instead of re-running live
verification. Re-rendering from the snapshot preserves the report inputs; a newverify-generated is a fresh measurement.
Generated packs are executable intent. exec-plan refuses unreviewed or changed
packs unless you explicitly bypass the review gate.
Repository Layout
ARCHITECTURE.md full technical architecture and system design
src/ CLI, generation, verification, reporting, static checks
src/ingest/ OpenAPI and GraphQL ingestion
src/generate/ task-pack generation, review, report, normalized records
src/harness/ host-agent profiles, transcripts, traces, probe
src/surface/ API, CLI, SDK, MCP surface prompt adapters
src/target/ pack-declared auth, sandbox scope, reset
targets/ target-pack index and example pack directories (see targets/README.md)
examples/ stable example reports and case-study artifacts
tests/ vitest suite, keyless/offline by default
assets/ README images and report screenshots
docs/ maintainer-local notes, intentionally not public docs
Contributing
See CONTRIBUTING.md. The best first contribution is a new
target pack generated from a public spec, reviewed with the gate, and backed by a
focused test or oracle improvement.
Contact
Questions, target ideas, or agent-usability examples? Open an issue or reach me
on X: @richardt830.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi