slop-guard
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 96 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Slop Scoring to Stop Slop
slop-guard
A rule-based prose linter that scores text 0--100 for formulaic AI writing patterns. No LLM judge, no API calls. Purely programmatic.
The default pipeline loads 23 configurable rules backed by 200+ literal and structural heuristics. It returns a numeric score, a band label, specific violations with surrounding context, and concrete advice for each hit.
Add to Your Agent
Both clients use the same MCP command: uvx slop-guard.
If you want a custom rule JSONL, append -c /path/to/config.jsonl.
Claude Code
Add from the command line:
claude mcp add slop-guard -- uvx slop-guard
Add to your .mcp.json:
{
"mcpServers": {
"slop-guard": {
"command": "uvx",
"args": ["slop-guard"]
}
}
}
Codex
Add from the command line:
codex mcp add slop-guard -- uvx slop-guard
Add to your ~/.codex/config.toml:
[mcp_servers.slop-guard]
command = "uvx"
args = ["slop-guard"]
If you want a fixed release, pin it in args, for example: ["slop-guard==0.3.1"].
CLI
The sg command lints prose from the terminal. No API keys, no network calls.
Quick start
# Run without installing
uvx --from slop-guard sg README.md
# Or install it
uv tool install slop-guard
sg README.md
Usage
sg [OPTIONS] INPUT [INPUT ...]
sg requires at least one input. Each input can be a file path, - for stdin, or quoted inline prose text:
sg "This is some test text"
echo "Latency dropped from 180 ms to 95 ms." | sg -
Lint multiple files at once (shell-level glob expansion):
sg docs/*.md README.md
sg path/**/*.md
Options
| Flag | Description |
|---|---|
-j, --json |
Output results as JSON, including source as the raw inline/stdin text or full file path |
-v, --verbose |
Show individual violations and advice |
-q, --quiet |
Only print sources that fail the threshold |
-t SCORE, --threshold SCORE |
Minimum passing score (0-100). Exit 1 if any input scores below this |
-c JSONL, --config JSONL |
Path to JSONL rule configuration. Defaults to packaged settings |
-s, --score-only |
Print only numeric score output |
--counts |
Show per-rule hit counts in the summary line |
Examples
# One-line summary per file
sg draft.md
# => draft.md: 72/100 [light] (1843 words) *
# Score-only output
sg -s draft.md
# Use a custom rule config
sg -c /path/to/config.jsonl draft.md
# Verbose output with violations and advice
sg -v draft.md
# JSON for scripting
sg -j report.md | jq '.score'
# JSON preserves the true CLI input identity
sg -j "The migration finished in 12 seconds." | jq '.source'
# => "The migration finished in 12 seconds."
# CI gate: fail if any file scores below 60
sg -t 60 docs/*.md
# Quiet mode: only show failures
sg -q -t 60 **/*.md
Exit codes
| Code | Meaning |
|---|---|
| 0 | Success (all files pass threshold, or no threshold set) |
| 1 | One or more files scored below the threshold |
| 2 | Error (bad file path, read failure, etc.) |
Fit Rule Configs (sg-fit)
Use sg-fit to fit a rule JSONL config from corpus data:
# Legacy shorthand
sg-fit TARGET_CORPUS OUTPUT
# Multi-input mode (for shell-expanded globs or many files)
sg-fit --output OUTPUT TRAIN_INPUT [TRAIN_INPUT ...]
Example:
sg-fit data.jsonl rules.fitted.jsonl
sg-fit --output rules.fitted.jsonl **/*.txt **/*.md
Optional arguments:
--init JSONL: Start from a specific rule config JSONL instead of packaged defaults.--negative-dataset INPUT [INPUT ...]: Add negative dataset inputs. This flag can be repeated; all negative rows are normalized to label0.--no-calibration: Skip post-fit contrastive penalty calibration for faster fitting on large corpora.--output JSONL: Required when you pass more than one training input.
Target corpus rows can be either:
{"text": "body of text", "label": 1}
or:
{"text": "body of text"}
If label is omitted in the target corpus, sg-fit treats it as 1 (positive/target style).
sg-fit also accepts .txt and .md files. Each file is normalized into a single training sample.
Installation
Requires uv.
Run without installing (recommended for MCP setups):
uvx slop-guard
# MCP server with custom rule config
uvx slop-guard -c /path/to/config.jsonl
Install persistently (gives you slop-guard, sg, and sg-fit):
uv tool install slop-guard
Pin versions for reproducibility:
uvx slop-guard==0.3.1
Upgrade an installed tool:
uv tool upgrade slop-guard
From source
From a local checkout:
uv run slop-guard # MCP server
uv run slop-guard -c config.jsonl
uv run sg # CLI linter
uv run sg-fit data.jsonl rules.fitted.jsonl
Core development workflows are also exposed through make:
make sync
make check
make fix
make build
make verify-wheel
MCP Tools
check_slop(text): Analyze a string. Returns JSON diagnostics only; it does not repeat the input text.
check_slop_file(file_path): Read a file from disk and analyze it. Same output, without repeating the file path in the payload.
What it catches
The default rules cover stock hype words and boilerplate phrases, assistant tone markers, unattributed weasel phrasing, AI self-disclosure, placeholder text, bullet/blockquote/horizontal-rule-heavy Markdown structures, sentence and paragraph rhythm, and em dash or colon overuse.
They also flag contrast/setup-resolution tells, pithy fragments, repeated 4-8 word phrases, copula chains, extreme long sentences, aphoristic closers, and uneven paragraph cadence.
Texts under 10 words are skipped and return a clean 100.
Otherwise scoring uses exponential decay: score = 100 * exp(-lambda * density), where density is the weighted penalty sum normalized per 1000 words. Claude-specific categories (contrast pairs, setup-resolution, pithy fragments) get a concentration multiplier. Repeated use of the same tic costs more than diverse violations.
Scoring bands
| Score | Band |
|---|---|
| 80-100 | Clean |
| 60-79 | Light |
| 40-59 | Moderate |
| 20-39 | Heavy |
| 0-19 | Saturated |
Output
CLI --json output and MCP tool responses share this structure:
source CLI JSON only; raw inline/stdin text or full file path
score 0-100 integer
band "clean" / "light" / "moderate" / "heavy" / "saturated"
word_count integer
violations array of {type, rule, match, context, penalty, start, end}
counts per-category violation counts
total_penalty sum of all penalty values
weighted_sum after concentration multiplier
density weighted_sum per 1000 words
advice array of advice strings, one per distinct issue
MCP tool responses omit source, because the tool transport already carries the
input parameter.
violations[].type is always "Violation" for typed records.
Benchmark snapshot
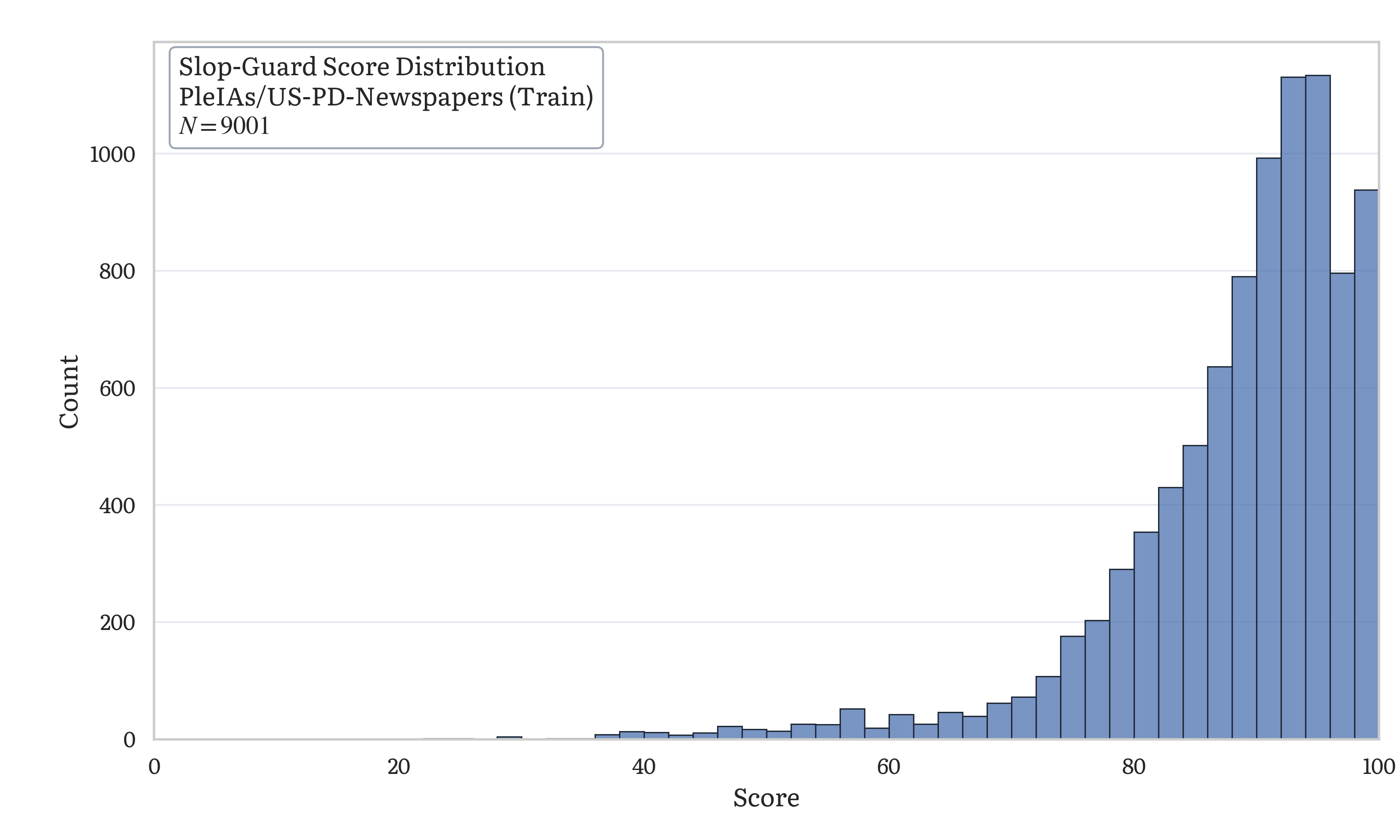
Example score distribution from benchmark/us_pd_newspapers_histogram.py onPleIAs/US-PD-Newspapers (first 9,001 rows of one local shard):
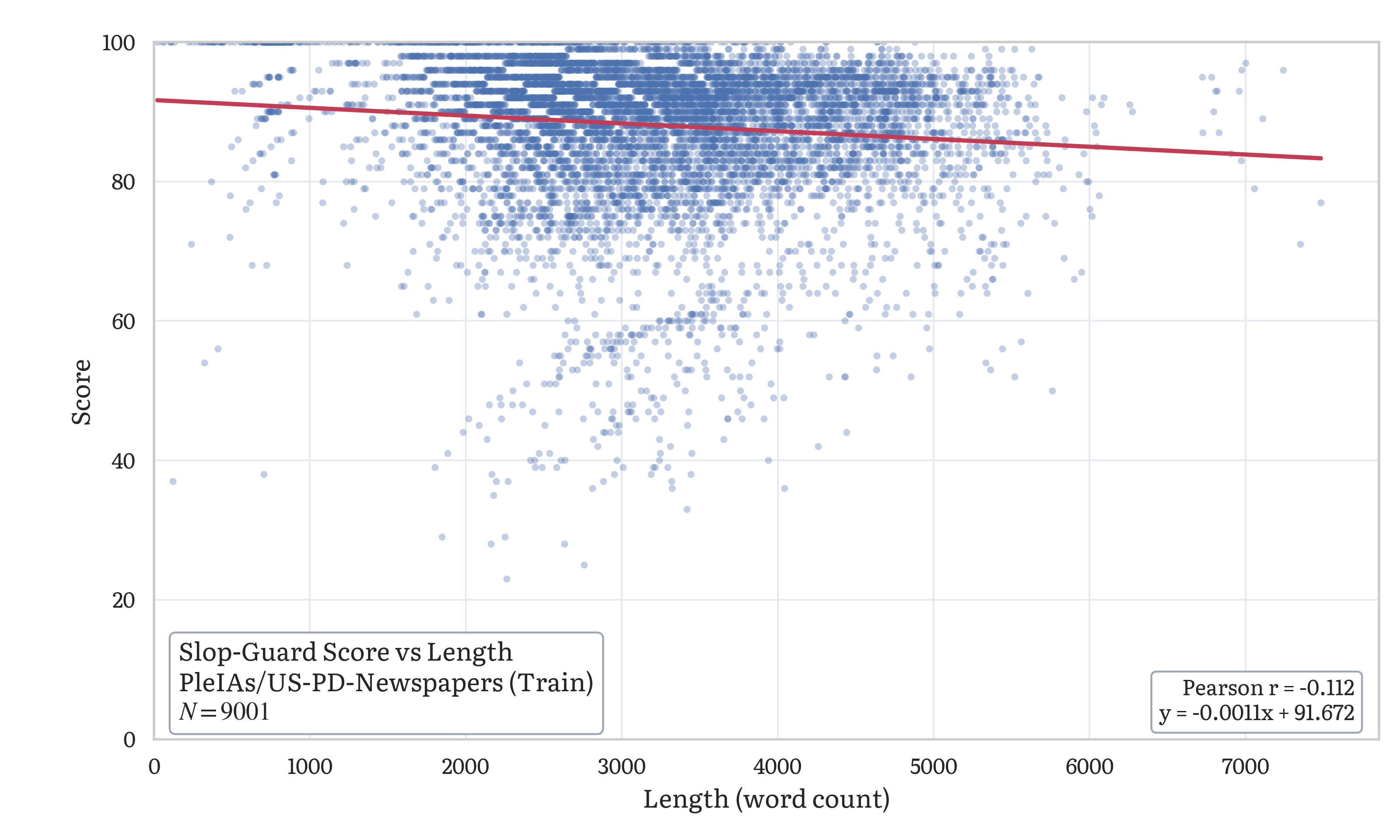
Example score-vs-length scatter plot frombenchmark/us_pd_newspapers_scatter.py on the same shard:
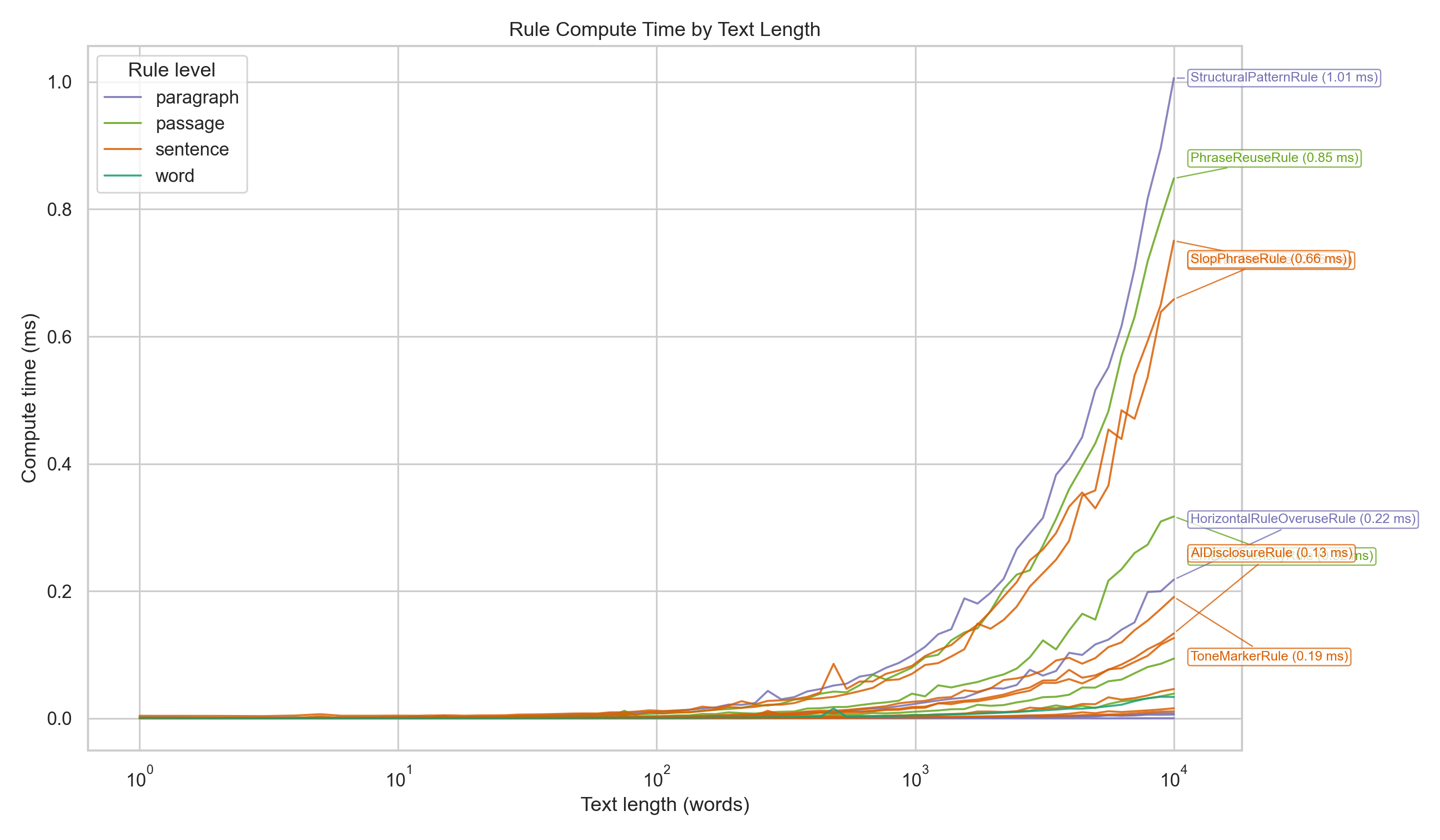
Example per-rule compute-time curves from benchmark/compute-time.py +benchmark/chart.py (annotated with the slowest rules at max length):
License
MIT
Acknowledgements
- @secemp9 for his original anti-slop rubric and inspiration.
- @myainotez for their contributions and many helpful conversations about the project.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found