AutoViralAI
Health Gecti
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Community trust — 10 GitHub stars
Code Basarisiz
- Hardcoded secret — Potential hardcoded credential in .github/workflows/ci.yml
Permissions Gecti
- Permissions — No dangerous permissions requested
This autonomous AI agent researches viral content, generates social media posts, publishes them automatically, and adjusts its strategy based on engagement metrics. It connects to external platforms like Threads and uses LangGraph alongside Claude to operate.
Security Assessment
The tool inherently handles sensitive data, requiring API keys and social media credentials to function. It makes continuous external network requests to fetch trends, interact with the Claude AI model, and publish content directly via the Threads API. The most critical finding is a confirmed failure in the security scan: a hardcoded secret was detected inside the `.github/workflows/ci.yml` file. Exposing credentials in version control is a significant vulnerability that could easily lead to account compromise. Because of the extensive network capabilities and the hardcoded secret, the overall security risk is rated as High.
Quality Assessment
The project is highly active, with its last code push occurring today. It benefits from a clear MIT license and a well-structured, informative README. However, community trust is minimal, currently sitting at only 10 GitHub stars, meaning the codebase has not undergone widespread peer review or enterprise-level testing.
Verdict
Use with caution — the tool functions as advertised but contains hardcoded secrets and handles highly sensitive social media access tokens, requiring immediate manual security fixes before deployment.
Autonomous AI agent that researches viral content, generates posts, publishes them, measures engagement — and rewrites its own strategy based on what worked. Self-learning loop powered by LangGraph + Claude.

AutoViralAI
Your social media grows while you sleep.
An autonomous AI agent that researches what's going viral, generates content,
publishes it, measures engagement — and rewrites its own strategy based on what actually worked.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Real Results · Demo · Quick Start · How It Works · Configuration · Roadmap · Contributing
🔥 Real Results
We've been running AutoViralAI for ~1.5 months on a tech/programming Threads account. Here are some posts that went viral — every single one was researched, generated, and ranked by the agent:
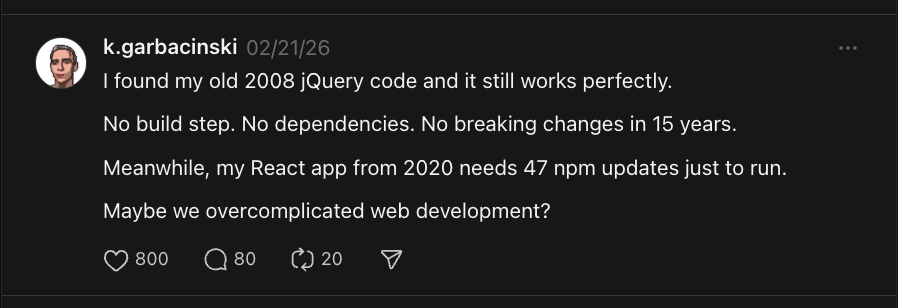
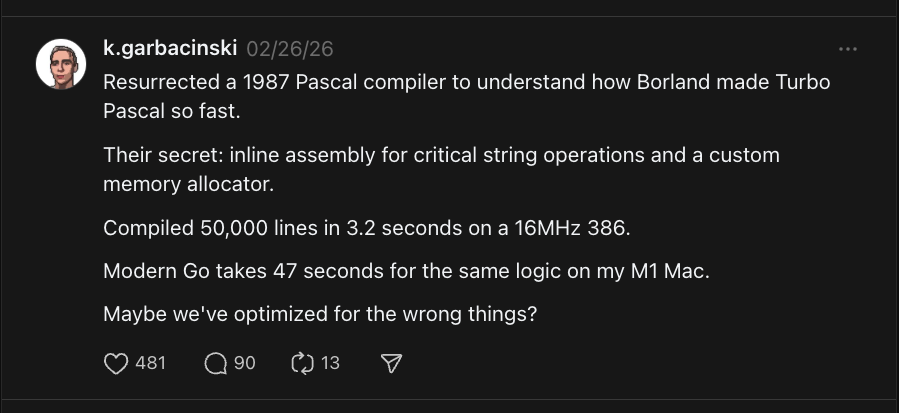
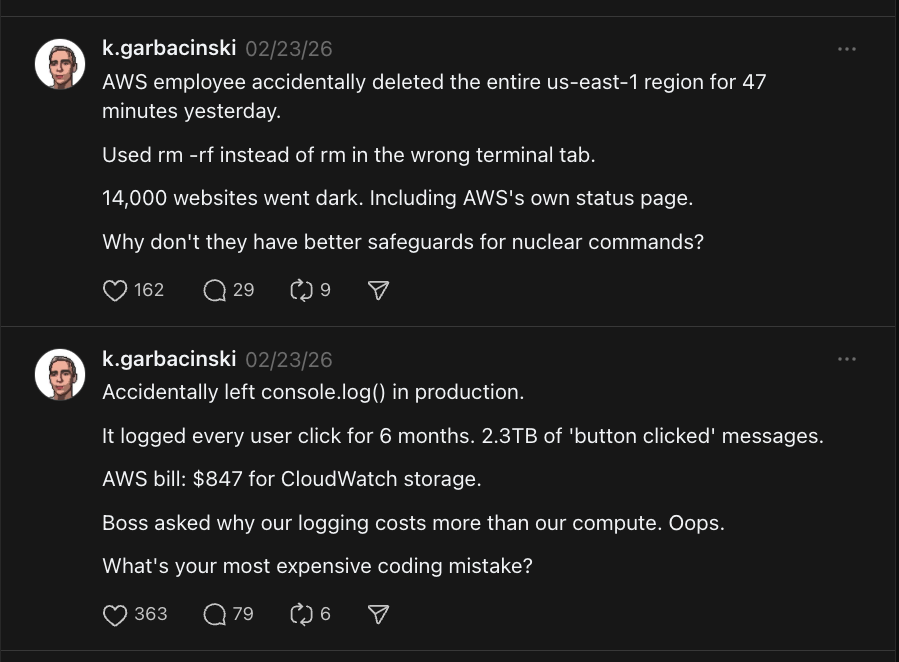
800+ likes on a single post. The agent learned that contrarian "old tech vs new tech" hooks and relatable developer war stories consistently outperform generic tips — and it adapted its strategy automatically.
🎬 Demo
See it in action — the agent researches trends, generates posts, ranks them, and sends you an approval request.
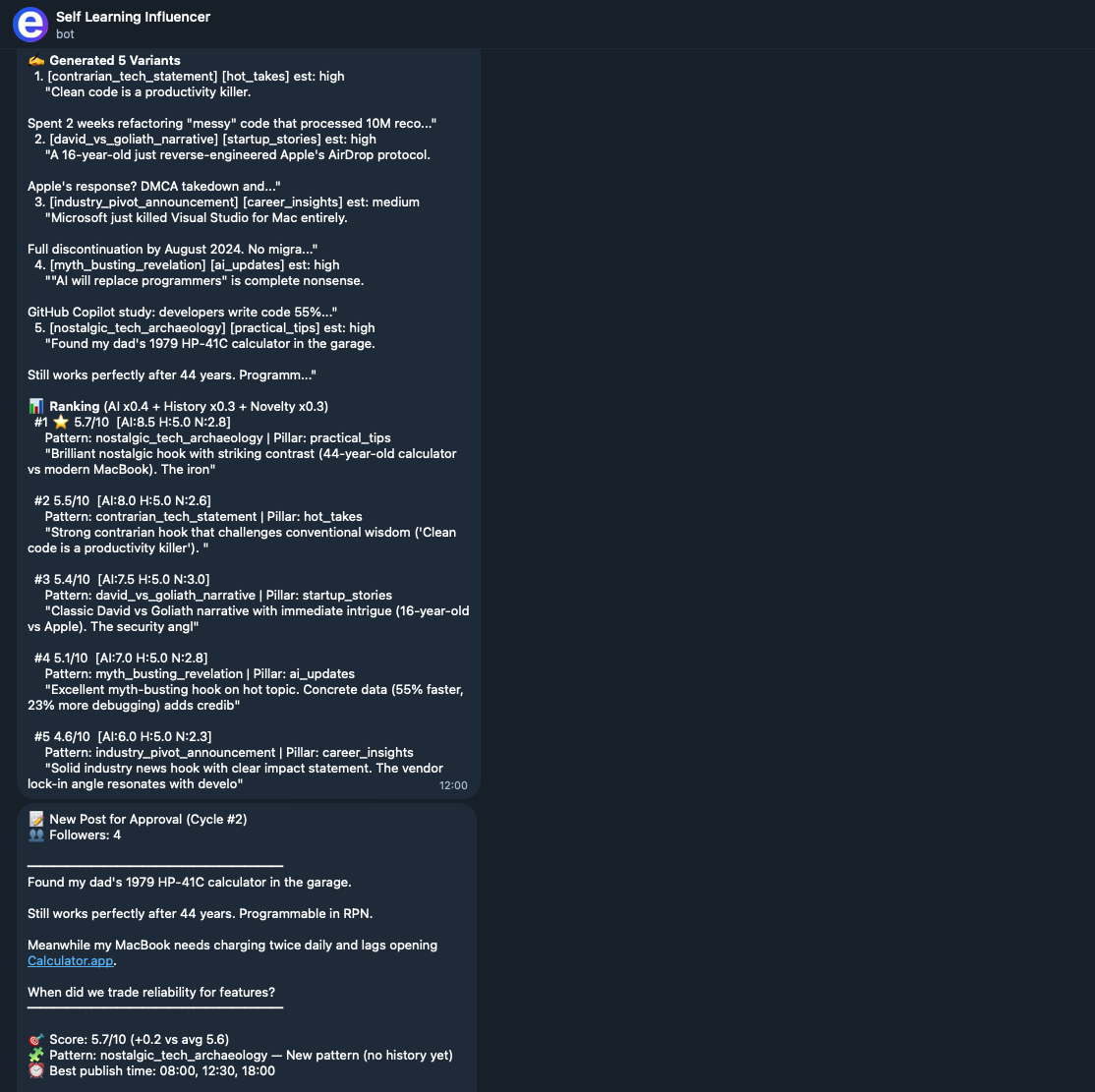
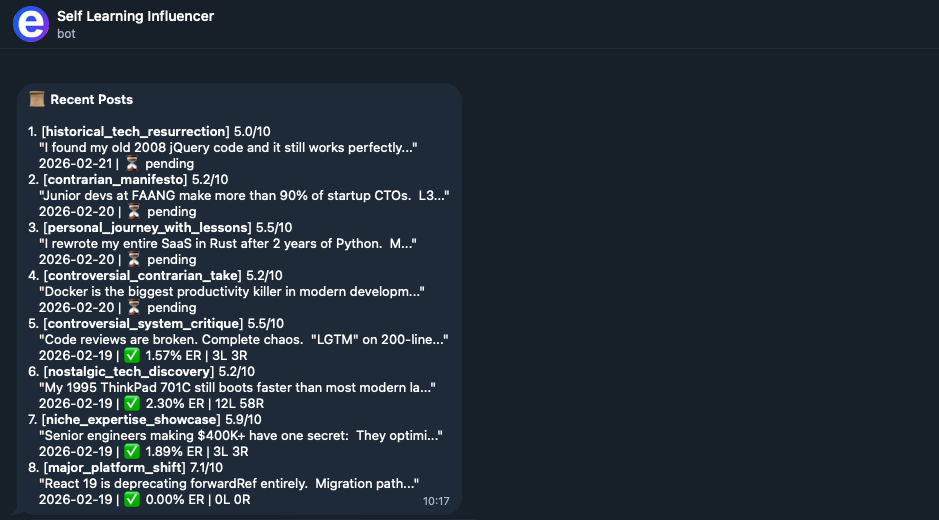
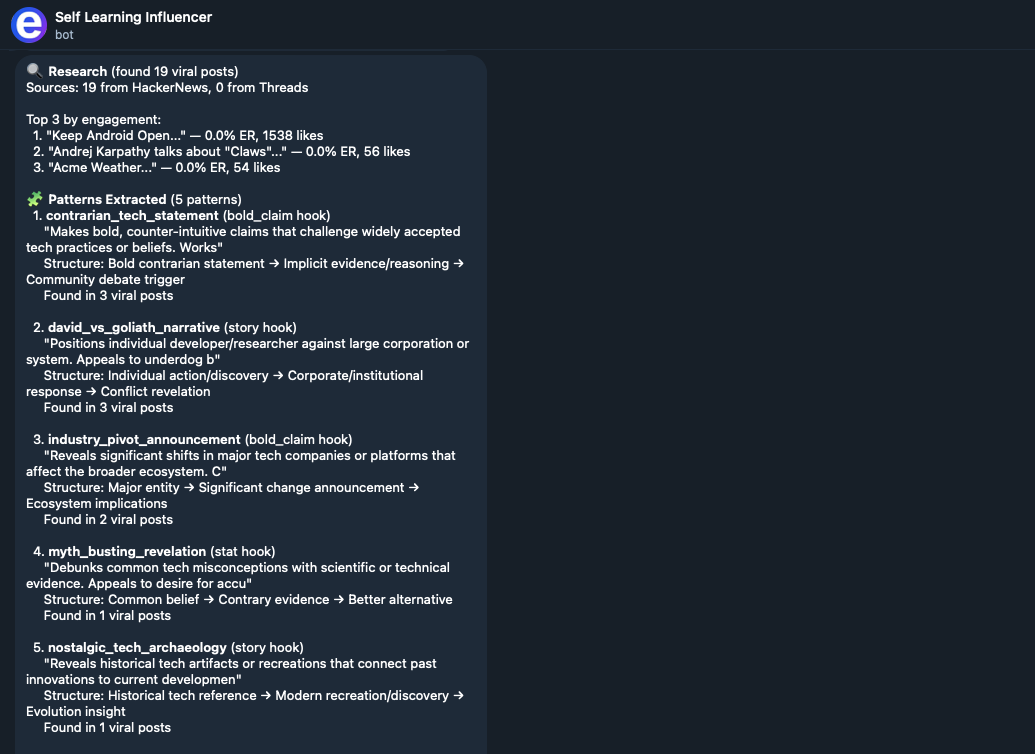
💡 The Problem
You know you should be posting consistently. You know what kind of content performs. But researching trends, writing posts, tracking what works, adjusting strategy — it's a full-time job.
💡 The Solution
AutoViralAI does the entire loop autonomously. It doesn't just post — it learns. Every day it gets a little better at understanding what your audience actually engages with.
Day 1: "Here's a generic coding tip" → 12 likes
Day 7: "Hot take: most devs don't need Docker" → 340 likes
Day 14: Agent learned contrarian hooks work 3x → adapts strategy automatically
Day 30: Posts consistently hit 500+ engagement → you didn't write a single one
Day 45: Single post hits 800 likes → the agent wrote it, not you
⚡ Why AutoViralAI?
Most "AI social media tools" are glorified schedulers with a GPT wrapper. They generate generic content, blast it out, and call it a day.
AutoViralAI is fundamentally different:
| Traditional tools | AutoViralAI | |
|---|---|---|
| 🔍 | Generate content from a static prompt | Research what's actually going viral right now, extract the patterns, and generate content using those patterns |
| 📈 | Same strategy forever | Strategy evolves daily based on real engagement data |
| 📊 | Post and forget | Measure results after 24h, learn what worked and why, feed it back |
| 🏆 | AI picks the post | Multi-signal ranking: AI score + historical pattern performance + novelty scoring |
| 🛡️ | Fully automated (risky) | Human-in-the-loop: you approve every post via Telegram before it goes live |
✨ Key Features
🧠 Self-Learning LoopThe agent doesn't just execute. It observes, measures, and adapts. Pattern that got 3x engagement? It'll use it more. Strategy that flopped? Automatically deprioritized. |
🏆 Multi-Signal RankingPosts aren't ranked on "AI vibes." Each variant scores on 3 independent signals: AI-evaluated viral potential, historical pattern performance, and novelty (so it doesn't repeat itself). |
🛡️ Human-in-the-LoopNothing gets published without your approval. The agent sends you the top-ranked post via Telegram. You approve, edit, or reject. Built on LangGraph's |
🎯 Niche-AwareDefine your voice, audience, content pillars, and topics to avoid in a single YAML file. The agent stays on-brand in every cycle. |
🔍 Research-DrivenBefore generating anything, the agent scrapes Threads and HackerNews to understand what's trending right now in your niche. No hallucinated trends. |
🚀 Production-ReadyPostgreSQL persistence, Docker deployment, CI/CD via GitHub Actions, Telegram webhooks, APScheduler for cron-like execution. Not a toy — this runs 24/7. |
🚀 Quick Start
Prerequisites
- Python 3.13+
- uv (recommended) or pip
- An Anthropic API key
Setup
git clone https://github.com/kgarbacinski/AutoViralAI.git
cd AutoViralAI
uv sync
cp .env.example .env
# Edit .env → set ANTHROPIC_API_KEY (minimum required)
Run Your First Cycle
# Interactive mode — you approve/reject posts in the terminal
uv run python scripts/manual_run.py
# Auto-approve mode (for testing the full pipeline)
uv run python scripts/manual_run.py --auto-approve
# Run the learning pipeline
uv run python scripts/manual_run.py --pipeline learning
Note: The first run uses mock APIs — no social media account needed. You'll see the full pipeline execute with realistic simulated data.
🔄 How It Works
The system runs two independent pipelines that share a knowledge base:
graph TB
subgraph creation ["Content Creation Pipeline · runs 3x/day"]
direction TB
A["Goal Check"]
B["Research Viral Content<br/>(HackerNews + Threads)"]
C["Extract Patterns<br/>(hooks, structures, triggers)"]
D["Generate Post Variants"]
E["Multi-Signal Ranking<br/>(AI + History + Novelty)"]
F{"Human Approval<br/>via Telegram"}
G["Publish to Threads"]
H["Schedule Metrics Check"]
Z(["Target Reached"])
A -->|not reached| B
A -->|target reached| Z
B --> C --> D --> E --> F
F -->|"Approve / Edit"| G --> H
F -->|Reject + Feedback| D
end
subgraph learning ["Learning Pipeline · runs daily"]
direction TB
I["Collect Engagement Metrics"] --> J["Analyze Performance"]
J --> K["Update Pattern Scores"] --> L["Adjust Strategy"]
end
subgraph store ["Shared Knowledge Base"]
direction LR
KB[("Patterns · Strategy<br/>Metrics · Posts")]
end
H -. "post data" .-> KB
KB -. "metrics" .-> I
L -. "improved strategy" .-> KB
KB -. "patterns + strategy" .-> B
style creation fill:transparent,stroke:#4A90D9,stroke-width:2px,color:#fff
style learning fill:transparent,stroke:#9B59B6,stroke-width:2px,color:#fff
style store fill:transparent,stroke:#50C878,stroke-width:2px,color:#fff
style A fill:#4A90D9,stroke:#2C6FA0,color:#fff
style B fill:#4A90D9,stroke:#2C6FA0,color:#fff
style C fill:#5BA0E0,stroke:#2C6FA0,color:#fff
style D fill:#5BA0E0,stroke:#2C6FA0,color:#fff
style E fill:#5BA0E0,stroke:#2C6FA0,color:#fff
style F fill:#E8A838,stroke:#C4872A,color:#fff
style G fill:#50C878,stroke:#3A9A5C,color:#fff
style H fill:#50C878,stroke:#3A9A5C,color:#fff
style Z fill:#2ECC71,stroke:#27AE60,color:#fff
style I fill:#9B59B6,stroke:#7D3C98,color:#fff
style J fill:#9B59B6,stroke:#7D3C98,color:#fff
style K fill:#AF7AC5,stroke:#7D3C98,color:#fff
style L fill:#AF7AC5,stroke:#7D3C98,color:#fff
style KB fill:#50C878,stroke:#3A9A5C,color:#fff
Why two pipelines? Posts need 24-48 hours to accumulate meaningful engagement data. The creation pipeline runs multiple times per day, while the learning pipeline runs once daily on yesterday's data — then feeds the improved strategy back into creation.
🔁 The Self-Learning Loop
graph LR
R["Research<br/>What's viral?"] --> E["Extract<br/>Why it works"]
E --> G["Generate<br/>Using patterns"]
G --> K["Rank<br/>AI + History + Novelty"]
K --> P["Publish<br/>Post the winner"]
P --> M["Measure<br/>Wait 24h, collect data"]
M --> L["Learn<br/>What worked & why"]
L --> A["Adapt<br/>Update strategy"]
A -->|"feed back"| R
style R fill:#4A90D9,stroke:#2C6FA0,color:#fff
style E fill:#5BA0E0,stroke:#2C6FA0,color:#fff
style G fill:#5BA0E0,stroke:#2C6FA0,color:#fff
style K fill:#E8A838,stroke:#C4872A,color:#fff
style P fill:#50C878,stroke:#3A9A5C,color:#fff
style M fill:#9B59B6,stroke:#7D3C98,color:#fff
style L fill:#AF7AC5,stroke:#7D3C98,color:#fff
style A fill:#AF7AC5,stroke:#7D3C98,color:#fff
📊 Multi-Signal Ranking
Each variant gets a composite score from three independent signals:
graph LR
subgraph signals [" "]
direction TB
AI["AI Score<br/>(0–10)<br/>weight: 0.4"]
PH["Pattern History<br/>(0–10)<br/>weight: 0.3"]
NV["Novelty<br/>(0–10)<br/>weight: 0.3"]
end
AI --> C(["Composite Score"])
PH --> C
NV --> C
C --> W{"Select<br/>Winner"}
style AI fill:#4A90D9,stroke:#2C6FA0,color:#fff
style PH fill:#E8A838,stroke:#C4872A,color:#fff
style NV fill:#9B59B6,stroke:#7D3C98,color:#fff
style C fill:#50C878,stroke:#3A9A5C,color:#fff
style W fill:#2ECC71,stroke:#27AE60,color:#fff
style signals fill:transparent,stroke:transparent
| Signal | What it measures | How |
|---|---|---|
| AI Score (0-10) | Viral potential: hook strength, emotional trigger, shareability | Claude evaluates each variant |
| Pattern History (0-10) | How well this pattern performed in the past | Cumulative engagement data from knowledge base |
| Novelty (0-10) | How different this is from recent posts | Cosine distance of embeddings vs last 20 posts |
New patterns get a 5.0 exploration bonus — the system balances exploitation (use what works) with exploration (try new things).
🤝 Human-in-the-Loop
The agent never posts without your approval. Before the approval message, you get a full pipeline report showing what each agent did — research results, extracted patterns, generated variants, and ranking breakdown.
Built on LangGraph's interrupt() — the graph pauses, saves state, and resumes when you respond. Survives server restarts.
🎯 Configuring Your Niche
Edit config/account_niche.yaml to define your identity:
niche: "tech"
sub_niche: "programming & startups"
voice:
tone: "conversational, insightful, slightly provocative"
persona: "experienced developer who shares hard-won lessons"
style_notes:
- "Use short, punchy sentences"
- "Lead with a controversial or surprising take"
- "End with a question or call-to-action"
content_pillars:
- name: "hot_takes"
description: "Contrarian opinions on tech trends"
weight: 0.30
- name: "practical_tips"
description: "Actionable coding tips and tool recommendations"
weight: 0.25
# ... add your own pillars
avoid_topics:
- "political opinions unrelated to tech"
- "cryptocurrency shilling"
The agent uses this config in every generation cycle to stay on-brand and on-topic.
🏗️ Architecture
AutoViralAI/
├── config/
│ ├── account_niche.yaml # Your niche, voice, audience, content pillars
│ └── settings.py # Environment config (pydantic-settings)
│
├── src/
│ ├── models/ # Pydantic models + TypedDict states
│ ├── graphs/ # LangGraph pipeline definitions
│ │ ├── creation_pipeline.py # Research → generate → approve → publish
│ │ └── learning_pipeline.py # Metrics → analyze → learn → adapt
│ ├── nodes/ # Individual pipeline steps (11 nodes)
│ ├── tools/ # External service wrappers (mock-first)
│ ├── prompts/ # All LLM prompt templates
│ ├── store/ # Knowledge base (LangGraph Store)
│ ├── orchestrator.py # APScheduler (cron-like scheduling)
│ └── persistence.py # Checkpointer + Store factory
│
├── bot/ # Telegram bot (approval, commands, config)
├── api/ # FastAPI server
├── scripts/ # Manual run, init, health check
└── tests/ # pytest suite
📦 Knowledge Base
Both pipelines share a persistent knowledge base via LangGraph Store:
graph LR
subgraph store ["LangGraph Store"]
direction TB
subgraph config_ns ["Configuration"]
C1["config/<br/>Niche & voice"]
C2["strategy/<br/>Content strategy"]
end
subgraph perf_ns ["Performance"]
P1["pattern_performance/<br/>What patterns work"]
P2["metrics_history/<br/>Engagement data"]
end
subgraph content_ns ["Content"]
T1["published_posts/<br/>Post history"]
T2["pending_metrics/<br/>Awaiting check"]
end
end
CP["Creation<br/>Pipeline"] --> store
store --> LP["Learning<br/>Pipeline"]
LP --> store
style store fill:transparent,stroke:#50C878,stroke-width:2px
style config_ns fill:#EBF5FB,stroke:#4A90D9,color:#333
style perf_ns fill:#F5EEF8,stroke:#9B59B6,color:#333
style content_ns fill:#EAFAF1,stroke:#50C878,color:#333
style C1 fill:#fff,stroke:#4A90D9,color:#333
style C2 fill:#fff,stroke:#4A90D9,color:#333
style P1 fill:#fff,stroke:#9B59B6,color:#333
style P2 fill:#fff,stroke:#9B59B6,color:#333
style T1 fill:#fff,stroke:#50C878,color:#333
style T2 fill:#fff,stroke:#50C878,color:#333
style CP fill:#4A90D9,stroke:#2C6FA0,color:#fff
style LP fill:#9B59B6,stroke:#7D3C98,color:#fff
Dev: InMemoryStore · Prod: AsyncPostgresStore with embedding support.
🛠️ Tech Stack
| Component | Technology | Purpose |
|---|---|---|
| Agent Framework | LangGraph 0.3+ | Two-graph architecture with shared state |
| LLM | Claude Sonnet 4 via langchain-anthropic | Pattern extraction, generation, ranking, analysis |
| State Persistence | LangGraph Checkpointer | Survives interrupts, restarts, crashes |
| Knowledge Base | LangGraph Store | Cross-pipeline memory with namespaces |
| Human-in-the-Loop | LangGraph interrupt() + python-telegram-bot |
Pause graph, notify via Telegram, resume on response |
| Research | Apify + HN Firebase API | Threads + HackerNews viral content discovery |
| Novelty Scoring | Cosine similarity on embeddings | Prevent repetitive content |
| Scheduling | APScheduler | Creation 3x/day, learning 1x/day |
| API | FastAPI | Webhook receiver + status endpoints |
| Database | PostgreSQL (prod) / In-memory (dev) | Checkpoints, store, metrics |
| Validation | Pydantic v2 | Structured LLM output + data models |
🧪 Tests
# Run all tests
uv run pytest
# With coverage
uv run pytest --cov=src --cov=bot --cov=api --cov-report=term-missing
# Lint
uv run ruff check .
🐳 Production Deployment
Push to main → GitHub Actions runs lint, test, and deploys automatically via SSH + Docker.
# Local development with Docker
docker compose up -d
🗺️ Roadmap
- ✅ Two-graph architecture (creation + learning)
- ✅ Mock-first development (works without API keys except Anthropic)
- ✅ Multi-signal ranking (AI + history + novelty)
- ✅ Human-in-the-loop via
interrupt() - ✅ Configurable niche/voice/audience
- ✅ CI/CD: GitHub Actions → auto-deploy on push to main
- ✅ Telegram bot approval flow (end-to-end)
- ✅ Pipeline transparency — full AI agent report (research, patterns, generation, ranking)
- ✅ Enriched approval messages — metrics benchmark, pattern rationale, optimal publish time
- ✅ Reject with feedback — reason buttons feed back into the learning loop
- ✅ Publish later — schedule approved posts for optimal times
- ✅ Bot commands —
/metrics,/history,/schedule,/force,/learn,/research,/pause,/resume - ✅ Remote config via Telegram —
/configto change tone, language, hashtags, posting schedule - ✅ Live
/status— running/paused state, cycles, pending approvals, next run - ✅ Standalone
/research— see what virals the agent finds without running the full pipeline - ✅ Real Threads API integration
- 🔲 LangSmith observability dashboard
- 🔲 A/B testing (publish two variants, compare)
- 🔲 Multi-platform support (X, Bluesky, LinkedIn)
- 🔲 Web dashboard for strategy visualization
- 🔲 Configurable LLM provider (OpenAI, Ollama)
- 🔲 Plugin system for research sources
🤝 Contributing
Contributions are welcome! Please read the Contributing Guide for details on the development workflow, code style, and how to submit pull requests.
Some good first issues:
- Add more content pattern templates
- Implement real Reddit research with better filtering
- Add retry logic with exponential backoff for API calls
- Build a web dashboard showing learning progress
- Add support for image/carousel posts
- Add support for new platforms (X, LinkedIn, Bluesky)
📄 License
⭐ Star History
If you find this project useful, consider giving it a star!
Created by @kgarbacinski · Co-Founder at Efektywniejsi - we build custom AI solutions for businesses and people!
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi