agent-harness-kit
Health Uyari
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 133 GitHub stars
Code Uyari
- process.env — Environment variable access in agent-harness-kit.config.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
A provider-agnostic scaffolding kit for running structured multi-agent workflows in your codebase.
@cardor/agent-harness-kit
A provider-agnostic scaffolding kit for running structured multi-agent workflows in your codebase.
Instead of letting AI agents roam freely through your project with no memory, no coordination, and no audit trail, agent-harness-kit gives them a shared structure: a task backlog, a defined workflow, a persistent log of every action taken, and a health gate that must be green before any work begins.
You stay in control. The agents stay on track.
npx ahk init
Table of Contents
- Why this exists
- How it works
- Features
- Requirements
- Installation
- Commands
- Files created by ahk init
- What you can customize
- MCP tools (for agents)
- Agent roles
- What to commit
- Runtime compatibility
- Contributing & local development
- Roadmap
Why this exists
If you don't know what is Agent Harness, you can check this blog post: Introducing Agent Harness.
Most AI coding tools give you a single agent with a chat window. That works for small tasks. It breaks down when:
- You want multiple specialized agents working in sequence (plan → explore → build → review)
- You need to track what changed, what was tried, and what was blocked — across sessions
- You switch between AI providers (Claude Code today, OpenCode tomorrow) and don't want to re-setup everything
- You want a health check that agents must pass before touching code
agent-harness-kit solves all of this with a thin layer of scaffolding and a local MCP server that any MCP-compatible AI tool can connect to.
How it works
ahk init
└── creates config, agent definitions, task backlog, health check
AI tool opens your project
└── reads .claude/mcp.json or opencode.json
└── spawns: npx ahk serve (stdio MCP server)
Agent starts working
└── tasks.get() → picks a task from the backlog
└── tasks.claim(id) → atomically claims it (no double-work)
└── actions.start() → registers its action
└── actions.write() → logs sections: result, files, blockers…
└── actions.complete() → closes the action
Lead → Explorer → Builder → Reviewer
└── each role has its own agent definition with clear responsibilities
└── the harness DB records the full history
Everything is stored locally in a SQLite database (.harness/harness.db). No cloud, no external services, no API keys required beyond what your AI tool already uses.
Features
- Provider-agnostic — works with Claude Code, OpenCode, or any MCP-compatible AI tool. Switch providers without losing your task history or reconfiguring your workflow.
- Structured 4-agent workflow — Lead, Explorer, Builder, and Reviewer each have defined responsibilities and can only act within their role.
- Atomic task claiming — agents use
tasks.claim()which uses a SQLite transaction to prevent two agents from picking up the same task at the same time. - Full audit trail — every action, file touched, tool used, and section written is stored in SQLite and queryable.
- Health gate — agents must run
health.shand get a green exit before starting or closing any task. You define what "healthy" means. - Markdown fallback —
current.mdis always regenerated so agents can understand the session state even without the MCP server. - Docs search — agents can call
docs.search(query)to find relevant content in your project's docs folder before writing code. - Multi-database support — SQLite by default (zero native deps, uses
node:sqliteon Node ≥ 22 orbun:sqliteon Bun). Switch to PostgreSQL or MySQL with a single config line — same schema, same MCP tools, same workflow. - Incremental scaffold —
ahk initandahk buildnever overwrite files you've customized. Agent definitions you've edited are preserved. - Global installation —
ahk initcan scaffold the harness into your home directory (~/.claudeor~/.config/opencode) to share it across all projects. - Input validation — CLI prompts validate all inputs (name length, path format, task title, etc.) and retry with the error message instead of silently accepting bad values.
Requirements
- Node.js ≥ 22.5 or Bun (any recent version)
- npm ≥ 9
Installation
# Install in your project as a dev dependency
npm install --save-dev @cardor/agent-harness-kit
# Or globally
npm install -g @cardor/agent-harness-kit
Then run the interactive setup inside your project:
npx ahk init
# or, if installed globally:
ahk init
Commands
ahk init
Interactive scaffold. Asks for your project name, description, AI provider, whether to install globally, docs path, task adapter, and an optional first task. Creates all harness files in the current directory (or home directory if global).
ahk init
# Skip prompts with flags
ahk init --name "my-app" --provider claude-code --docs ./docs --tasks local
Run this once per project. Safe to re-run — it will not overwrite files you've customized.
Global installation — if you answer yes to "Install globally?", files go to ~/.claude (Claude Code) or ~/.config/opencode (OpenCode). This lets you share one harness config across all your projects.
ahk build
Regenerates AGENTS.md and provider-specific files from your agent-harness-kit.config.ts. Use this after changing config values.
ahk build
ahk build --watch # watch mode: rebuilds automatically on config changes
ahk dashboard
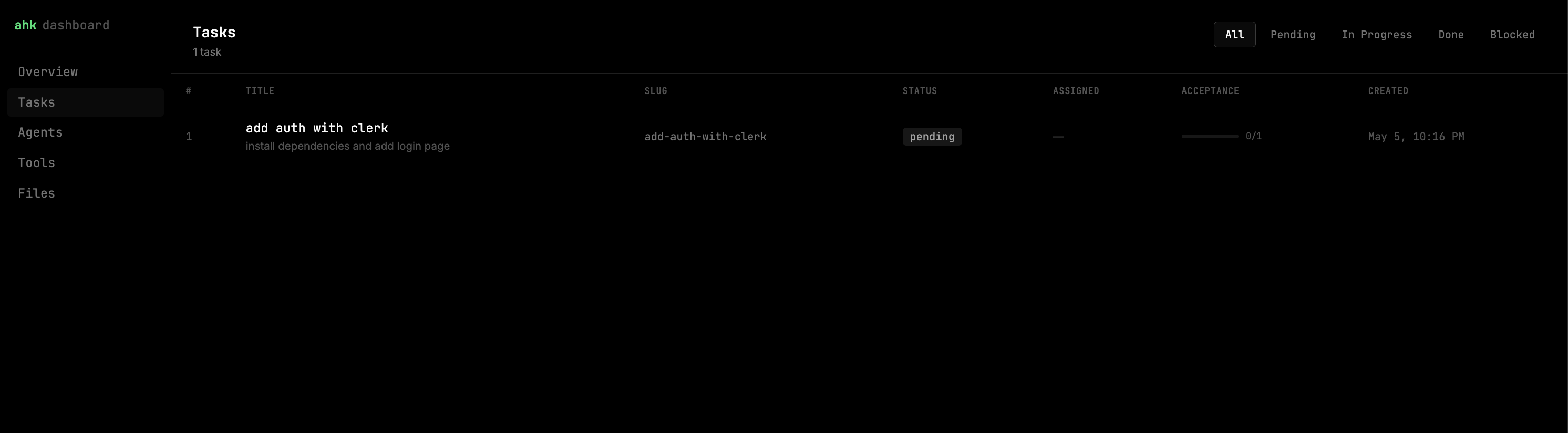
Opens a local web dashboard to visualize everything stored in the harness database — tasks, agent actions, file operations, tool usage, and live timelines. Updates in real time via WebSocket as agents work.
ahk dashboard # opens http://localhost:4242 in your browser
ahk dashboard --port 8080 # custom port
ahk dashboard --no-open # start server without opening browser
The dashboard includes:
| View | What it shows |
|---|---|
| Overview | Status counts, active tasks with acceptance progress, recent agent activity |
| Tasks | Full task list, filterable by status, with acceptance progress bars |
| Task detail | Acceptance criteria, action timeline per agent, files touched, tools used |
| Agents | Per-role breakdown: actions, tasks worked, files touched, completion rate |
| Tools | Top tools bar chart + full log of recent tool calls with args and results |
| Files | Most-touched files with operation breakdown + recent file operation log |
ahk status
Shows the current task table and any active agent actions in the terminal.
ahk status
ahk status --json # machine-readable output
ahk health
Runs health.sh and reports the result. Exit 0 = healthy, exit 1 = something is wrong.
ahk health
ahk sync
Syncs .harness/feature_list.json ↔ SQLite. Tasks already in the DB are skipped by slug. Use this to seed the backlog from the JSON file without duplicating existing tasks.
ahk sync # both directions (default)
ahk sync --direction in # JSON → SQLite only
ahk sync --direction out # SQLite → JSON only
ahk sync --dry-run # preview changes without applying them
ahk sync --dry-run --direction in
ahk serve
Starts the MCP server on stdio. You never need to call this manually. After ahk init, the generated .claude/mcp.json (Claude Code) or opencode.json (OpenCode) tells the AI tool to spawn it automatically when you open the project.
ahk serve
ahk serve --port 3456 # store a port hint in config (stdio transport only)
ahk task add
Interactively adds a new task to the backlog (SQLite + feature_list.json).
ahk task add
ahk task list
Lists all tasks. Optionally filter by status.
ahk task list
ahk task list --status pending
ahk task list --status in_progress
ahk task list --status done
ahk task list --status blocked
ahk task list --json # machine-readable output
ahk task done <id|slug>
Marks a task as done. Runs the health check first if health is required — if it fails, the task is not closed.
ahk task done 3
ahk task done add-auth-flow
ahk reset
Clears harness data interactively. Only SQLite databases are managed by this command — remote Postgres/MySQL databases are intentionally skipped.
ahk reset # interactive — asks before deleting each item
ahk reset --force # skip all confirmation prompts
ahk reset --provider claude-code # also delete agent .md files for this provider
ahk reset --provider opencode
What it can reset:
- The SQLite
.dbfile (plus WAL and SHM files if present) .harness/feature_list.json- Agent
.mdfiles in.claude/agents/or.opencode/agents/
After a reset, run ahk init to scaffold a fresh harness.
ahk migrate
Migrates provider-specific files from one AI provider to another. Useful when switching from Claude Code to OpenCode or vice versa.
ahk migrate --to opencode
ahk migrate --to claude-code
ahk export
Exports the full database as JSON or SQL. Useful for backups, external reporting, or migrating data.
ahk export --json # JSON to stdout
ahk export --json --output snapshot.json # JSON to file
ahk export --sql # SQL dump to stdout
ahk export --sql --output dump.sql # SQL dump to file
Files created by ahk init
your-project/
├── agent-harness-kit.config.ts ← main config (edit freely)
├── AGENTS.md ← navigation map regenerated from config
├── health.sh ← implement your health checks here
├── .harness/
│ ├── harness.db ← SQLite source of truth (gitignored)
│ ├── current.md ← auto-generated session snapshot (gitignored)
│ └── feature_list.json ← human-editable task backlog (commit this)
└── .claude/ ← or .opencode/ depending on your provider
├── agents/
│ ├── lead.md
│ ├── explorer.md
│ ├── builder.md
│ └── reviewer.md
└── mcp.json ← tells Claude Code to spawn ahk serve
What each file does
| File | Purpose | Edit it? |
|---|---|---|
agent-harness-kit.config.ts |
Defines project metadata, provider, storage paths, MCP port | Yes — it's yours |
AGENTS.md |
Navigation map agents read first. Regenerated by ahk build |
No — changes will be overwritten |
health.sh |
Shell script agents run before starting work. Must exit 0 | Yes — implement your checks here |
.harness/feature_list.json |
Task backlog in JSON. Humans edit this, ahk sync loads it into SQLite |
Yes — add tasks here |
.harness/harness.db |
SQLite database. Source of truth for tasks, actions, sections | No — managed by the harness |
.harness/current.md |
Auto-generated session snapshot for agents without MCP access | No — regenerated automatically |
.claude/agents/*.md |
Agent role definitions. Created once, never overwritten | Yes — customize agent behavior |
.claude/mcp.json |
MCP server config. Merged (not overwritten) by ahk build |
Yes, carefully — don't remove the agent-harness-kit entry |
What you can customize
agent-harness-kit.config.ts
Everything in the config file is yours to change:
import { defineHarness } from '@cardor/agent-harness-kit'
export default defineHarness({
project: {
name: 'My App',
description: 'What this project does',
docsPath: './docs', // where agents search for documentation
},
provider: 'claude-code', // 'claude-code' | 'opencode'
agents: {
lead: { instructionsPath: null },
explorer: { instructionsPath: null, allowedPaths: ['./docs', './src'] },
builder: { instructionsPath: null, writablePaths: ['./src', './tests'] },
reviewer: { instructionsPath: null },
custom: [], // define extra agents here
},
// ── Database ──────────────────────────────────────────────────────────────
// SQLite (default — zero native deps, Node 22+ or Bun)
database: { type: 'sqlite', path: '.harness/harness.db' },
// PostgreSQL — uncomment to use instead:
// database: { type: 'postgres', connectionString: process.env.DATABASE_URL },
// MySQL — uncomment to use instead:
// database: { type: 'mysql', connectionString: process.env.DATABASE_URL },
storage: {
dir: '.harness',
tasks: { adapter: 'local' }, // 'local' | 'jira' | 'linear' | 'mcp'
sections: {
toolsUsed: true, // log which tools agents used
filesModified: true, // log which files were touched
result: true, // log action results
blockers: true, // log blockers agents hit
nextSteps: false, // optional next steps field
},
markdownFallback: { enabled: true, path: '.harness/current.md' },
},
health: {
scriptPath: './health.sh',
required: true, // set to false to skip health checks
},
tools: {
mcp: { enabled: true, port: 3742 },
scripts: { enabled: true, outputDir: './.harness/scripts' },
},
})
health.sh
This is the most important file to implement. Agents will not start or close tasks until this script exits 0. Examples:
#!/usr/bin/env bash
# Check the dev server is up
curl -sf http://localhost:3000/health > /dev/null || exit 1
# Run unit tests
npm test || exit 1
# Check DB connection
psql "$DATABASE_URL" -c "SELECT 1" > /dev/null 2>&1 || exit 1
echo "All checks passed."
Agent definition files (.claude/agents/*.md or .opencode/agents/*.md)
These are Markdown files with a YAML frontmatter and free-form instructions. They are created once and never overwritten by ahk build — so any edits you make are permanent.
You can:
- Add domain-specific context (e.g. "this project uses hexagonal architecture")
- Restrict what the agent is allowed to do
- Add project-specific conventions the agent must follow
- Reference specific files or docs the agent should read first
---
description: Builder agent — implements the plan produced by explorer and lead
---
# Builder Agent
You are the builder agent for MyApp. Follow these rules:
- All API endpoints must be defined in `src/routes/`
- Never modify `src/core/` without lead approval
- Run `npm test` after every change and fix failures before completing
- Use the existing error handling pattern from `src/lib/errors.ts`
.harness/feature_list.json
The human-editable task backlog. Add tasks here, then run ahk sync to load them into SQLite.
[
{
"slug": "add-auth-flow",
"title": "Add JWT authentication flow",
"description": "Implement login, refresh token, and logout endpoints",
"acceptance": [
"POST /auth/login returns a signed JWT",
"POST /auth/refresh validates and rotates the token",
"All protected routes return 401 without a valid token",
"Tests cover happy path and token expiry"
]
}
]
Good acceptance criteria make the difference — the reviewer agent uses them to decide whether to approve or block a task.
MCP tools (for agents)
The harness exposes these tools via MCP. Agents use them instead of reading files directly.
| Tool | Parameters | Description |
|---|---|---|
tasks.get |
status? |
List tasks, optionally filtered by pending | in_progress | done | blocked |
tasks.claim |
id, agent |
Atomically claim a pending task. Returns task_already_claimed if another agent got it first |
tasks.update |
id, status |
Change task status |
tasks.add |
title, slug?, description?, acceptance? |
Create a new task directly from MCP (agents can queue work on the fly) |
tasks.acceptance.update |
criterionId |
Mark an acceptance criterion as met. Criterion IDs come from tasks.get |
actions.start |
taskId, agent |
Start a new action, returns actionId |
actions.write |
actionId, sectionType, content |
Record a text section: result | tools_used | blockers | next_steps. Does not populate the Files dashboard — use actions.record_file for that |
actions.complete |
actionId, summary |
Close an action with a one-line summary |
actions.get |
taskId |
Full action history for a task (all agents, all sections) |
actions.record_file |
actionId, filePath, operation, notes? |
Register a file touch. The only way to populate the Files dashboard. operation: read | created | modified | deleted |
actions.record_tool |
actionId, toolName, argsJson?, resultSummary? |
Register a tool call. The only way to populate the Tools dashboard |
docs.search |
query |
Search the docsPath folder for content matching the query |
Agent roles
| Role | Responsibility |
|---|---|
| lead | Decomposes the task into a plan, assigns sub-agents. Does not write code or read source files. |
| explorer | Reads and maps the codebase. Never writes files. Records every file read. |
| builder | Implements the plan. Only writes to writablePaths. Records every file modified. |
| reviewer | Verifies all acceptance criteria are met. Approves or blocks. Runs health check before approving. |
What to commit
| File | Commit? |
|---|---|
agent-harness-kit.config.ts |
Yes |
AGENTS.md |
Yes |
health.sh |
Yes |
.harness/feature_list.json |
Yes |
.claude/agents/*.md |
Yes |
.claude/mcp.json / opencode.json |
Yes |
.harness/harness.db |
No (gitignored) |
.harness/current.md |
No (gitignored) |
The rule: commit inputs (config, task definitions, agent instructions). Ignore outputs (DB, auto-generated snapshots).
Runtime compatibility
| Runtime | SQLite | PostgreSQL | MySQL |
|---|---|---|---|
| Node.js ≥ 22 | ✅ uses node:sqlite built-in |
✅ via postgres package |
✅ via mysql2 package |
| Bun (any recent) | ✅ uses bun:sqlite built-in |
✅ via postgres package |
✅ via mysql2 package |
| Node.js < 22 | ❌ node:sqlite not available |
✅ | ✅ |
SQLite requires no additional packages. For PostgreSQL install postgres, for MySQL install mysql2:
npm install postgres # for PostgreSQL
npm install mysql2 # for MySQL
Contributing & local development
git clone <repo-url>
cd agent-harness-kit
npm install
npm run build:ui # build the dashboard SPA (dashboard/ → src/dashboard-dist/)
npm run build # build:ui + tsc + copy-assets
npm run dev # watch mode (CLI TypeScript only)
npm test # run tests
Testing the local build in another project
Use the helper script to build the package and link it into any local project in one step:
# Build + link into a specific project
./scripts/link-local.sh /path/to/your-other-project
# Build + register globally only (then link manually wherever you need)
./scripts/link-local.sh
What the script does:
- Runs
npm run build(full build including dashboard assets) - Runs
npm linkto register the package globally on your machine - Runs
npm link @cardor/agent-harness-kitinside the target project - Smoke-tests the
ahkbinary with--version
After linking, npx ahk inside the target project will use your local build. To unlink when you're done:
# Inside the target project
npm unlink @cardor/agent-harness-kit
# Optionally remove the global registration
npm uninstall -g @cardor/agent-harness-kit
Tip: If you're iterating quickly, run
npm run buildin this repo after each change — the link picks up the newdist/immediately without re-running the script.
To work on the dashboard UI with hot reload:
# Terminal 1 — CLI server (no browser open)
cd your-test-project && ahk dashboard --no-open --port 4242
# Terminal 2 — Vite dev server with HMR
cd dashboard && npm run dev # http://localhost:5173, proxies /api and /ws → :4242
Commit messages follow Conventional Commits with a required scope:
feat(cli): add export command
fix(db): prevent race condition in claimTask
chore(ci): update Node version to 22
Types: feat fix chore refactor docs test perf style build ci revert
Roadmap
- ✅
ahk dashboard— local web UI with real-time WebSocket updates. Shows tasks, action timelines, file activity, tool usage, and per-agent breakdowns. - ✅
ahk reset— interactively clear the SQLite DB, feature list, and agent files to start a project fresh. - ✅ PostgreSQL + MySQL drivers — remote database support via
postgresandmysql2packages. Configure withdatabase: { type: 'postgres', connectionString: '...' }. - ✅
actions.record_file+actions.record_tool— dedicated MCP tools for populating the Files and Tools dashboard views. - ✅
tasks.addvia MCP — agents can create new tasks on the fly without leaving the conversation. - ✅ Global installation —
ahk initcan install the harness to your home directory, shared across projects. - ✅ Input validation — all CLI prompts validate and retry on bad values.
- Graphify integration — connect the harness to Graphify to visualize agent workflows, task dependencies, and action timelines as interactive graphs.
- Open Telemetry integration — emit OpenTelemetry spans for all agent actions, file operations, and tool calls.
- Jira task adapter — pull tasks directly from Jira instead of maintaining
feature_list.jsonmanually. - Linear task adapter — same as Jira, for Linear.
- GitHub Issues adapter — same, for GitHub Issues.
- Remote MCP adapter — connect to a hosted MCP server instead of a local SQLite file. Enables shared task state across machines and team members without syncing a DB file.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi