claudes-ai-buddies
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Three AIs, one terminal — call Codex and Gemini as peer reviewers, brainstorm partners, or second opinions. Direct CLI, no MCP

![]()
![]()
![]()
Any AI can join. They compete. They collaborate. They can just talk.
Quick Start
# 1. Install the engines you want (one or more)
npm install -g @openai/codex # OpenAI Codex
npm install -g @google/gemini-cli # Google Gemini
brew install opencode # OpenCode (MiniMax, Anthropic, Google, etc.)
# 2. Authenticate
codex auth login # uses your OpenAI account
gemini auth login # uses your Google account
opencode providers login # optional — pick a provider (works without for free model)
# 3. Add the marketplace & install
claude plugin marketplace add cukas/claudes-ai-buddies
claude plugin install claudes-ai-buddies@cukas
# Done — start a new Claude Code session
Works with any combination of Codex, Gemini, OpenCode, or any custom AI CLI you register.
All Skills
| Command | What it does |
|---|---|
/campfire "topic" |
Open conversation — all buddies think together, no competition |
/brainstorm "task" |
Confidence bid — buddies assess the task, you pick who builds it |
/forge "task" --fitness "cmd" |
Competitive build with automated scoring |
/tribunal "question" |
Evidence-based debate — 6 modes |
/leaderboard |
Show ELO ratings from forge competitions |
/codex "prompt" |
Talk to Codex — raw voice, conversational |
/gemini "prompt" |
Talk to Gemini — raw voice, conversational |
/opencode "prompt" |
Talk to OpenCode — raw voice, conversational |
/codex-review |
Code review via Codex |
/gemini-review |
Code review via Gemini |
/opencode-review |
Code review via OpenCode |
/add-buddy |
Register any CLI as a new buddy |
Campfire — Open Multi-AI Conversation
/campfire "What's the best way to handle auth in microservices?"
All buddies respond to a topic together. No competition, no ranking — just thinking together. Each buddy speaks in their own voice:
🔵 Codex:
> The service mesh approach with mTLS is cleanest...
🟣 Gemini:
> I'd push back on that — JWT with short-lived tokens scales better...
🟢 OpenCode:
> What if you combine both? mTLS between services, JWT for user-facing...
🟠 Claude:
> Three different angles, and OpenCode's hybrid is interesting...
Aliases: /think, /talk
Brainstorm — Confidence Bid
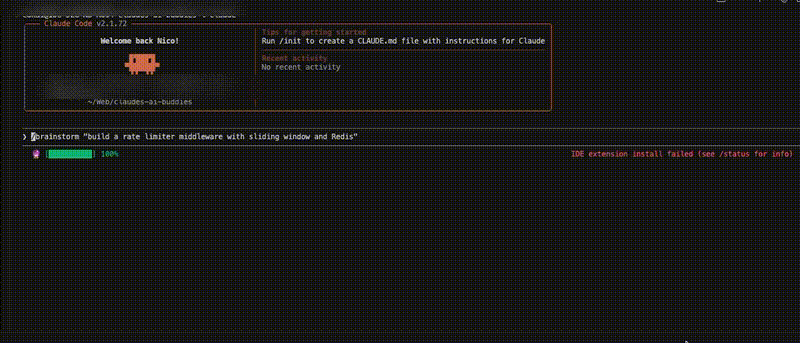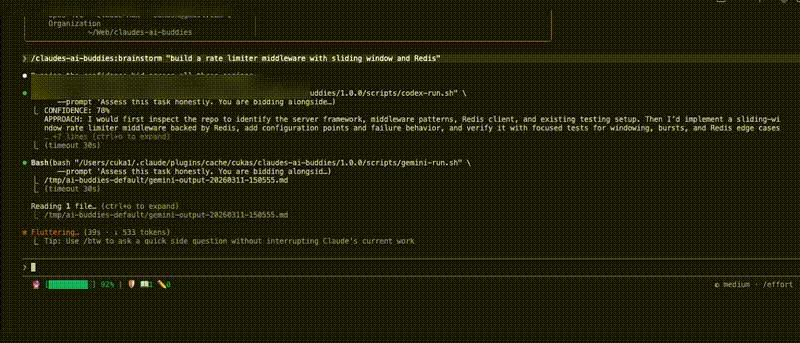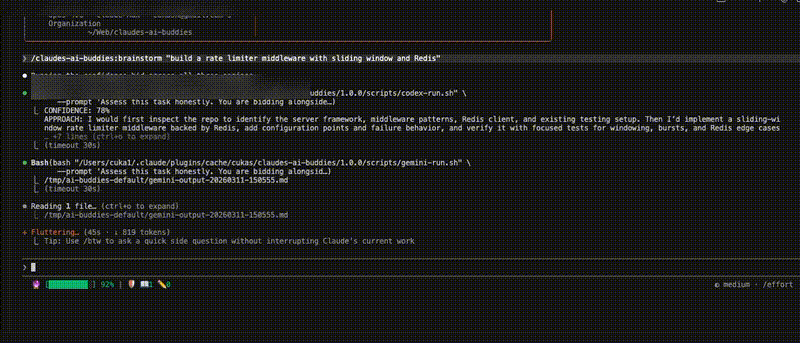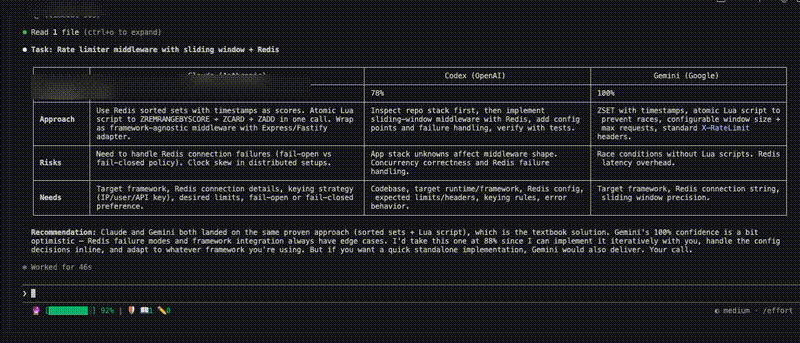
/brainstorm "Fix the race condition in the WebSocket reconnection handler"
Each buddy assesses the task, rates their confidence, and proposes an approach. Claude calibrates the scores and recommends who should take it.
- Disagreements are the signal — if AIs disagree, that's where the insight is
- Claude calibrates — adjusts inflated/deflated scores based on approach quality
- Context-aware — Claude passes relevant conversation context when it helps
Forge — Competitive Build
/forge "Add input validation to math utils" --fitness "npm test"
Buddies independently implement the same task in isolated git worktrees. A staged pipeline scores them objectively — the best code wins.
- Staged pipeline — starter runs first; challengers only if needed; synthesis on close calls
- Composite scoring — diff size, lint, style, test pass, duration = 0-100 score
- ELO tracking — persistent ratings per task class
- Speculative tests — omit
--fitnessand engines propose test suites --async— run in background, continue your conversation
- Context — detects languages, conventions, and candidate files
- Stage 1: Starter — one engine runs first. Auto-accepted if score >= 88 with clean lint
- Stage 2: Challengers — remaining engines run in parallel if the starter didn't clear the bar
- Stage 3: Synthesis — on close calls (spread < 8 pts), losers critique, winner refines
- Scoreboard — composite scores (diff 30%, lint 15%, style 15%, files 10%, duration 5%, tests 25%)
- ELO — winner gains rating vs each loser, per auto-detected task class
- Converge — you approve the winning diff before it touches your working tree
Tribunal — Evidence-Based Debate
/tribunal "Should we refactor the auth middleware to use async/await?"
Two buddies debate with evidence citations (file:line). Claude judges on evidence quality, not consensus.
6 debate modes| Mode | AIs do | Best for |
|---|---|---|
| adversarial | FOR vs AGAINST | Binary decisions |
| socratic | Probe assumptions | Early exploration |
| steelman | Argue other side's best case | Avoiding bias |
| red-team | Attack, no defense | Poking holes |
| synthesis | Propose, then hybridize | Finding a third option |
| postmortem | Investigate from angles | Bug investigation |
Direct Chat & Code Reviews
Talk directly to any buddy. With conversational mode enabled, they remember across calls:
/codex "What's the best way to implement a rate limiter in Go?"
/gemini "Debug this: TypeError: Cannot read property 'map' of undefined"
/opencode "Review this architecture for scaling issues"
Code reviews with native review protocols:
/codex-review # review uncommitted changes
/gemini-review branch:main "focus on security" # review branch diff with focus
/opencode-review commit:abc1234 # review specific commit
Companion Scripts (v4)
Each buddy has a companion script that connects via the engine's native protocol for richer integration:
| Buddy | Protocol | What it enables |
|---|---|---|
| 🔵 Codex | codex app-server JSONRPC over stdio |
Thread resume, native review, structured output (fileChanges, commands) |
| 🟣 Gemini | --output-format json |
Session resume, token stats |
| 🟢 OpenCode | --format json + --session |
Session resume, token/cost tracking |
All companions fall back gracefully to the legacy CLI if the protocol isn't available.
Configuration
Optional — works out of the box. Config at ~/.claudes-ai-buddies/config.json:
| Key | Default | Description |
|---|---|---|
conversational |
false |
Buddies remember conversations across calls |
codex_conversational |
(global) | Per-buddy override |
timeout |
0 (none) |
Max seconds per call (0 = no timeout) |
codex_model |
CLI default | Codex model override |
gemini_model |
CLI default | Gemini model override |
opencode_model |
CLI default | OpenCode model (format: provider/model) |
sandbox |
full-auto |
full-auto or suggest |
debug |
false |
Enable debug logging |
elo_enabled |
true |
Track ELO ratings |
tribunal_rounds |
2 |
Tribunal debate rounds |
Dynamic Buddy Registry
Any CLI-based AI tool can become a buddy:
/add-buddy --id aider --binary aider --display "Aider" --modes exec
Registered buddies automatically participate in /forge, /brainstorm, /tribunal, and /campfire.
How It Works
┌──────────┐ ┌──────────────┐ ┌─────────────┐ ┌──────────────┐
│ User │────>│ Claude Code │────>│ Registry │────>│ Any AI CLI │
│ │ │ (orchestrator│ │ (buddy JSON │ │ (codex, gem │
│ │<────│ + judge) │<────│ + companion│<────│ aider, ...) │
└──────────┘ └──────────────┘ └─────────────┘ └──────────────┘
- Companion scripts — native protocol integration (JSONRPC, JSON output, session resume)
- No MCP servers — direct CLI subprocess calls with graceful fallback
- No API keys in transit — each engine uses its own auth
- No timeouts by default — buddies respond when ready, user can interrupt
- Context injection — Claude passes conversation context when it helps
- Conversational mode — buddies remember across calls via session/thread resume
Testing
bash tests/run-tests.sh
=== Results: 270/270 passed, 0 failed ===
Part of the cukas Plugin Ecosystem
| Plugin | Description |
|---|---|
| Remembrall | Never lose work to context limits |
| Patrol | ESLint for Claude Code |
| Evil Twin | Adversarial self-challenge + blind verification |
| Hello Claude | Plugin starter template |
| AI Buddies | You are here |
All available via the claude-plugins monorepo.
MIT License
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi