CTX
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
Trigger-Driven Dynamic Context Loading for Code-Aware LLM Agents
CTX: Trigger-Driven Dynamic Context Loading for Code-Aware LLM Agents
![]()
![]()



CTX classifies developer queries into four trigger types and routes each to a specialized retrieval pipeline. For dependency-sensitive queries, CTX traverses the codebase import graph to resolve transitive relationships that keyword and embedding methods miss. It achieves 1.9x higher Token-Efficiency Score than BM25 while using only 5.2% of tokens, and outperforms BM25 on held-out external codebases (Flask, FastAPI, Requests — mean R@5 +0.163).
Key insight: code import graphs encode structural dependency information that text-based RAG cannot capture. CTX achieves Recall@5 = 1.0 on implicit dependency queries vs 0.4 for BM25.
Install for Claude Code (Hook mode)
CTX runs as Claude Code hooks that inject context before every prompt. Two install paths:
Option A — pip (always works, recommended)
pip install ctx-retriever
ctx-install # wires hooks into ~/.claude/settings.json
Restart Claude Code. Done.
Option B — Claude Code plugin
First, register the CTX marketplace (one-time, per machine):
python3 -c "
import json, pathlib
p = pathlib.Path('~/.claude/settings.json').expanduser()
s = json.loads(p.read_text()) if p.exists() else {}
s.setdefault('extraKnownMarketplaces', {})['jaytoone'] = {
'source': {'source': 'github', 'repo': 'jaytoone/CTX'}
}
p.write_text(json.dumps(s, indent=2))
print('[CTX] marketplace registered')
"
Then in Claude Code:
/plugin install ctx@jaytoone
The plugin Setup hook installs dependencies and wires everything automatically. Restart Claude Code.
The marketplace registration step will become unnecessary once CTX is accepted into
the official Claude Code plugin directory. Until then, Option A is simpler for new users.
Quick Start (library API)
from ctx_retriever.retrieval.adaptive_trigger import AdaptiveTriggerRetriever
# Point at any codebase directory
retriever = AdaptiveTriggerRetriever("/path/to/your/project")
# Retrieve relevant files for any natural-language query
result = retriever.retrieve(
query_id="my_query",
query_text="how does authentication work?",
k=5
)
for filepath in result.retrieved_files:
print(filepath, result.scores[filepath])
Claude Code Hook details
Optional: enable cross-encoder reranking (BGE)
By default, CTX uses BM25 + vec-daemon (multilingual-e5-small, ~120MB) for semantic search.
For higher-quality reranking, enable the BGE cross-encoder (BAAI/bge-reranker-v2-m3, ~2GB):
# Add to ~/.claude/settings.json env block:
CTX_BGE_ENABLE=1
When enabled, bge-daemon starts automatically on session open and reranks retrieved results.
Not recommended for machines with less than 4GB RAM or slow internet (model downloads on first run).
What ctx-install does (atomic, backup-first)
- Verifies the 4 CTX hook files exist at
~/.claude/hooks/(chat-memory, bm25-memory, memory-keyword-trigger, g2-fallback) - Reads
~/.claude/settings.json, takes a timestamped backup (settings.json.bak.<TS>) - Merges the CTX hook registrations into the existing
hooksdict without overwriting your other hooks (dedupes by command string — safe to re-run) - Atomically writes the new settings.json (temp-file-then-rename — never leaves partial state on disk)
- Smoke-tests by firing
bm25-memory.pyonce with a dummy prompt and confirminglast-injection.jsongets written
Other subcommands
ctx-install --dry-run # show what would change, touch nothing
ctx-install status # verify hook file presence + settings.json registration + last fire
ctx-install --uninstall # remove CTX hook registrations (hook files left in place)
Manual install (legacy — only needed if ctx-install fails)
# 1. Copy hook files to ~/.claude/hooks/
# 2. Register each in ~/.claude/settings.json under the appropriate event key
Example settings block (what ctx-install writes for you):
{
"hooks": {
"UserPromptSubmit": [
{ "hooks": [{ "type": "command", "command": "python3 $HOME/.claude/hooks/chat-memory.py" }] },
{ "hooks": [{ "type": "command", "command": "python3 $HOME/.claude/hooks/bm25-memory.py --rich" }] },
{ "hooks": [{ "type": "command", "command": "python3 $HOME/.claude/hooks/memory-keyword-trigger.py" }] }
],
"PostToolUse": [
{ "matcher": "Grep",
"hooks": [{ "type": "command", "command": "python3 $HOME/.claude/hooks/g2-fallback.py" }] }
]
}
}
What you get in each prompt:
[CTX] Trigger: EXPLICIT_SYMBOL | Query: AuthService | Confidence: 0.70 | Intent: judge from prompt
Code files (3/847 total):
• src/auth/service.py [score=1.000]
• src/auth/middleware.py [score=0.823]
• tests/test_auth.py [score=0.741]
(Use the prompt intent to decide how to treat this context.)
Validate on your own transcripts
Before installing, you can measure what CTX would give you on your own Claude Code transcripts — no install, no signup, no upload:
python3 benchmarks/ctx_validate.py --days 7
stdlib-only; reads ~/.claude/projects/*/<session>.jsonl locally and emits a Wilson-95-CI markdown report:
- Text match rate: 26.9% [23.2%, 31.1%] ±4.0pp (n=201)
- Tool-use match: 11.1% [8.6%, 14.2%] ±2.8pp
- Union (either): 32.8% [28.7%, 37.1%] ±4.2pp
Per response-type:
prose: 51.2% ±10.3pp (n=86)
tool_heavy: 26.2% ±8.2pp (n=107)
mixed: 25.0% ±26.0pp (n=8)
What this measures — distinctive terms from each user prompt, substring-matched against the assistant's response text AND tool_use parameters (file_path/command/pattern). On turns where CTX's hooks would surface related context, this rate approximates the ceiling of plausible utility. It is NOT a direct CTX measurement — install CTX and compare against live utility_measured telemetry for the actual delta. Use it to decide "is this signal worth pursuing?" before committing to install.
Live dashboard (after install):
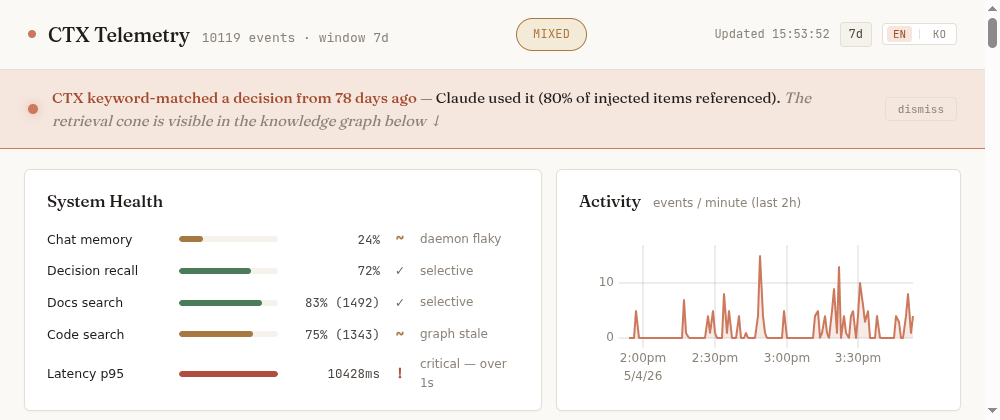
The dashboard visualizes utility in four stacked views — pooled rate with 95% CI, per-block breakdown (g1/g2_docs/g2_prefetch), by response type (prose/mixed/tool_heavy), and by item age (0-7d / 7-30d / 30d+). The knowledge graph below it lights up decisions in coral when Claude actually used them in the last 7 days; dead-weight decisions (no recent references) appear muted — pruning candidates.
Hook Performance
CTX adds no LLM calls — latency is purely algorithmic (BM25 + BFS indexing):
| Project | Language | Files | Hook Latency |
|---|---|---|---|
| Small project | Python | ~88 | ~40ms |
| Medium project | Python | ~215 | ~165ms |
| Large project | TypeScript | ~651 | ~270ms |
| Very large | any | >2000 | skipped (auto-excluded) |
The hook is skipped for prompts <15 chars, slash commands, [noctx] tags, and codebases with <3 files.
Control tags you can add to any prompt:
| Tag | Effect |
|---|---|
[noctx] |
Disable CTX for this prompt |
[fix] |
Fix/Replace mode — adds anti-anchoring reminder so Claude doesn't copy the existing (potentially wrong) implementation |
[fix] is also auto-triggered when the prompt starts with fix:, bug:, refactor:, or replace:.
Trigger Types
| Trigger | When Used | Mechanism |
|---|---|---|
EXPLICIT_SYMBOL |
Query names a class/function | Symbol index lookup |
SEMANTIC_CONCEPT |
Query describes a concept | BM25 keyword scoring |
IMPLICIT_CONTEXT |
Dependency queries ("what uses X") | BFS import graph traversal |
TEMPORAL_HISTORY |
Recent changes / history | Session file tracker |
Results
Synthetic Benchmark (50 files, 166 queries)
| Strategy | Recall@5 | Token Usage | TES |
|---|---|---|---|
| Full Context | 0.075 | 100.0% | 0.019 |
| BM25 | 0.982 | 18.7% | 0.410 |
| Dense TF-IDF | 0.973 | 21.0% | 0.406 |
| GraphRAG-lite | 0.523 | 24.0% | 0.218 |
| LlamaIndex | 0.972 | 20.1% | 0.405 |
| Chroma Dense | 0.829 | 19.3% | 0.346 |
| Hybrid Dense+CTX | 0.725 | 23.6% | 0.303 |
| CTX (Ours) | 0.874 | 5.2% | 0.776 |
TES = Recall@5 / ln(1 + files_loaded). Higher = better token efficiency.
External Codebase Benchmark (Flask, FastAPI, Requests)
CTX outperforms BM25 on all three held-out external codebases in code-to-code structural retrieval:
| Codebase | Files | CTX R@5 | BM25 R@5 | Δ |
|---|---|---|---|---|
| Flask | 79 | 0.545 | 0.347 | +0.198 |
| FastAPI | 928 | 0.328 | 0.174 | +0.154 |
| Requests | 35 | 0.626 | 0.489 | +0.137 |
| Mean | — | 0.500 | 0.337 | +0.163 |
Bootstrap 95% CI: external mean [0.441, 0.550]
COIR External Benchmark (CodeSearchNet Python)
| Strategy | Recall@1 | Recall@5 | MRR |
|---|---|---|---|
| Dense Embedding (MiniLM) | 0.960 | 1.000 | 0.978 |
| Hybrid Dense+CTX | 0.930 | 0.950 | 0.940 |
| BM25 | 0.920 | 0.980 | 0.946 |
| CTX Adaptive Trigger | 0.720 | 0.740 | 0.728 |
Downstream LLM Evaluation
CTX context injected into developer prompts improves LLM task quality across two models:
| Scenario | WITH CTX | WITHOUT CTX | Δ |
|---|---|---|---|
| G1 (session memory recall) | 1.000 | 0.110 | +0.890 |
| G2 (CTX-specific knowledge) | 0.688 | 0.000 | +0.688 |
G1: CTX persistent memory enables perfect cross-session recall (vs 11% without). G2: CTX context eliminates hallucination on CTX-specific API queries.
Key Findings
- CTX achieves 1.9x higher TES than BM25 with only 5.2% token usage
- CTX achieves perfect Recall@5 (1.0) on IMPLICIT_CONTEXT dependency queries
- CTX outperforms BM25 on all 3 external codebases in code-to-code retrieval (mean +0.163 R@5)
- CTX context improves downstream LLM task quality: G1 +0.890, G2 +0.688
- Trigger classifier achieves 100% accuracy (all 4 types F1=1.00) on synthetic benchmark
- CTX Adaptive Trigger achieves R@5=0.740 on COIR (improved from 0.380 via BM25 hybrid + CamelCase fix)
- Hybrid Dense+CTX achieves R@5=0.950 on COIR — best of both worlds
- No single strategy dominates all dimensions — workload determines optimal choice
When to Use CTX
CTX excels when:
- You need dependency-aware retrieval:
IMPLICIT_CONTEXTqueries (e.g., "what uses AuthService?") achieve perfect Recall@5 (1.0) via BFS import graph traversal - Working with a known codebase with established symbol/import structure — code-to-code retrieval outperforms BM25 on real projects (Flask: +0.198, FastAPI: +0.154, Requests: +0.137)
- Token budget is critical — CTX uses only 5.2% of tokens vs 18.7% for BM25 (TES: 1.9x higher)
- Queries name explicit symbols (class names, function names) — EXPLICIT_SYMBOL trigger routes directly to symbol index
CTX is not designed for:
- Text-to-code semantic search (COIR-style): finding code from natural-language descriptions. CTX R@5=0.740 vs BM25=0.980 on CodeSearchNet Python — still a gap; for best results use Dense Embedding or Hybrid Dense+CTX instead
- Large unseen codebases (>500 files, no prior indexing): heuristic symbol extraction degrades at scale; consider AST-based indexers
- Natural-language concept queries without code keywords: SEMANTIC_CONCEPT trigger falls back to BM25, losing CTX's structural advantage
Running Experiments
# Synthetic benchmark
python run_experiment.py --dataset-size small --strategy all
# Real codebase
python run_experiment.py --dataset-source real --project-path /path/to/project --strategy all
# COIR external benchmark
python run_coir_eval.py --n-queries 100
# Ablation study
python run_experiment.py --dataset-size small --mode ablation
Results are written to benchmarks/results/.
Project Structure
CTX/
src/
retrieval/ # Retrieval strategies (8 total)
adaptive_trigger.py # CTX core: trigger-driven retrieval
hybrid_dense_ctx.py # Hybrid: dense seed + graph expansion
bm25_retriever.py # BM25 sparse retrieval
dense_retriever.py # TF-IDF dense retrieval
chroma_retriever.py # ChromaDB + sentence-transformers
graph_rag.py # GraphRAG-lite baseline
llamaindex_retriever.py # LlamaIndex AST-aware chunking
full_context.py # Full context baseline
trigger/ # Trigger classifier (4 types)
evaluator/ # Benchmark runner, metrics, COIR
data/ # Dataset generation, real codebase loader
hooks/
ctx_real_loader.py # Claude Code UserPromptSubmit hook
ctx_session_tracker.py # PostToolUse session tracker
benchmarks/
results/ # Experiment results and reports
docs/
claude_code_integration.md # Claude Code setup guide
paper/ # Paper draft (markdown + LaTeX)
Telemetry (opt-in, local-only)
CTX can log retrieval quality metrics locally to help you understand how well the context injection is working.
Opt in:
export CTX_TELEMETRY=1 # enable for this shell
# or: touch ~/.claude/ctx-telemetry.enabled # persist across shells
View your data:
ctx-telemetry # summary + flywheel health verdict (causal r, upgrade hint)
ctx-telemetry last # last 10 session turns
ctx-telemetry calibrate # citation bias + causal r-analysis (v1.5)
ctx-telemetry tune # compute auto-tune params → ctx-auto-tune.json
ctx-telemetry cluster [-p DIR] # detect tech stack → project_type_hint in ctx-auto-tune.json
ctx-telemetry consent # Stage 2 upload consent status
ctx-telemetry upload # Stage 2 dry-run preview
ctx-telemetry clear # delete all local telemetry logs
Sample ctx-telemetry output:
CTX Retrieval Telemetry — 42 session-turn records (schema v1.6)
...
Flywheel health [n=42]: causal-r=+0.35 | upgrade=✓ HYBRID | kw=43%
Auto-tune (flywheel): After ctx-telemetry tune runs with ≥15 records, CTX automatically adjusts retrieval parameters based on your usage patterns (e.g., top_k reduction for query types with lower citation rates). The active tuning state is shown in CTX's context header: > **CTX auto-tune** [n=42, hybrid✓].
With ≥10 v1.5 records, tune also computes a causal signal: Pearson r between BM25 top retrieval score and citation rate. High r (>0.30) means quality-driven citations — HYBRID upgrade is worthwhile. Low r (<0.10) suggests position bias may be dominant — validate before upgrading. This is stored as hybrid_upgrade_hint in ctx-auto-tune.json.
Project cluster detection (Stage 3 prerequisite): ctx-telemetry cluster scans your project's source files, matches term frequencies against tech-stack signature profiles (python_ml, python_backend, nextjs_react, rust_systems, go_backend), and writes project_type_hint to ctx-auto-tune.json. This is a local-first proxy for the Stage 3 project_type_id cluster — enabling cold-start pre-warming without requiring cross-user data. Example output:
python_ml ██████████████████████████████ 80.0% (18 keywords matched)
python_backend ███████ 19.0% (13 keywords matched)
Project type: python_ml (confidence: HIGH)
What is collected (schema v1.6)
All data stays on your machine at ~/.claude/ctx-retrieval-events.jsonl. Nothing is uploaded.
| Field | Type | Description |
|---|---|---|
user_id |
string(16) | SHA256(machine-id + install-month)[:16] — anonymous, changes on reinstall |
session_id_hash |
string(16) | SHA256(session_id)[:16] — non-reversible |
ts_unix_hour |
int | Unix timestamp truncated to hour |
hook_source |
enum | G1 / G2_DOCS / G2_CODE / CM |
query_type |
enum | KEYWORD / SEMANTIC / TEMPORAL |
retrieval_method |
enum | HYBRID / BM25 / UNKNOWN |
candidates_returned |
int | Number of candidates before ranking |
total_injected |
int | Items injected into context |
total_cited |
int | Items referenced by the AI response |
utility_rate |
float | cited / injected — retrieval precision proxy |
session_turn_index |
int | Turn index within the current session |
vec_daemon_up |
bool | Whether semantic layer was active |
bge_daemon_up |
bool | Whether cross-encoder reranker was active |
duration_ms |
int | Per-block retrieval latency |
top_score_bm25 |
float|null | Max BM25 score — causal calibration signal (v1.5) |
top_score_dense |
float|null | Max cosine similarity score (v1.5) |
What is NOT collected
- ❌ No query text, response text, or code content
- ❌ No file names, commit messages, or project paths
- ❌ No email, device name, or personally identifiable information
- ❌ No network requests — Stage 1 is local-only
Privacy design
user_id= SHA256(machine-id + month-boundary) — not linkable to email or name; changes on reinstall- Timestamps truncated to hour (not minute)
- All content stripped — only counts, rates, method names, and latency
- Follows Sourcegraph's numeric-only telemetry pattern
Stage 2 (not yet implemented): opt-in upload of k-anonymized session_aggregate rows via ctx-telemetry consent. Rows with fewer than 5 users per (date × project_type) window are suppressed before any upload.
Paper
- Paper draft:
docs/paper/CTX_paper_draft.md - arXiv: TBD
- EMNLP 2026 submission: TBD
License
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found