recursive-improve
Health Pass
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 117 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
🪞 Make your agents recursively self-improve



make your agents recursively self-improve
90% of Claude's code is now written by Claude. Recursive self-improvement is already happening at Anthropic. What if you could do the same for your own agents?
Closing the Loop
You have an agent. It works, most of the time. But it could be better. Solving harder problems, handling more edge cases, wasting fewer tokens. What if it could improve itself, recursively, every time it runs?
Right now, it can't. Your agent is stateless. Every run starts from scratch. The only way to improve it is to manually improve it. There is no compounding of improvements.
recursive-improve closes this loop:

Your agent runs. Every LLM call is captured. Your coding agent analyzes the traces, identifying common failure patterns across runs, and applies targeted fixes. You run it again. It's better.
Get Started
1. Install
uv tool install "recursive-improve[all] @ git+https://github.com/kayba-ai/recursive-improve.git"
Then in your agent's project directory:
cd /path/to/your/agent
recursive-improve init
This creates the /recursive-improve skill files and the eval/traces/ directory.
2. Add tracing to your agent
Add the tracing dependency to your project:
uv add "recursive-improve @ git+https://github.com/kayba-ai/recursive-improve.git"
Two lines. Your agent code stays unchanged, we just observe.
import recursive_improve as ri
ri.patch() # auto-captures openai, anthropic, litellm calls
with ri.session("./eval/traces") as run:
result = my_agent("book a flight to Paris")
run.finish(output=result, success=True)
Already have traces? Drop them in
eval/traces/and skip to step 4.
3. Run your agent a few times to generate traces
4. Run the improvement loop
Open Claude Code or Codex in your project directory:
/recursive-improve
5. Re-run your agent
Clear old traces and run your agent again so the benchmark measures your improved code:
rm -f eval/traces/*.json
# run your agent the same way as step 3
6. Benchmark
Measure whether your changes actually solved the problems:
/benchmark
Results are stored in eval/benchmark_results.json and auto-compared against the previous run on the same dynamic metrics that were generated for your agent.
CLI alternative:
recursive-improve benchmark --label "v1-baseline"andrecursive-improve benchmark list
7. Dashboard
Start the interactive dashboard to visualize your improvement cycles:
recursive-improve dashboard # default: http://localhost:8420
recursive-improve dashboard -p 8080 # custom port
Each improvement cycle lives on its own branch. The dashboard shows before/after metrics for every cycle. See exactly what improved, merge the wins, discard the rest.
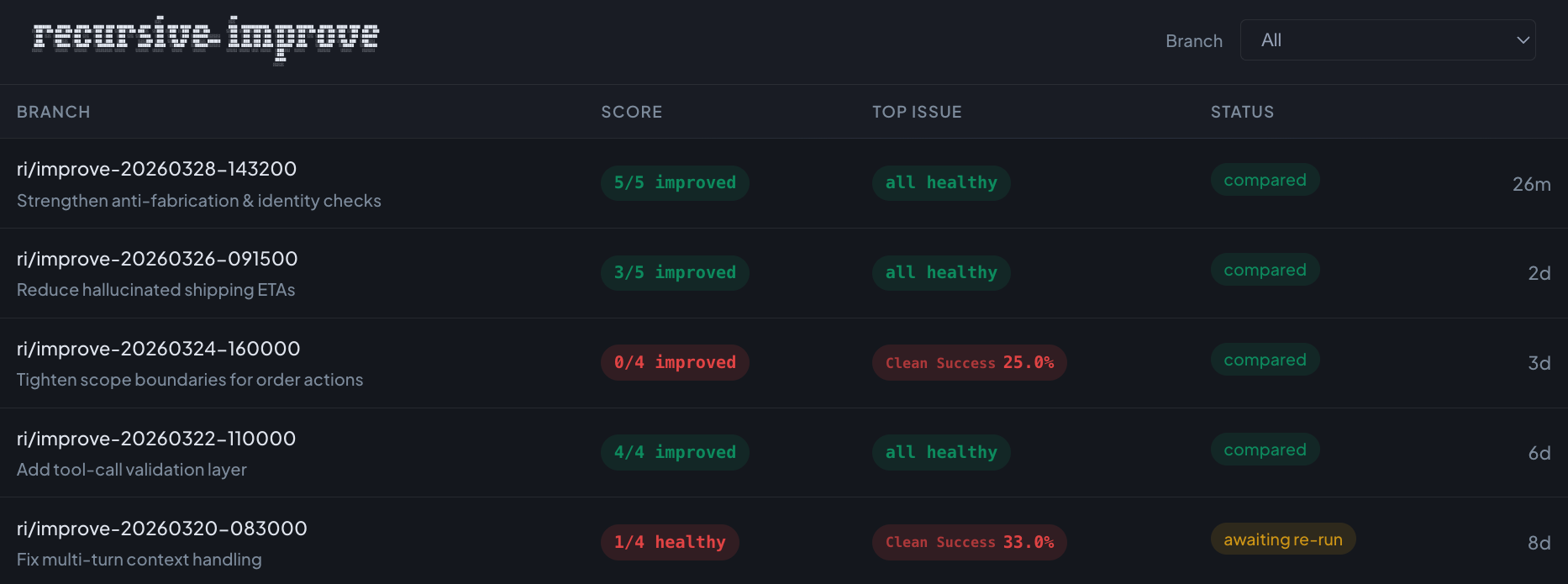
8. Run it overnight
/ratchet
An autoresearch-style autonomous loop. It asks you what to optimize, then repeats: improve → run agent → eval → keep or revert. Only improvements survive. Check eval/ratchet_summary.md when you wake up.
[!TIP]
Want deeper analysis? Kayba offers managed recursive agent improvement at
scale, tailored to your agent.
How It Works
When you run the /recursive-improve skill, it walks through a structured pipeline:
- Build context: detects your agent's architecture, tools, and system prompt
- Analyze traces: reads your traces, surfaces failure patterns, missed opportunities, recurring errors
- Measure: runs built-in detectors (loops, give-ups, errors, recovery) and generates custom domain-specific evaluations from your insights, then computes baselines
- Plan: triages each insight into discard / code fix / prompt fix, prioritized by impact
- Review: presents the plan for your approval before anything changes
- Fix: implements approved changes on a dedicated branch
Every fix traces back to a specific insight, linked to a specific metric.
Architecture
your agent ──> ri.patch() + ri.session() ──> eval/traces/*.json
│
▼
/recursive-improve
│
▼
improved agent code ──> repeat
│
▼
benchmark ──> recursive-improve dashboard
┌──────────────────────────────┐
│ /ratchet (autonomous loop) │
│ improve → run → eval → │
│ keep or revert → repeat │
└──────────────────────────────┘
ri.patch(): monkey-patches OpenAI, Anthropic, and LiteLLM clients to capture every callri.session(): context manager that writes structured trace JSON files/recursive-improve: Claude Code / Codex skill that analyzes traces and applies fixesrecursive-improve benchmark: snapshot metric quality, store, and compare over timerecursive-improve dashboard: web UI to visualize runs and compare branches/ratchet: autonomous keep-or-revert loop that runs/recursive-improverepeatedly overnight
Star this repo if you find it useful!
Built with ❤️ by Kayba and the open-source community.
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found