openLight
Health Gecti
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 25 GitHub stars
Code Basarisiz
- Hardcoded secret — Potential hardcoded credential in configs/agent.example.yaml
- Hardcoded secret — Potential hardcoded credential in configs/agent.openai.example.yaml
- Hardcoded secret — Potential hardcoded credential in configs/agent.rpi.ollama.example.yaml
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool is a lightweight, self-hosted AI agent runtime designed for Raspberry Pi and homelabs. It provides safe Telegram-based status checks, service actions, and alerts for small Linux boxes.
Security Assessment
Risk Rating: Medium. The agent accesses local system metrics (CPU, memory, disk) and interacts with local services via systemd and Docker. It does not request dangerous overarching permissions and relies on an explicit allowlist for operations, which is a strong security design. However, it does execute service actions and allows remote SSH target management, meaning it touches sensitive system controls. Network requests are made to messaging APIs and AI providers (like OpenAI or local Ollama). The automated scan failed due to potential hardcoded credentials found in three example YAML configuration files (`agent.example.yaml`, `agent.openai.example.yaml`, `agent.rpi.ollama.example.yaml`). Because these are example files, they likely contain placeholder tokens rather than actual leaked secrets, but you should verify this before use.
Quality Assessment
The project appears to be of good quality and is actively maintained, with its last code push occurring today. It is properly licensed under the permissive MIT license. Community trust is currently low but growing, as indicated by 25 GitHub stars, which is standard for a niche homelab utility. The repository features a clear description, continuous integration (CI), and transparent documentation outlining its intended capabilities and limitations.
Verdict
Use with caution: it is a well-maintained tool with a secure allowlisted architecture, but administrators must safely configure API keys and verify the example configuration files to avoid exposing system access.
Lightweight AI agent runtime for Raspberry Pi and homelabs, built around deterministic skills and local LLMs.
openLight
Synapse went down → Restart → Back online
![]()
Safe Telegram ops for Raspberry Pi, homelabs, and small Linux hosts.
openLight is a lightweight self-hosted agent for checking box status, handling safe service actions, and receiving actionable alerts from Telegram. It exists for setups where a full agent framework is too heavy, but plain scripts and ad hoc bots are not enough.
- Deterministic-first routing. Slash commands, explicit commands, aliases, and semantic rules run before LLM fallback.
- Safe allowlisted operations. Files, services, runtimes, and remote hosts must be declared in config.
- Local Ollama by default. The bundled Docker path starts
openLightwith Ollama, but the same runtime can also run deterministic-only or with OpenAI.
Good fit / Not a fit
Good fit:
- Raspberry Pi, homelabs, and small self-hosted Linux boxes
- Telegram-based status checks, alerts, and light operational actions
- Users who want a small codebase they can inspect and extend
Not a fit:
- browser agents
- arbitrary shell autonomy
- complex multi-agent orchestration
What it can do today
Core use case: safe Telegram-based status checks, service actions, and alerts for self-hosted boxes.
- Check host status quickly from Telegram with
status,cpu,memory,disk,uptime,hostname,ip, andtemperature. - Inspect, tail logs, and restart allowlisted services across local
systemd, Docker Compose, Docker, and named SSH targets. - Create service and metric watches, then receive Telegram alerts with
Restart,Logs,Status, andIgnoreactions. - Enable built-in packs with
/enable docker,/enable system, and/enable auto-heal. - Run with local Ollama, deterministic-only mode, or remote providers such as OpenAI.
- Reuse the same runtime from Telegram and
cmd/clifor local execution and smoke checks.
Quick start
Recommended path: use the bundled installer. It resolves the latest tagged release, downloads openlight-compose.yaml, and starts openLight plus Ollama in ./openlight.
export TELEGRAM_BOT_TOKEN=123456:replace-me
export ALLOWED_USER_IDS=111111111
curl -fsSL https://raw.githubusercontent.com/evgenii-engineer/openLight/master/scripts/install.sh | bash
After it starts, open Telegram and try:
/start
/status
/enable system
/chat explain load average
Typical first-minute flow with the bundled default stack:
You: /status
openLight:
Hostname: <host>
CPU: <usage>
Memory: <used> / <total>
You: /enable system
openLight:
System pack enabled.
Created 3 watch(es), updated 0.
Defaults: CPU > 90%, Memory > 90%, Disk / > 85%.
System alerts will offer quick Status and Ignore actions.
With allowlisted services configured, a service alert looks like:
You: /watch add service tailscale ask for 30s cooldown 10m
openLight:
Watch created:
#7 service/tailscale down
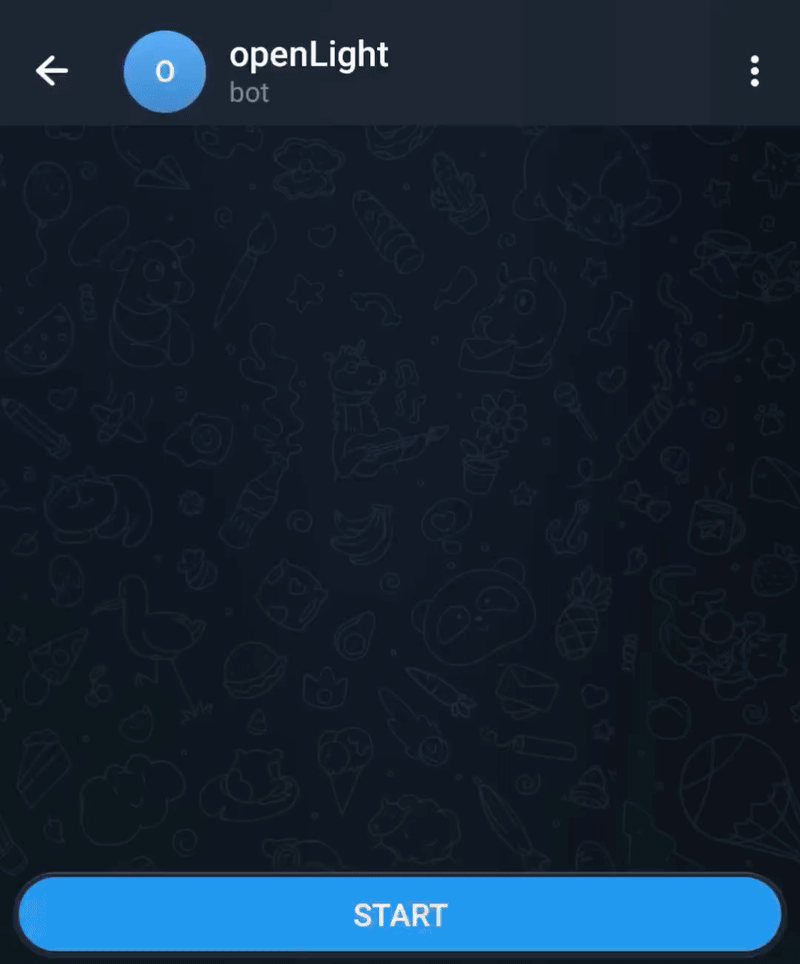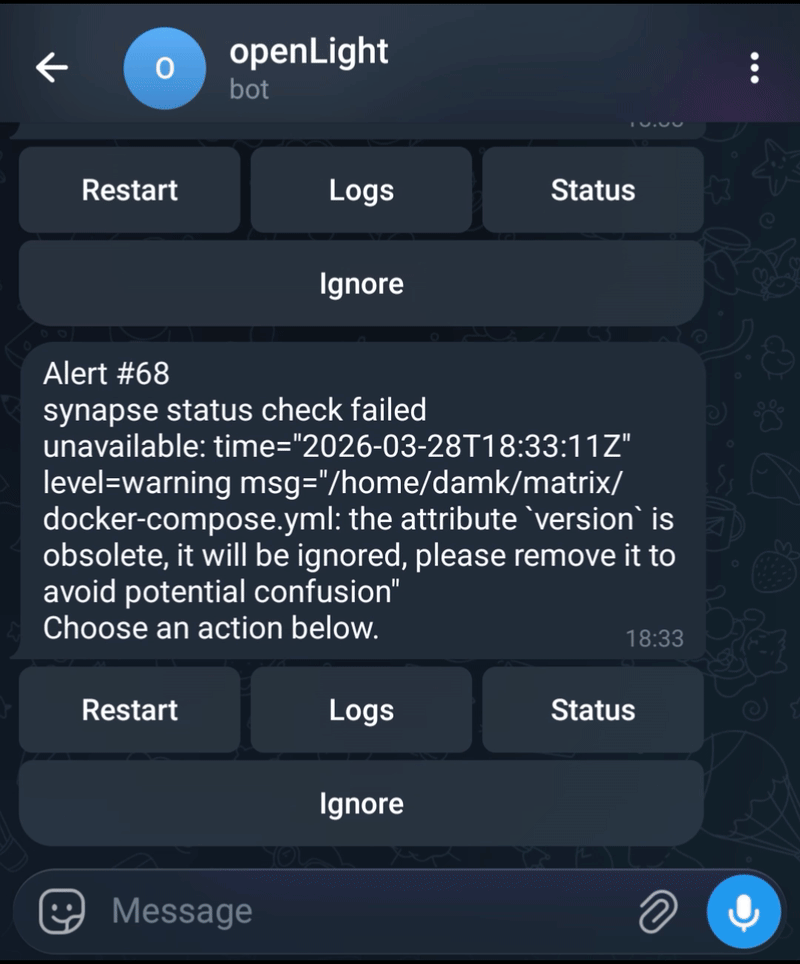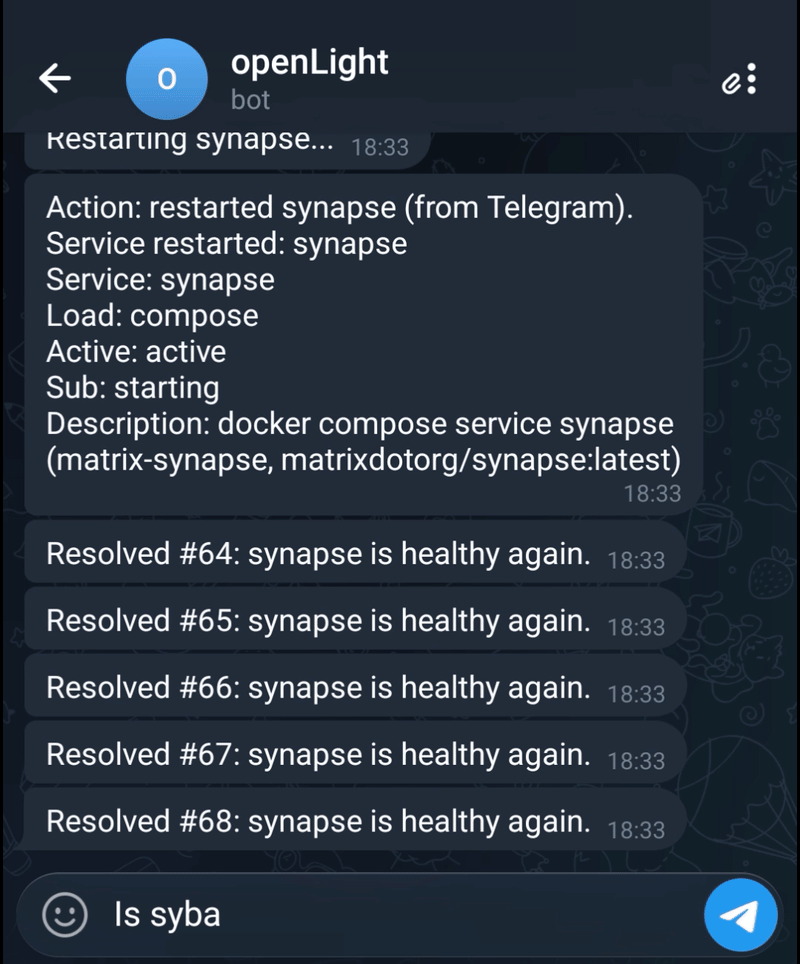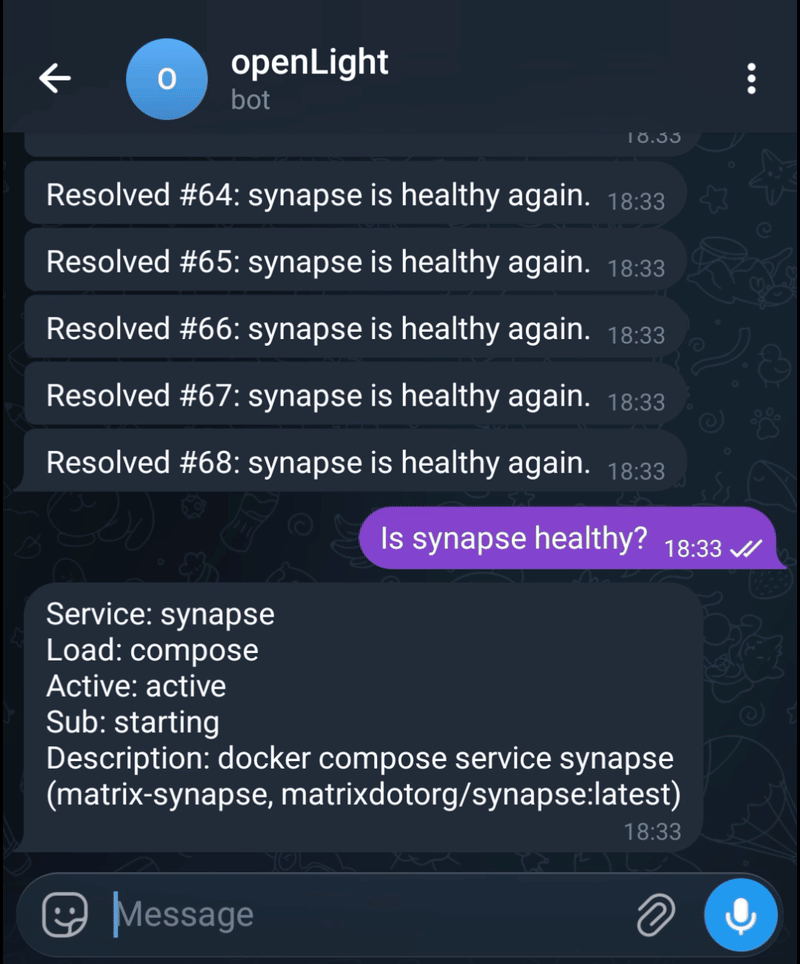
Later, if the service goes down:
openLight:
Alert #7
tailscale is down
[Restart] [Logs] [Status] [Ignore]
That is the core loop: define a safe watch once, then handle real incidents from Telegram.
If you want deterministic-only mode, set LLM_ENABLED=false before running the installer.
Architecture overview
Telegram or CLI
-> auth checks
-> router
-> skill registry
-> storage / watch service / optional LLM
cmd/agentruns the Telegram bot in polling or webhook mode.cmd/cliruns the same runtime locally and adds one-shot execution plus smoke tests.internal/appwires storage, skills, the optional LLM provider, and the watch service.internal/routerhandles slash commands, explicit command text, semantic rules, and optional LLM classification.internal/skillscontains the built-in modules:system,services,files,notes,watch,chat,accounts, andworkbench.internal/storage/sqlitepersists messages, skill calls, notes, watches, watch incidents, and settings.
Run with Docker / Compose
If you already cloned the repo, the top-level openlight-compose.yaml is the same bundled stack used by the installer.
git clone https://github.com/evgenii-engineer/openLight.git
cd openLight
export TELEGRAM_BOT_TOKEN=123456:replace-me
export ALLOWED_USER_IDS=111111111
docker compose up -d
This stack starts:
openlightfromghcr.io/evgenii-engineer/openlight:latestollamaollama-pull, which pullsqwen2.5:0.5bby default
Notes for the bundled stack:
- It is aimed at the local Ollama path.
- It only mounts
./databy default. - The image ships with a minimal
/etc/openlight/agent.yamlthat only sets the SQLite path. - The bundled Compose env expects
ALLOWED_USER_IDSfor the quick-start path. - If you want host file access, host service access, remote SSH hosts, workbench, accounts, webhook mode, or a different provider setup, mount your own config file.
Example mount:
services:
openlight:
volumes:
- ./data:/var/lib/openlight/data
- ./agent.yaml:/etc/openlight/agent.yaml:ro
For deterministic-only Docker usage:
export LLM_ENABLED=false
docker compose up -d
Run locally
Prerequisites:
- Go
1.25+ - a writable SQLite path
- a Telegram bot token
Start from the closest example config:
- configs/agent.example.yaml: deterministic baseline
- configs/agent.rpi.ollama.example.yaml: Raspberry Pi plus Ollama
- configs/agent.openai.example.yaml: OpenAI-backed
Example local run:
cp configs/agent.example.yaml ./agent.yaml
# edit ./agent.yaml
go run ./cmd/agent -config ./agent.yaml
If you want local Ollama for the repo checkout:
make ollama-up
make ollama-pull
go run ./cmd/agent -config ./agent.yaml
The agent binary checks config in this order:
-configOPENLIGHT_CONFIG/etc/openlight/agent.yaml
For Raspberry Pi deployment, the repo includes build and deploy helpers:
cp configs/agent.rpi.ollama.example.yaml ./agent.rpi.yaml
# edit ./agent.rpi.yaml
make deploy-rpi-full PI_HOST=raspberrypi.local PI_USER=pi CONFIG_SRC=./agent.rpi.yaml
make smoke-rpi-cli-ollama PI_HOST=raspberrypi.local PI_USER=pi SMOKE_FLAGS='-smoke-all'
The systemd unit template is deployments/systemd/openlight-agent.service.
Configuration
Important config sections:
telegram: bot token, polling or webhook mode, webhook URL and listen address.auth: allowed Telegram user IDs and chat IDs.storage: SQLite path.services: allowed service targets plus log limits.files: allowed file roots plus read and list limits.access.hosts: named SSH hosts for remote service targets.watch: background polling interval and ask TTL.llm: provider, endpoint, model, thresholds, and optional profiles.accounts: explicit account-provider commands executed inside already allowed services.workbench: optional runtimes, allowed files, and output limits.
Useful env overrides:
TELEGRAM_BOT_TOKENALLOWED_USER_IDSALLOWED_CHAT_IDSSQLITE_PATHLLM_ENABLEDLLM_PROVIDERLLM_ENDPOINTLLM_MODELOPENAI_API_KEYLLM_PROFILETELEGRAM_MODETELEGRAM_WEBHOOK_URLTELEGRAM_WEBHOOK_LISTEN_ADDRTELEGRAM_WEBHOOK_SECRET_TOKEN
Example service and remote-host config:
access:
hosts:
vps:
address: "203.0.113.10:22"
user: "root"
password_env: "OPENLIGHT_VPS_PASSWORD"
known_hosts_path: "/home/pi/.ssh/known_hosts"
services:
allowed:
- tailscale
- "matrix=compose:/home/pi/matrix/docker-compose.yml"
- "web=host:vps:docker:docker-jitsi-meet_web_1"
Polling is the default Telegram mode. Webhook mode is supported through telegram.mode: webhook and telegram.webhook.*.
Skills, routing, providers
Routing order:
- slash commands
- explicit command text such as
service tailscale - skill names and aliases
- semantic rules
- optional LLM route and skill classification
chatfallback when LLM is enabled
The LLM never bypasses the Go-side allowlists. Files, services, remote hosts, accounts, and workbench access still have to be explicitly configured.
Built-in LLM providers:
genericollamaopenai
You can keep multiple LLM profiles in one config file and switch with LLM_PROFILE:
llm:
enabled: true
profile: "ollama"
profiles:
ollama:
provider: "ollama"
endpoint: "http://127.0.0.1:11434"
model: "qwen2.5:0.5b"
openai:
provider: "openai"
endpoint: "https://api.openai.com/v1"
model: "gpt-4o-mini"
For OpenAI, set OPENAI_API_KEY or provide llm.api_key in your config.
Then switch without editing the file:
LLM_PROFILE=openai go run ./cmd/agent -config ./agent.yaml
Example workflows and commands
Basic Telegram session:
/start
/skills
/status
/services
/service tailscale
/logs tailscale
/restart tailscale
Watch setup:
/enable docker
/enable system
/watch add service tailscale ask for 30s cooldown 10m
/watch add cpu > 90% for 5m cooldown 15m
/watch list
/watch history
Files and notes:
/files
/read /tmp/openlight/example.txt
/write /tmp/openlight/example.txt :: hello
/replace hello with hi in /tmp/openlight/example.txt
/note rotate backups
/notes
Local CLI:
go run ./cmd/cli -config ./agent.yaml -exec "status"
go run ./cmd/cli -config ./agent.yaml -exec "watch list"
go run ./cmd/cli -config ./agent.yaml -smoke
go run ./cmd/cli -config ./agent.yaml -smoke-all
Advanced capabilities
- SQLite-backed notes, watches, incidents, messages, and skill-call history
- Allowlisted file read, write, and replace operations
- Optional account-provider flows executed through already allowed services
- Optional workbench runtime for restricted code and file execution
- Polling and webhook Telegram modes
- Multiple LLM profiles switched with
LLM_PROFILE
Project structure
- cmd/agent: Telegram runtime
- cmd/cli: local runner and smoke harness
- internal/app: runtime wiring
- internal/router: deterministic routing and optional LLM classifier
- internal/skills: built-in modules
- internal/watch: watch rules, incidents, and alert actions
- internal/storage/sqlite: SQLite storage
- configs: example configs
- deployments/docker: Docker stack files
- deployments/systemd: systemd unit template
- scripts: install and Raspberry Pi deploy helpers
- migrations: embedded SQLite migrations
Current limitations
- Telegram is the primary interface. The CLI is mainly for local execution and smoke tests.
- Local service control is Linux-oriented and assumes
systemd, Docker Compose, Docker, or configured SSH targets. - Metric watches currently support
notifyonly.askandautorestart flows apply to service-down watches. - Running inside Docker does not automatically expose host services or files. You need an explicit config plus the right mounts or sockets.
- The bundled Docker path is optimized for local Ollama. If you want OpenAI or another remote provider in Docker, use a mounted config and, if needed, extend the Compose environment.
Contributing
Small, focused contributions are the best fit here.
Before opening a PR:
make test
Optional real Ollama end-to-end run:
make ollama-up
make ollama-pull
make test-e2e-ollama
make ollama-down
For deeper project details, see ARCHITECTURE.md and CHANGELOG.md.
License
MIT. See LICENSE.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi