zenith
Health Uyari
- No license — Repository has no license file
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 179 GitHub stars
Code Gecti
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Zenith — a continuous-improvement harness for long-running agent tasks. Turns Claude Code, Codex, or Hermes into a multi-agent mission orchestrator via MCP/ACP. Includes the 'From RALPH to Zenith' technical report.
Zenith: A Continuous-Improvement Harness for Long-Running Tasks
Technical report from Intelligent Internet (2026) on how an agent harness should control work that may run for days or weeks, where the dominant failure mode is premature completion rather than inability to make progress.
Abstract
Long-running agents often fail not because they cannot make progress, but because they stop before the task is truly complete. We tested five harness designs across eight long-horizon tasks to isolate the control mechanisms that matter: repeated gap-finding, revisable planning, independent verification, adaptive orchestration, and stopping discipline.
RALPH is the strongest simple baseline because it forces each new session to reopen the gap between the current project state and the original requirement. But RALPH is expensive and has no principled stopping rule.
Our Zenith method keeps the useful parts of repeated review while making the loop adaptive: the orchestrator dynamically allocates workers, testers, reusable skills, replanning, and stopping decisions. In this study, Zenith achieved the best mean rank while using less than half of RALPH's per-task cost.
Installation
Copy and give this to your agent harness:
/goal Read the readme at https://github.com/Intelligent-Internet/zenith, detect if using claude code, codex or both, install requirements, install and run Zenith (ie uv run zenith etc like in the readme) and create a new skill called /zenith - when used (along with an additional prompt) it will call the skill: the minimum skill content should be: """First read .claude/orchestrator_prompt.md and treat it as your primary role, then use Zenith to run this mission.""" and afterwards you can add information about Zenith Harness, based on the readme and the technical report (inside the repo), and info on how to start zenith if its not already running. Change the skill to use .codex when using in codex. If both hernesses are available, make sure to add these skill to both of them correctly. Infact, there might be more harness options (hermes for example). See what is supported in §zenith/src/zenith_harness/providers.py, and for those that you detect are present, add their skills correctly. When Finished, confirm to me that Zenith is installed, running and ready, explain a bit about Zenith, and why and when to use it.
This will:
- install zenith with requirements
- start zenith using uv
- create claude code and codex skills to run & use zenith
Then, use /zenith like so - in claude code or codex, type:
/zenith <your instruction or query>
Or install it manually:
Zenith is a small MCP/ACP harness that runs a coding agent as a multi-agent orchestrator. See zenith/ for the full package.
Requirements
- Python 3.11+
uv- Node.js 22+ and
npm - Claude Code or Codex
Install
cd zenith
uv sync
uv run zenith --help
Install the ACP adapters globally for the agents you want Zenith to run:
# Claude workers/validators
npm install -g @agentclientprotocol/claude-agent-acp
command -v claude-agent-acp
# Codex workers/validators
npm install -g @agentclientprotocol/codex-acp
command -v codex-acp
Initialize a workspace
Initialize the project workspace Zenith should operate on. This is your target app/repo, not the Zenith source checkout:
# Claude Code, from this Zenith checkout
uv run zenith init --workspace-dir /path/to/your-app --agent claude
# Or Codex, from this Zenith checkout
uv run zenith init --workspace-dir /path/to/your-app --agent codex
Run a mission
Start your agent from the initialized project workspace:
cd /path/to/your-app
claude
# or
codex
Then ask the agent to read the generated orchestrator prompt:
First read .claude/orchestrator_prompt.md and treat it as your primary role, then use Zenith to run this mission.
<your instruction or query>
For Codex, use:
First read .codex/orchestrator_prompt.md and treat it as your primary role, then use Zenith to run this mission.
<your instruction or query>
Zenith
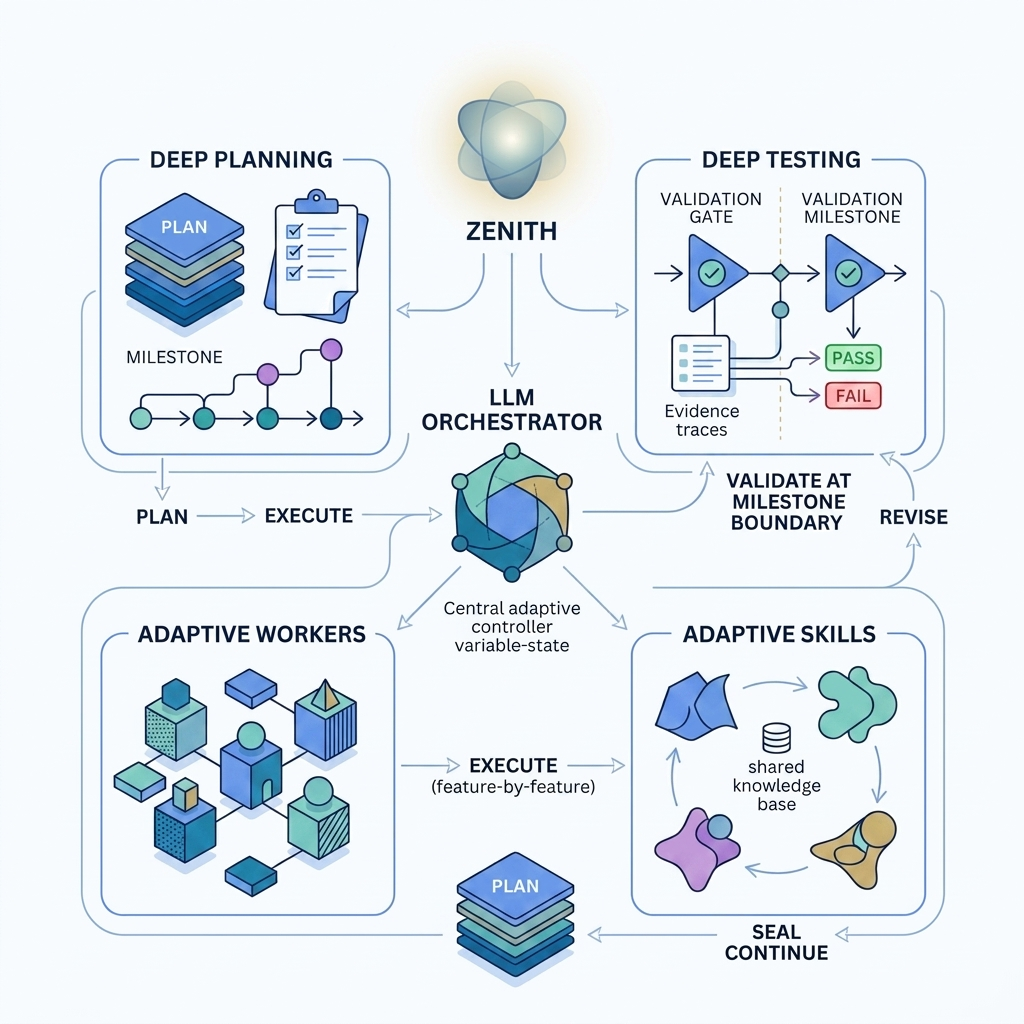
A single orchestrator session reads task state each turn and decides what to do next: spawn worker or tester subagents, register a reusable skill, replan, or stop. Workers and testers run in their own contexts and report back; the orchestrator integrates their results before the next decision.
Results
Frontier SWE Benchmark
On the Frontier SWE benchmark, Zenith — running on GPT-5.5 — ranks first overall, leading on implementation, performance, and dominance against frontier models paired with their native harnesses.
| # | Model | Harness | AVG RANK ¹ | Dominance ² | Implementation | Performance | Research |
|---|---|---|---|---|---|---|---|
| 1 | GPT-5.5 | Zenith | 2.06 | 92% | 1.60 | 1.89 | 3.33 |
| 2 | Claude Fable | Claude Code | 2.71 | 88% | 1.80 | 2.11 | 6.00 |
| 3 | Claude Opus 4.8 | Claude Code | 5.06 | 71% | 4.20 | 5.56 | 5.00 |
| 4 | GLM-5.2 | Claude Code | 5.31 | 69% | 5.60 | 6.50 | 1.67 |
| 5 | GPT-5.5 | Codex | 5.53 | 68% | 7.40 | 4.44 | 5.67 |
| 6 | Claude Opus 4.7 | Claude Code | 6.35 | 59% | 5.00 | 7.00 | 6.67 |
| 7 | Claude Opus 4.6 | Claude Code | 7.53 | 52% | 7.60 | 7.56 | 7.33 |
| 8 | GPT-5.4 | Codex | 8.06 | 50% | 7.20 | 9.67 | 4.67 |
| 9 | Composer 2.5 | Cursor CLI | 9.35 | 38% | 7.80 | 11.11 | 6.67 |
| 10 | Gemini 3.1 Pro | Gemini CLI | 9.65 | 37% | 11.80 | 7.44 | 12.67 |
| 11 | GLM-5.1 | Claude Code | 10.88 | 29% | 10.80 | 11.00 | 10.67 |
| 12 | DeepSeek V4 Pro | Claude Code | 11.00 | 27% | 10.80 | 11.11 | 11.00 |
| 13 | Kimi K2.5 | Kimi CLI | 11.65 | 24% | 13.00 | 10.22 | 13.67 |
| 14 | Kimi K2.6 | Kimi CLI | 11.82 | 25% | 10.40 | 12.78 | 11.33 |
| 15 | Qwen3.6-Plus | Qwen Code | 12.47 | 21% | 15.00 | 10.67 | 13.67 |
Ablation Study
To isolate the control mechanisms that matter, we compared Zenith against RALPH and three reduced harness variants across eight long-horizon tasks. Zenith achieves the best mean rank at less than half of RALPH's per-task cost.
| Method | Mean rank ↓ | Mean cost (USD/task) ↓ | Wins (of 8) ↑ |
|---|---|---|---|
| One-session | 5.00 | $22.21 | 0 |
| Plan-RALPH | 4.00 | $161.53 | 0 |
| Milestone-RALPH | 2.88 | $209.47 | 0 |
| RALPH | 1.75 | $407.58 | 3 |
| Zenith | 1.38 | $175.68 | 5 |
A "win" is a task on which the method ranked first; the eight wins partition the eight benchmark tasks.
Citation
@techreport{ii2026zenith,
title = {From RALPH to Zenith: Designing Harnesses for Long-Running Agents},
author = {{Intelligent Internet}},
institution = {Intelligent Internet},
year = {2026},
type = {Technical Report},
url = {https://github.com/Intelligent-Internet/zenith}
}
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi