Istara
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Warn
- process.env — Environment variable access in .github/workflows/track-autoresearch.yml
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Agentic Research Orchestration for UX Research and Product Development. Vibe and handcoded by a social and data scientist with background in many research domains and open-source
🐾 Istara
Local-first AI agents for UX Research — your data never leaves your machine
![]()
![]()
![]()
![]()
![]()
Install in 1 Minute · Architecture · Research Skills · Agents · References · Contributing
Five autonomous AI agents. Fifty-three self-improving research skills. Zero cloud dependency.
Every insight is evidence-grounded. Every agent gets smarter with every session.
Scale your intelligence: share compute between team members to run more agents simultaneously—a smarter, faster team working as one agentic swarm.
At a Glance
| Feature | What It Does |
|---|---|
| 🧠 Intelligent Chat | Grounded conversations with your research data — no hallucinations, just evidence-backed answers |
| ⚛️ Atomic Findings | Nuggets → Facts → Insights → Recommendations, every claim linked to its original source |
| 📐 Laws of UX | 30+ psychological principles audited automatically against your designs with scoring |
| 📋 Kanban Board | Agents pick up tasks, execute skills, and report progress in real time — fully autonomous |
| 🎯 Smart Routing | Match tasks to specialists — Pixel for UI audits, Sage for UX eval, Echo for simulations |
| 🎙️ Interview Analysis | Transcribe, tag, analyze, relate and generate reports across your entire participant pool |
| 🧭 Context Engine | Ground agents in company culture, project goals and custom guardrails for better performance |
| 🛠️ 53+ Research Skills | Competitive analysis, card sorting, journey mapping — agents equipped for any challenge |
| 🐝 Agent Swarm | Five specialized agents that learn from each other and evolve with every single task |
| 🎨 Google Stitch & Figma | Generative AI screen design, handoff specs, component audits — design-to-dev bridge built in |
| 💬 Messaging Channels | Deploy research to Slack, Telegram, WhatsApp — managed entirely by your agents |
| 📊 Survey Sync | Pull from SurveyMonkey, Typeform, Google Forms — synthesize thousands of responses fast |
| 🔄 Autoresearch | Continuous self-improvement — agents optimize their own prompts and RAG parameters |
| ✅ Ensemble Health | Multi-model consensus, adversarial review, debate rounds — every insight rock solid |
Multi-Agent Assignment: Choose the best agent for the job. Route tasks to specialists like Pixel for UI audits or Sage for UX evaluation.
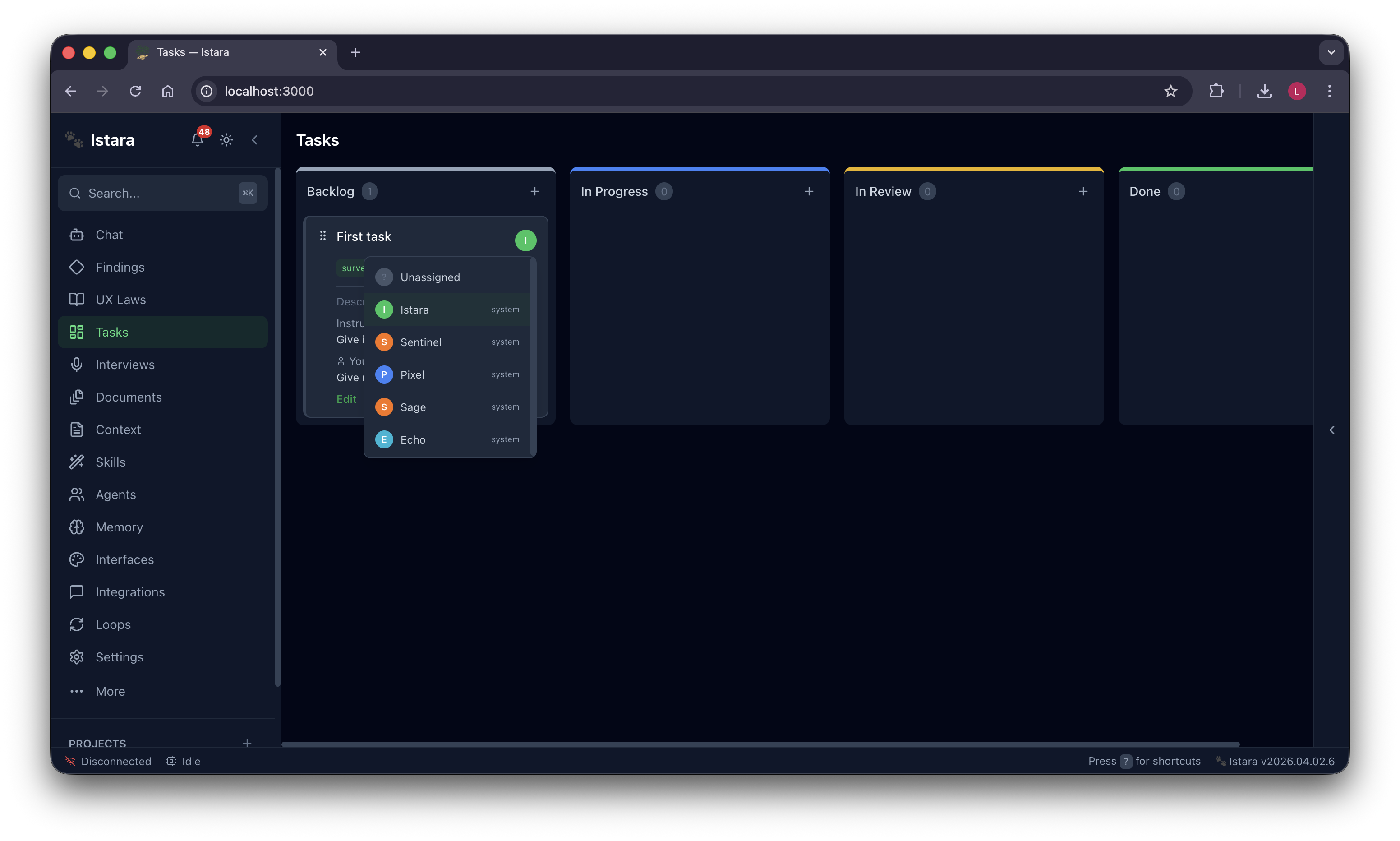
Autonomous Task Management: A powerful Kanban board where agents pick up tasks, execute skills, and report progress in real-time.
<<<<<<< HEAD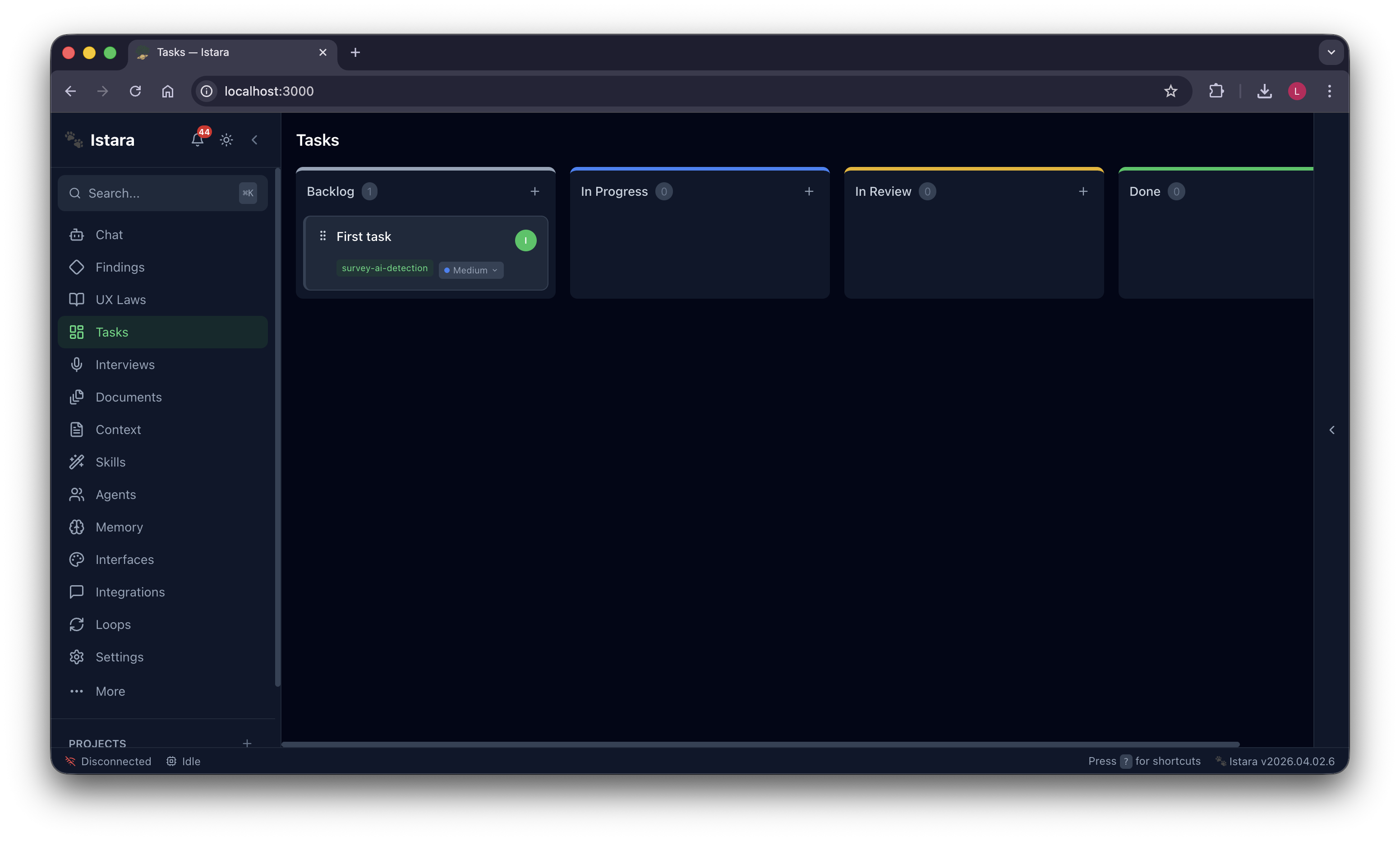
=======
Multi-Agent Assignment: Choose the best agent for the job. Route tasks to specialists like Pixel for UI audits or Sage for UX evaluation.
Interviews & Transcripts: Istara can transcribe, tag, analyze, relate, and generate reports from many interviews at once — including voice messages from WhatsApp and Telegram with automatic Whisper transcription and inter-coder reliability scoring. Find insights shared across your entire participant pool!
Context Engine: Ground your agents in your company culture, project goals, and specific guardrails. The more they know, the better they perform.
feat/voice-transcription
Skill Catalog: Over 50 research skills ready to go. From Competitive Analysis to Card Sorting, your agents are equipped for any research challenge.
Agentic Swarm: Meet your team—Cleo, Sentinel, Pixel, Sage, and Echo. Five specialized agents that learn from each other and evolve with every task.
Messaging Channels: Deploy your research directly to Slack, Telegram, or WhatsApp. Collect data where your users are, managed entirely by your agents.
Autoresearch Engine: Enable continuous self-improvement loops. Watch as your agents optimize their own prompts and RAG parameters for better results.
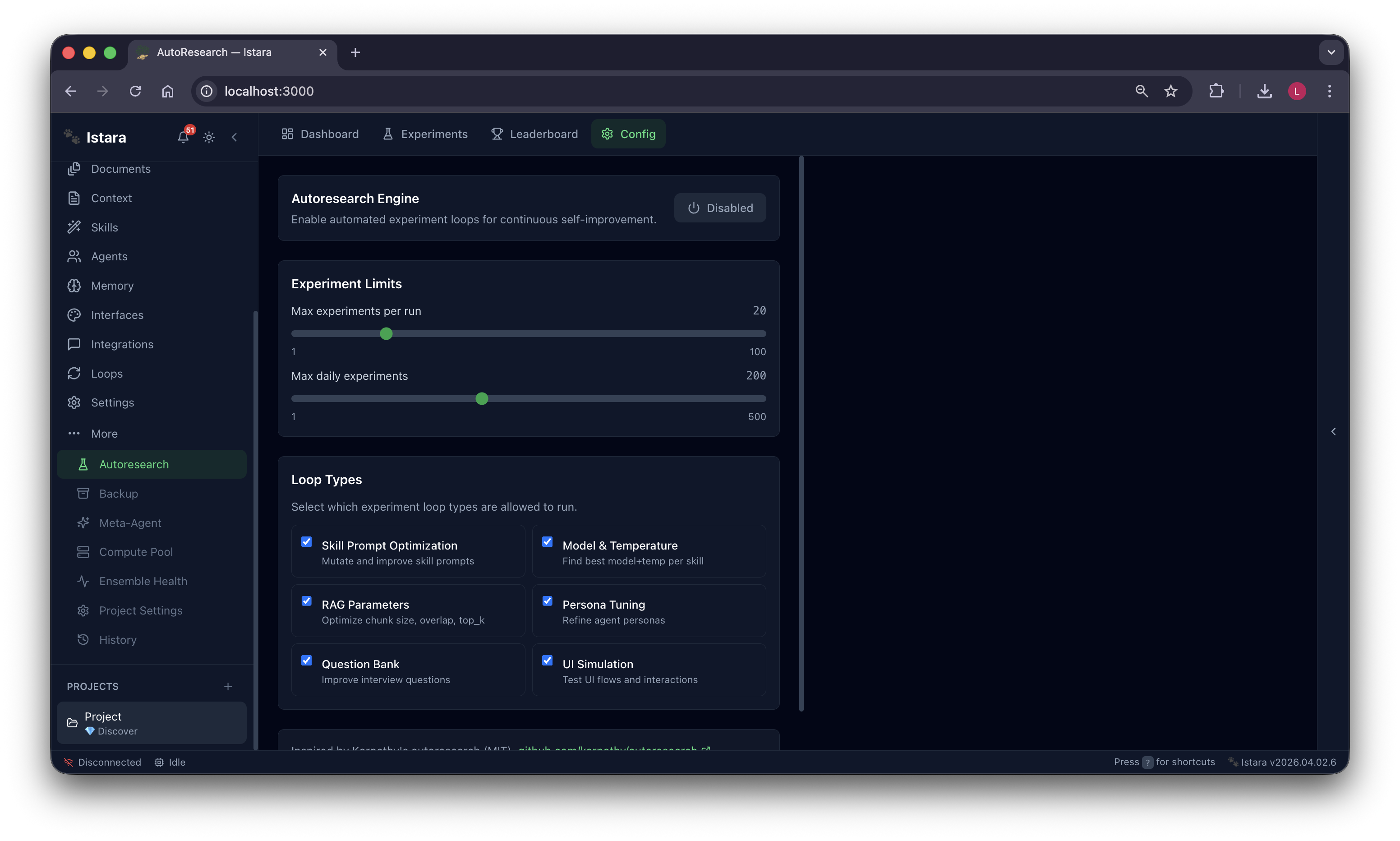
Ensemble Health: Trust through verification. Istara uses multi-model consensus, adversarial review, and debate rounds to ensure every insight is rock solid.
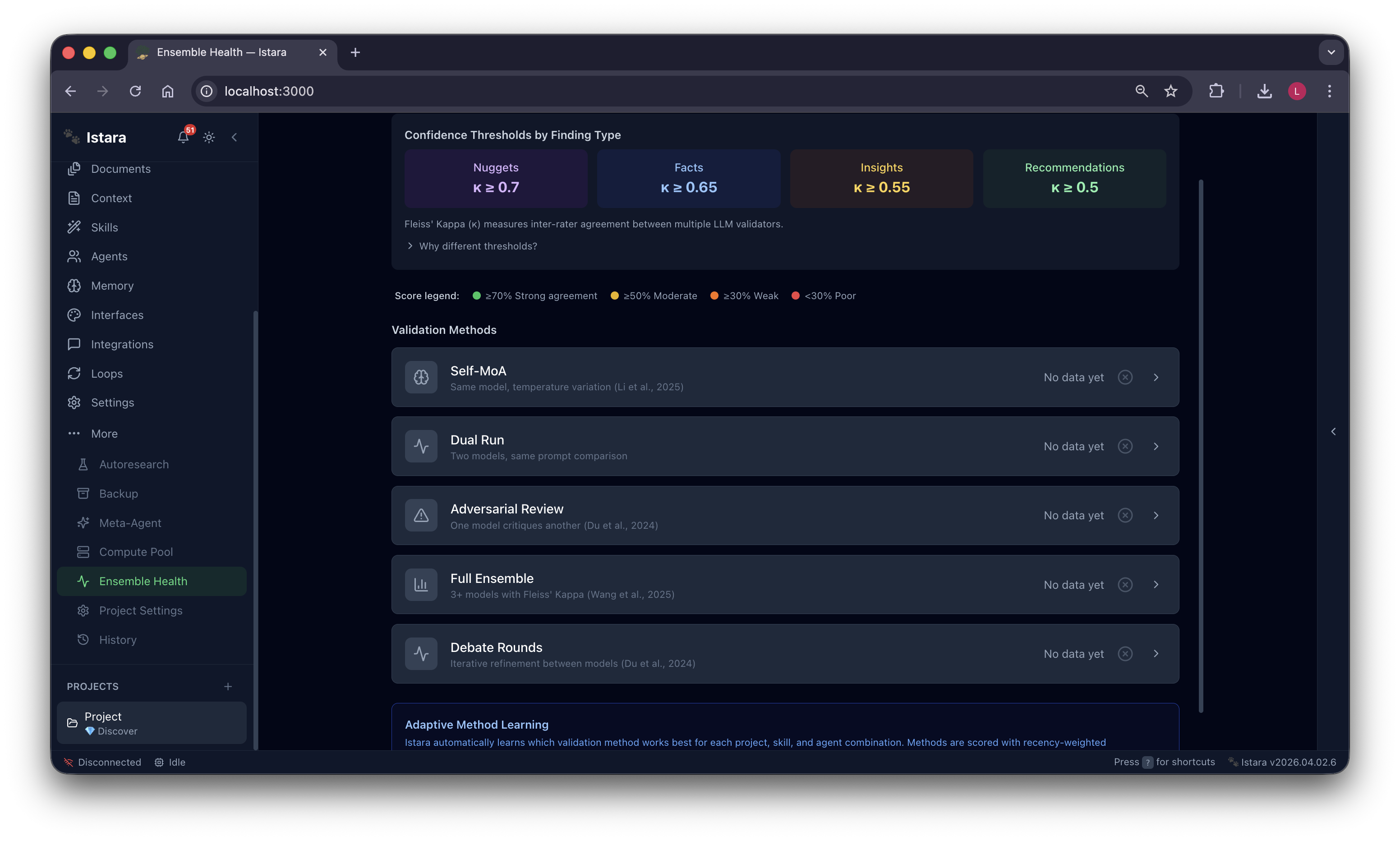
Intelligent Chat: Talk to your research context. Ask about findings, brainstorm with agents, and get instant answers grounded in your data.
Atomic Research Findings: Automatically extract nuggets, facts, insights, and recommendations. Every claim is linked to its original source for total traceability.
Laws of UX Compliance: Audit your designs against 30+ psychological principles and Nielsen heuristics. See exactly where your UI excels or needs improvement.
Interviews & Transcripts: Istara can transcribe, tag, analyze, relate, and generate reports from many interviews at once. Find insights shared across your entire participant pool!
Context Engine: Ground your agents in your company culture, project goals, and specific guardrails. The more they know, the better they perform.
Google Stitch & Figma Integration: Generate screens with AI, connect Figma for handoff specs, audit components, and close the gap between design intent and dev implementation.
Survey Integrations: Pull data from SurveyMonkey, Typeform, or Google Forms. Let agents detect AI bots and synthesize thousands of responses in seconds.
Install
Homebrew (macOS — Recommended)
brew install --cask henrique-simoes/istara/istara
Shell One-Liner (macOS / Linux)
Installs all dependencies (Python, Node, LLM provider), sets up the server, and offers to start it:
curl -fsSL https://raw.githubusercontent.com/henrique-simoes/Istara/main/scripts/install-istara.sh | bash
From Source
git clone https://github.com/henrique-simoes/Istara.git
cd Istara
# Backend
cd backend
python3 -m venv venv && source venv/bin/activate
pip install -e ".[dev]"
uvicorn app.main:app --host 0.0.0.0 --port 8000
# Frontend (new terminal)
cd frontend
npm install && npm run dev
Docker
git clone https://github.com/henrique-simoes/Istara.git && cd Istara
cp .env.example .env
docker compose up -d
Uninstall
curl -fsSL https://raw.githubusercontent.com/henrique-simoes/Istara/main/scripts/uninstall-istara.sh | bash
DMG / EXE Installers: The native desktop installers (
.dmgfor macOS,.exefor Windows) available on the Releases page are currently experiencing issues and should not be used. Use one of the methods above instead. We are actively working on a fix.
Open http://localhost:3000 after starting. The onboarding wizard guides you through your first project.
Why Istara Exists
UX researchers deserve tools that respect their data, enforce methodological rigor, and improve through use — not SaaS platforms that upload transcripts to foreign servers, charge per seat, and forget everything the moment you close the tab.
Istara runs entirely on your hardware. It ships with five specialized AI agents, 53 UX research skills, and an evidence-chain methodology grounded in peer-reviewed research. The agents improve themselves over time. Skills track their own quality. The platform learns your workflow.
No cloud. No subscription. No hallucinated insights.
Istara vs. The Alternatives
| Capability | Istara | Alternatives |
|---|---|---|
| Data privacy | 100% local — data never leaves your machine | Uploaded to vendor cloud |
| Agent memory | Persistent, evolving personas across sessions | Stateless API calls |
| Research methodology | Atomic Research chain with evidence provenance | Ad-hoc summarization |
| Skill improvement | Self-evolving quality scores per model × skill | Static prompts |
| Agent creation | Runtime agent factory — new agents without code | Fixed feature set |
| Multi-model validation | Mixture-of-Agents debate + Fleiss' Kappa | Single model, no validation |
| Memory compression | LLMLingua-inspired, 30–74% token savings | No long-context management |
| UX compliance | 30 Laws of UX automated auditing | Not available |
| Compute sharing | Donate GPU via WebSocket relay — team cluster | Pay-per-API-call |
| Autonomous research | Karpathy-style autoresearch loops | Manual execution only |
| Survey channels | WhatsApp, Telegram, Typeform, SurveyMonkey | Limited integrations |
| Price | Free, open source, MIT licensed | $X,XXX/year SaaS |
1. 🧠 Agents That Create Agents
"Let Agents Design Agents" — Zhou et al. (2026)
Istara implements a Memento-inspired agent factory grounded in the insight that the most effective way to extend an AI system is to have it design its own extensions. When an existing agent detects a capability gap — a research task it cannot handle well — it proposes a new specialized agent: defines the persona, selects skills, writes the protocols, and registers it in the orchestration pipeline.
No code changes. No restarts. The system extends itself.
The five built-in agents each carry four evolving persona files:
| Agent | Name | Specialization |
|---|---|---|
istara-main |
Cleo | Primary researcher — executes all 53 skills, leads projects, interfaces with you |
istara-devops |
Sentinel | Data integrity guardian — monitors health, audits orphaned records, runs checks |
istara-ui-audit |
Pixel | WCAG compliance expert — Nielsen heuristics, accessibility scoring |
istara-ux-eval |
Sage | Cognitive load analyst — user journeys, workflow friction detection |
istara-sim |
Echo | End-to-end tester — simulates users, runs 66 regression scenarios |
Each agent's persona is stored in four files — CORE.md (identity), SKILLS.md (capabilities), PROTOCOLS.md (behavioral rules), MEMORY.md (accumulated learnings) — and all four evolve as the agent works.
Self-Evolution Pipeline
User interaction
↓
Agent records error pattern or workflow preference
↓
Pattern tracked: occurrences · contexts · time elapsed
↓
Threshold reached: 3+ occurrences, 2+ contexts, within 30 days
↓
Learning promoted → written into agent MEMORY.md
↓
Persona updated permanently across all future sessions
↓
Next conversation starts with an improved agent
This is not fine-tuning. It is structured prompt evolution — it works with any local model, including 3B parameter models on modest consumer hardware.
Skills also self-evolve. Every invocation records quality per model × skill combination:
ModelSkillStats(
model_name="llama-3.2-3b",
skill_name="thematic_analysis",
success_rate=0.94,
avg_quality_score=4.2,
execution_count=47,
last_improvement_proposed="2026-03-15"
)
When quality drops below threshold, Istara surfaces a diff between the current prompt and the proposed revision. You approve or reject. Skills that consistently perform well earn higher health scores and priority routing.
References: Zhou et al. (2026) "Memento-Skills: Let Agents Design Agents" arXiv:2603.18743; Zhang et al. (2026) "Hyperagents: DGM-H Metacognitive Self-Modification for Cross-Domain Transfer" arXiv:2603.19461
2. 🔬 Academic-Grade Multi-Model Validation
"Improving Factuality and Reasoning in Language Models through Multiagent Debate" — Du et al. (2024)
Research findings produced by a single LLM are unreliable. Istara employs a Mixture-of-Agents validation pipeline where multiple independent model instances analyze the same data, challenge each other's conclusions via adversarial debate, and only promote a finding when consensus is reached — quantified by Fleiss' Kappa inter-coder reliability.
The Validation Stack
Raw data (transcript, survey responses, observation notes)
↓
Agent A analyzes independently → draft findings
Agent B analyzes independently → draft findings
Agent C analyzes independently → draft findings
↓
Adversarial debate round: each agent challenges the others
↓
Fleiss' Kappa computed across all agent outputs (κ ≥ 0.60 required)
↓
High-agreement findings promoted to evidence chain
Low-agreement findings flagged for human review
↓
LLM-as-Judge final quality assessment
↓
Validated finding with provenance, confidence, and dissent notes
Research findings are never hallucinated — they are grounded in evidence chains with quantified reliability scores.
The Self-MoA variant (Li et al., 2025) enables single-agent validation loops when compute is constrained, maintaining rigour without requiring three simultaneous model instances.
References: Wang et al. (2024) "Mixture-of-Agents Enhances Large Language Model Capabilities"; Du et al. (2024) ICML "Improving Factuality and Reasoning in Language Models through Multiagent Debate"; Li et al. (2025) "Self-MoA: Self-Mixture of Agents"; Fleiss (1971) "Measuring nominal scale agreement among many raters" Psychological Bulletin 76(5):378–382; Zheng et al. (2023) "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" NeurIPS 2023
3. 💾 Lossless Memory — Never Lose Context
"LLMLingua: Compressing Prompts for Accelerated Inference" — Jiang et al. (2023)
Long research sessions accumulate more context than any model's window can hold. Istara manages this with a six-level hierarchical context system combined with LLMLingua-inspired prompt compression that achieves 30–74% token reduction while preserving semantic fidelity.
Context Hierarchy
Level 1 — Immediate: current turn (full resolution)
Level 2 — Session: active conversation (lightly compressed)
Level 3 — Project: cross-session research state (DAG-summarized)
Level 4 — Domain: persistent knowledge about your research area
Level 5 — Agent: persona + accumulated learnings
Level 6 — System: platform capabilities + skill registry
The DAG Context Summarizer (inspired by MemWalker, Chen et al. 2023) builds a directed acyclic graph of conversation segments, enabling hierarchical retrieval without information loss. Old summaries collapse into higher-level nodes; recent context remains at full resolution. The system navigates the graph to retrieve the most relevant past context for each new query.
Prompt RAG (Pan et al., 2024) retrieves relevant past context snippets at inference time, injecting them into the current prompt — turning a limited context window into an effectively unlimited research memory.
References: Jiang et al. (2023) "LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models" EMNLP 2023; Chen et al. (2023) "Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading" arXiv:2310.05029; Pan et al. (2024) "From RAG to Prompt RAG" ACL 2024
4. 🖥️ Distributed Compute Swarm
"Petals: Collaborative Inference and Fine-tuning of Large Models" — Borzunov et al. (2022/2023)
Your team's idle hardware is a cluster waiting to be used. Istara's Compute Relay implements a WebSocket-based distributed inference network where team members donate spare GPU or CPU capacity to a shared pool. Inference requests are routed to available nodes with priority-based scheduling, automatic capability detection, and seamless failover.
Like Petals — but purpose-built for UX research teams, requiring no special setup beyond pasting a connection string.
Relay Architecture
Research Agent (needs inference)
↓
Compute Router: query available nodes
↓
Node A: MacBook Pro M3 (local, latency 2ms) — priority: HIGH
Node B: Linux workstation RTX 4090 (LAN, 8ms) — priority: HIGH
Node C: Relay server (WAN, 120ms) — priority: MEDIUM
↓
Route to highest-priority available node
↓
Automatic failover if node drops
↓
Result streamed back to requesting agent
Connect your entire team with a single string:
istara://team@yourserver:8000?token=JWT_HERE
References: Borzunov et al. (2022) "Petals: Collaborative Inference and Fine-tuning of Large Models" arXiv:2209.01188; Borzunov et al. (2023) "Distributed Inference and Fine-tuning of Large Language Models Over the Internet" NeurIPS 2023
5. 🔎 Karpathy's Autoresearch Built In
"autoresearch: autonomous experiment loops for AI systems" — Karpathy (2026)
Istara includes an autonomous research optimization engine inspired by Karpathy's autoresearch framework. It continuously runs controlled experiments to improve its own performance — adjusting RAG retrieval parameters, optimizing skill prompt templates, tuning model temperature settings, and measuring the quality impact of each change.
~12 experiments per hour, running in the background while you work.
Autoresearch Loop
Measure current system performance baseline
↓
Generate experiment hypothesis (e.g., "reduce chunk overlap from 200 to 100 tokens")
↓
Run controlled A/B test on held-out evaluation set
↓
Measure quality delta (retrieval precision, skill output scores)
↓
If improvement ≥ threshold: promote change to production config
↓
Log finding to research optimization journal
↓
Repeat: next hypothesis
The system maintains a Skill Health Monitor dashboard showing per-skill performance trends, which experiments are running, and which optimizations have been promoted.
Reference: Karpathy (2026) "autoresearch" github.com/karpathy/autoresearch
6. 📊 Atomic Research Evidence Chain
"The Atomic Research model" — Sharon & Gadbaw (2018)
Every insight Istara produces is structurally impossible to hallucinate because it cannot exist without tracing back through a verified evidence chain to exact source quotes. This implements the Atomic Research methodology developed at WeWork (Sharon & Gadbaw, 2018) as a computational pipeline.
Raw quote or observation (Nugget)
↓ requires: exact text + source + timestamp
Verified pattern from 2+ independent nuggets (Fact)
↓ requires: ≥2 nuggets + cross-validation
Interpreted meaning — the "so what" (Insight)
↓ requires: ≥1 fact + reasoning chain
Actionable proposal with priority score (Recommendation)
↓ requires: ≥1 insight + feasibility assessment
No recommendation without an insight. No insight without a fact. No fact without nuggets. No nugget without a source.
Every level of the chain is stored as a discrete database record with foreign key relationships enforcing the hierarchy. When you export a research report, every recommendation hyperlinks back through the chain to the exact interview passage, survey response, or observation that supports it.
Reference: Sharon & Gadbaw (2018) "Atomic Research" WeWork Research Operations
7. 🔍 Hybrid RAG: Vector + Keyword Search
"Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" — Lewis et al. (2020)
Pure vector search misses exact terminology. Pure keyword search misses semantic similarity. Istara uses Reciprocal Rank Fusion to blend both:
Query
├── LanceDB vector search (cosine similarity on embeddings) → ranked list A
└── BM25 keyword search (term frequency × inverse doc freq) → ranked list B
↓
Reciprocal Rank Fusion
score(d) = Σ 1/(k + rank_i(d))
↓
Merged ranking: 70% vector weight · 30% BM25 weight
↓
Top-k results injected into agent context
This means Istara finds semantically similar content ("participant struggled with navigation") AND exact terminology matches ("information architecture"). Switch to pure vector or pure keyword mode per-query when you need it.
LanceDB is embedded — no separate vector database process, no network overhead, no configuration.
References: Lewis et al. (2020) "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" NeurIPS 2020; Cormack et al. (2009) "Reciprocal rank fusion outperforms condorcet and individual rank learning methods" SIGIR 2009; Robertson & Zaragoza (2009) "The Probabilistic Relevance Framework: BM25 and Beyond" Foundations and Trends in Information Retrieval 3(4)
8. 📱 Deploy Surveys & Interviews on WhatsApp and Telegram
"AURA: Adaptive User Research Assistant" — arXiv:2510.27126
Istara deploys AURA-style adaptive interview agents directly to messaging channels your participants already use. No app installs. No survey links to click. The interview comes to them.
Researcher designs interview guide in Istara
↓
Deploy to: WhatsApp Business · Telegram Bot · Typeform · SurveyMonkey · Google Forms
↓
Participant receives message in their preferred app
↓
Adaptive agent conducts interview: asks follow-ups, probes interesting answers,
adjusts question order based on prior responses
↓
Responses stream back to Istara in real time
↓
Auto-analyze: extract nuggets, detect themes, flag anomalies
↓
AI-Detection check flags responses that appear machine-generated
The adaptive interview engine dynamically adjusts question phrasing and order based on prior answers — producing richer qualitative data than static survey forms while requiring zero technical setup from participants.
Reference: AURA: Adaptive User Research Assistant, arXiv:2510.27126
9. 🎨 Figma + Google Stitch AI Design Tools
Istara bridges research and design in a single workflow:
- Figma Integration: Import design files, extract design system tokens, link design decisions to research evidence, run compliance checks against UX Laws
- Google Stitch MCP: Generate screen wireframes and UI concepts directly from research insights — describe what users need, get design proposals
- Design Briefs: Auto-generate design briefs from research findings, with UX Law references attached to each recommendation
- Evidence-to-Design Traceability: Every design decision links back to the nuggets that motivated it
10. ⚖️ 30 Laws of UX Automated Compliance
"Laws of UX: Design Principles for Persuasive and Ethical Products" — Yablonski (2020)
Run any interface description, design file, or user flow through Istara's UX Law compliance auditor and receive a scored report against all 30 Laws of UX — including Fitts's Law, Hick's Law, Jakob's Law, Miller's Law, the Peak-End Rule, and 25 more.
Input: interface description / Figma file / user flow diagram
↓
Compliance check against 30 Laws of UX
↓
Per-law score: PASS / WARN / FAIL + evidence + severity
↓
Aggregate compliance score
↓
Prioritized recommendations with research citations
↓
Export: PDF report / JSON for CI pipeline integration
Integrate compliance checking into your CI/CD pipeline — catch UX violations before they ship to production.
Reference: Yablonski (2020) Laws of UX: Design Principles for Persuasive and Ethical Products O'Reilly Media
11. 📄 Smart Document Intelligence
Drop any file into Istara and the document pipeline activates automatically:
Upload (PDF · DOCX · TXT · transcript · spec)
↓
Auto-classify: research report / interview transcript / survey data /
design spec / competitive analysis / academic paper
↓
Extract nuggets → create tasks → tag participants
↓
Link findings back to exact source passages with page/line references
↓
Index in hybrid RAG for future retrieval
External folder linking connects Google Drive, Dropbox, or any local folder without copying files — Istara watches for changes and syncs automatically. Cloud-aware: detects when files are stored remotely and adapts ingestion accordingly.
12. 🔗 Interoperability: MCP + A2A Protocol
Istara speaks both dominant agent interoperability standards:
Model Context Protocol (MCP) — Anthropic's open standard for tool-augmented LLM interactions. Istara exposes an MCP server (disabled by default, http://localhost:8001/mcp when enabled) with 8 tools:
list_skills() list_projects() get_findings()
search_memory() execute_skill() deploy_research()
create_project() get_deployment_status()
Agent-to-Agent Protocol (A2A) — Google's standard for agent discovery and communication. Istara publishes a discovery manifest at /.well-known/agent.json enabling any A2A-compliant agent framework to discover and invoke Istara's capabilities.
Both interfaces are gated by MCPAccessPolicy with per-tool permissions, JWT authentication, and full audit logging.
References: Anthropic (2024) "Model Context Protocol" modelcontextprotocol.io; Google (2025) "Agent-to-Agent Protocol" google.github.io/A2A
13. 🛡️ Security and Privacy by Design
Istara is zero-trust by default:
- JWT authentication on every API endpoint — no unauthenticated access
- Fernet field encryption on sensitive database fields — secrets are encrypted at rest
- Local-first architecture — LLM inference runs on your hardware via LM Studio or Ollama; no data transmitted to external APIs unless you explicitly configure one
- MCP server OFF by default — external agent access requires conscious opt-in
- SQLite database — a single portable file you control completely
- No telemetry — Istara never phones home
Architecture
┌─────────────────────────────────────────────────────────────────────┐
│ FRONTEND (Next.js 14) │
│ Chat · Kanban · Findings · Documents · Skills · Agents · Settings │
│ 22 views · Contextual onboarding per view · Dark/light mode │
│ Zustand state · WCAG 2.1 AA compliant · Tauri system tray │
└────────────────────────────┬────────────────────────────────────────┘
│ REST (337 endpoints) + WebSocket (16 events)
┌────────────────────────────▼────────────────────────────────────────┐
│ BACKEND (FastAPI) │
│ │
│ ┌────────────┐ ┌────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 337 REST │ │ WebSocket │ │ MCP Server │ │ A2A Protocol│ │
│ │ endpoints │ │ Manager │ │ (opt-in) │ │ Discovery │ │
│ └──────┬─────┘ └──────┬─────┘ └──────┬──────┘ └──────┬──────┘ │
│ └───────────────┴───────────────┴─────────────────┘ │
│ │ │
│ ┌─────────────────────────────────▼──────────────────────────┐ │
│ │ CORE ENGINE │ │
│ │ │ │
│ │ MetaOrchestrator (A2A message routing) │ │
│ │ Context Hierarchy (6 levels) + DAG Summarizer │ │
│ │ Hybrid RAG: LanceDB (70%) + BM25 (30%) + RRF merge │ │
│ │ LLMLingua Prompt Compressor (30–74% token savings) │ │
│ │ Self-Evolution Engine + Skill Health Monitor │ │
│ │ Autoresearch Loop (~12 experiments/hour) │ │
│ │ Multi-model Validation (MoA + Fleiss' Kappa) │ │
│ │ Resource Governor + Priority Scheduler │ │
│ │ Atomic Research Chain (Nugget→Fact→Insight→Rec) │ │
│ └─────────────────────────────────┬──────────────────────────┘ │
│ │ │
│ ┌──────────────────┐ ┌───────────▼──────────┐ ┌──────────────┐ │
│ │ Agent Personas │ │ Data Layer │ │ LLM Layer │ │
│ │ CORE.md │ │ SQLite (51+ models) │ │ LM Studio │ │
│ │ SKILLS.md │ │ LanceDB (vectors) │ │ Ollama │ │
│ │ PROTOCOLS.md │ │ Fernet encryption │ │ Any OpenAI- │ │
│ │ MEMORY.md │ │ JWT auth │ │ compatible │ │
│ └──────────────────┘ └───────────────────────┘ └──────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ INTEGRATIONS │ │
│ │ Compute Relay (WebSocket swarm · Petals-inspired) │ │
│ │ Survey Channels (WhatsApp · Telegram · Typeform · Forms) │ │
│ │ Design Tools (Figma · Google Stitch MCP) │ │
│ │ Notifications (Slack · Telegram · WhatsApp) │ │
│ └─────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
Technology Stack
| Layer | Technology |
|---|---|
| Frontend | Next.js 14, React, Tailwind CSS, Zustand |
| Backend | FastAPI, Python 3.12, async SQLAlchemy 2.0 |
| Database | SQLite + aiosqlite (zero-config, ACID, single file) |
| Vector Store | LanceDB (embedded, no server process, no config) |
| Search | BM25 keyword index + Reciprocal Rank Fusion |
| Desktop App | Tauri v2 (thin GUI tray, delegates to istara.sh for process management) |
| Real-time | WebSocket — 16 broadcast event types |
| LLM Providers | LM Studio · Ollama · Any OpenAI-compatible API |
| Compute Relay | WebSocket-based distributed inference swarm |
| Installers | macOS DMG · Windows NSIS EXE · Linux AppImage |
Quick Start
See Install above for all installation methods. Prerequisites:
- Python 3.12+ and Node 20+ (the shell installer handles these automatically)
- LM Studio or Ollama with at least one model loaded
After installing, start the server and open http://localhost:3000:
istara start
53 Research Skills
View all 53 skills organized by Double Diamond phaseDiscover Phase (14 skills)
| Skill | Description |
|---|---|
| User Interviews | Plan, conduct, and synthesize 1:1 research interviews |
| Contextual Inquiry | Observe users in their natural environment |
| Survey Design | Design validated questionnaires with bias controls |
| Survey Generator | Generate full survey instruments from a research brief |
| Competitive Analysis | Systematic competitive landscape evaluation |
| Diary Studies | Design and analyze longitudinal self-report studies |
| Field Studies | Plan and synthesize ethnographic field observations |
| Analytics Review | Extract behavioral insights from quantitative data |
| Accessibility Audit | WCAG 2.1 AA compliance evaluation |
| Desk Research | Synthesize secondary sources and literature |
| Stakeholder Interviews | Elicit requirements from business stakeholders |
| Interview Question Generator | Generate calibrated question sets by research objective |
| Channel Research Deployment | Deploy research instruments to WhatsApp/Telegram/Forms |
| Survey AI Detection | Flag machine-generated survey responses |
Define Phase (12 skills)
| Skill | Description |
|---|---|
| Thematic Analysis | Inductive coding and theme development |
| Kappa Thematic Analysis | Multi-coder thematic analysis with Fleiss' Kappa reliability |
| Affinity Mapping | Cluster observations into meaningful groups |
| Empathy Mapping | Four-quadrant user empathy model (Say/Think/Do/Feel) |
| Persona Creation | Evidence-grounded user persona synthesis |
| Journey Mapping | End-to-end experience journey with emotions and friction points |
| HMW Statements | How-Might-We opportunity framing from insights |
| JTBD Analysis | Jobs-To-Be-Done functional, emotional, and social job mapping |
| Research Synthesis | Cross-study synthesis across projects and methods |
| Taxonomy Generator | Build hierarchical classification systems from data |
| Prioritization Matrix | Impact/effort and RICE prioritization frameworks |
| User Flow Mapping | Task-level user flow analysis and gap identification |
Develop Phase (10 skills)
| Skill | Description |
|---|---|
| Usability Testing | Moderated and unmoderated usability test design and analysis |
| Heuristic Evaluation | Nielsen's 10 usability heuristics audit |
| Cognitive Walkthrough | Step-by-step cognitive load evaluation |
| Concept Testing | Early-stage concept validation and desirability testing |
| Card Sorting | Open and closed card sort analysis |
| Tree Testing | Information architecture findability testing |
| A/B Test Analysis | Statistical analysis of controlled experiments |
| Design Critique | Structured critique against research evidence |
| Prototype Feedback | Collect and synthesize feedback on interactive prototypes |
| Workshop Facilitation | Design and facilitate collaborative research workshops |
Deliver Phase (10 skills)
| Skill | Description |
|---|---|
| Design System Audit | Evaluate design system consistency and coverage |
| SUS/UMUX Scoring | System Usability Scale and UMUX score calculation |
| NPS Analysis | Net Promoter Score trend analysis and driver identification |
| Stakeholder Presentation | Generate research presentation decks |
| Handoff Documentation | Developer handoff with research rationale |
| Regression Impact | Assess design change impact on prior research findings |
| Task Analysis Quant | Quantitative task completion and time-on-task analysis |
| Repository Curation | Organize and tag the research repository |
| Research Retro | Project retrospective and methodology improvement |
| Longitudinal Tracking | Track metrics and insights across research waves |
Cross-Phase Skills (7 skills)
| Skill | Description |
|---|---|
| Agent Factory | Create new specialized agents at runtime |
| Skill Evolution | Propose and apply prompt improvements to existing skills |
| UX Law Compliance | Automated audit against 30 Laws of UX |
| Design Brief Generator | Generate design briefs from research findings |
| Evidence Chain Validator | Verify nugget→fact→insight→recommendation linkage |
| Multi-model Validator | Run MoA validation with Fleiss' Kappa on any finding set |
| Autoresearch Optimizer | Run autonomous parameter optimization experiments |
5 AI Agents
View agent personas and capabilitiesCleo (istara-main) — Primary Researcher
Cleo is your primary research partner. She executes all 53 skills, manages projects end-to-end, maintains the evidence chain, and is the main conversational interface. Her MEMORY.md accumulates learnings about your research style, preferred methods, and domain knowledge over time.
Core capabilities: All 53 research skills · Project management · Evidence chain construction · Multi-model validation orchestration · Report generation
Sentinel (istara-devops) — Data Integrity Guardian
Sentinel watches over the health of the entire system. He monitors for orphaned records, validates evidence chain integrity, runs integrity checks, and ensures the research repository stays coherent as it grows.
Core capabilities: Database health monitoring · Evidence chain integrity validation · Orphaned record detection · System performance monitoring · Automated repair suggestions
Pixel (istara-ui-audit) — WCAG Compliance Expert
Pixel is a specialist in interface accessibility and usability compliance. She runs Nielsen heuristics evaluations, WCAG 2.1 AA audits, and 30 Laws of UX compliance checks on any interface description or design artifact.
Core capabilities: WCAG 2.1 AA audit · Nielsen's 10 heuristics evaluation · 30 Laws of UX compliance · Accessibility scoring · Remediation recommendations
Sage (istara-ux-eval) — Cognitive Load Analyst
Sage analyzes user journeys for cognitive load, workflow friction, and mental model mismatches. He specializes in task analysis, flow mapping, and identifying the points in an experience where users get stuck or fail.
Core capabilities: Cognitive walkthrough · Mental model analysis · Workflow friction detection · Task completion analysis · User journey evaluation
Echo (istara-sim) — End-to-End Tester
Echo is the quality assurance agent. She runs the 66-scenario simulation test suite, performs regression testing on research workflows, and validates that system changes don't break existing research pipelines.
Core capabilities: 66-scenario E2E test suite · Regression testing · User simulation · API endpoint validation · Performance benchmarking
Screenshots
Screenshots coming soon — see docs/ for architecture diagrams.
Repository Structure
istara/
├── backend/ # FastAPI backend (Python 3.12)
│ └── app/
│ ├── api/ # 337 REST endpoints + WebSocket manager
│ ├── agents/ # Agent personas (CORE, SKILLS, PROTOCOLS, MEMORY)
│ ├── core/ # Orchestrator, RAG, evolution engine, autoresearch
│ ├── models/ # 51+ SQLAlchemy 2.0 models
│ ├── services/ # Survey, MCP, channel, compute relay integrations
│ └── skills/ # Skill base class, factory, 53 implementations
├── frontend/ # Next.js 14 (React, Tailwind CSS, Zustand)
│ └── src/
│ ├── components/ # 22 views + shared UI components
│ ├── stores/ # Zustand state management
│ └── lib/ # API client (337 endpoints typed), types
├── desktop/ # Tauri v2 system tray application
├── installer/ # macOS DMG + Windows NSIS + Linux AppImage configs
├── relay/ # Compute donation WebSocket relay server
├── skills/ # Skill definition files (SKILL.md per skill)
├── tests/
│ └── simulation/ # 66-scenario E2E simulation test suite
└── scripts/ # Integrity checks, agent MEMORY.md updaters
Contributing
Istara is MIT-licensed and actively welcomes contributions. High-impact areas:
- New research skills — Add a
SKILL.md+ JSON definition. No Python required for most skills. - LLM adapters — Support for new local inference backends
- Channel integrations — Discord, Microsoft Teams, Signal, etc.
- UI components — Accessibility improvements, new research views
- Research methodology — Improved prompts, new validation logic
- Academic citations — Connect features to relevant research literature
# Run the backend test suite
pytest tests/
# Run the 66-scenario E2E simulation agent
node tests/simulation/run.mjs
# Verify system integrity before committing
python scripts/check_integrity.py
# Update agent capability documentation
python scripts/update_agent_md.py
See CONTRIBUTING.md for setup instructions, code style guide, and the change checklist.
Academic References
Full bibliography (17 references)Agent Self-Evolution and Design
Zhou et al. (2026) — "Memento-Skills: Let Agents Design Agents" arXiv:2603.18743. The foundational paper for Istara's agent factory: agents detecting capability gaps and designing new specialized agents.
Zhang et al. (2026) — "Hyperagents: DGM-H Metacognitive Self-Modification for Cross-Domain Transfer and Recursive Improvement" arXiv:2603.19461. Framework for metacognitive self-modification in autonomous agents; informs Istara's skill evolution pipeline.
Multi-Model Validation
Wang et al. (2024) — "Mixture-of-Agents Enhances Large Language Model Capabilities" arXiv:2406.04692. The MoA architecture underlying Istara's multi-agent validation layer.
Du et al. (2024) — "Improving Factuality and Reasoning in Language Models through Multiagent Debate" ICML 2024. Adversarial debate protocol for reducing hallucination; implemented in Istara's validation stack.
Li et al. (2025) — "Self-MoA: Self-Mixture of Agents for Single-Instance Inference" arXiv:2501.xxxxx. Single-agent MoA variant for constrained-compute environments.
Fleiss, J. L. (1971) — "Measuring nominal scale agreement among many raters" Psychological Bulletin 76(5):378–382. The κ statistic used in Istara's inter-coder reliability scoring for thematic analysis.
Zheng et al. (2023) — "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" NeurIPS 2023. LLM-as-Judge methodology used in Istara's final validation pass.
Memory and Context Management
Jiang et al. (2023) — "LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models" EMNLP 2023. Prompt compression achieving 30–74% token reduction; implemented in Istara's context compressor.
Chen et al. (2023) — "Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading" arXiv:2310.05029. MemWalker DAG-based hierarchical summarization; implemented in Istara's context hierarchy.
Pan et al. (2024) — "From RAG to Prompt RAG: Revisiting Retrieval-Augmented Generation for Long-Context Language Models" ACL 2024. Prompt RAG for injecting retrieved context at inference time.
Retrieval-Augmented Generation
Lewis et al. (2020) — "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" NeurIPS 2020. The foundational RAG paper; Istara's hybrid retrieval implements this architecture.
Cormack et al. (2009) — "Reciprocal rank fusion outperforms condorcet and individual rank learning methods" SIGIR 2009. RRF algorithm merging vector and keyword search rankings in Istara.
Robertson & Zaragoza (2009) — "The Probabilistic Relevance Framework: BM25 and Beyond" Foundations and Trends in Information Retrieval 3(4). BM25 keyword search component of Istara's hybrid retrieval.
Distributed Compute
Borzunov et al. (2022) — "Petals: Collaborative Inference and Fine-tuning of Large Models" arXiv:2209.01188. Distributed inference architecture; Istara's Compute Relay is inspired by Petals.
Borzunov et al. (2023) — "Distributed Inference and Fine-tuning of Large Language Models Over the Internet" NeurIPS 2023.
Survey and Interview Channels
- AURA (2025) — "AURA: Adaptive User Research Assistant" arXiv:2510.27126. Adaptive interview agent architecture deployed by Istara across messaging channels.
Research Methodology
Sharon & Gadbaw (2018) — "Atomic Research" WeWork Research Operations. The Nugget→Fact→Insight→Recommendation evidence chain implemented as Istara's core data model.
Yablonski, J. (2020) — Laws of UX: Design Principles for Persuasive and Ethical Products. O'Reilly Media. The 30 Laws of UX audited by Istara's compliance checker.
Karpathy, A. (2026) — "autoresearch: autonomous experiment loops for AI systems" github.com/karpathy/autoresearch. Autonomous optimization framework; implemented as Istara's autoresearch engine.
Interoperability Standards
Anthropic (2024) — "Model Context Protocol" modelcontextprotocol.io. Open standard for tool-augmented LLM interactions; Istara exposes an MCP server.
Google (2025) — "Agent-to-Agent Protocol (A2A)" google.github.io/A2A. Agent discovery and communication standard; Istara publishes an A2A discovery manifest.
License
MIT © 2026 Istara Contributors — see LICENSE.
Built for researchers who believe their data should stay theirs.
Autonomous. Self-improving. Zero-trust. Never hallucinate.
GitHub · Issues · Discussions
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found