neuralmind
Health Uyari
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
🧠 Adaptive Neural Knowledge System - 40-70x token reduction for AI code understanding
🧠 NeuralMind
![]()
![]()
![]()
![]()
![]()
![]()
Semantic code intelligence for AI coding agents — smart context retrieval + tool-output compression in one package.
NeuralMind turns a code repository into a queryable neural index. AI agents use it to answer code questions in ~800 tokens instead of loading 50,000+ tokens of raw source.
⚖️ Not affiliated with NeuralMind.ai. This project is an independent, open-source tool for semantic code intelligence.
🔒 Security & Compliance
For enterprises and regulated industries:
- 100% Local Processing – Your code never leaves your machine. All embeddings are generated and stored locally using ChromaDB.
- No External APIs – NeuralMind runs completely offline. No cloud services, no telemetry, no data exfiltration.
- Explainable AI – Every context decision is auditable. Know exactly which code was retrieved (Extracted) vs. inferred by the model.
- Open-Source & MIT Licensed – Full transparency. No hidden clauses, no vendor lock-in. Audit the code yourself.
- GDPR/HIPAA-Friendly – Process sensitive code without compliance concerns. All data stays under your control.
For CTOs & Security Teams:
- ✅ Zero external dependencies for code storage
- ✅ Runs behind your firewall or on-premise
- ✅ No collection of usage metrics or code patterns
- ✅ Predictable, reproducible results (not a black box)
- ✅ Works with proprietary and sensitive code
📌 For AI Coding Agents
If you are Claude Code, Codex, Cursor, Cline, or any AI agent with NeuralMind installed, start here.
Check if NeuralMind is active
neuralmind stats .
Expected output when ready:
Project: your-project
Built: True
Nodes: 241
If Built: False, run graphify update . && neuralmind build . first.
Startup workflow
Every new session, do this first:
neuralmind wakeup .
Or via MCP:
neuralmind_wakeup(project_path=".")
This returns ~365–600 tokens of structured project context:
- Project name and description (from
CLAUDE.md,mempalace.yaml, orREADME.mdfirst line) - How many code entities and clusters are indexed
- Architecture overview: top 10 code clusters with their entity types and sample names
- Sections from
graphify-out/GRAPH_REPORT.mdif present
Use this output as your orientation before writing any code. It replaces reading the entire repository.
Decision tree — which tool to call
Need to understand the project?
└─► neuralmind wakeup . (MCP: neuralmind_wakeup) ~400 tokens
Answering a specific code question?
└─► neuralmind query . "question" (MCP: neuralmind_query) ~800–1100 tokens
About to open a source file?
└─► neuralmind skeleton <file> (MCP: neuralmind_skeleton) ~5–15× cheaper than Read
→ Only fall back to Read when you need the actual implementation body
→ Use NEURALMIND_BYPASS=1 when you truly need raw source
Searching for a specific function/class/entity?
└─► neuralmind search . "term" (MCP: neuralmind_search) ranked by semantic similarity
Made code changes and need to update the index?
└─► neuralmind build . (MCP: neuralmind_build) incremental — only re-embeds changed nodes
Understanding the output
wakeup / query output format
## Project: myapp
Full-stack web app for task management. Uses React 18, Node.js, and PostgreSQL.
Knowledge Graph: 241 entities, 23 clusters
Type: Code repository with semantic indexing
## Architecture Overview
### Code Clusters
- Cluster 5 (45 entities): function — authenticate_user, hash_password, verify_token
- Cluster 12 (23 entities): class — UserController, AuthMiddleware, SessionStore
- Cluster 3 (18 entities): function — createTask, updateTask, deleteTask
...
## Relevant Code Areas ← query only; absent from wakeup
### Cluster 5 (relevance: 1.73)
Contains: function entities
- authenticate_user (code) — auth.py
- verify_token (code) — auth.py
## Search Results ← query only
- AuthMiddleware (score: 0.91) — middleware.py
- jwt_handler (score: 0.85) — auth/jwt.py
---
Tokens: 847 | 59.0x reduction | Layers: L0, L1, L2, L3 | Communities: [5, 12]
Layer meanings:
| Layer | Name | Always loaded | Content |
|---|---|---|---|
| L0 | Identity | ✅ yes | Project name, description, graph size |
| L1 | Summary | ✅ yes | Architecture, top clusters, GRAPH_REPORT sections |
| L2 | On-demand | query only | Top 3 clusters most relevant to the query |
| L3 | Search | query only | Semantic search hits (up to 10) |
skeleton output format
# src/auth/handlers.py (community 5, 8 functions)
## Functions
L12 authenticate_user — Validates credentials and issues JWT
L45 verify_token — Checks JWT signature and expiry
L78 refresh_token — Issues new JWT from a valid refresh token
L102 logout — Revokes refresh token in DB
## Call graph (within this file)
authenticate_user → verify_token, hash_password
refresh_token → verify_token
## Cross-file
verify_token imports_from → utils/jwt.py (high 0.95)
authenticate_user shares_data_with → models/user.py (high 0.91)
[Full source available: Read this file with NEURALMIND_BYPASS=1]
Use skeleton to understand what a file does, how its functions relate, and which other files it depends on — without consuming tokens on the full source body.
search output format
1. authenticate_user (function) - score: 0.92
File: auth/handlers.py Community: 5
2. AuthMiddleware (class) - score: 0.87
File: auth/middleware.py Community: 5
3. hash_password (function) - score: 0.81
File: utils/crypto.py Community: 5
PostToolUse hooks — what happens automatically
If neuralmind install-hooks has been run for this project (check for .claude/settings.json), Claude Code automatically compresses tool outputs before you see them:
| Tool | What happens | Typical savings |
|---|---|---|
| Read | Raw source → graph skeleton (functions, rationales, call graph) | ~88% |
| Bash | Full output → error lines + warning lines + last 3 lines + summary | ~91% |
| Grep | Unlimited matches → capped at 25 + "N more hidden" pointer | varies |
This is fully automatic — you do not need to call any extra tools.
To bypass compression for a single command (e.g., when you need the full file body):
NEURALMIND_BYPASS=1 <your command>
After making code changes
The index does not auto-update unless a git post-commit hook was installed with neuralmind init-hook .. After significant code changes, rebuild manually:
neuralmind build . # incremental — only re-embeds changed nodes
neuralmind build . --force # full rebuild — re-embeds everything
MCP tool quick reference
| Tool | When to call | Required params | Returns |
|---|---|---|---|
neuralmind_wakeup |
Session start | project_path |
L0+L1 context string, token count |
neuralmind_query |
Code question | project_path, question |
L0–L3 context string, token count, reduction ratio |
neuralmind_search |
Find entity | project_path, query |
List of nodes with scores, file paths |
neuralmind_skeleton |
Explore file | project_path, file_path |
Functions + rationales + call graph + cross-file edges |
neuralmind_stats |
Check status | project_path |
Built status, node count, community count |
neuralmind_build |
Rebuild index | project_path |
Build stats dict |
neuralmind_benchmark |
Measure savings | project_path |
Per-query token counts and reduction ratios |
⚡ Two-phase optimization
┌─────────────────────────────────────────────────────────────┐
│ Phase 1: Retrieval — what to fetch │
│ neuralmind wakeup . → ~365 tokens (vs 50K raw) │
│ neuralmind query "?" → ~800 tokens (vs 2,700 raw) │
│ neuralmind_skeleton → graph-backed file view │
├─────────────────────────────────────────────────────────────┤
│ Phase 2: Consumption — what the agent actually sees │
│ PostToolUse hooks compress Read/Bash/Grep output │
│ File reads → graph skeleton (~88% reduction) │
│ Bash output → errors + summary (~91% reduction) │
│ Search results → capped at 25 matches │
└─────────────────────────────────────────────────────────────┘
Combined effect: 5–10× total reduction vs baseline Claude Code.
🎯 The Problem
You: "How does authentication work in my codebase?"
❌ Traditional: Load entire codebase → 50,000 tokens → $0.15–$3.75/query
✅ NeuralMind: Smart context → 766 tokens → $0.002–$0.06/query
💰 Real Savings
| Model | Without NeuralMind | With NeuralMind | Monthly Savings |
|---|---|---|---|
| Claude 3.5 Sonnet | $450/month | $7/month | $443 |
| GPT-4o | $750/month | $12/month | $738 |
| GPT-4.5 | $11,250/month | $180/month | $11,070 |
| Claude Opus | $2,250/month | $36/month | $2,214 |
Based on 100 queries/day. Pricing sources
✅ Does it work on your code? Prove it in 5 minutes.
NeuralMind benchmarks itself in CI on every PR. But your codebase isn't our fixture. The only way to know what it does for you is to measure it on your code.
pip install neuralmind graphifyy
cd /path/to/your-project
graphify update . && neuralmind build .
neuralmind benchmark .
You'll get back your actual reduction ratio and per-query token count — typically 30–80× on real repos. No telemetry, nothing uploaded, nothing committed. If the numbers don't justify it, pip uninstall neuralmind and move on — 5 minutes lost.
Want the dollar figure for your team?
neuralmind benchmark . --contribute
That flag produces a ready-to-share JSON blob with your project's numbers, the exact command that produced them, and an estimated monthly savings at your query volume. Paste it into Slack, a design doc, a PR — or optionally contribute it to the public leaderboard.
Full walkthrough: Does NeuralMind work on your codebase?
🚨 When do I reach for NeuralMind?
Two ways to decide: start with what's annoying you (symptoms), or start with what you're trying to achieve (goals).
Symptoms — "This is happening to me"
| What you notice | Reach for | Why it fixes it |
|---|---|---|
| Claude Code hits context limits mid-task | neuralmind install-hooks . |
Auto-compresses Read/Bash/Grep before the agent sees them (~88–91%) |
| My monthly LLM bill is climbing | neuralmind query + hooks |
40–70× fewer tokens per code question |
| I start every session re-pasting project structure | neuralmind wakeup . |
~400 tokens of orientation; pipe into any chat |
| Agent reads a 2,000-line file to answer about one function | neuralmind skeleton <file> |
Functions + call graph, no body; ~88% cheaper than Read |
grep floods the agent with hundreds of matches |
neuralmind install-hooks . |
Caps at 25 matches with "N more hidden" pointer |
| The agent is confidently wrong about what my code does | Start session with wakeup; ask with query |
Grounds the model in real structure instead of guessing |
| I want to query my codebase from ChatGPT / Gemini | neuralmind wakeup . | pbcopy |
Model-agnostic output; paste into any chat |
| Retrieval feels random across similar questions | neuralmind learn . |
Cooccurrence-based reranking adapts to your patterns |
| Index feels out of date after a refactor | neuralmind build . (or init-hook once) |
Incremental — only re-embeds changed nodes |
Goals — "What am I trying to solve for?"
| If your goal is… | Do this | Expected outcome |
|---|---|---|
| Cut LLM spend on code Q&A | install-hooks + use query for questions |
5–10× total reduction vs baseline agent |
| Faster, more grounded agent responses | wakeup at session start → query / skeleton during |
Fewer hallucinations; less re-exploration |
| Keep all code local (no SaaS, no telemetry) | Default install — no extra config | 100% offline; nothing leaves the machine |
| Work across Claude + GPT + Gemini with one index | Build once, pipe output into any model | Same context quality, model-agnostic |
| Make retrieval adapt to how your team queries | Enable memory (TTY prompt) + neuralmind learn . |
Relevance improves on repeat patterns |
| Measure savings for a manager or stakeholder | neuralmind benchmark . --json |
Per-query tokens, reduction ratios, dollar estimate |
| Auto-refresh the index as code changes | neuralmind init-hook . (git post-commit) |
Every commit rebuilds incrementally |
Still not sure?
You probably don't need NeuralMind if:
- Your codebase is under ~5K tokens total (just paste the whole thing in).
- You don't use an AI coding agent.
- You only want inline completions — use Copilot or Cursor directly.
You almost certainly want NeuralMind if any row above describes a recurring frustration, or if your LLM bill has crossed the point where a 40–70× reduction is worth 5 minutes of setup.
See the use-case walkthroughs for step-by-step guides matched to your situation.
👤 Who is NeuralMind for?
| You are… | NeuralMind gives you… |
|---|---|
| A Claude Code user watching your token bill climb | PostToolUse compression on every Read/Bash/Grep + ~60× smaller query context |
| A Cursor user who wants semantic retrieval outside Cursor too | CLI + MCP server that works in any agent with the same index |
| A Cline / Continue user without a built-in codebase index | Drop-in MCP neuralmind_query and neuralmind_skeleton tools |
| Running OpenAI / Gemini / local models | Model-agnostic context — pipe wakeup / query output into any chat |
| A solo developer with a growing monorepo | Incremental rebuilds + learning that adapts to your query patterns |
| A team tech lead worried about LLM spend | Measurable per-query token reduction with neuralmind benchmark |
| A security-conscious engineer or in a regulated industry | 100% local, offline, no code leaves the machine |
| A researcher / hobbyist exploring LLM cost optimization | Open-source reference implementation of two-phase token optimization |
Not a fit if: you need cross-repo search across a whole organization (use Sourcegraph Cody), or you only want inline completions (use Copilot).
🏢 Enterprise Use Cases
NeuralMind solves specific pain points for companies at scale:
Regulated Industries (Finance, Healthcare, Legal, Government)
Challenge: AI tools can't be trusted if they can't explain decisions.
NeuralMind Solution:
- Every recommendation is traceable to extracted code (auditable, not guessed)
- Works 100% on-premise — no cloud, no data transfer, zero exfiltration risk
- Meets GDPR, HIPAA, SOC 2, and ISO 27001 requirements
- Explainability by design — see what code fed each decision
Enterprises with Proprietary / Sensitive Code
Challenge: Sending code to external APIs or SaaS models is a legal no-go.
NeuralMind Solution:
- All processing stays on your hardware or internal network
- No ChromaDB cloud — uses local SQLite-compatible storage
- No API keys, no authentication to external vendors
- Process trade secrets, algorithms, and confidential code safely
Large Organizations Scaling AI Coding Assistant Spend
Challenge: 100 developers × Claude Sonnet queries = $50K+/month LLM bill
NeuralMind Solution:
- 40–70× token reduction per query → cut budget by 95%+
- Explicit benchmarking (
neuralmind benchmark) to show ROI to finance - Measurable savings: baseline vs. optimized (in dollars)
- Deploy once, benefit across all teams using the same codebase
Internal Platform Teams & Shared Infrastructure
Challenge: Different teams query the same codebase; results are inconsistent.
NeuralMind Solution:
- Build the index once → share across all teams
- Cooccurrence learning adapts to your org's query patterns (
neuralmind learn) - Consistent, reproducible context for every question
- Single source of truth for "how does this system work?"
Teams Needing Offline/Disconnected Development
Challenge: Regulated environments, air-gapped networks, or unreliable connectivity.
NeuralMind Solution:
- No internet required after the initial install
- Pre-build the index on a connected machine, ship it in source control
- Works in submarines, rural offices, flight-mode development
- No API rate limiting or service outages
🤔 Why NeuralMind vs. Heuristic-Only
Both approaches are valid; the tradeoff is retrieval quality vs. simplicity.
| Approach | Token Reduction | Accuracy | Deps | Learns Over Time |
|---|---|---|---|---|
| Heuristic-only (no embeddings) | ~33x (~97% fewer tokens) | 70-80% top-5 (community baseline) | None | No |
| NeuralMind | 40-70x | Project-dependent; evaluate against the same top-5 query set | ChromaDB | Yes (cooccurrence patterns) |
NeuralMind does include a dependency (ChromaDB), but it still runs entirely offline — no API calls, no cloud services, no data leaves your machine.
If your priority is strict zero-dependency operation, heuristic-only is the simplest path. If your priority is stronger semantic retrieval and adaptive relevance, NeuralMind is the better fit.
⚖️ NeuralMind vs. Alternatives
Short answers to "why not just use X?". Each row links to a deeper page.
| Compared against | Short verdict |
|---|---|
Cursor @codebase |
Works only in Cursor; NeuralMind works in any agent and adds tool-output compression |
| Aider repo-map | Aider is syntactic only; NeuralMind adds semantic retrieval and compression |
| Sourcegraph Cody | Cody is server-hosted and org-wide; NeuralMind is local and per-project |
| Continue / Cline | Those are agent runtimes; NeuralMind is the context/compression layer underneath |
| GitHub Copilot | Copilot is hosted completions; NeuralMind is local context for any agent |
| Windsurf / Codeium | Vertically integrated IDE; NeuralMind is editor- and model-agnostic |
| Claude Projects | Projects reload all files every turn; NeuralMind retrieves only what the query needs |
| Prompt caching | Caching amortizes a big prompt; NeuralMind makes the prompt small — combine both |
| LangChain / LlamaIndex for code | Frameworks you assemble; NeuralMind is the assembled default for code agents |
| Long context windows (1M/2M) | Possible ≠ cheap — NeuralMind gives ~60× cost reduction on the same model |
| Generic RAG over a codebase | Text chunking loses structure; NeuralMind keeps the call graph |
| Tree-sitter / ctags / grep | Deterministic but syntactic; use alongside NeuralMind, not instead of |
Full comparison index: docs/comparisons/.
🚀 Quick Start (humans)
# Install
pip install neuralmind graphifyy
# Go to your project
cd your-project
# Generate knowledge graph (requires graphify)
graphify update .
# Build neural index
neuralmind build .
# (Optional) Install Claude Code PostToolUse compression hooks
neuralmind install-hooks .
# (Optional) Auto-rebuild on every git commit
neuralmind init-hook .
# Start using
neuralmind wakeup .
neuralmind query . "How does authentication work?"
neuralmind skeleton src/auth/handlers.py
🔧 How It Works
NeuralMind wraps a graphify knowledge graph (graphify-out/graph.json) in a ChromaDB vector store.
When you query it, a 4-layer progressive disclosure system loads only the context relevant to
your question.
┌─────────────────────────────────────────────────────────────┐
│ Layer 0: Project Identity (~100 tokens) — ALWAYS LOADED │
│ Source: CLAUDE.md / mempalace.yaml / README first line │
├─────────────────────────────────────────────────────────────┤
│ Layer 1: Architecture Summary (~500 tokens) — ALWAYS LOADED │
│ Source: Community distribution + GRAPH_REPORT.md │
├─────────────────────────────────────────────────────────────┤
│ Layer 2: Relevant Modules (~300–500 tokens) — QUERY-AWARE │
│ Source: Top 3 clusters semantically matching the query │
├─────────────────────────────────────────────────────────────┤
│ Layer 3: Semantic Search (~300–500 tokens) — QUERY-AWARE │
│ Source: ChromaDB similarity search over all graph nodes │
└─────────────────────────────────────────────────────────────┘
Total: ~800–1,100 tokens vs 50,000+ for the full codebase
Prerequisites: NeuralMind requires graphify update . to have been run first. This produces:
graphify-out/graph.json— the knowledge graph (required)graphify-out/GRAPH_REPORT.md— architecture summary (enriches L1, optional)graphify-out/neuralmind_db/— ChromaDB vector store (created byneuralmind build)
🖥️ Complete CLI Reference
neuralmind build
Build or incrementally update the neural index from graphify-out/graph.json.
neuralmind build [project_path] [--force]
| Argument/Option | Default | Description |
|---|---|---|
project_path |
. |
Project root containing graphify-out/graph.json |
--force, -f |
off | Re-embed every node even if unchanged |
neuralmind build .
neuralmind build /path/to/project --force
Output: nodes processed, added, updated, skipped, communities indexed, build duration.
neuralmind wakeup
Get minimal project context for starting a session (~400–600 tokens, L0 + L1 only).
neuralmind wakeup <project_path> [--json]
neuralmind wakeup .
neuralmind wakeup . --json
neuralmind wakeup . > CONTEXT.md
neuralmind query
Query the codebase with natural language (~800–1,100 tokens, all 4 layers).
neuralmind query <project_path> "<question>" [--json]
neuralmind query . "How does authentication work?"
neuralmind query . "What are the main API endpoints?" --json
neuralmind query /path/to/project "Explain the database schema"
On first run from a TTY, you will be prompted once to enable local query memory logging.
Disable with NEURALMIND_MEMORY=0.
neuralmind search
Direct semantic search — returns code entities ranked by similarity to the query.
neuralmind search <project_path> "<query>" [--n N] [--json]
| Option | Default | Description |
|---|---|---|
--n |
10 | Maximum number of results |
--json, -j |
off | Machine-readable JSON output |
neuralmind search . "authentication"
neuralmind search . "database connection" --n 5
neuralmind search . "PaymentController" --json
neuralmind skeleton
Print a compact graph-backed view of a file without loading full source (~88% cheaper than Read).
neuralmind skeleton <file_path> [--project-path .] [--json]
| Option | Default | Description |
|---|---|---|
--project-path |
. |
Project root (where the index lives) |
--json, -j |
off | Machine-readable JSON output |
neuralmind skeleton src/auth/handlers.py
neuralmind skeleton src/auth/handlers.py --project-path /my/project
neuralmind skeleton src/auth/handlers.py --json
Output: function list with line numbers and rationales, internal call graph, cross-file edges
(imports, data sharing), and a pointer to the full source for when you need it.
neuralmind benchmark
Measure token reduction using a set of sample queries.
neuralmind benchmark <project_path> [--json]
neuralmind benchmark .
neuralmind benchmark . --json
neuralmind stats
Show index status and statistics.
neuralmind stats <project_path> [--json]
neuralmind stats .
neuralmind stats . --json # {"built": true, "total_nodes": 241, "communities": 23, ...}
neuralmind learn
Analyze logged query history to discover module cooccurrence patterns. Improves future query
relevance automatically.
neuralmind learn <project_path>
neuralmind learn .
Reads .neuralmind/memory/query_events.jsonl, writes .neuralmind/learned_patterns.json.
The next neuralmind query applies boosted reranking automatically.
neuralmind install-hooks
Install or remove Claude Code PostToolUse compression hooks.
neuralmind install-hooks [project_path] [--global] [--uninstall]
| Option | Description |
|---|---|
--global |
Install in ~/.claude/settings.json (affects all projects) |
--uninstall |
Remove NeuralMind hooks only; preserves other tools' hooks |
neuralmind install-hooks . # project-scoped
neuralmind install-hooks --global # all projects
neuralmind install-hooks --uninstall # remove project hooks
neuralmind install-hooks --uninstall --global # remove global hooks
neuralmind init-hook
Install a Git post-commit hook that auto-rebuilds the index after every commit.
Safe and idempotent — coexists with other tools' hook contributions.
neuralmind init-hook [project_path]
neuralmind init-hook .
neuralmind init-hook /path/to/project
🔌 MCP Server
NeuralMind ships a Model Context Protocol server (neuralmind-mcp) that exposes all tools
to MCP-compatible agents.
Starting the server
neuralmind-mcp
# or
python -m neuralmind.mcp_server
Claude Desktop configuration
{
"mcpServers": {
"neuralmind": {
"command": "neuralmind-mcp",
"args": ["/absolute/path/to/project"]
}
}
}
Config file locations:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json - Linux:
~/.config/Claude/claude_desktop_config.json
Claude Code / Cursor project-scoped auto-registration
Drop a .mcp.json at your project root:
{
"mcpServers": {
"neuralmind": {
"command": "neuralmind-mcp",
"args": ["."]
}
}
}
MCP tool schemas
neuralmind_wakeup
{
"project_path": "string (required) — absolute path to project root"
}
Returns:
{
"context": "string",
"tokens": 412,
"reduction_ratio": 121.4,
"layers": ["L0", "L1"]
}
neuralmind_query
{
"project_path": "string (required)",
"question": "string (required) — natural language question"
}
Returns:
{
"context": "string",
"tokens": 847,
"reduction_ratio": 59.0,
"layers": ["L0", "L1", "L2", "L3"],
"communities_loaded": [5, 12],
"search_hits": 8
}
neuralmind_search
{
"project_path": "string (required)",
"query": "string (required)",
"n": 10
}
Returns array of:
{ "id": "node_id", "label": "authenticate_user", "file_type": "code",
"source_file": "auth/handlers.py", "score": 0.92 }
neuralmind_skeleton
{
"project_path": "string (required)",
"file_path": "string (required) — absolute or project-relative path"
}
Returns:
{ "file": "src/auth/handlers.py", "skeleton": "# src/auth/handlers.py ...", "chars": 620, "indexed": true }
neuralmind_build
{
"project_path": "string (required)",
"force": false
}
Returns:
{
"success": true,
"nodes_total": 241,
"nodes_added": 5,
"nodes_updated": 2,
"nodes_skipped": 234,
"communities": 23,
"duration_seconds": 3.1
}
neuralmind_stats
{ "project_path": "string (required)" }
Returns:
{ "built": true, "total_nodes": 241, "communities": 23, "db_path": "..." }
neuralmind_benchmark
{ "project_path": "string (required)" }
Returns:
{
"project": "myapp",
"wakeup_tokens": 341,
"avg_query_tokens": 739,
"avg_reduction_ratio": 65.6,
"results": [...]
}
🪝 PostToolUse Compression
When neuralmind install-hooks has been run, Claude Code automatically applies these transforms
to every tool output before the agent sees it.
Read → skeleton
Raw source files are replaced with the graph skeleton (functions + rationales + call graph +
cross-file edges). This is ~88% smaller and contains the structural information agents need most.
To get the full source anyway:
NEURALMIND_BYPASS=1 <command>
Bash → filtered output
Long bash output is reduced to:
- All
error/ERROR/FAIL/traceback/warninglines - All summary lines (
=====,passed,failed,Finished,Done in, etc.) - Last 3 lines verbatim
- Header:
[neuralmind: bash compressed, exit=N]
All errors and failures are always preserved. Routine pip/npm/build chatter is dropped.
Grep → capped results
Search results are capped at 25 matches with a [N more hidden] note appended.
Prevents context flooding from repository-wide searches.
Tunable thresholds
| Variable | Default | Description |
|---|---|---|
NEURALMIND_BYPASS |
unset | Set to 1 to disable all compression |
NEURALMIND_BASH_TAIL |
3 |
Lines to keep verbatim from end of bash output |
NEURALMIND_BASH_MAX_CHARS |
3000 |
Below this size, bash output is not compressed |
NEURALMIND_SEARCH_MAX |
25 |
Max grep/search matches before capping |
NEURALMIND_OFFLOAD_THRESHOLD |
15000 |
Chars above which content is written to a temp file |
🧠 Continual Learning
NeuralMind optionally learns from your query patterns to improve future relevance.
How it works
- Collect — Each
neuralmind querylogs which modules appeared in the result to.neuralmind/memory/query_events.jsonl(opt-in, local only, zero overhead) - Learn —
neuralmind learn .analyzes cooccurrence: which clusters appear together across queries - Improve — The next
neuralmind queryapplies a+0.3reranking boost to modules that
co-occur with the current query's top matches - Repeat — The system gets smarter as you use it
Opt-in / consent
On first TTY query:
NeuralMind can keep local query memory (project + global JSONL) to improve future retrieval.
Enable? [y/N]:
Consent saved to ~/.neuralmind/memory_consent.json. Disable at any time:
export NEURALMIND_MEMORY=0 # disable query logging
export NEURALMIND_LEARNING=0 # disable pattern application
File locations
~/.neuralmind/
├── memory_consent.json # consent flag
└── memory/
└── query_events.jsonl # global event log
<project>/.neuralmind/
├── memory/
│ └── query_events.jsonl # project-specific events
└── learned_patterns.json # created by: neuralmind learn .
Privacy
100% local — nothing is sent to any server. Delete ~/.neuralmind/ and <project>/.neuralmind/
at any time to remove all learning data.
⏰ Keeping the Index Fresh
Automatic — Git post-commit hook (recommended)
neuralmind init-hook .
After every commit, the hook runs:
neuralmind build . 2>/dev/null && echo "[neuralmind] OK"
Manual
graphify update .
neuralmind build .
Scheduled — cron
0 6 * * * cd /path/to/project && graphify update . && neuralmind build .
CI/CD — GitHub Actions
- run: pip install neuralmind graphifyy
- run: graphify update . && neuralmind build .
- run: neuralmind wakeup . > AI_CONTEXT.md
🔌 Compatibility
| Component | Works With | Notes |
|---|---|---|
| CLI | Any environment | Pure Python, no daemon required |
| MCP Server | Claude Code, Claude Desktop, Cursor, Cline, Continue, any MCP client | pip install "neuralmind[mcp]" |
| PostToolUse Hooks | Claude Code only | Uses Claude Code's PostToolUse hook system |
| Git hook | Any git workflow | Appends to existing post-commit, idempotent |
| Copy-paste | ChatGPT, Gemini, any LLM | neuralmind wakeup . | pbcopy |
Quick-start by tool
Claude Code — full two-phase optimizationpip install neuralmind graphifyy
cd your-project
graphify update .
neuralmind build .
neuralmind install-hooks . # PostToolUse compression
neuralmind init-hook . # auto-rebuild on commit (optional)
Then use MCP tools in sessions: neuralmind_wakeup, neuralmind_query, neuralmind_skeleton.
pip install "neuralmind[mcp]" graphifyy
graphify update .
neuralmind build .
Add to your MCP config:
{ "mcpServers": { "neuralmind": { "command": "neuralmind-mcp" } } }
neuralmind wakeup . | pbcopy # macOS — paste into chat
neuralmind query . "question" # get context for a specific question
✨ What's New in v0.3.x
| Feature | Version | Details |
|---|---|---|
| Memory Collection | v0.3.0 | Local JSONL storage for query events |
| Opt-in Consent | v0.3.0 | One-time TTY prompt, env var overrides |
| EmbeddingBackend abstraction | v0.3.1 | Pluggable vector backend (Pinecone/Weaviate ready) |
| Pattern Learning | v0.3.2 | neuralmind learn . analyzes cooccurrence |
| Smart Reranking | v0.3.2 | L3 results boosted by learned patterns |
| Accurate Build Stats | v0.3.3 | Correctly distinguishes added vs updated nodes |
| Documentation polish | v0.3.4 | CLI flags sync, Setup Guide, agent guidance in README |
📊 Benchmarks
NeuralMind benchmarks itself on every pull request. A hermetic fixture (tests/fixtures/sample_project/) plus a committed query set (tests/fixtures/benchmark_queries.json) runs through the full retrieval pipeline, and CI fails if aggregate reduction drops below a conservative floor (currently 4× on the small fixture — the fixture is intentionally tiny, real repos consistently hit 40–70× as shown below).
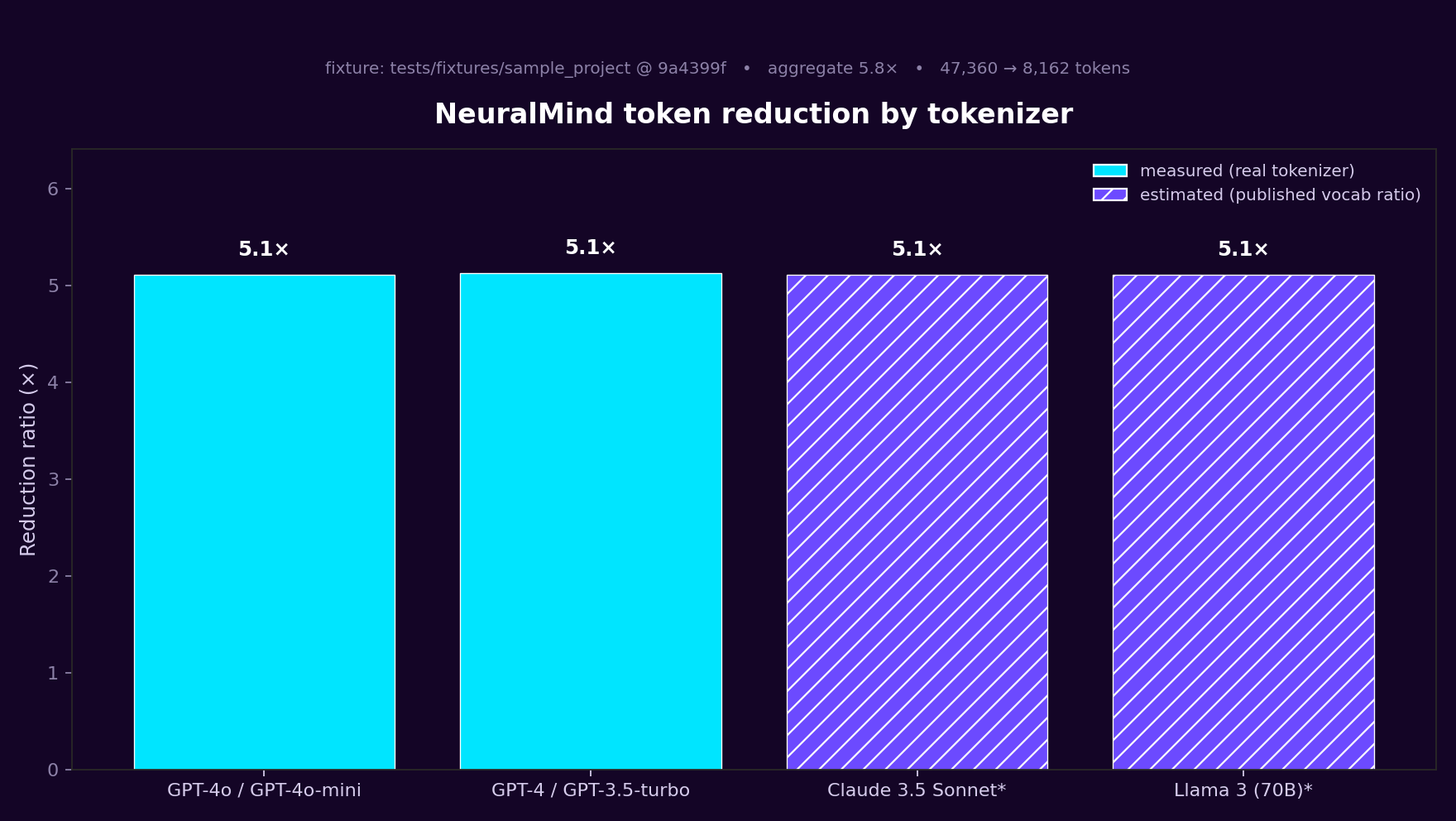
What CI measures on every PR
- Phase 1 — Reduction. Naive baseline (every
.pyfile in the fixture concatenated) vsNeuralMind.query()output, per query. All tokens counted withtiktoken. - Phase 2 — Learning uplift. Same queries run cold, then after seeding memory and running
neuralmind learn. Reports the delta in reduction ratio and top-k retrieval hit rate. On a 500-line fixture the numerical uplift is modest by design — the test proves the mechanism persists, not that it's magic. - Per-model breakdown. GPT-4o and GPT-4/3.5 counts are measured via real tiktoken encodings. Claude uses the Anthropic SDK tokenizer when available, else a clearly-labeled estimate derived from published vocab ratios. Llama is always estimated. No fabricated numbers anywhere.
- Memory persistence.
tests/test_memory_persistence.pyasserts events are logged,neuralmind learnproduces a patterns file, and subsequent queries load it without error.
Community benchmarks
Real-world numbers submitted by users. Your code never leaves your machine — you submit a PR (or an issue, which a maintainer converts to a PR) with only the numbers. CI validates every entry against the schema and re-renders this table automatically.
| Project | Lang | Nodes | Wakeup | Avg Query | Reduction | Model | Submitted |
|---|---|---|---|---|---|---|---|
| cmmc20 | JavaScript | 241 | 341 | 739 | 65.6× | Claude 3.5 Sonnet | @dfrostar · 2025-10-01 |
| mempalace | Python | 1,626 | 412 | 891 | 46.0× | Claude 3.5 Sonnet | @dfrostar · 2025-10-01 |
2 submission(s). See the JSON data for notes and verification commands.
Submit yours:
- Easy path: open a benchmark submission issue — fill out a form, a maintainer converts it to a PR.
- PR directly: add an entry to
docs/community-benchmarks.jsonand runpython scripts/render_community_table.py --inject README.mdto regenerate the table. Schema:community-benchmarks.schema.json.
All entries include the exact neuralmind command that produced them, so reviewers (and any reader) can audit the numbers.
Reproduce locally (on our fixture)
pip install . tiktoken matplotlib graphifyy
graphify update tests/fixtures/sample_project
neuralmind build tests/fixtures/sample_project --force
python -m tests.benchmark.run # phase 1 + phase 2
python -m tests.benchmark.multi_model # per-model breakdown
python scripts/generate_chart.py # refreshes the PNG above
Full machine-readable results land in tests/benchmark/results.json, human-readable report in tests/benchmark/report.md.
Reproduce on your code
Don't just trust numbers from our fixture — run it on your repo:
pip install neuralmind graphifyy
graphify update . && neuralmind build .
neuralmind benchmark . --contribute
Output shows your reduction ratio, tokens per query, and estimated monthly savings at Claude 3.5 Sonnet pricing. Full walkthrough: Does NeuralMind work on your codebase?
Retrieval quality baseline
- Heuristic-only baseline (community-reported): 70–80% top-5 retrieval accuracy
- NeuralMind target on the same query set: exceed that baseline via semantic retrieval + learned cooccurrence reranking
The pytest regression gate (tests/test_benchmark_regression.py) currently enforces ≥50% top-k hit rate on the fixture plus ≥4× reduction (low because the fixture is tiny; real repos measure 10× higher).
❓ FAQ
How much does NeuralMind reduce Claude / GPT token costs?
Measured on real repos: 40–70× reduction per query (see Benchmarks). For a team running 100 queries/day on Claude Sonnet, that is roughly $450/month → $7/month. Exact savings depend on codebase size and model pricing.
Does NeuralMind work outside Claude Code?
Yes. The CLI works anywhere Python runs; the MCP server works with Cursor, Cline, Continue, Claude Desktop, and any MCP-compatible agent. For non-MCP tools like ChatGPT or Gemini, neuralmind wakeup . | pbcopy pipes context into a regular chat window. Only the PostToolUse compression hooks are Claude-Code-specific.
Does my code leave my machine?
No. NeuralMind is fully offline — no API calls, no cloud services. Embeddings run locally via ChromaDB, and the knowledge graph is stored in graphify-out/ in your project. Query memory (optional, opt-in) is written to .neuralmind/ on disk.
Is this RAG? How is it different from LangChain or LlamaIndex?
It is a form of RAG, but specialized for code. Instead of chunking text, NeuralMind retrieves over a knowledge graph of code entities (functions, classes, clusters) with a fixed 4-layer structure. That keeps the call graph intact and produces a token-budgeted output instead of a flat list of chunks. See vs. LangChain/LlamaIndex.
I have a 1M context window now — do I still need this?
Long context makes it possible to stuff a whole repo in; it does not make it cheap. You still pay per input token, so a 50K-token repo at Claude Sonnet rates costs ~$0.15 every turn. NeuralMind drops that to ~$0.002. See vs. long context.
Does it support my language?
Any language graphify supports (Python, JavaScript/TypeScript, and others via tree-sitter). NeuralMind consumes graphify-out/graph.json — if graphify can index it, NeuralMind can query it.
What is the difference between wakeup, query, and skeleton?
wakeup— ~400 tokens of project orientation (L0 + L1). Run it at session start.query— ~800–1,100 tokens for a specific natural-language question (L0–L3).skeleton— compact view of a single file (functions + call graph + cross-file edges). Use beforeRead.
How does the PostToolUse compression work?
When neuralmind install-hooks . has been run, Claude Code invokes NeuralMind after every Read/Bash/Grep tool call but before the agent sees the output. Read becomes a skeleton (~88% smaller), Bash keeps errors + last 3 lines (~91% smaller), Grep caps at 25 matches. Set NEURALMIND_BYPASS=1 on any command to opt out.
Can I use NeuralMind without a knowledge graph?
No — the knowledge graph (graphify-out/graph.json) is the source of truth. Run graphify update . first, then neuralmind build ..
Does it auto-update when I change code?
Only if you install the git post-commit hook with neuralmind init-hook .. Otherwise run neuralmind build . manually; it is incremental and only re-embeds changed nodes.
What do I do if retrieval quality is poor on my repo?
- Check that
neuralmind stats .reports all your nodes indexed. - Run
neuralmind benchmark .to see reduction ratios. - Enable query memory (it prompts on first TTY run) and periodically run
neuralmind learn .— cooccurrence-based reranking improves relevance on your actual queries. - Open an issue with the query and expected result — retrieval quality is the thing we most want to improve.
📚 Documentation
| Resource | Contents |
|---|---|
| Setup Guide | First-time setup for Claude Code, Claude Desktop, Cursor, any LLM |
| CLI Reference | All commands and options |
| Learning Guide | Continual learning details |
| API Reference | Python API (NeuralMind, ContextResult, TokenBudget) |
| Architecture | 4-layer progressive disclosure design |
| Integration Guide | MCP, CI/CD, VS Code, JetBrains |
| Troubleshooting | Common issues and fixes |
| Brain-like Learning | Design rationale for the learning system |
| Use Cases | Step-by-step walkthroughs: Claude Code, cost optimization, any-LLM, offline/regulated, growing monorepo |
| Comparisons | NeuralMind vs. Cursor, Copilot, Cody, Aider, Claude Projects, LangChain, long context, prompt caching, RAG, tree-sitter |
| USAGE.md | Extended usage examples |
🤝 Contributing
See CONTRIBUTING.md for guidelines.
📄 License
MIT License — see LICENSE for details.
⭐ Star this repo if NeuralMind saves you money!
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi