drt
Health Uyari
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 8 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
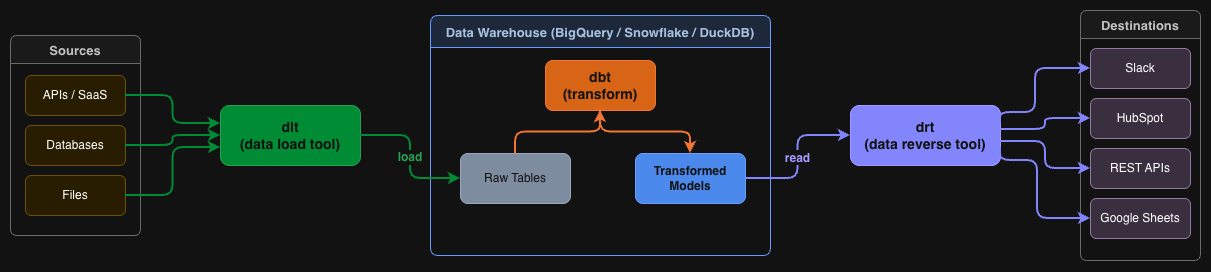
This tool is a reverse ETL (Extract, Transform, Load) solution that syncs data from your data warehouse to external services. It is designed for a code-first data stack, operating declaratively via YAML configurations and a CLI interface.
Security Assessment
The overall risk is Medium. By design, the application reads from data warehouses and sends data outbound to external REST APIs, Slack, Google Sheets, and HubSpot. While the automated code scan of 12 files found no dangerous patterns, hardcoded secrets, or malicious code, the tool inherently handles sensitive database information and makes external network requests based on user-defined configurations. Standard security practices, such as using environment variables or secret managers for database credentials and API keys, are highly recommended.
Quality Assessment
The project is quite new but actively maintained, evidenced by a repository push as recent as today. It uses a standard Apache-2.0 license, and the developer experience appears polished with CI testing and detailed documentation. However, community trust is currently minimal. The repository has only 8 GitHub stars, indicating a very low adoption rate. This means potential bugs or security edge cases might not yet be fully identified or battle-tested by a wider audience.
Verdict
Use with caution — the code itself appears safe and free of obvious threats, but its low community adoption requires you to independently verify how it handles your sensitive data pipelines.
Reverse ETL for the code-first data stack
drt — data reverse tool
Reverse ETL for the code-first data stack.
![]()


drt syncs data from your data warehouse to external services — declaratively, via YAML and CLI.
Think dbt run → drt run. Same developer experience, opposite data direction.

pip install drt-core # core (DuckDB included)
drt init && drt run
Why drt?
| Problem | drt's answer |
|---|---|
| Census/Hightouch are expensive SaaS | Free, self-hosted OSS |
| GUI-first tools don't fit CI/CD | CLI + YAML, Git-native |
| dbt/dlt ecosystem has no reverse leg | Same philosophy, same DX |
| LLM/MCP era makes GUI SaaS overkill | LLM-native by design |
Quickstart
No cloud accounts needed — runs locally with DuckDB in about 5 minutes.
1. Install
pip install drt-core
For cloud sources:
pip install drt-core[bigquery],drt-core[postgres], etc.
2. Set up a project
mkdir my-drt-project && cd my-drt-project
drt init # select "duckdb" as source
3. Create sample data
python -c "
import duckdb
c = duckdb.connect('warehouse.duckdb')
c.execute('''CREATE TABLE IF NOT EXISTS users AS SELECT * FROM (VALUES
(1, 'Alice', '[email protected]'),
(2, 'Bob', '[email protected]'),
(3, 'Carol', '[email protected]')
) t(id, name, email)''')
c.close()
"
4. Create a sync
# syncs/post_users.yml
name: post_users
description: "POST user records to an API"
model: ref('users')
destination:
type: rest_api
url: "https://httpbin.org/post"
method: POST
headers:
Content-Type: "application/json"
body_template: |
{ "id": {{ row.id }}, "name": "{{ row.name }}", "email": "{{ row.email }}" }
sync:
mode: full
batch_size: 1
on_error: fail
5. Run
drt run --dry-run # preview, no data sent
drt run # run for real
drt status # check results
See examples/ for more: Slack, Google Sheets, HubSpot, GitHub Actions, etc.
CLI Reference
drt init # initialize project
drt list # list sync definitions
drt run # run all syncs
drt run --select <name> # run a specific sync
drt run --dry-run # dry run
drt run --verbose # show row-level error details
drt validate # validate sync YAML configs
drt status # show recent sync status
drt status --verbose # show per-row error details
drt mcp run # start MCP server (requires drt-core[mcp])
MCP Server
Connect drt to Claude, Cursor, or any MCP-compatible client so you can run syncs, check status, and validate configs without leaving your AI environment.
pip install drt-core[mcp]
drt mcp run
Claude Desktop (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"drt": {
"command": "drt",
"args": ["mcp", "run"]
}
}
}
Available MCP tools:
| Tool | What it does |
|---|---|
drt_list_syncs |
List all sync definitions |
drt_run_sync |
Run a sync (supports dry_run) |
drt_get_status |
Get last run result(s) |
drt_validate |
Validate sync YAML configs |
drt_get_schema |
Return JSON Schema for config files |
AI Skills for Claude Code
Install the official Claude Code skills to generate YAML, debug failures, and migrate from other tools — all from the chat interface.
Install via Plugin Marketplace (recommended)
/plugin marketplace add drt-hub/drt
/plugin install drt@drt-hub
Tip: Enable auto-update so you always get the latest skills when drt is updated:
/plugin→ Marketplaces → drt-hub → Enable auto-update
Manual install (slash commands)
Copy the files from .claude/commands/ into your drt project's .claude/commands/ directory.
| Skill | Trigger | What it does |
|---|---|---|
/drt-create-sync |
"create a sync" | Generates valid sync YAML from your intent |
/drt-debug |
"sync failed" | Diagnoses errors and suggests fixes |
/drt-init |
"set up drt" | Guides through project initialization |
/drt-migrate |
"migrate from Census" | Converts existing configs to drt YAML |
Connectors
| Type | Name | Status | Install |
|---|---|---|---|
| Source | BigQuery | ✅ v0.1 | pip install drt-core[bigquery] |
| Source | DuckDB | ✅ v0.1 | (core) |
| Source | PostgreSQL | ✅ v0.1 | pip install drt-core[postgres] |
| Source | Snowflake | 🗓 planned | pip install drt-core[snowflake] |
| Source | SQLite | ✅ v0.4.2 | (core) |
| Source | Redshift | ✅ v0.3.4 | pip install drt-core[redshift] |
| Source | MySQL | 🗓 planned | pip install drt-core[mysql] |
| Destination | REST API | ✅ v0.1 | (core) |
| Destination | Slack Incoming Webhook | ✅ v0.1 | (core) |
| Destination | Discord Webhook | ✅ v0.4.2 | (core) |
| Destination | GitHub Actions (workflow_dispatch) | ✅ v0.1 | (core) |
| Destination | HubSpot (Contacts / Deals / Companies) | ✅ v0.1 | (core) |
| Destination | Google Sheets | ✅ v0.4 | pip install drt-core[sheets] |
| Destination | PostgreSQL (upsert) | ✅ v0.4 | pip install drt-core[postgres] |
| Destination | MySQL (upsert) | ✅ v0.4 | pip install drt-core[mysql] |
| Destination | CSV / JSON file | 🗓 v0.5 | (core) |
| Destination | Salesforce | 🗓 v0.6 | pip install drt-core[salesforce] |
| Destination | Notion | 🗓 planned | (core) |
| Destination | Linear | 🗓 planned | (core) |
| Destination | SendGrid | 🗓 planned | (core) |
| Integration | Dagster | ✅ v0.4 | pip install dagster-drt |
| Integration | Airflow | 🗓 v0.6 | pip install airflow-drt |
| Integration | dbt manifest reader | ✅ v0.4 | (core) |
Roadmap
Detailed plans & progress → GitHub Milestones
Looking to contribute? → Good First Issues
| Version | Focus |
|---|---|
| v0.1 ✅ | BigQuery / DuckDB / Postgres sources · REST API / Slack / GitHub Actions / HubSpot destinations · CLI · dry-run |
| v0.2 ✅ | Incremental sync (cursor_field watermark) · retry config per-sync |
| v0.3 ✅ | MCP Server (drt mcp run) · AI Skills for Claude Code · LLM-readable docs · row-level errors · security hardening · Redshift source |
| v0.4 ✅ | Google Sheets / PostgreSQL / MySQL destinations · dagster-drt · dbt manifest reader · type safety overhaul |
| v0.5 | Snowflake source · CSV/JSON destination · test coverage |
| v0.6 | Salesforce destination · Airflow integration |
| v1.x | Rust engine (PyO3) |
Orchestration: dagster-drt
Community-maintained Dagster integration. Expose drt syncs as Dagster assets with full observability.
pip install dagster-drt
from dagster import Definitions
from dagster_drt import drt_assets, DagsterDrtTranslator
class MyTranslator(DagsterDrtTranslator):
def get_group_name(self, sync_config):
return "reverse_etl"
defs = Definitions(
assets=drt_assets(
project_dir="path/to/drt-project",
dagster_drt_translator=MyTranslator(),
)
)
See dagster-drt README for full API docs (Translator, DrtConfig dry-run, MaterializeResult).
Ecosystem
drt is designed to work alongside, not against, the modern data stack:
Contributing
See CONTRIBUTING.md.
Disclaimer
drt is an independent open-source project and is not affiliated with,
endorsed by, or sponsored by dbt Labs, dlt-hub, or any other company.
"dbt" is a registered trademark of dbt Labs, Inc.
"dlt" is a project maintained by dlt-hub.
drt is designed to complement these tools as part of the modern data stack,
but is a separate project with its own codebase and maintainers.
License
Apache 2.0 — see LICENSE.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi