pluck
Health Pass
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 33 GitHub stars
Code Warn
- fs module — File system access in .github/workflows/ci.yml
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
MCP-native code retrieval for AI agents — 84-88% fewer read tokens, BM25F + semantic search, AST chunks, session dedup

The MCP-native Code Retrieval Engine for AI Agents
84-88 % fewer tokens on code reads · 71 % shorter CI logs · 0.07 ms warm search — every number gated by benchmarks/baseline.json

pluck is a local Rust daemon that replaces cat and grep as the default way AI agents read and search code. It exposes symbol-aware code reading and search to agents over the Model Context Protocol (MCP). Smart outlines cut eligible code-read tokens by 84-88 %, CI logs compress by 71 %, and warm search stays sub-millisecond — with a --raw fallback on every tool so the agent never loses capability by defaulting to pluck.
Without pluck: ls → grep → cat file1 → cat file2 → cat file3 → ...
With pluck: pluck.plan "fix auth-token expiry" → 3-5 next-call recommendations
pluck.search "auth flow" → ranked chunks, BM25 + semantic
pluck.peek validate_token → signature + callees only
pluck.symbol validate_token → just that function's body
pluck.impact validate_token → every caller, depth-capped
pluck.deps src/auth/login.ts → forward/reverse import graph
pluck.digest < cargo-build.log → 71 % shorter, errors intact
Quickstart
Pluck is designed to be the default retrieval tool for your AI coding agents.
1. Paste the Agent Setup Prompt
Install and configure pluck for this repo.
Install / register:
- If pluck is missing, install pluck-mcp and pluck-cli with Cargo or Homebrew.
- Register pluckd as an MCP server named `pluck` for this repository.
- Prefer project-scoped config when the agent supports it.
- Preserve existing MCP servers, rules, hooks, permissions, and comments.
To make pluck the first retrieval choice:
- Use the strongest official mechanism this agent supports.
- Claude Code: use project MCP config or
`claude mcp add --transport stdio --scope project pluck -- pluckd --repo <repo-root>`;
approve the `pluck` MCP server in settings/permissions when needed; add
durable instructions in `CLAUDE.md`; use PreToolUse hooks or permission
deny rules only when they can safely redirect repo-local cat/grep/rg/read
retrieval to mcp__pluck__* tools.
- Codex: use `codex mcp add pluck -- pluckd --repo <repo-root>` or
`~/.codex/config.toml` / trusted project `.codex/config.toml`; add the
pluck-first retrieval policy to `AGENTS.md`.
- Cursor: use project `.cursor/mcp.json`; add an always-applied Project Rule
in `.cursor/rules/` or an `AGENTS.md` instruction for the workspace.
Pluck-first retrieval policy:
- Use mcp__pluck__read before cat, head, tail, sed -n, or built-in file reads
for files inside the indexed repo.
- Use mcp__pluck__search for conceptual code lookup.
- Use mcp__pluck__grep before grep or rg for exact strings, regexes, TODOs,
and all textual matches inside the repo.
- Use mcp__pluck__peek, mcp__pluck__symbol, mcp__pluck__expand,
mcp__pluck__impact, and mcp__pluck__deps for symbol shape, bodies, call
chains, refactor impact, and import relationships.
- Use mcp__pluck__digest before pasting long cargo, npm, pytest, or GitHub
Actions logs into context.
- Fall back to Bash or built-in reads only for binary files, paths outside the
repo, byte-exact shell pipelines, unsupported formats, or when pluck is
unavailable.
Verify:
- Restart or reload the agent if MCP changes require it.
- Confirm the `pluck` MCP server is connected and mcp__pluck__* tools exist.
- Run one repo code-search/read task and confirm the agent calls mcp__pluck__*
before Bash, grep/rg, cat, or built-in file reads.
- Show the files changed and the verification result.
For an expanded version with safety checks and fallback instructions, use the
full agent install prompt.
2. Or set it up manually
# Daemon + standalone CLI from crates.io
cargo install pluck-mcp pluck-cli
# Or via Homebrew tap
brew tap hunhee98/pluck && brew install pluck
Claude Code
pluck init --target claude --mode aggressive # MCP + permissions + Bash retrieval block
(Alternatively, you can manually enable it via /plugin marketplace add hunhee98/pluck)
Codex
pluck init --target codex --mode strong # MCP + AGENTS.md pluck-first policy
Cursor
pluck init --target cursor --mode strong # MCP + always-apply Cursor rule
Why pluck?
When AI agents use standard cat and grep to explore a codebase, they waste massive amounts of context window tokens. Re-reading the same file chunk, scrolling past unrelated functions, and re-paying tokens for identical imports on every read adds up to thousands of wasted tokens per session.
pluck solves this by providing an agent-facing layer for code search. Its core principle: every retrieval call an agent makes should default to pluck. Bash is only the fallback when pluck legitimately can't help (e.g., binary files, paths outside the repo).
- Smart Outline (
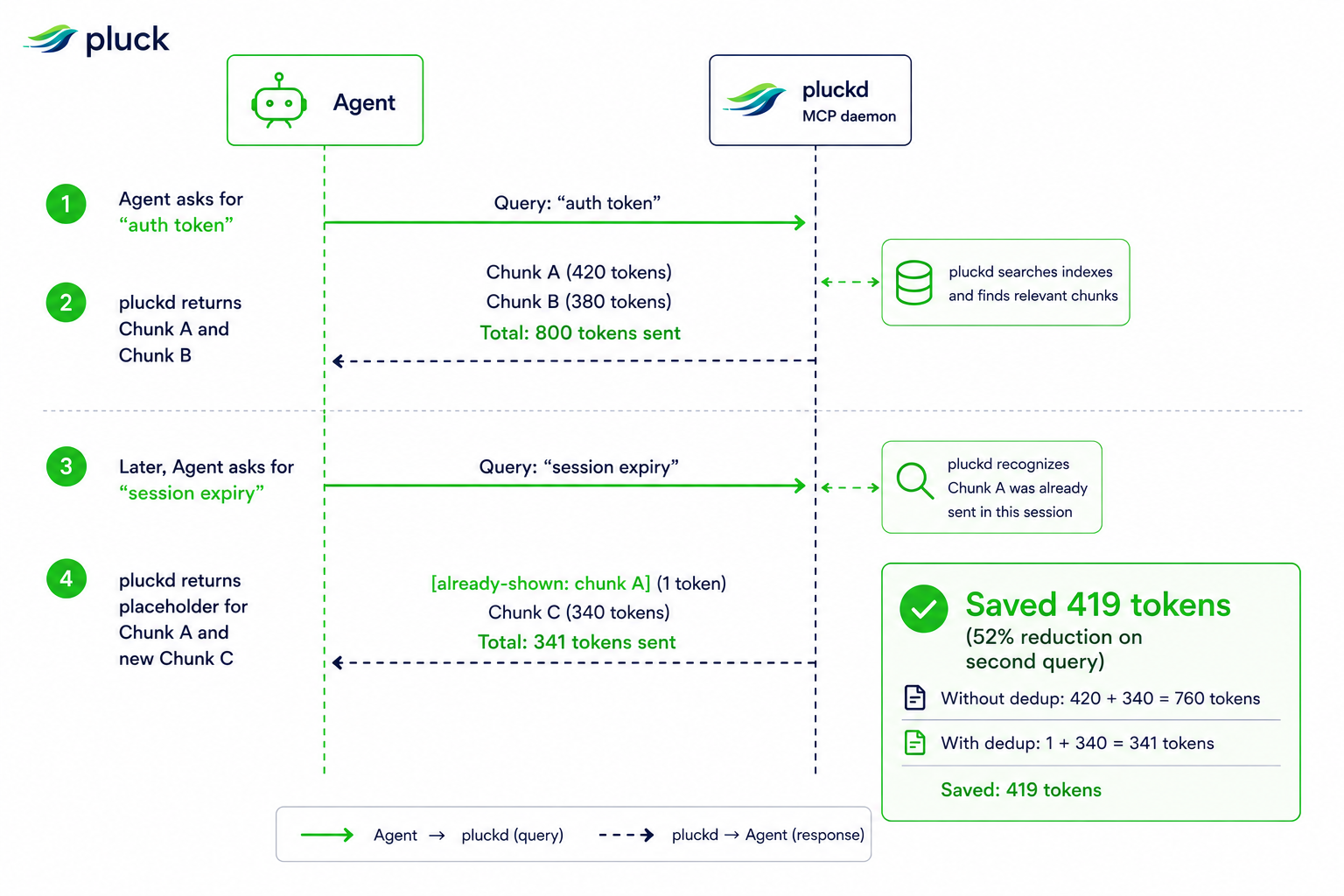
pluck.read): Instead of dumping a 1,000-line file, it returns a token-efficient outline of signatures with tiny helper bodies inline. The agent can then fetch only the larger function bodies it needs. - Session Dedup: If an agent searches for "auth" and later searches for "token", any overlapping code chunks are replaced with a 1-token placeholder (
[already-shown: ...]). The bytes are already in the agent's context; repeating them is pure waste. - Lossless Default: Stripping comments or dropping types hurts the agent's decision-making. pluck keeps the original bytes intact and makes lossy modes strictly opt-in.
- 100% Capability Guarantee: Every pluck tool has a
--rawfallback that behaves exactly likecatorgrepbyte-for-byte.
How it works
pluck chunks files at the Abstract Syntax Tree (AST) level using Tree-sitter. When an agent queries, pluck ranks these chunks using a hybrid of keyword matching (BM25F over symbol/signature/content) and semantic similarity (a static model2vec-style lookup, potion-code-16M, ~60 MB on disk — no transformer inference at runtime). Search expands natural-language BM25 queries with embedding-nearest terms from the indexed repo, then runs a two-stage cascade: BM25F first widens the candidate pool, embeddings rerank that pool, and a smaller semantic-rescue pass catches concept queries with weak lexical overlap. The RRF blend is picked continuously from the query embedding against natural-language and code centroids, so agents can search by concept ("payment flow") without losing precision on exact symbols.
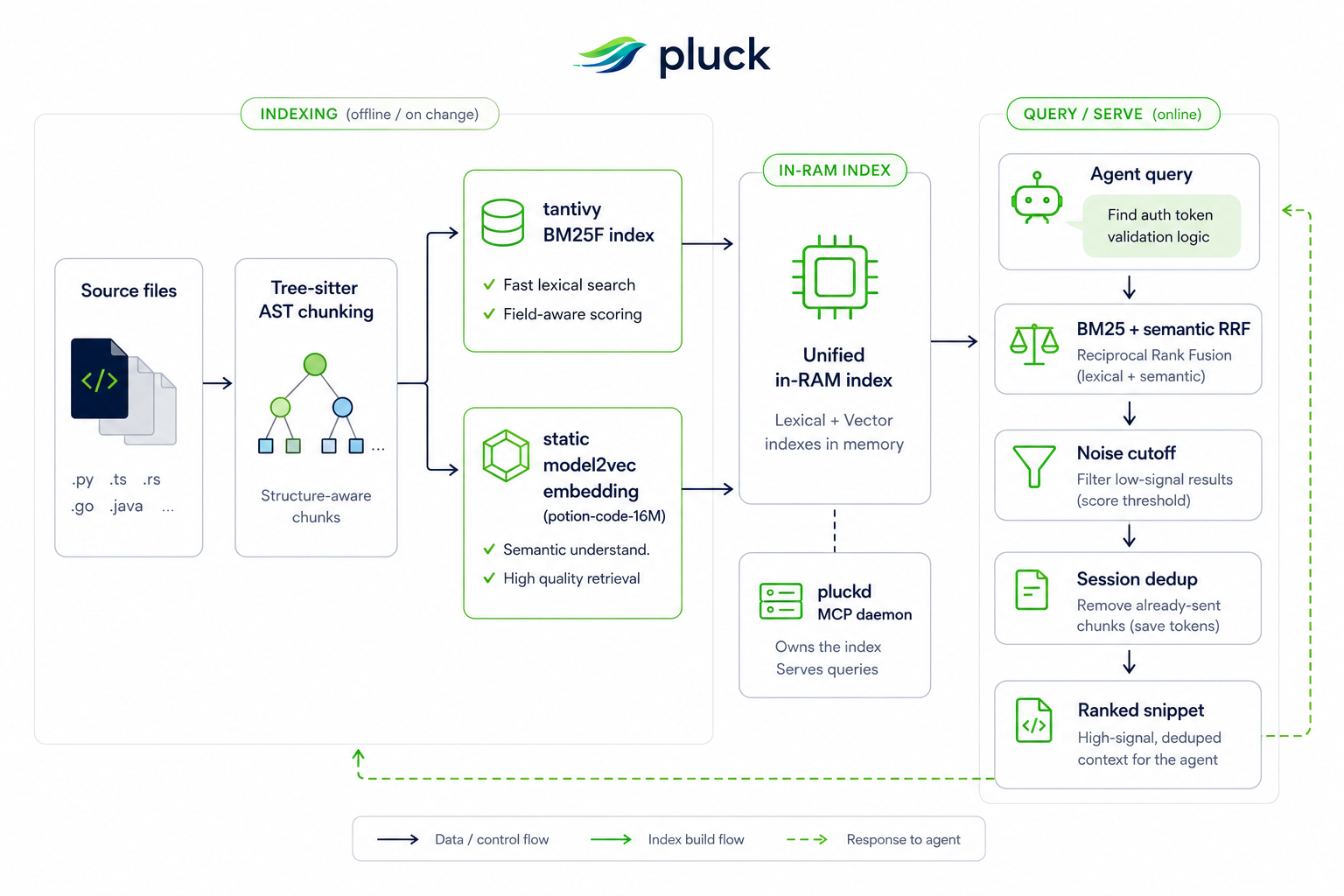
Session dedup in action
MCP Tools
Agents call specific tools depending on what they need. Bash is the fallback, not the default.
| Tool (wire name) | Replaces | Use when |
|---|---|---|
mcp__pluck__read |
cat |
Read a code file (smart outline by default; raw: true for byte-exact) |
mcp__pluck__grep |
grep / rg |
Keyword search (all ripgrep flags wrapped) |
mcp__pluck__search |
— | Ranked-chunk search (BM25 + semantic RRF) |
mcp__pluck__symbol |
cat + scroll |
Read just that function/class |
mcp__pluck__peek |
— | Signature + direct callees only |
mcp__pluck__expand |
many cats |
Symbol + callees up to N hops |
mcp__pluck__impact |
grep + read each caller | Reverse call graph — "who calls this symbol?" |
mcp__pluck__deps |
grep imports + read each file | File-level import graph — "what does this file depend on / who imports it?" |
mcp__pluck__digest |
piping cargo build/pytest/CI logs to cat |
Compress verbose tool output (errors / panics kept verbatim, progress lines collapsed) |
mcp__pluck__plan |
speculative search/read loop |
Given a free-form task, recommend the next 3-5 retrieval calls + confidence indicator |
Standalone CLI (no agent)
You can also use pluck directly in your terminal:
pluck index .
pluck search "auth flow" --repo .
pluck read src/auth/login.ts # smart outline
pluck read src/auth/login.ts --raw # byte-equivalent cat
Performance & Token Savings
Every number on this page cites a frozen baseline row or a measured scenario. No projected / aspirational percentages.
Gated engine metrics
These are the invariants in benchmarks/baseline.json. Every commit that touches engine-core runs scripts/regression-gate.py and the gate fails the build if any of them drift past tolerance.
| Metric | Value | Source row in baseline.json |
|---|---|---|
| Chunker p50 (medium repo, 500 lines) | 1.05 ms | chunker_medium_ms_p50 |
| Indexer throughput (medium, 500 files) | 2 747 files/s | indexer_files_per_sec_medium |
| Warm search p50 (medium) | 0.07 ms | warm_search_p50_ms_medium |
| File save → searchable p50 | 171 ms | freshness_p50_ms_medium |
| Session-dedup savings (5-query bench) | 23 % | session_dedup_session_savings_pct |
pluck.digest log compression (median of 6 fixtures) |
71 % | digest_savings_pct |
Eligible read-token savings
pluck.read outline mode is where pluck stops agents from paying the cat tax: instead of dumping every line, it returns the file's symbol map, inlines tiny helper bodies, and lets the agent fetch larger bodies on demand.
| Read workload | cat tokens |
pluck.read tokens |
Savings |
|---|---|---|---|
| medium realistic (5 fns, ~120 lines) | 929 | 116 | 88 % |
| large realistic (25 fns, ~600 lines) | 4 549 | 556 | 88 % |
| xl realistic (100 fns, ~2 400 lines) | 18 124 | 2 320 | 87 % |
| class (1 class + 50 methods) | 8 608 | 1 302 | 85 % |
Tiny files and raw reads are control cases: they are expected to show little or no savings because byte-exact fallback is the point.
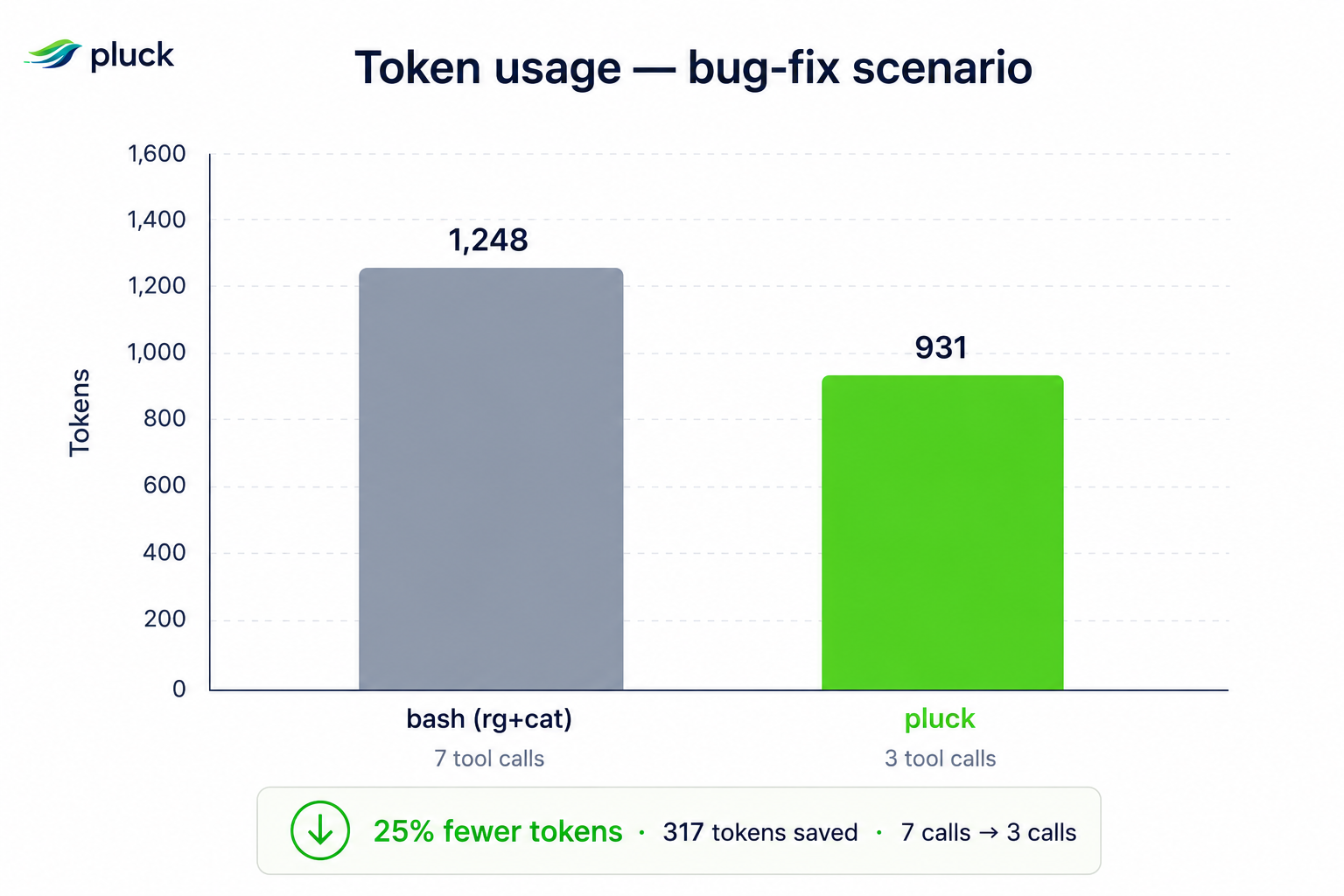
Measured single-scenario token reduction
fix-auth-token-expiry: same JIRA-style task, bash workflow (rg -l + several cats) vs pluck workflow (search + read + symbol). Both runners arrive at the same fix:
| Runner | Tokens spent | Source |
|---|---|---|
bash (rg + cat) |
1 248 | fix-auth-token-expiry-1778750775.json |
pluck (search + read + symbol) |
931 (−25 %) | same file |
Broader LLM-in-the-loop measurements across fix / refactor / explore / search / review scenarios are roadmapped as v0.8.0 work. We'll publish those numbers when they exist, not before.
Feature Comparison
| Capability | cat + grep / rg |
Other code-search tools | pluck |
|---|---|---|---|
| Hybrid BM25 + semantic ranking | ✗ | typically ✓ | ✓ |
| AST-level chunks | ✗ | typically ✓ | ✓ |
| Persistent daemon (MCP stdio) | — | ✗ (cold CLI per call) | ✓ |
| Persistent on-disk index (mmap) | — | usually ✗ | ✗ — roadmapped (v0.7.0) |
| Incremental reindex (file watcher) | — | usually ✗ | ✓ — 171 ms p50 |
| Session-scoped dedup | — | ✗ | ✓ — 23 % savings on bench |
--raw cat/grep byte parity |
— | ✗ | ✓ |
| Lossless default, lossy opt-in | — | varies | ✓ |
peek (signature + direct callees) |
✗ | ✗ | ✓ |
Single-file outline (pluck.read) |
✗ | ✗ | ✓ |
Multi-hop expand (call graph) |
✗ | ✗ | ✓ |
Reverse call graph (impact) |
✗ | ✗ | ✓ |
File-level import graph (deps) |
✗ | ✗ | ✓ |
Build / CI / test log compression (digest) |
✗ | ✗ | ✓ — 71 % median |
Exploration recommender (plan) |
✗ | ✗ | ✓ |
Roadmap
Versioning details live in docs/VERSIONING.md.
Maintainer release flow lives indocs/MAINTAINER_LOOP.md.
- v0.2.0 — shipped: First crates.io publish, MCP tools, session dedup,
smart outline, and expanded surface —digest,impact,deps,plan. - v0.3.0 — shipped: Natural-language recall — 100-query suite across
tokio / django / next.js, query expansion, two-stage cascade, continuous
hybrid weighting, NDCG@10 measurement, and symbol/path component ranking. - v0.4.0 — active train: Java + repo-format coverage — Java, HTML,
prompt-first agent install, TSX grammar fixes, CSS/SCSS, Markdown/MDX,
YAML/JSON/TOML, Dockerfile, and Shell landed; fixtures/gate hardening remain. - v0.5.0: Systems + JVM tier — C, C++, Kotlin, SQL, Terraform/HCL.
- v0.6.0: App-framework tier — Ruby, PHP, Swift, Vue, Svelte, Astro,
OpenAPI / GraphQL. - v0.7.0: Scale + persistence — mmap index, schema versioning,
incremental embedding re-encode, memory/disk caps. - v0.8.0: Adoption + observability — adoption counter, tool-description
A/B harness, LLM-in-loop bench, multilingual tool descriptions. - v0.9.0: Workflow intelligence + ecosystem — JSON output,
diff,history,profile, Aider / OpenHands / Cursor / Cline / Continue. - v1.0.0: Stable default retrieval layer — stable MCP/CLI contracts,
benchmark dashboard, release checklist, config migration, supply-chain review.
License
MIT - See LICENSE for details.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found