aether-llmops-platform
Health Warn
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
本项目是一个复杂的LLMOps平台开发,通过本项目,你可以全流程打造你自己的 AI 原生应用开发平台,欢迎提issue,参与讨论与贡献。
Aether LLMOps 原生AI 应用开发平台







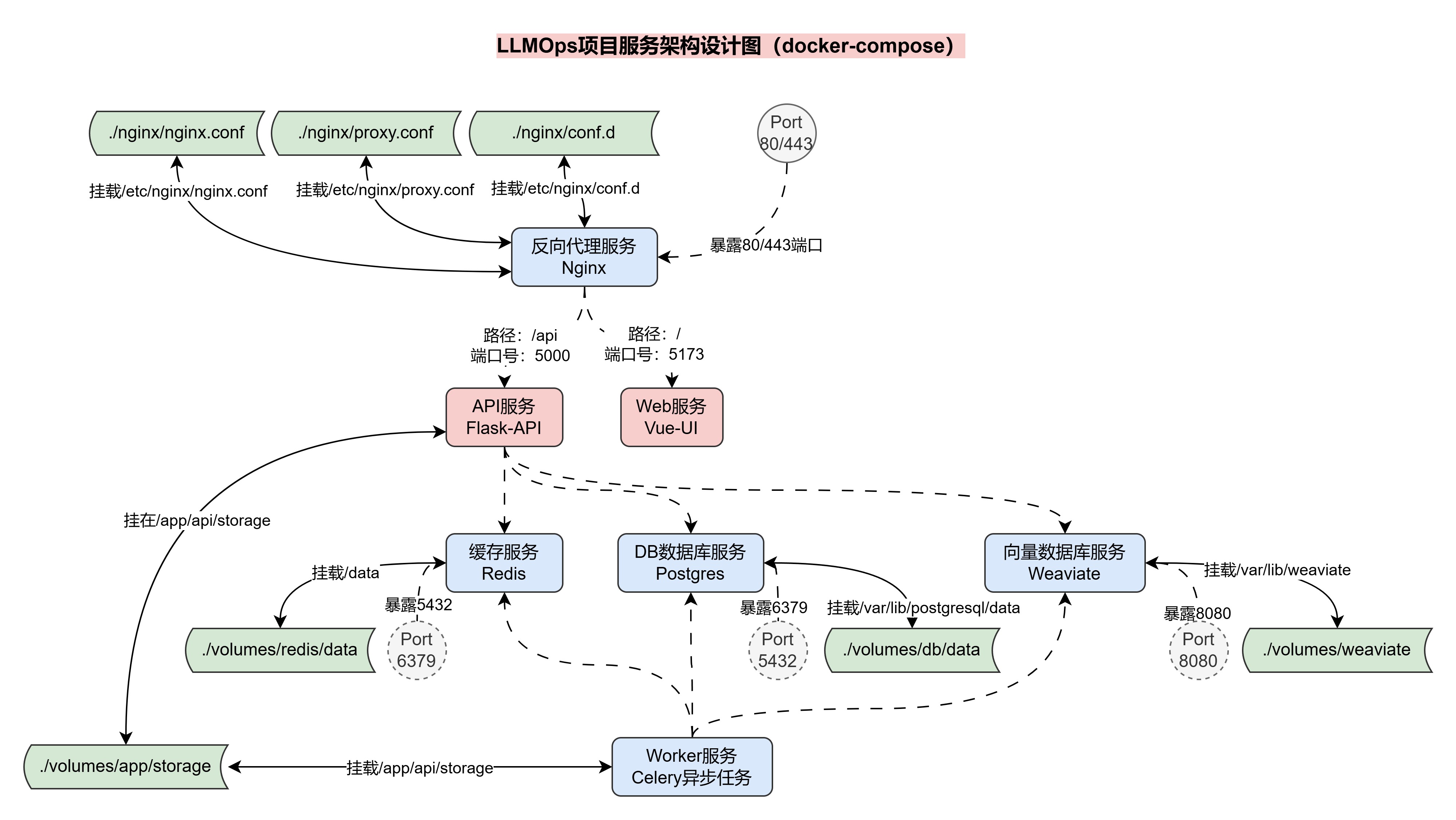
Aether LLMOps 项目服务架构设计
在整个Aether LLMOps项目中,我使用了多个服务,具体如下:
- API:基于
Flask和LangChain搭建的LLMOps API服务。 - Web:基于
Vue.js搭建的LLMOps前端服务,一个静态html文件服务。 - 数据库:
Postgres数据库,用于存储LLMOps项目的数据信息。 - 缓存:
Redis缓存数据库,用于存储Embeddings缓存、Celery消息代理等信息。 - 向量数据库:
Weaviate向量数据库,用于存储Embeddings向量。 - 任务队列:
Celery任务队列,用于执行异步任务。 - Nginx反向代理:反向代理连接
API和WEB服务,实现域名访问LLMOps项目。
为了便于部署和管理,我将这些服务部署到Docker容器中,并使用docker-compose管理多个容
器,同时通过 Nginx 进行反向代理,连接 API 和 web 服务,项目整体服务架构设计图如下:
快速开始
填写docker-compose.yml文件中的环境变量,包括数据库连接信息、缓存数据库连接信息、向量数据库连接信息,各种API密钥等。
cd docker
docker-compose up -d
项目后端模块设计
该项目采用经典的分层架构设计
- 入口层 app/http/ 负责应用初始化和中间件注册
- 路由层 handler/ 负责接收请求和参数校验
- 业务层 service/ 实现核心业务逻辑
- 数据层 model/ 负责数据库交互
- 公共组件 pkg/ 提供跨模块复用的通用能力
- 配置和工具模块分离,便于维护和扩展
核心引擎层internal/core/:
- workflow/ - 完整的工作流引擎,支持多种节点类型(LLM、工具调用、HTTP请求、代码执行等)
- language_model/ - LLM 抽象封装
- embedding/ - 文本向量化
- vector_store/ - 向量数据库管理
- unstructured/ - 非结构化文档解析
- tool/ - 内置工具集
- memory/ - 对话上下文记忆
API 项目文件结构梳理:
api/
├── config/ # 配置模块
│ ├── __init__.py
│ ├── config.py # 配置加载逻辑
│ └── default_config.py # 默认配置项
├── app/ # 应用入口层
│ ├── __init__.py
│ └── http/ # HTTP服务入口
│ ├── __init__.py
│ ├── app.py # FastAPI 应用实例创建、中间件注册
│ └── module.py # 依赖注入模块配置
├── internal/ # 核心业务实现层
│ ├── core/ # 核心组件(工作流、向量存储、文档处理等)
│ │ ├── agent/ # Agent 相关实现
│ │ │ ├── agent_builder.py
│ │ │ ├── agent_executor.py
│ │ │ └── conversation_agent.py
│ │ ├── builtin_apps/ # 内置应用实现
│ │ │ ├── chat/
│ │ │ ├── completion/
│ │ │ ├── dataset_qa/
│ │ │ └── workflow/
│ │ ├── file_extractor/ # 文件提取工具
│ │ ├── langchain_fix/ # LangChain 补丁/修复
│ │ ├── language_model/ # 语言模型封装
│ │ │ ├── base.py # LLM 基类
│ │ │ ├── factory.py # LLM 工厂
│ │ │ ├── openai.py # OpenAI 模型封装
│ │ │ ├── anthropic.py # Anthropic 模型封装
│ │ │ └── azure_openai.py # Azure OpenAI 模型封装
│ │ ├── memory/ # 对话记忆管理
│ │ ├── retrievers/ # 检索器实现
│ │ ├── tools/ # 工具集
│ │ │ ├── base_tool.py
│ │ │ ├── builtin_tools/
│ │ │ │ ├── search/
│ │ │ │ ├── calculator/
│ │ │ │ └── web_scraper/
│ │ │ └── api_tools/
│ │ ├── unstructured/ # 非结构化文档处理
│ │ │ ├── document_processor.py
│ │ │ └── nltk_data/ # NLTK 数据文件
│ │ │ ├── punkt/
│ │ │ │ └── ... (18种语言的 punkt 分词数据)
│ │ │ └── punkt_tab/
│ │ │ └── ... (22种语言的 punkt_tab 分词数据,包含 abbrev_types.txt、collocations.tab、ortho_context.tab等)
│ │ ├── vector_store/ # 向量数据库存储
│ │ └── workflow/ # 工作流引擎核心
│ │ ├── workflow.py # 工作流引擎主逻辑
│ │ ├── workflow_validate_rule.jpg # 工作流验证规则图
│ │ ├── entities/ # 工作流实体定义
│ │ │ ├── node_entity.py # 节点实体
│ │ │ ├── edge_entity.py # 边实体
│ │ │ ├── variable_entity.py # 变量实体
│ │ │ └── workflow_entity.py # 工作流实体
│ │ ├── nodes/ # 工作流节点类型实现
│ │ │ ├── base_node.py # 节点基类
│ │ │ ├── start/ # 开始节点
│ │ │ ├── end/ # 结束节点
│ │ │ ├── llm/ # LLM 调用节点
│ │ │ ├── code/ # 代码执行节点
│ │ │ ├── tool/ # 工具调用节点
│ │ │ ├── http_request/ # HTTP 请求节点
│ │ │ ├── dataset_retrieval/ # 数据集检索节点
│ │ │ ├── template_transform/ # 模板转换节点
│ │ │ ├── question_classifier/ # 问题分类节点
│ │ │ └── iteration/ # 循环迭代节点
│ │ └── utils/ # 工作流工具函数
│ ├── entity/ # 实体定义
│ ├── exception/ # 自定义异常定义
│ ├── extension/ # 扩展模块
│ ├── handler/ # API 接口处理器(Controller层)
│ ├── lib/ # 内部工具库
│ ├── middleware/ # HTTP 中间件
│ ├── migration/ # 数据库迁移(Alembic)
│ ├── model/ # 数据库模型(DAO层)
│ ├── router/ # 路由配置
│ ├── schema/ # 请求/响应模型(Pydantic)
│ ├── server/ # 服务启动配置
│ ├── service/ # 业务逻辑层(Service层)
│ └── task/ # 异步任务模块
├── pkg/ # 公共可复用组件
├── storage/ # 存储相关模块
├── test/ # 单元测试/集成测试
├── Dockerfile
├── requirements.txt
└── ...
应用编排模块
在 LLMOps 应用编排页面,应用的配置可以划分成几种,例如:
- 草稿配置:用户在前端编排页面修改
Agent配置时,实时存储的就是 草稿配置,草稿配置只会在 编排页面 调试中生效,在开放API或者WebApp中均不会起效果。 - 当前发布的运行配置:即当前 Agent 智能体在开放
API或者在WebApp中使用的配置信息,由 草稿配置 发布得到。 - 历史发布的运行配置:记录每一次发布的运行配置,便于在编排页面对配置进行 回退操作,当执行回退操作时会将对应的运行配置同步到草稿配置中,完成对 草稿配置 的覆盖。
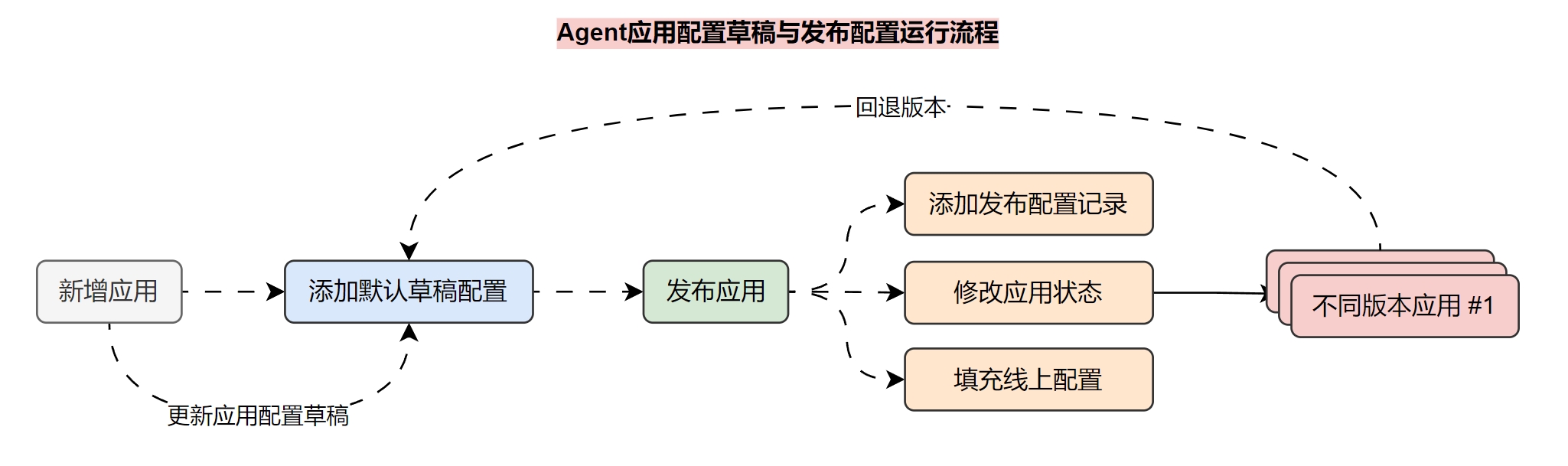
在 LLMOps 项目中,考虑使用两张表来完成该运行流程,这两张表分别是:
- app_config:应用运行配置表,用于存储该
Agent应用实际运行的配置信息(WebApp、开放API运行的 Agent 配置)。 - app_config_version:应用配置历史版本表,该表用于存储每次发布的配置信息历史+草稿信息,通过
config_type来标识记录是 历史配置 还是草稿,通过version字段来标识不同的版本。
那么不同的操作执行的逻辑如下:
- 创建应用:创建应用的同时添加 app_config_version 记录,并在记录中存储 默认草稿配置信息。
- 更新应用草稿配置:将数据同步到 app_config_version 的草稿配置记录中。
- 发布应用:取出应用的 app_config_version 草稿配置,同步添加到 app_config 中,同时在app_config_version 中添加一个历史配置信息记录,并更改应用的状态,从而完成发布应用流程。
- 更新应用:取出应用的 app_config_version 草稿配置,并同步更新 app_config 中的配置,同时在app_config_version 中添加一条历史配置信息记录,从而完成应用更新流程。
- 取消发布:删除 app_config 中的配置,并更改应用的状态。
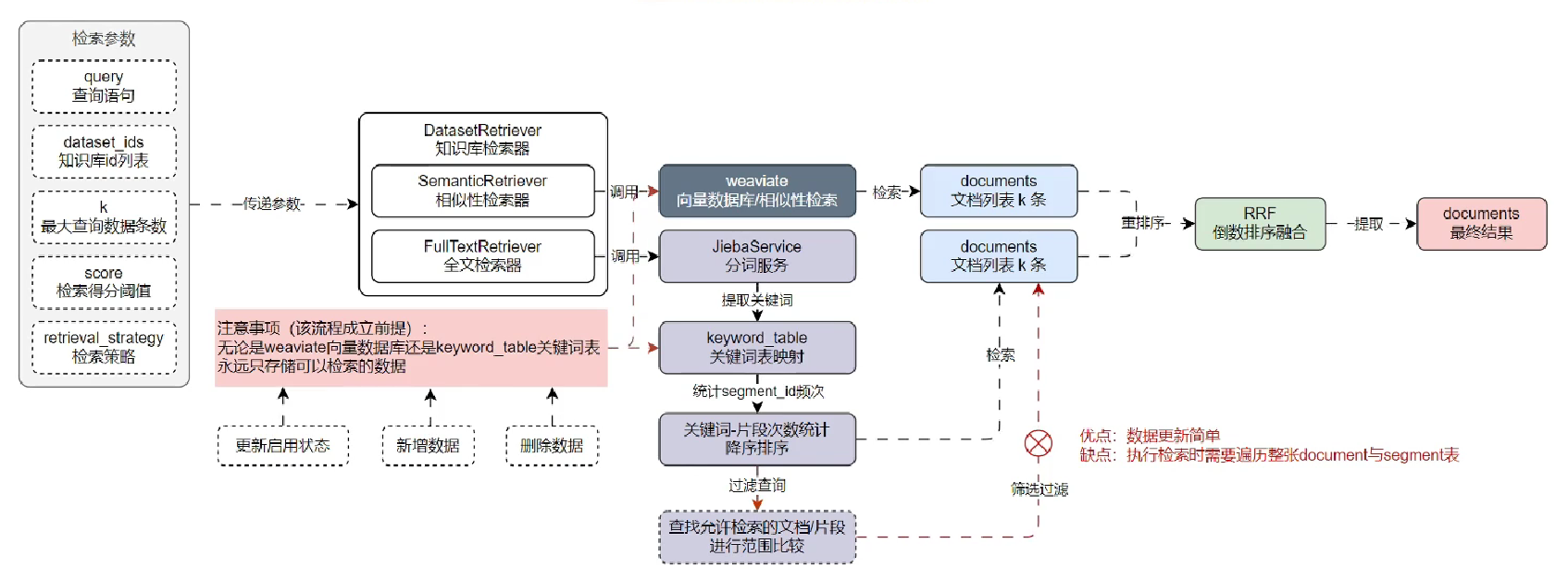
知识库模块
一些优化点
- 考虑到处理大量文档分块、嵌入等的长耗时,利用 Celery+Redis 构建异步任务队列处理分块嵌入,用线程池优化向量入库。
- 随着功能迭代,针对检索准确率不够,在 RAG 引入检索前处理+混合检索+重排,在黑神话悟空的自建QA数据下测试,准确率相比语义检索提升近30%,召回率从60%左右提升至80%+。
- 在文档与片段(chunk)的更新与删除时,实现 Redis 缓存锁,保障数据安全。
检索器设计思路
- 在全文检索时,项目考虑的是第一种方案,增删改都要将数据同步到关键词表中,简化全文检索的实现。
- 第二种方法,本项目并未使用,因为其在全文检索时,需要将所有 doc 和 seg 都遍历一遍再过滤,导致查询效率低。
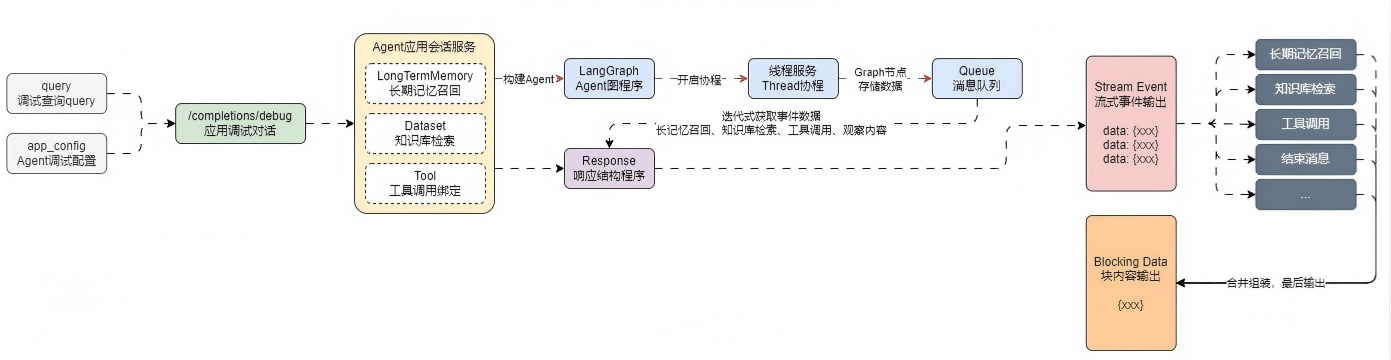
流式输出
考虑在LLMOps项目中,借用队列(Queue)+线程(Thread)的方式来重新实现流式输出这个逻辑,思路如下:
构建一个 队列(Queue),用于存储数据,队列的数据先进先出,并且是线程安全的,非常适合用于开发。
在LangGraph构建的节点(nodes)中,所有代码都使用stream() 代替invoke(),获取数据的时候,将数据添加到队列(Queue) 中。
创建一条线程,专门用于执行LangGraph图程序,这样不影响主线程。
在主线程监听队列(Queue)里的数据,并逐个取出,然后进行流式事件响应输出,直到取到结果为None结束请求。
基于该思想,在LLMOps项目中实现流式事件响应 + 块内容响应的两种输出响应运行流程如下:
项目时间节点
gantt
dateFormat YYYY-MM-DD
section 第一阶段
需求分析 :2026-01-01, 14d
架构设计 :2026-01-15, 16d
基础框架搭建 :2026-01-31, 18d
数据库表设计 :2026-01-31, 10d
section 第二阶段
核心模块开发&性能优化 :2026-02-18, 30d
工作流引擎&知识库模块 :2026-02-18, 20d
多LLM接入&安全性保障 :2026-02-18, 20d
section 第三阶段
发布渠道集成 :2026-03-17, 15d
多模态插件 :2026-03-17, 15d
第三方应用集成 :2026-03-17, 15d
开放API开发 :2026-03-17, 15d
section 第四阶段
生产环境调优 :2026-04-02, 20d
上线部署 :2026-04-22, 10d
附录
术语表
| 术语 | 定义 |
|---|---|
| LLM | Large Language Model,大语言模型 |
| RAG | Retrieval-Augmented Generation,检索增强生成 |
| API | Application Programming Interface,应用程序接口 |
贡献
贡献是使开源社区成为学习、激励和创造的惊人之处。非常感谢您所做的任何贡献。如果您有任何建议或功能请求,请先开启一个议题讨论您想要改变的内容。
许可证
该项目根据 Apache-2.0 许可证的条款进行许可。详情请参见LICENSE文件。
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found