research-innovation-explorer
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 52 GitHub stars
Code Pass
- Code scan — Scanned 6 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
This tool is an AI agent designed to automate academic research discovery. It systematically searches for literature, analyzes combinations of existing papers, and generates polished Markdown reports summarizing the strongest, evidence-backed research hypotheses.
Security Assessment
The overall risk is rated as Low. The automated code scan evaluated 6 files and found no dangerous patterns, hardcoded secrets, or requests for risky permissions. While the agent's "search-first" methodology and its need to "collect recent papers" imply that it makes external network requests to academic databases or search engines, this activity is completely expected and normal for its intended function. It does not appear to access unrelated sensitive data or execute hidden shell commands.
Quality Assessment
The project demonstrates strong health and maintenance indicators. It is actively maintained, with the most recent code push occurring today. The repository is properly licensed under the standard MIT license, making it safe for integration into most projects. It also enjoys a decent level of community trust for a niche research tool, currently backed by 52 GitHub stars.
Verdict
Safe to use.
Host-neutral, search-first skill for literature-grounded research idea discovery, framing, and Markdown reporting.
Research Innovation Explorer
A host-neutral, search-first skill for literature-grounded idea discovery, theory framing, and polished Markdown reporting.


Why This Exists
Most research-idea workflows fail in one of three ways:
- they rely on vague intuition instead of systematic search
- they generate combinations but cannot explain why the combination matters
- they stop at analysis and never produce a clean, evidence-backed report
research-innovation-explorer is built to close those gaps with one coherent workflow:
- Search broadly and repeatedly.
- Decompose papers into reusable capabilities.
- Generate and score candidate combinations.
- Frame the strongest hypothesis honestly.
- Finish with a polished Markdown report that includes citations, analysis basis, and visual summaries.
Core Methodology
This skill is built around one explicit research-production loop:
- Collect roughly 40 recent, top-tier, oral-level, open-source, industry-recognized papers.
- Build a
40 x 40directional combination matrix over those papers. - Remove the diagonal self-pairs and keep the remaining
40 x 39 = 1560possibleA + Bcombinations. - Run fast logical checks, lightweight experiments, and targeted search passes on those 1560 candidates.
- Use the evidence to filter the space down to roughly 15 ideas that are actually defensible and runnable.
This is the operational core of the workflow, not a side note. The point is not to wait for a single flash of inspiration. The point is to search comprehensively, force structured combination, validate aggressively, and only then keep the few ideas that survive contact with evidence.
| Stage | What to do | What comes out |
|---|---|---|
| Paper pool | Gather around 40 strong recent papers with code and real impact | a reusable capability inventory |
| Combination pass | Enumerate the 40 x 40 space and remove self-pairs |
1560 directional A + B candidates |
| Fast validation | Search prior work, inspect code, run quick logic checks or minimal experiments | a smaller set of realistic options |
| Final shortlist | Keep only combinations that remain novel enough, coherent enough, and implementable enough | about 15 viable ideas |
What You Get
| Layer | What it does |
|---|---|
SKILL.md |
Defines the end-to-end workflow and decision rules |
scripts/build_search_queries.py |
Generates structured query packs for topic scan, novelty checks, and failure analysis |
scripts/build_idea_matrix.py |
Builds a scored pairwise candidate matrix from the paper pool |
scripts/build_research_figures.py |
Generates publication-style literature heatmaps, scoring heatmaps, and analysis panels from the research artifacts |
scripts/build_markdown_report.py |
Scaffolds a polished Markdown report with Mermaid visuals, evidence tables, and references |
references/ |
Contains the search playbook, theory framing rules, reporting rules, and ethics boundaries |
assets/templates/ |
Provides ready-to-use CSV and Markdown templates for search logs, paper pools, idea briefs, experiment plans, and reports |
Workflow
flowchart LR
A[Search Pass] --> B[Paper Pool]
B --> C[Capability Decomposition]
C --> D[Idea Matrix]
D --> E[Shortlist]
E --> F[Theory Framing]
F --> G[Experiment Plan]
G --> H[Markdown Report]
Design Principles
1. Search First
The skill assumes that current literature claims should not come from memory alone when search is available.
2. Honest Framing
It supports strong abstraction and theory writing, but only when the assumptions, limiting cases, and failure boundaries are real.
3. Evidence-Carrying Reports
The final Markdown output is not a pretty wrapper around intuition. It must include:
- citations
- explicit analysis basis
- candidate comparison
- visual summaries
4. Host Neutrality
The workflow is portable across different agent hosts and even manual use. The repo does not depend on one specific runtime.
Quick Start
1. Prepare the search pack
python scripts/build_search_queries.py \
--topic "long-context reasoning" \
--keywords "memory routing, verifier head, benchmark"
2. Build the paper pool
Start from:
assets/templates/search-log.csvassets/templates/paper-pool.csv
3. Generate the idea matrix
python scripts/build_idea_matrix.py \
assets/templates/paper-pool.csv \
--output work/idea-matrix.csv
4. Generate the Markdown report
Generate static figures first when the final research output should include academic paper-style data visuals:
python scripts/build_research_figures.py \
--paper-pool assets/templates/paper-pool.csv \
--idea-matrix work/idea-matrix.csv \
--output-dir work/figures \
--topic "Long-Context Reasoning" \
--prefix long_context
python scripts/build_markdown_report.py \
--topic "Long-Context Reasoning" \
--paper-pool assets/templates/paper-pool.csv \
--idea-matrix work/idea-matrix.csv \
--search-log assets/templates/search-log.csv \
--figure-dir work/figures \
--figure-prefix long_context \
--output work/report.md
Output Style
The reporting layer is intentionally designed for GitHub-native reading:
- Mermaid flowcharts for process explanation
- static PNG heatmaps for matrix snapshots and worked examples
- Mermaid pie charts for quick distribution views
- Markdown evidence tables for claim tracing
- compact narrative sections for executive summary and detailed analysis
This makes the output readable both as a working note and as a shareable artifact.
Example Output
Exploring LLM Training Directions
This worked example uses frontier large language model training research as the target domain. It starts from a search-backed pool of roughly 40 recent, top-tier, oral-level, open-source, industry-recognized papers, builds a 40 x 40 directional matrix, removes the diagonal, and then searches, inspects, and lightly validates the remaining 1560 A + B candidates until only a small shortlist remains.
At the survey level, the workflow turns the literature into a readable interaction matrix instead of a prose dump:
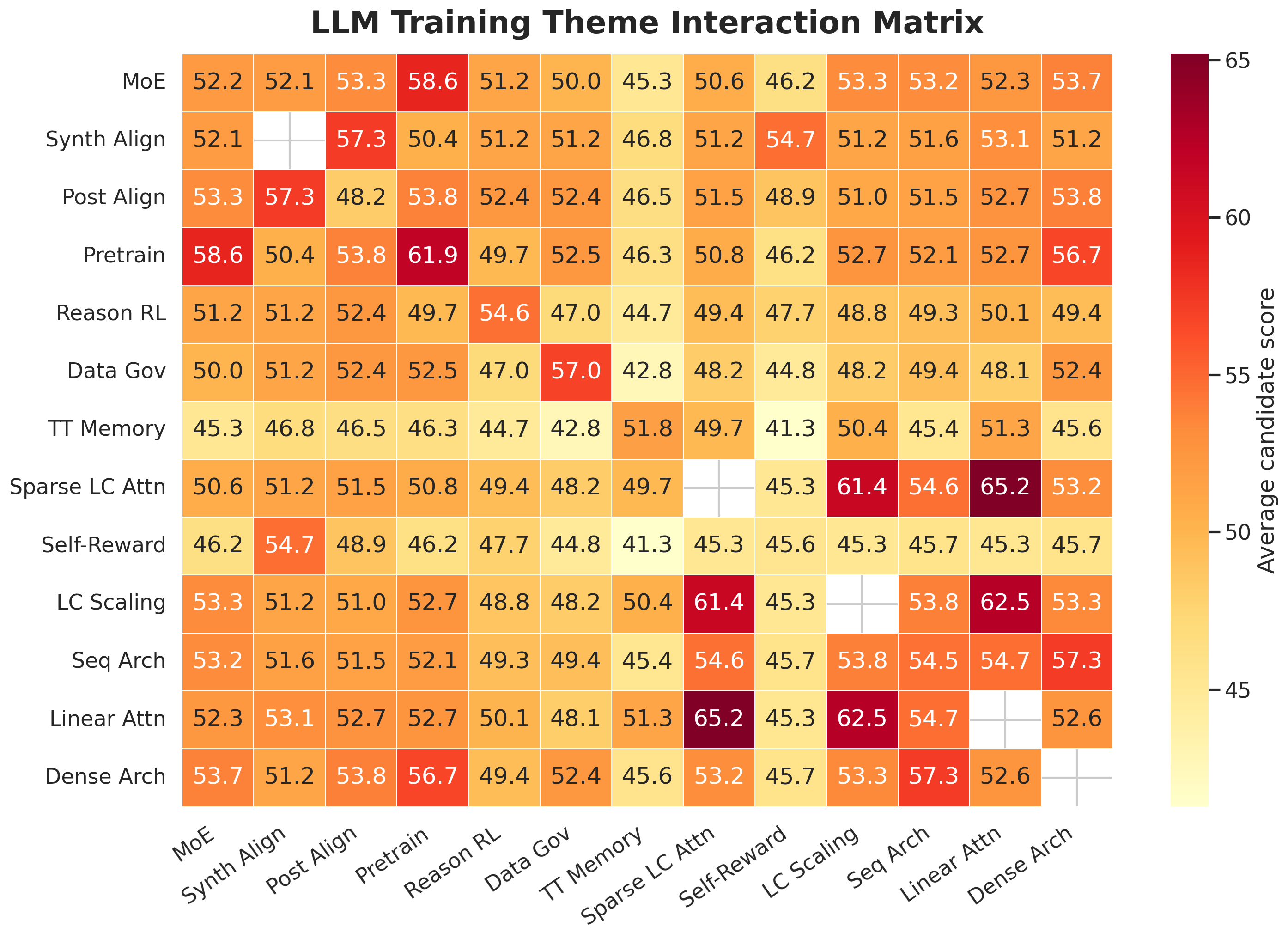
At the decision level, the workflow collapses the shortlist into a result matrix that exposes novelty space, implementation feasibility, evaluation clarity, open-source readiness, and narrative sharpness:
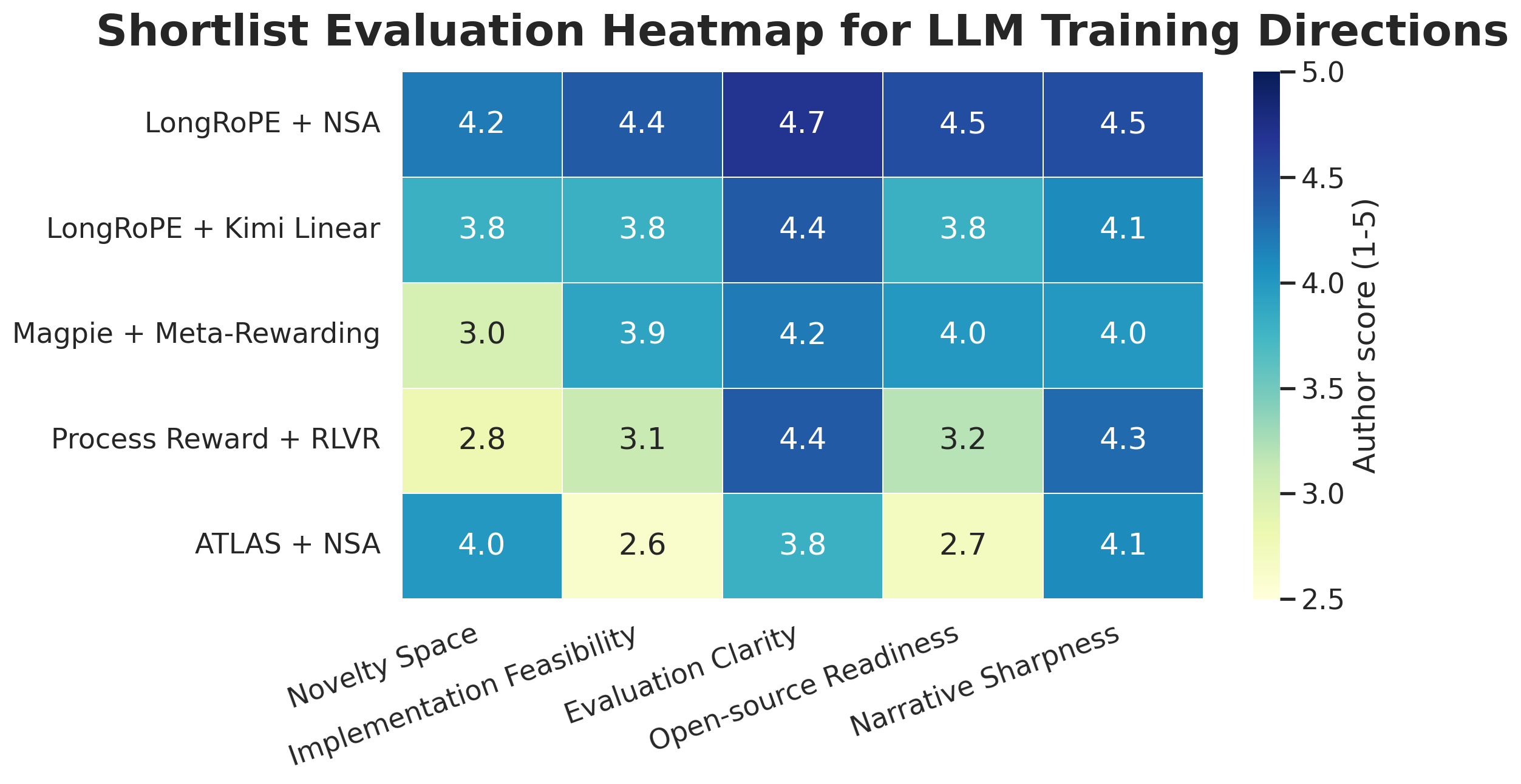
What this example demonstrates:
- search is used during collection and during analysis, not only at the beginning
- the
40 x 40 -> 1560 -> ~15narrowing process is explicit and inspectable - GitHub README pages and Markdown reports can show the screening logic with direct images, without depending on host-side math rendering
The bundled example images live in assets/examples/llm-training/ and can be regenerated with scripts/build_llm_training_example_figures.py.
Repository Layout
.
├── SKILL.md
├── README.md
├── README.zh-CN.md
├── agents/
│ └── openai.yaml
├── assets/
│ ├── examples/
│ │ └── llm-training/
│ └── templates/
├── references/
└── scripts/
├── build_idea_matrix.py
├── build_llm_training_example_figures.py
├── build_markdown_report.py
├── build_research_figures.py
└── build_search_queries.py
Recommended Use Cases
- discovering incremental but defensible research ideas
- mapping literature around a topic before starting implementation
- checking whether an A+B combination already exists in prior work or code
- producing a strong Markdown research memo with citations and visual summaries
- training literature review, abstraction, evaluation design, and research writing habits
Documentation
- Core workflow:
SKILL.md - Search protocol:
references/search-playbook.md - Theory framing:
references/framing-and-theory.md - Reporting rules:
references/reporting-and-visualization.md - Report template:
assets/templates/analysis-report-template.md
Notes
- If your host cannot render Mermaid, keep the Markdown tables and replace Mermaid blocks with static images or plain-text summaries.
- If your host has no search capability, use the workflow manually and explicitly downgrade confidence in current-literature claims.
Community
For broader discussion around tools, workflows, and AI-native building, visit linux.do.
License
This repository is released under the MIT License.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found