multi-bot-agentic
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Deterministic multi-provider AI-agent orchestrator — ODA loops, GPT/Claude/Gemini/Kimi adapters, safety controls, event log
multi-bot-agentic
multi-bot-agentic is a standalone AI-agent engineering showcase: a deterministic agent coordinator with explicit Observe -> Decide -> Act loops, durable event logs, rationale traces, provider adapters, and bounded safety controls.
It is built as a portfolio-quality recreation of the multi-bot product idea without depending on private infrastructure. The default path runs fully offline with a deterministic fake provider. Real adapters are included for OpenAI GPT, Claude Code CLI, Gemini, and Kimi/Moonshot.
Why It Exists
Most agent demos let the LLM decide everything. This repo takes the production-minded path:
- The LLM is an input source, not the control plane.
- A deterministic decision engine chooses actions.
- Every decision has a rationale trace.
- Every lifecycle transition is persisted.
- Every external integration goes through an adapter.
- Safety controls bound scope, runtime, tools, and cancellation.
Use Cases: Issues This Solves
1. "My agent did something, but I cannot explain why."
LLM-first agents often skip straight from prompt to action. When something goes wrong, the transcript may show what the model said, but not which control rule allowed the action.
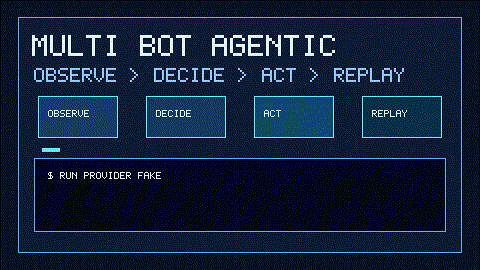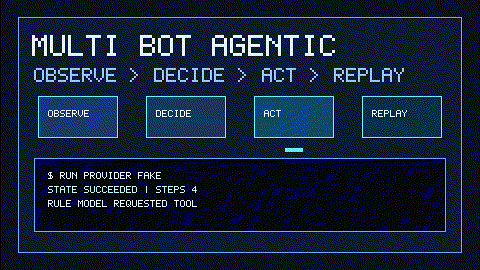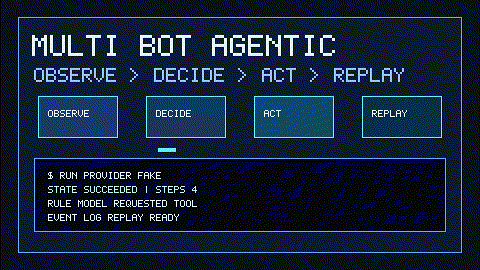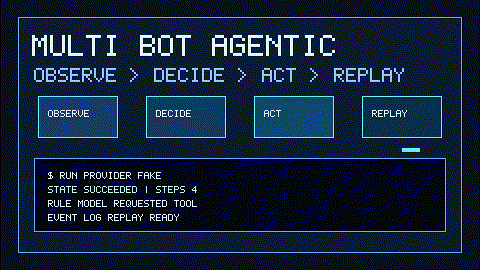
multi-bot-agentic writes every decision as a durable event with a RationaleTrace: rule id, observations used, rejected actions, and explanation. You can replay the run later and inspect exactly why the engine chose call_llm, call_tool, finish, or cancel.
multi-bot-agentic replay --event-log data/runs.sqlite --event-type decision --format text
2. "I want to use AI agents, but I do not want the model directly executing tools."
Many agent frameworks let the model choose and invoke tools directly. That is convenient, but risky for production workflows where tool access should be explicit, bounded, and auditable.
This repo treats model output as an observation. The deterministic decision engine interprets constrained text like TOOL:checklist:<payload>, checks the safety policy, and only then executes an allowlisted tool adapter.
3. "I need the same agent flow to work with GPT, Claude Code, Gemini, and Kimi."
Provider-specific SDKs and response shapes make agent code hard to port. A prototype built around one model often leaks provider details into the orchestration layer.
multi-bot-agentic normalizes providers behind one adapter interface:
OpenAIAdapterfor GPT/OpenAI-compatible chat completions.ClaudeCodeCLIAdapterfor local Claude Code CLI workflows.GeminiAdapterfor GeminigenerateContent.KimiAdapterfor Moonshot/Kimi chat completions.FakeLLMAdapterfor deterministic CI and demos.
The runner consumes all provider responses as ModelOutput, so orchestration logic stays provider-neutral.
4. "I need a safe demo path that does not require API keys."
Portfolio and CI demos should not depend on live model credentials, model availability, or network behavior.
The fake provider produces deterministic model-like outputs that the real runtime consumes. It still exercises Observe -> Decide -> Act, tool routing, safety checks, event logging, replay, and reports.
multi-bot-agentic run --goal "Create a launch checklist for an AI agent platform" --provider fake
5. "Agent runs fail silently or leave no durable audit trail."
Long-running agent tasks need post-run inspection. Without durable state, crashes and restarts turn into guesswork.
The sqlite event log records lifecycle transitions, observations, decisions, action requests, action results, failures, cancellations, and completion. Replay does not call any provider or tool, so postmortems are safe and deterministic.
multi-bot-agentic report --event-log data/runs.sqlite
6. "The agent keeps looping or spending tokens without finishing."
Unbounded agent loops are a common failure mode. They waste time, cost money, and make incident response harder.
SafetyPolicy bounds run scope with max_steps, provider/tool timeouts, prompt size limits, cancellation files, and tool allowlists. If the run reaches its budget, the decision engine finishes or fails through explicit lifecycle events.
7. "I need to compare AI provider behavior without rewriting my orchestration."
Teams often want to test GPT vs Gemini vs Kimi vs Claude Code, but provider-specific code makes comparisons noisy.
With provider adapters, you can keep the same runner, same decision engine, same event log, and same replay/report UX while swapping the provider:
multi-bot-agentic run --goal "Draft a migration plan" --provider openai
multi-bot-agentic run --goal "Draft a migration plan" --provider gemini
multi-bot-agentic run --goal "Draft a migration plan" --provider kimi
multi-bot-agentic run --goal "Draft a migration plan" --provider claude_code
8. "I want agents to produce useful artifacts, not just chat text."
Agent demos often end with prose. Real workflows need structured, repeatable artifacts.
The built-in checklist tool turns a goal into a deterministic launch checklist and records the tool result in the event log. It is intentionally simple, but it demonstrates the production pattern: model suggests, policy validates, adapter executes, event log records.
9. "I need a clean teaching or interview example for agent architecture."
Agent systems can become hard to explain when planning, tool use, model calls, retries, and state are mixed together.
This repo keeps the boundaries visible:
runner.py: owns Observe -> Decide -> Act.decision.py: deterministic rules and rationale traces.lifecycle.py: state-machine transitions.event_log.py: durable sqlite events.llm/: provider adapters.tools/: allowlisted tool adapters.safety.py: bounds and cancellation.
10. "I need CI to prove the agent works without real provider credentials."
Live provider tests are useful, but they should not be required for every pull request.
CI runs lint, format, typecheck, tests, and a fake-provider smoke demo across Python 3.10, 3.11, and 3.12. Live provider calls remain operator-triggered because they require credentials and external systems.
Architecture At A Glance
Goal
|
v
Observe -> durable observation event
|
v
Decide -> deterministic rule + rationale trace
|
v
Act -> LLM adapter or allowlisted tool
|
v
Event log + replay
Quick Demo
python -m venv .venv
. .venv/bin/activate
python -m pip install -e ".[dev]"
ruff check .
ruff format --check .
mypy src tests
pytest
multi-bot-agentic run --goal "Create a launch checklist for an AI agent platform" --provider fake
Replay the durable event log:
multi-bot-agentic replay --event-log data/runs.sqlite
multi-bot-agentic replay --event-log data/runs.sqlite --format text
multi-bot-agentic report --event-log data/runs.sqlite
What This Showcases
- Explicit Observe -> Decide -> Act runtime loop.
- Deterministic decision engine with rationale traces.
- State-machine lifecycle: created, observing, deciding, acting, succeeded, failed, cancelled.
- Durable sqlite event log with replay.
- LLM adapters for OpenAI GPT, Claude Code CLI, Gemini, and Kimi/Moonshot.
- Tool adapters with allowlisted execution, including deterministic checklist generation.
- Safety controls for max steps, prompt bounds, cancellation, and timeouts.
- Human-readable replay and run reports for inspecting durable rationale traces.
- Production-minded layout:
src/,tests/,scripts/,migrations/,.github/workflows/, env config, docs.
Providers
| Provider | Adapter | Live credential |
|---|---|---|
| Fake | deterministic local provider | none |
| GPT / OpenAI | OpenAIAdapter |
OPENAI_API_KEY |
| Claude Code | ClaudeCodeCLIAdapter |
local claude command |
| Gemini | GeminiAdapter |
GEMINI_API_KEY |
| Kimi / Moonshot | KimiAdapter |
KIMI_API_KEY |
All adapters normalize output into ModelOutput. The runner consumes that output as an observation before the decision engine selects the next action.
Built-In Safe Tools
checklist: deterministic launch checklist generator used by the fake-provider demo.echo: safe text echo for adapter tests.readonly_file: root-contained read-only file reader.
Repository Layout
src/multi_bot_agentic/ runtime, lifecycle, decision engine, event log, adapters
tests/ deterministic unit and integration tests
scripts/ demo and verification scripts
migrations/ sqlite schema scaffold
docs/ architecture, safety, config, quickstart, demo
.github/workflows/ CI for lint, format, typecheck, tests, demo smoke
Documentation
Verification
scripts/check.sh
scripts/check.sh runs ruff, format check, mypy, pytest, and a fake-provider smoke run with replay/report. CI runs the same script on Python 3.10, 3.11, and 3.12.
For a richer local demo:
scripts/run_demo.sh
Visual Asset
The README GIF is reproducible:
python scripts/render_demo_gif.py
The repo also keeps docs/demo.svg as a static architecture card.
License
MIT — see LICENSE.
Production use cases
Real issues this agent solves — deterministic ODA loop, rationale traces, durable event log,
GPT / Claude / Gemini / Kimi adapters, and safety controls (timeouts, bounded scope, cancellation).
| Issue | Problem | Solution doc |
|---|---|---|
| #001 | Non-deterministic agent loops hard to debug | doc |
| #002 | Long-running tasks need cancellation | doc |
| #003 | Tool failures should not crash the run | doc |
Full index: docs/use-cases/README.md
Agentic design
- Decision engine — deterministic step selection with logged rationale
- State machine —
pending → running → completed | failed | cancelled - Event log — SQLite/JSON audit trail for replay
- Tool adapters — pluggable HTTP/LLM/retrieval integrations
- Safety — timeouts, cancellation tokens, bounded clinical scope
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found