ChronoLog
Health Uyari
- License — License: BSD-2-Clause
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 9 GitHub stars
Code Basarisiz
- rm -rf — Recursive force deletion command in .github/scripts/dynamic_deploy.sh
- fs module — File system access in .github/workflows/check-format.yml
- rm -rf — Recursive force deletion command in .github/workflows/create-release.yml
- rm -rf — Recursive force deletion command in .github/workflows/integration-pipeline.yml
- rm -rf — Recursive force deletion command in .github/workflows/publish-dev-image.yml
- rm -rf — Recursive force deletion command in CI/docker/dynamic_deploy.sh
- rm -rf — Recursive force deletion command in CI/docker/dynamic_deploy_pearc2025.sh
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool is a high-performance, distributed storage infrastructure designed to handle activity and log workloads. It provides an MCP server to integrate this log storage system directly with Large Language Models (LLMs) for real-time event processing.
Security Assessment
Overall Risk: Low (with execution caveats)
The tool is designed to process and store logs, which could potentially include sensitive operational data depending on how it is configured by the user. It does not request dangerous permissions, and no hardcoded secrets were detected. However, the automated testing and deployment scripts contain multiple `rm -rf` (recursive force deletion) commands. While these deletions appear confined to GitHub Actions and CI/Docker scripts rather than the core application, they still represent a standard execution risk if those specific scripts are run locally. No malicious network requests or unauthorized shell executions were found in the core program logic.
Quality Assessment
The project demonstrates strong foundational health. It uses the permissive BSD-2-Clause license and has a clear, detailed description of its capabilities. Backed by reputable academic institutions (Illinois Tech and UChicago), the repository is highly active with a push made as recently as today. The only notable weakness is its low community visibility; having only 9 GitHub stars means it has not yet been broadly tested or adopted by the open-source community, so external peer review is minimal.
Verdict
Use with caution: The core infrastructure is actively maintained by academic researchers, but the low community adoption and presence of aggressive file deletion commands in the deployment scripts warrant a careful review before integrating into production environments.
A High-Performance Storage Infrastructure for Activity and Log Workloads
[!IMPORTANT]
ChronoLog MCP is now available.
Integrate ChronoLog directly with LLMs through our new MCP server for real-time logging, event processing, and structured interactions.
Code - Documentation
![]()
ChronoLog
Distributed Shared Tiered Log Store
A distributed and tiered shared log storage ecosystem that uses physical time to distribute log entries while providing total log ordering.

![]()
![]()
![]()


Members
 Illinois Tech |
 UChicago |
Overview
ChronoLog is a distributed, tiered shared log storage system that provides scalable log storage with time-based data ordering and total log ordering guarantees. By leveraging physical time for data distribution and utilizing multiple storage tiers for elastic capacity scaling, ChronoLog eliminates the need for a central sequencer while maintaining high performance and scalability.
The system's modular, plugin-based architecture serves as a foundation for building scalable applications, including SQL-like query engines, streaming processors, log-based key-value stores, and machine learning integration modules.
Key Features
ChronoLog is built on four foundational pillars:
Time-Structured Ingestion — Events are chunked and organized by physical time, enabling high-throughput parallel writes without a central sequencer.
Tiered & Efficient Storage — StoryChunks flow across fast and scalable storage tiers, automatically balancing performance and capacity.
Concurrent Access at Scale — Multi-writer, multi-reader support with zero coordination overhead, optimized for both RDMA and TCP networks.
Modular, Extensible Serving Layer — Plugin-based architecture enables custom services to run directly on the log, supporting diverse application requirements.
Use Cases
ChronoLog's flexible architecture supports a wide range of applications:
AI & LLM Integration — MCP server for seamless LLM integration with enterprise logging and real-time event processing.
Machine Learning & Training — TensorFlow module for training and inference workflows using time-ordered data streams.
SQL-like Query Engine — Query and analyze log data with SQL semantics and time-based distribution.
Streaming Processor — Real-time event processing and analytics for monitoring, alerting, and data pipelines.
Log-based Key-Value Store — Distributed key-value stores with strong consistency guarantees.
For more information, visit chronolog.dev.
Installation
[!NOTE]
ChronoLog is designed for deployment on distributed clusters and complex environments.
For comprehensive installation guides, configuration details, and deployment strategies, please refer to our detailed documentation on the Wiki.
🐳 Docker Installation 
Single-Node Deployment
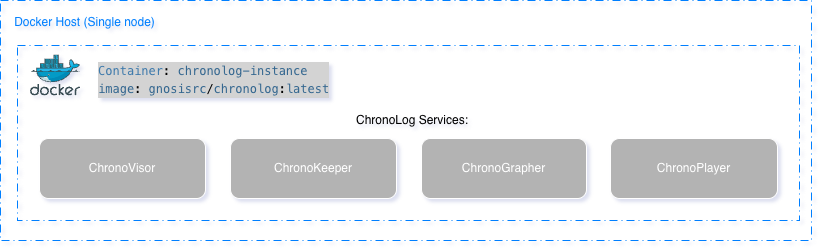
Pull Docker image:
docker pull gnosisrc/chronolog:latest
Run container interactively:
docker run -it --rm --name chronolog-instance gnosisrc/chronolog:latest
Deploy components:
/home/grc-iit/chronolog_repo/deploy/local_single_user_deploy.sh -d -w /home/grc-iit/chronolog_install/Release
Verify deployment:
pgrep -la chrono
For detailed setup instructions, troubleshooting, and advanced configuration, see: Single-node Docker tutorial
Multi-Node Deployment
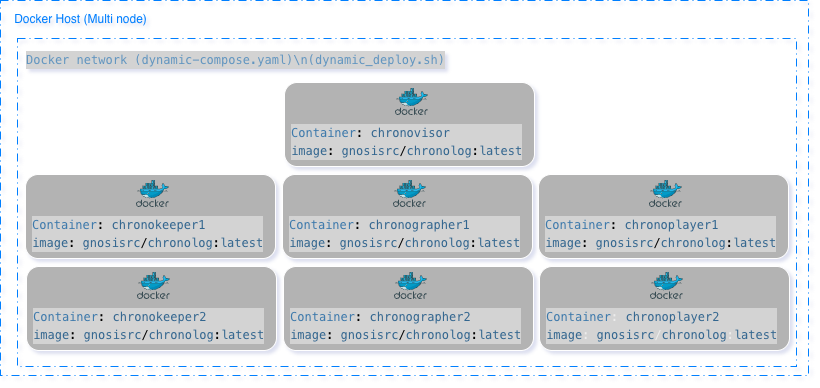
Pull Docker image:
docker pull gnosisrc/chronolog:latest
Download deployment script:
wget https://raw.githubusercontent.com/grc-iit/ChronoLog/refs/heads/develop/CI/docker/dynamic_deploy.sh
chmod +x dynamic_deploy.sh
Run default deployment:
./dynamic_deploy.sh -n 7 -k 2 -g 2 -p 2
Verify containers:
docker ps
For detailed setup instructions, troubleshooting, and advanced configuration, see:
Multi-Node Docker tutorial
Documentation
Comprehensive documentation and tutorials are available on our Wiki. The documentation covers everything from getting started to advanced configuration and deployment strategies.
📚 Documentation
| Document | Description |
|---|---|
| Getting Started | Introduction and first steps with ChronoLog |
| Installation | Detailed installation guides and requirements |
| Configuration | Configuration options and settings |
| Deployment | Deployment strategies and best practices |
| Client API | API reference and usage examples |
| Client Examples | Code examples and use cases |
| Architecture | System architecture and design principles |
| Plugins | Plugin development and integration |
| Code Style Guidelines | Coding standards and conventions |
| Contributors Guidelines | Guidelines for contributing to ChronoLog |
🎓 Tutorials
| Tutorial | Description |
|---|---|
| Tutorial 1: First Steps with ChronoLog | Get started with your first ChronoLog deployment |
| Tutorial 2: How to run a Performance test | Learn how to benchmark and test ChronoLog performance |
| Tutorial 3: Running ChronoLog with Docker (single-node) | Deploy ChronoLog on a single node using Docker |
| Tutorial 4: Running ChronoLog with Docker (Multi-Node) | Deploy ChronoLog across multiple nodes using Docker |
Collaborators
We are grateful for the collaboration and support from our research and industry partners.
| Organization | Description |
|---|---|
 Argonne National Laboratory Argonne National Laboratory |
Collaborating with the funcX team to enable event-based and real-time computing capabilities, supporting scalable execution of machine learning workloads and integration with Colmena framework for materials science applications. |
| University of Chicago |
Working with Tom Glanzman and the Dark Energy Science Collaboration on Parsl workflow extensions for Rubin Observatory data processing, enabling extreme-scale logging and monitoring for cosmology workflows. |
 Parsl Parsl |
Developing workflow extensions to enable extreme-scale logging and monitoring for large-scale scientific workflows, with potential impact across domains including biology, social science, and high energy physics. |
 Institute for Food Safety and Health (IFSH) Institute for Food Safety and Health (IFSH) |
Exploring new scientific applications of ChronoLog in genomics and bioinformatics, with discussions helping shape development priorities while informing adjacent research communities about ChronoLog capabilities. |
 Lawrence Livermore National Laboratory Lawrence Livermore National Laboratory |
Working with the system scheduler team to integrate ChronoLog with Sonar and Flux job scheduler, eliminating bottlenecks in HPC resource management and telemetry data collection. |
 University of Wisconsin-Madison University of Wisconsin-Madison |
Working with Shaowen Wang to deploy ChronoLog as a storage backend for CyberGIS, addressing growing data volume and velocity demands while refining ChronoLog features through GIS workloads. |
 University of Illinois at Urbana-Champaign University of Illinois at Urbana-Champaign |
Collaborating on Parsl workflow extensions for the Dark Energy Science Collaboration, enabling extreme-scale logging and monitoring for Rubin Observatory data processing workflows. |
 DePaul University DePaul University |
Working with Tanu Malik to develop novel lightweight indexing mechanisms within the ChronoKeeper for efficient querying of log data by both identifier and value predicates. |
 ParaTools, Inc. ParaTools, Inc. |
Exploring integration and evaluation of ChronoLog with performance monitoring tools, optimizing ChronoLog and its native plugins for application performance analysis use cases. |
 OmniBond Systems LLC OmniBond Systems LLC |
Working with Boyd Wilson to fine-tune the storage stack using extended attributes in OrangeFS, optimizing ChronoLog's multi-tiered distributed log store performance. |
Resources
- Documentation: Visit chronolog.dev for comprehensive documentation and guides
- GitHub Repository: github.com/grc-iit/ChronoLog
- Issues & Support: Report issues or request features on GitHub Issues
- Releases: Check out the latest releases on GitHub Releases
Gnosis Research Center
Illinois Institute of Technology
Advancing the Future of Scalable Computing and Data-Driven Discovery
Connect with us:
🌐 Website • 🐦 X (Twitter) • 💼 LinkedIn • 📺 YouTube • ✉️ Email
Sponsored by:

National Science Foundation (NSF CSSI-2104013)
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi