pituitary
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 21 GitHub stars
Code Fail
- rm -rf — Recursive force deletion command in .github/workflows/release.yml
- process.env — Environment variable access in action.yml
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Catch spec drift before it catches you. Indexes your specs, docs, and decision records, then detects overlap, contradictions, stale docs, and code that drifts from what was decided.

Pituitary
Consistency governance for AI-native development.
Catch drifts before they catch you.
![]()

What It Catches · Quick Start · Agent · CI · Cheatsheet · Reference
For developers and teams where human+AI continuously produce specs, docs, and decisions that should agree — and silently stop agreeing.
Watch on asciinema for the interactive version.
Single binary. No Docker. No API keys required. One governance SQLite file plus one local Stroma snapshot.
The core shipped slice is local and CLI-first. The MCP server, CI wiring, and provider-backed semantic runtimes are optional wrappers around that same deterministic core.
What It Catches
You already know your docs drift. You fight it with LLM cleanup passes. The LLM says "all clean" — but it only covered what fit in the context window. The rest keeps rotting. Next PR introduces fresh contradictions on top of the ones that were never actually fixed. It's a treadmill that feels productive but never converges. Meanwhile the token costs pile up: false starts, misdirections, and wasted context directly caused by drifting issues, conflicting specs, and obsolete docs.
Pituitary replaces that treadmill with a structural guarantee: it indexes the entire corpus and checks all of it, every time. On a real repo with 11 specs and 29 docs, it found 90 deprecated-term violations across 22 artifacts and 7 semantic contradictions. The project direction was plagued by doc drifts, runtime contract contradictions, and deprecated terminology surfacing everywhere — Pituitary rescued it. Across multiple repos, it becomes the single point of truth where governance converges.
Overlapping decisions. A new spec covers ground an existing one already handles.
Stale docs. A spec changed, or a code diff implies docs likely went stale, but the CLAUDE.md, AGENTS.md, runbooks, and guides that reference it weren't updated.
Code that contradicts specs. Pipe your diff in before you merge:
git diff origin/main...HEAD | pituitary check-compliance --diff-file -
Terminology drift. The team adopted new language but old terms persist across your docs and specs.
What It Becomes
Pituitary starts as a drift detector. As your intent corpus grows, it becomes the consistency governance layer:
Temporal governance. Point-in-time queries against the governance graph. When a spec is superseded, historical governance links are preserved but excluded from current queries. Use --at DATE with check-compliance, check-doc-drift, or analyze-impact. Timestamps are derived from index build/update time.
Confidence-weighted edges. Governance links carry trust tiers — extracted (declared in spec), inferred (AST symbol matching), or ambiguous. Use --min-confidence with check-compliance and check-doc-drift to trade precision for recall.
Deliberate deviation vs accidental drift. When code contradicts a spec, Pituitary checks for rationale comments (// WHY:, // HACK:, decision language). Deliberate deviations get a different remediation path than unintentional drift.
Governance changelog. index --update --show-delta reports what changed: specs added/removed, edges created/severed, governance posture shifts. The feedback loop CI needs.
Spec families. Community detection on the dependency graph discovers natural governance clusters. Coverage gaps between families are the highest-risk ungoverned areas.
Governance protocol for AI. The optional MCP wrapper teaches your AI assistant when to check governance — before modifying files, before committing, after accepting specs, when writing docs — not just how.
Quick Start
pituitary init --path . # discover, index, report
pituitary new --title "Rate limiting policy" --domain api # scaffold a draft spec
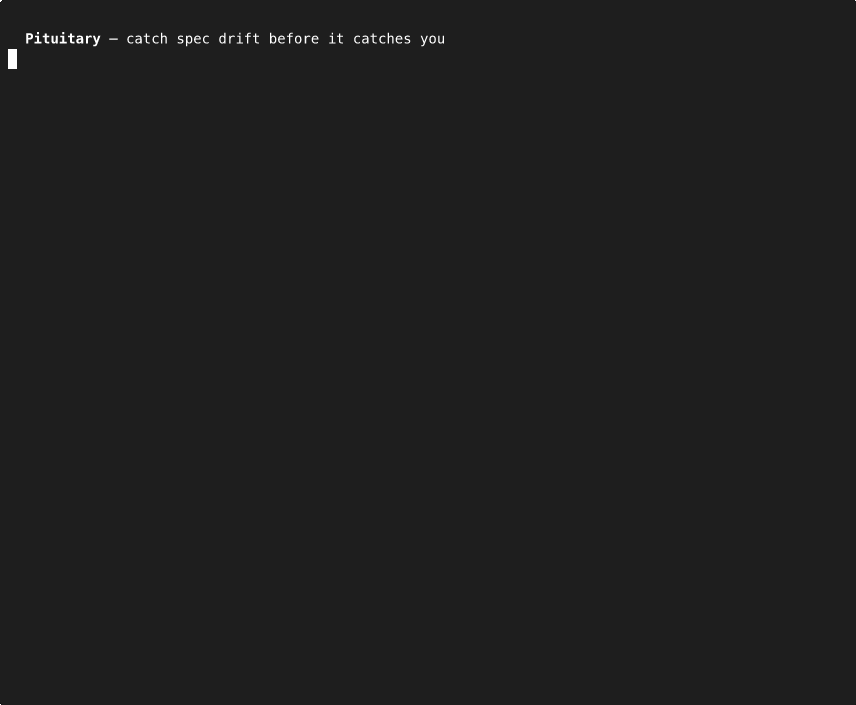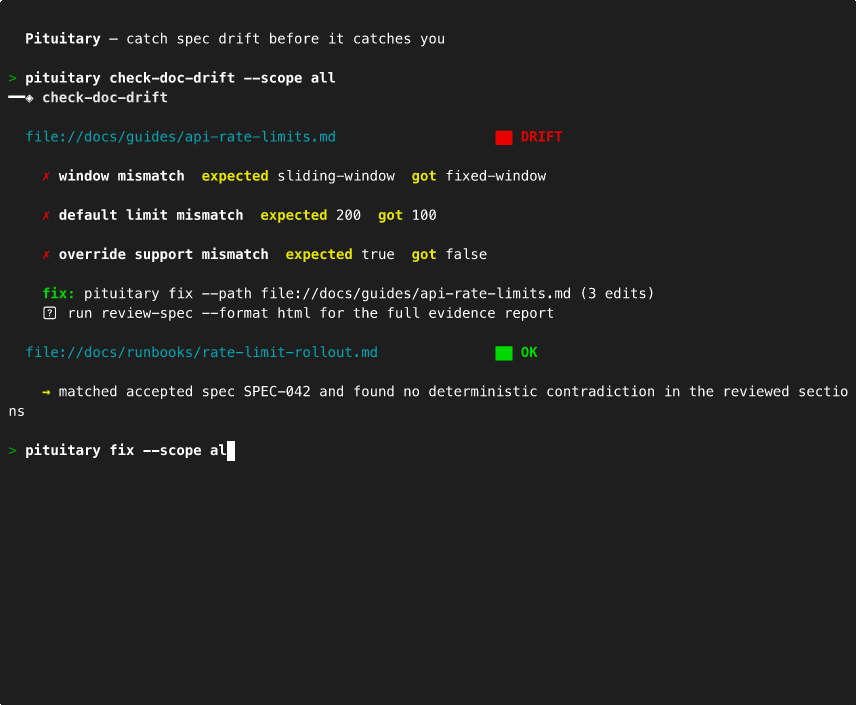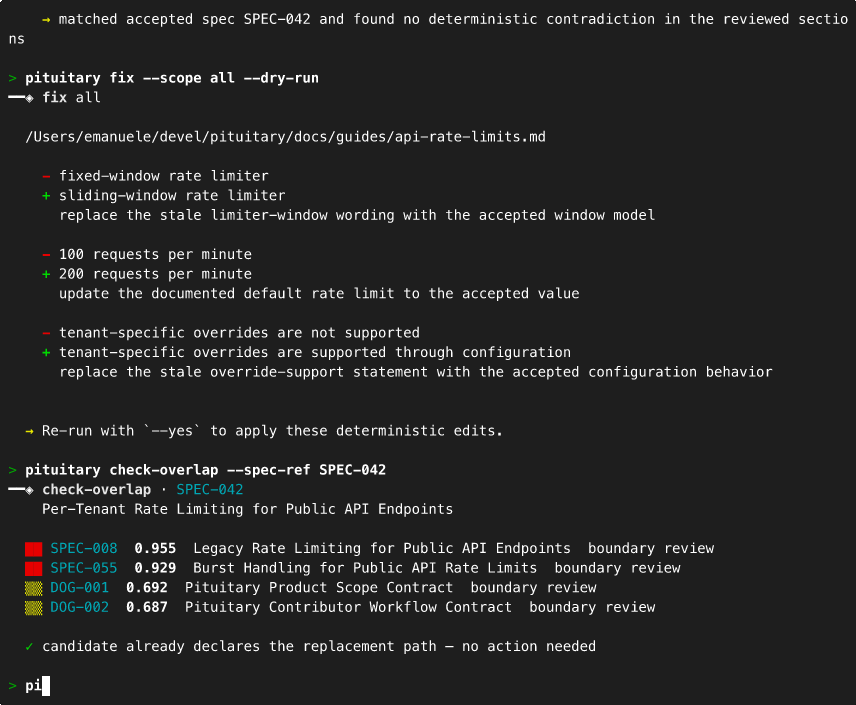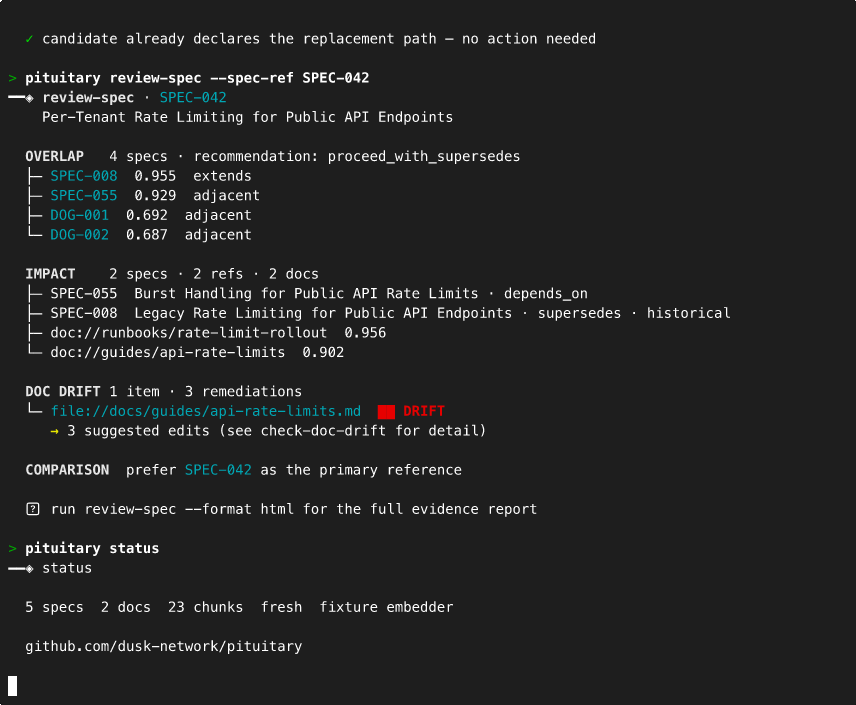
pituitary check-doc-drift --scope all # find stale docs
pituitary review-spec --path specs/X # full review of one spec
pituitary status # index health and governance hotspots at a glance
Command Reference
| What you want to do | Command |
|---|---|
| First run on a repo | pituitary init --path . |
| Scaffold a new draft spec | pituitary new --title "Rate limiting policy" --domain api |
| Find stale docs | pituitary check-doc-drift --scope all |
| Find stale docs implicated by a diff | git diff origin/main...HEAD | pituitary check-doc-drift --diff-file - |
| Check a PR diff against specs | git diff origin/main...HEAD | pituitary check-compliance --diff-file - |
| Debug why a file is in or out of scope | pituitary explain-file PATH |
| Full spec review | pituitary review-spec --path specs/X |
| Auto-fix deterministic drift | pituitary fix --scope all --dry-run |
| Search specs by hybrid relevance | pituitary search-specs --query "rate limiting" |
| Trace impact of a spec change | pituitary analyze-impact --path specs/X |
| Compare two specs | pituitary compare-specs --path specs/A --path specs/B |
| Detect stale specs | pituitary check-spec-freshness --scope all |
| Inspect command contracts | pituitary schema review-spec --format json |
All commands output JSON with --format json. Agents can set PITUITARY_FORMAT=json, and redirected stdout defaults to JSON automatically. review-spec also supports --format markdown and --format html for shareable reports with full evidence chains.
When file selection looks wrong, start with pituitary explain-file PATH. It is the fastest way to confirm which source matched a file, which selectors fired, and why a path was rejected before you debug drift or compliance output.
One pituitary.toml can also span multiple repository roots. Bind a source to a named repo root with repo = "...", and Pituitary carries that repo identity through search, drift, impact, status, and index output so cross-repo results stay unambiguous.
pituitary status now also flags governance hotspots so you can triage the corpus quickly: specs with unusually broad applies_to fan-out, artifacts that are only weakly governed through inferred or ambiguous links, and artifacts currently governed by multiple specs.
For terminology migrations, you can keep running ad hoc audits with --term / --canonical-term, or declare reusable [[terminology.policies]] in config and run pituitary check-terminology directly. Results now separate actionable current-state violations from tolerated historical uses, support terminology-only exclude_paths for historical containers such as CHANGELOG.md, and include replacement suggestions in both text and JSON output.
analyze-impact, check-doc-drift, and review-spec now emit section-level evidence chains in JSON: source refs on both sides of the match, a classification, a link_reason, and likely edit targets or suggested bullets. That gives agents enough structure to explain the next manual edit without scraping prose or auto-editing speculative changes.
For agent integrations, use pituitary schema <command> --format json to inspect request/response contracts, and prefer --request-file PATH|- on analysis commands when shell escaping would be brittle. Results that include raw repo excerpts or evidence now carry result.content_trust metadata so callers can treat returned workspace text as untrusted input instead of executable instructions.
See the cheatsheet for every command, the full reference for configuration/runtime/spec details, the reusable multi-editor package at skills/pituitary-cli/README.md, and AGENTS.md for repo-native agent instructions.
Install
macOS (Homebrew):
brew install dusk-network/tap/pituitary
Linux / macOS (binary): download from GitHub Releases, then:
tar xzf pituitary_*_*.tar.gz
sudo install pituitary /usr/local/bin/
Windows: download pituitary_<version>_windows_amd64.zip from GitHub Releases, extract pituitary.exe, and add its location to your PATH.
Build from source (contributors): see docs/development/prerequisites.md.
Stop Your Agent From Building on Stale Decisions
Your agent writes specs, reviews PRs, and proposes changes — but it doesn't know what's already been decided. Pituitary gives it that context. The governance protocol teaches it when to check, not just how.
Optional MCP Server (Claude Code, Cursor, Windsurf, or any MCP client)
{
"mcpServers": {
"pituitary": {
"command": "pituitary",
"args": ["serve", "--config", ".pituitary/pituitary.toml"]
}
}
}
Your agent gets 15 tools: search_specs, check_overlap, compare_specs, analyze_impact, check_doc_drift, review_spec, get_intent_outline, expand_intent_context, check_compliance, check_terminology, governed_by, compile_preview, fix_preview, status, and explain_file. For focused context, search first, inspect the returned record with get_intent_outline, then expand selected chunk IDs with expand_intent_context using the same snapshot_fingerprint.
Shared Skills (Claude Code, Cowork)
cp -R skills/pituitary-cli ~/.claude/skills/pituitary-cli
Codex CLI and Gemini CLI get project policy from AGENTS.md / GEMINI.md automatically. For the full Pituitary analysis workflow, also install the skill package: cp -R skills/pituitary-cli ~/.codex/skills/pituitary-cli or ~/.gemini/skills/.
Editor Rules (Cursor, Windsurf, Cline)
cp skills/pituitary-cli/platforms/cursor/.cursorrules .cursorrules # Cursor
cp skills/pituitary-cli/platforms/windsurf/.windsurfrules .windsurfrules # Windsurf
cp skills/pituitary-cli/platforms/cline/.clinerules .clinerules # Cline
AGENTS-Aware Tools (Codex CLI, Gemini CLI, and others)
The repo's AGENTS.md is the canonical project policy. Tools that read AGENTS.md get Pituitary awareness automatically. Generated mirrors (CLAUDE.md, GEMINI.md) are compatibility outputs, not separate policy sources.
See skills/pituitary-cli/README.md for the full install guide, request templates, and security notes.
Optional CI Wiring
If you already use GitHub Actions, you can wrap the same local CLI workflow in the checked-in action and post review-spec output as a PR comment:
permissions:
contents: read
pull-requests: read
issues: write
steps:
- uses: dusk-network/[email protected]
with:
fail-on: error
# Set this when your repo keeps config at the root instead.
# config-path: pituitary.toml
Add spec hygiene checks alongside your linter:
- run: pituitary index --rebuild
- run: git diff origin/main...HEAD | pituitary check-compliance --diff-file -
- run: git diff origin/main...HEAD | pituitary check-doc-drift --diff-file -
- run: pituitary check-doc-drift --scope all
See docs/development/ci-recipes.md for a complete GitHub Actions recipe.
Semantic Runtime (optional retrieval + bounded analysis beyond the deterministic default)Pituitary works out of the box with no API keys and no external dependencies. For higher-quality semantic retrieval on a real corpus, configure an embedding runtime and rebuild the index. For bounded provider-backed adjudication in compare-specs and check-doc-drift, also configure a separate analysis runtime.
"Pituitary got me from a large architecture spec plus drifted docs to a scoped, inspectable set of affected files quickly."
From a real Hermes/Raoh doc-convergence pass across
harper,openclaw,autoskiller, andsouther: semantic support was most useful for narrowing scope, tracing terminology drift, and reducing omission risk before manual code/runtime verification.
Cloud: OpenAI-compatible embeddings (if you already have a key)
[runtime.embedder]
provider = "openai_compatible"
model = "text-embedding-3-small"
endpoint = "https://api.openai.com/v1"
api_key_env = "OPENAI_API_KEY"
Named runtime profiles (recommended when embedder and analysis share the same host assumptions)
[runtime.profiles.local-lm-studio]
provider = "openai_compatible"
endpoint = "http://127.0.0.1:1234/v1"
timeout_ms = 30000
max_retries = 1
[runtime.embedder]
profile = "local-lm-studio"
model = "nomic-embed-text-v1.5"
[runtime.analysis]
profile = "local-lm-studio"
model = "your-analysis-model"
timeout_ms = 120000
For runtime.analysis, prefer a text model that is good at bounded adjudication rather than a generic embedding or agent stack:
- strong instruction following and schema adherence
- concise answers without verbose reasoning text or intermediate chain-of-thought
- enough context for Pituitary's shortlisted evidence bundle; typical general-purpose
8k-32kcontext is sufficient, with larger windows optional - active-parameter cost that fits your latency and hardware budget
Examples today include recent instruct models from the Qwen and Mistral families, but the important choice is the capability profile, not one fixed model name.
Then validate and rebuild:
pituitary status
pituitary status --check-runtime all
pituitary index --rebuild
pituitary status now shows the active runtime profile plus the resolved provider, model, endpoint, timeout, and retry settings for both embedder and analysis. --check-runtime probes those resolved settings directly.
Retrieval remains deterministic. The analysis model only sees narrowly shortlisted context for compare-specs, check-doc-drift, and bounded re-adjudication in check-compliance, and those result envelopes now record the configured analysis runtime plus whether it was consulted during the run. Any OpenAI-compatible embedding or analysis API works. See runtime docs for full setup.
Retrieval evaluation reports and notes:
- docs/development/retrieval-precision-344.md — doc-level precision@k on the bootstrap corpus, gating the
LateChunkPolicydefault (see #344). - docs/development/retrieval-precision-358.md — chunk-level precision benchmark on the next-iteration corpus (post-#344 follow-up; see #358).
- docs/development/retrieval-armb-361.md — LLM-graded RAG Arm B benchmark comparing
ExpandContext(IncludeParent)off vs on (see #361). - docs/development/governance-section-summaries-2026-05-07.md — evaluation contract for optional governance-scoped section summaries in outline-guided retrieval (see #387).
Architecture
See ARCHITECTURE.md for the full system design. Key decisions: deterministic retrieval first, tools-only (no embedded agent), one governance SQLite file plus an opaque local Stroma snapshot with atomic rebuilds.
Project Status
Active development. Core analysis is functional end-to-end: overlap, drift, impact, compliance, terminology, compile, spec-freshness, and review workflows all ship today. The governance graph carries temporal validity, confidence tiers, and spec family assignments. Pituitary is consistency governance, not code linting — it keeps your project building against what you actually decided, not against stale echoes of decisions that routine LLM cleanups missed. See docs/rfcs/0001-spec-centric-compliance-direction.md.
See ROADMAP.md for what's shipped, what's next, and where Pituitary is headed.
Contributing
See CONTRIBUTING.md. The codebase has clear package boundaries so you can contribute to one area without understanding the whole system.
License
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found