claude-playbook-plugin
Health Uyari
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 10 GitHub stars
Code Gecti
- Code scan — Scanned 11 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
This tool is a Claude Code plugin that provides a structured methodology for managing AI-driven software development. It organizes work into persistent task documents that execute, self-inspect, and survive across multiple agent sessions.
Security Assessment
The automated code scan of 11 files found no dangerous patterns, no hardcoded secrets, and no requirement for risky permissions. The core design relies entirely on reading and writing local `.md` files (like task logs and mind maps) rather than storing state in active memory. This execution model is inherently safe. While the system relies on an AI agent to execute tasks—which could involve running shell commands or accessing local files depending on the specific instructions you give it—the plugin itself acts simply as a structured record-keeper. Overall risk is rated as Low.
Quality Assessment
The project is highly active, with its most recent push occurring just today. It has accumulated a modest but positive community trust signal with 10 GitHub stars. The main downside is the lack of a formal license file. Without a defined license, the code is technically under exclusive copyright by default, which introduces legal ambiguity if you plan to use, modify, or distribute it in a commercial or open-source environment.
Verdict
Safe to use for private development, but exercise caution regarding the missing license if you plan to incorporate it into broader commercial or distributed projects.
Agent steering methodology as a Claude Code plugin — task documents that execute, self-inspect, and pass between agents
Claude Playbook
A Claude Code plugin for building software you can trust. The agent remembers your project across sessions, works in small reviewed tasks, and tests as it builds.
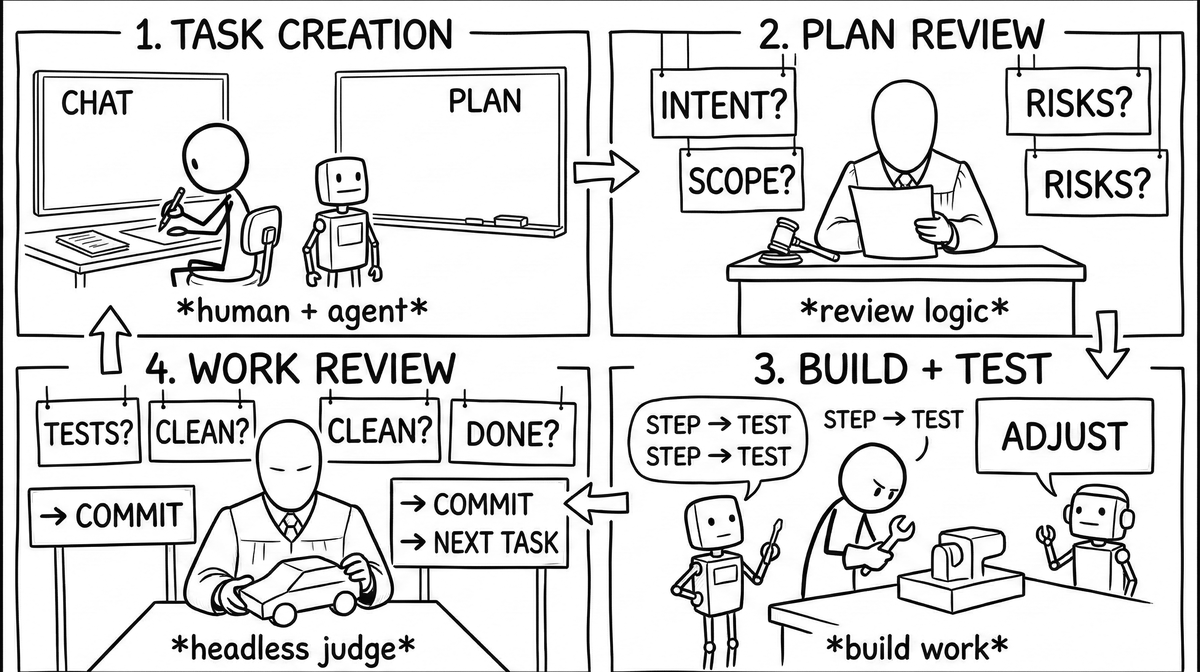
What it looks like
You: "Add rate limiting to the API endpoints"
Agent: creates task, writes a 12-gate plan
Judge: reviews the plan blind (no conversation access - no anchoring)
Agent: works gate by gate, checking boxes, annotating findings
You: (20 minutes later) read the task.md, see exactly what happened and why
task.md - plan and runtime
Work happens in task.md files. The agent works through gates top to bottom, checking boxes and annotating as it goes. You can run a judge on the plan before any code is written - blind, no conversation access. A fresh session picks up the same file and continues from wherever the last one stopped.
Each operation leaves a mark - a judge verdict, a checked gate with a note, a flagged wrong turn. When the task is done, it's the record of what happened and why.
The plan changes as work progresses. The agent edits gates as it learns - steps get added or removed as reality demands. A reflection gate mid-task asks "am I solving the stated problem or a different one?" and the remaining plan gets revised from the answer. You steer by chatting at any point - "wrong approach," "focus on X."
Claude, Cursor, and others will generate a checkboxable plan when you ask. But it's static - it doesn't edit itself as reality changes, it doesn't record what happened, and it disappears when the session ends. task.md grows.
Because state lives in the file and not in memory, execution survives context compaction. Tasks that run to 500+ steps work reliably - useful when you need to apply a templated analysis or transformation across a large collection of files.
What comes with it
The mind map (MIND_MAP.md) is the project's memory - persistent across tasks and sessions. It captures both directions: intent and goals from the top down, architecture and structure from the bottom up. A new agent reads it at session start and is oriented in seconds, not minutes. Session thirty picks up from session one without re-learning anything.
The judge reads the task plan before any code gets written. It sees the full codebase but not your conversation - no anchoring to whatever approach you already committed to in chat. On complex tasks, run a panel of several models; the hit rate on catching real problems goes up.
The chat log records every message you send. A gate in the design phase checks the task against it - pulling in things you said conversationally but never wrote down. If your messages and the task don't agree, that's a bug in the plan, not just a documentation gap.
Hooks enforce the structure at the system level. The agent can't edit code without an active task, can't skip gates, can't mark work done with gates still open. Warnings don't stick, so we block instead.
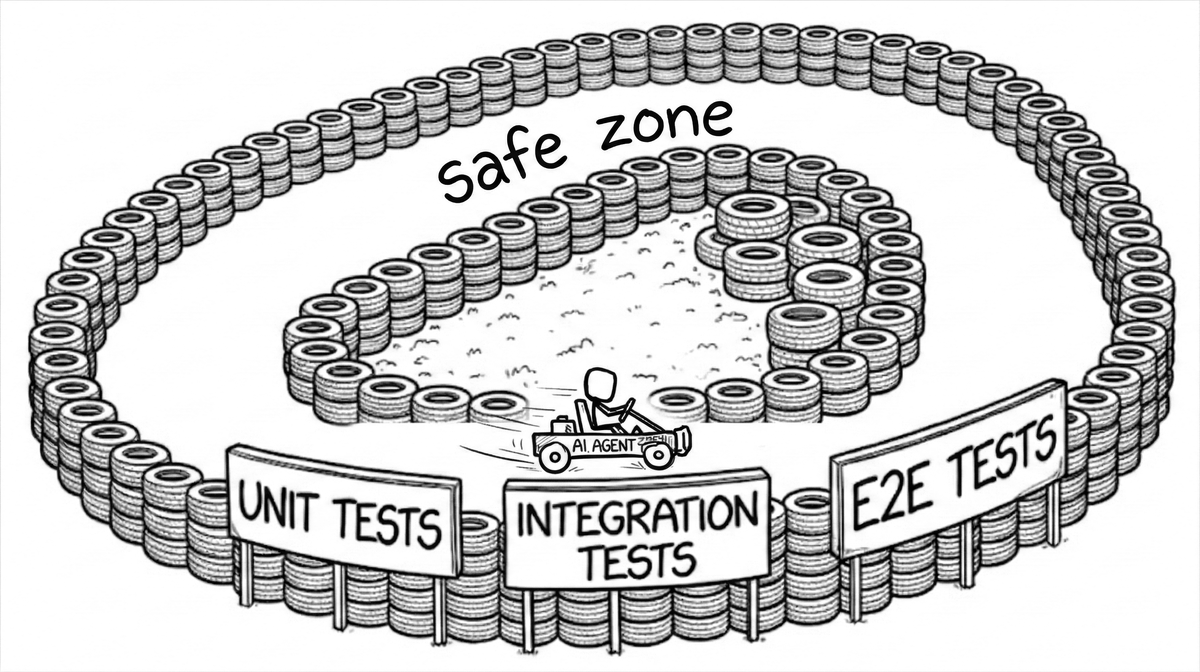
Tests make the consequences of a wrong change visible immediately - the agent sees the failure and corrects course. The better the tests, the longer it can run unsupervised. Playbook leans heavily on this: the task.md template puts a test gate after each work gate, and we recommend expanding test coverage as part of every task.
The sandbox lets you run the agent in full bypass-permissions mode - no prompts, no interruptions. The tradeoff is that blast radius is contained at the OS level: your project directory is writable, .git is read-only, and everything outside the project is blocked. You get the speed of unattended execution without the risk of it touching anything it shouldn't.
Install
claude plugin marketplace add horiacristescu/claude-playbook-plugin
Restart Claude Code, then in any project tell the agent /playbook:init. This creates CLAUDE.md, MIND_MAP.md, and .claude/bin/tasks - the task CLI.
Then run /playbook:mindmap to build the initial mind map. The agent spends time mapping your code, tests, and docs - while you explain the goals and constraints that aren't in the code. The result is an agent that knows the internal geometry of your project before it touches anything. This is necessary, not optional: the mind map is the agent's memory and its starting point for every session that follows.
If your test coverage is thin, do this before anything else: ask the agent to propose and write tests. Once you have both the mind map and a solid test suite, you have everything you need to run playbook safely on real work.
To upgrade later: /playbook:upgrade.
Usage
Tell the agent what you want. It creates a task, writes a plan, gets the plan reviewed, then works through the gates - you chat, the agent runs the commands.
You: "Add rate limiting to the API endpoints"
Agent: tasks new feature rate-limiting
Agent: tasks plan-review 12
Agent: tasks work 12
Agent: [works gate by gate]
Agent: tasks work done
For plan review before the agent touches any code, ask for it explicitly:
You: "review the plan before coding"
Agent: tasks plan-review 12 # single judge, blind
Agent: tasks panel-review 12 # 7-model panel, higher discovery rate
For hands-off execution, run in sandbox mode - --dangerously-skip-permissions inside OS-level write containment:
sandbox
The sandbox uses macOS seatbelt or Linux bubblewrap. Your project directory is writable, .git is read-only, everything outside is blocked at the kernel level. The agent runs without permission prompts but can't escape the containment even if it tries. You still steer by chatting.
Tell the agent what you want built, what constraints matter, and what done looks like. You can steer at any point by chatting - but as the mind map fills in, the agent learns the project's quirks and needs less of it. If you want to follow along, task.md is easier to watch than the chat feed - you see from above, gates checking one by one, outcomes piling up. When it finishes, every decision is recorded and every test result is there.
Two agents, one task
One setup that works well: the orchestrator runs outside the sandbox - writes plans, reviews results, commits. The sandbox agent runs in bypass mode - picks up the task.md and builds. The task.md is the handoff. Different agents across different sessions can pick up the same task and keep going from wherever it stopped.
The mind map in practice
[1] Project Overview - Claude Playbook packages an agent steering methodology as a distributable plugin [2]. The core insight: the solution to agent autonomy is text, not code [18]. Refined across 700+ tasks...
[5] Task System - Each task is a living document that IS the execution trace [19]. Design Phase → Work Plan → Pre-review. Task types: feature → Build, explore → Investigate, review → Evaluate...
[19] Document-Driven Execution - task.md is a computational model: checkboxes = state, sections = memory, templates = instruction set, agent = interpreter [5]...
Nodes cross-reference each other - [5] links to [19] which links back. What was decided, what failed, what got tried and why - it persists between sessions instead of being re-explained from scratch.
When not to use it
Not everything needs a task. Questions, shell commands, docs, git - just ask. The rule is simple: the moment the agent touches code files, declare a task first. The hooks enforce this.
Works on macOS, Linux, and Windows.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi