memBook
mcp
Warn
Health Warn
- License — License: MIT
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 6 GitHub stars
Code Pass
- Code scan — Scanned 12 files during light audit, no dangerous patterns found
Permissions Pass
- Permissions — No dangerous permissions requested
No AI report is available for this listing yet.
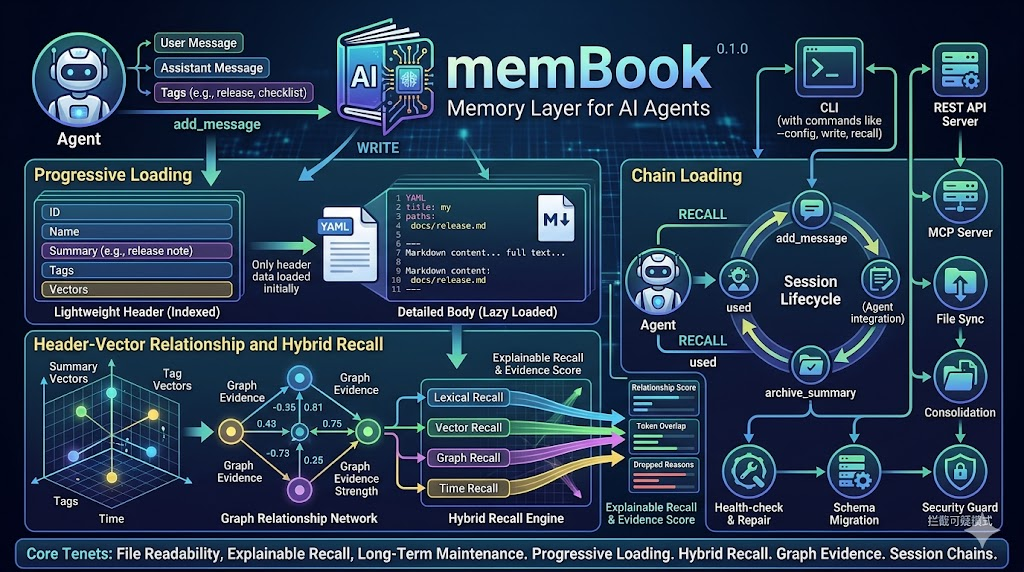
Progressive memory layer for AI agents with Header+Content indexing, chain recall, and file-first governance.
README.md
# memBook
![]()



中文 | English
给 AI Agent 用的渐进式长期记忆层。
不是把整段对话直接塞进向量库,而是:
- 先写成
Header + Content两层记忆。 - 先召回轻量记忆头,再按 token 预算渐进式加载正文。
- 必要时沿关系图做链式扩展,把 second-hop 证据一起带回来。
一句话说,memBook 的核心不是“存记忆”,而是“以可控成本把对的记忆逐步捞出来”。
历史 Benchmark 自申明
memBook 是从 agent_mem_L 清理出来的公开版。当前仓库不再内置 benchmark harness;下面这组数字来自旧仓库最后一个 pinned official4 快照,用来说明同一套记忆内核在 4 个官方 benchmark 上的历史表现。
| Benchmark | Score |
|---|---|
| LoCoMo | 0.7226 |
| LongMemEval | 0.7333 |
| HaluMem | 0.6667 |
| MemoryAgentBench | 0.6695 |
| macro4 | 0.6980 |
其中 official4 表示 LoCoMo + LongMemEval + HaluMem + MemoryAgentBench 的官方数据集联合跑分,固定协议为 strict_official_only=true、每个 benchmark 40 个 official samples、3 个 seeds(232010 / 467676 / 763545)。
- answer model + LongMemEval judge:
qwen3.5-plus - thinking: disabled
- embedding rerank: local
Qwen/Qwen3-Embedding-0.6B - cross-encoder rerank: disabled
- LoCoMo official JSON:
snap-research/locomo - LongMemEval cleaned JSON used by the legacy runner:
xiaowu0162/longmemeval-cleaned - HaluMem Medium JSONL used by the legacy runner:
IAAR-Shanghai/HaluMem - MemoryAgentBench official dataset used by the legacy runner:
ai-hyz/MemoryAgentBench - pinned baseline snapshot in the old repo:
docs/benchmark-baseline.md - legacy benchmark runner:
evaluation/run_comparison.py - legacy nightly workflow:
.github/workflows/nightly-official-benchmarks.yml
python -m evaluation.run_comparison \
--frameworks codex \
--benchmarks locomo,longmemeval,halumem,memoryagentbench \
--strict-official-only \
--use-llm --llm-model qwen3.5-plus --no-llm-enable-thinking \
--llm-fallback-mode balanced \
--longmemeval-official-judge --longmemeval-judge-model qwen3.5-plus --no-longmemeval-judge-enable-thinking \
--codex-use-embedding-rerank --codex-embedding-provider local \
--codex-embedding-local-model Qwen/Qwen3-Embedding-0.6B \
--no-codex-use-cross-encoder-rerank \
--max-samples-by-benchmark locomo=40,longmemeval=40,halumem=40,memoryagentbench=40
方法精髓
1. Header First,不是一上来就加载全文
Header保存 summary、tags、时间、关系、置信度和 metadata。Content保存完整正文,默认落盘到 Markdown。- 召回先看头部,只有分数够高、预算允许、关系需要时才扩正文。
2. Progressive Loading,不让长记忆直接炸掉上下文
- 第一阶段先做低成本候选筛选。
- 第二阶段再根据 token 预算逐步扩展内容层。
- 如果
l0不够,再向l1 / l2升级上下文层。
3. Chain Recall,不只找“像”的,还找“相关的”
- 支持 lexical / vector / graph / time 混合召回。
- 支持 relation-hop 扩展,把与命中记忆直接相关的链路节点带回来。
- 适合长时序、多关系、多会话的 agent 记忆问题。
4. File Truth Layer,记忆不是黑盒
- YAML 索引 + Markdown 正文。
- 支持
health-check、sync-files、rebuild-vector-index。 - 方便人看、人改、人审计,不会只剩数据库黑箱。
这套设计解决什么问题
| 问题 | 常见做法 | memBook 做法 |
|---|---|---|
| 长记忆直接塞进 prompt,成本失控 | 全文检索后硬拼上下文 | 先记忆头,后渐进式加载正文 |
| 只靠向量相似度,跨关系链容易漏 | 只返回“最像”的片段 | 在候选命中后做关系链扩展 |
| 记忆系统难排查 | 黑盒向量库 + 不可解释分数 | 返回分数拆解、丢弃原因、关系证据 |
| 文件和运行时状态容易漂移 | 手工改文件后系统不知道 | 提供文件同步、健康检查、重建工具 |
召回流程
flowchart LR
A[对话 / 工具输出] --> B[写入为 Header + Content]
B --> C[YAML Index]
B --> D[Markdown Content]
B --> E[Vector Index]
B --> F[Relation Graph]
Q[用户查询] --> G[候选召回]
C --> G
E --> G
F --> G
G --> H[lexical + vector + graph + time 融合打分]
H --> I[先返回高价值 Header]
I --> J[按 token 预算渐进式加载 Content]
J --> K[必要时沿关系链 second-hop 扩展]
K --> L[最终上下文 + explainability]
核心能力
Header + Content双层记忆模型。- 渐进式上下文加载和 token 预算控制。
- lexical / vector / graph / time 混合召回。
- 关系链式加载与可解释召回输出。
- 文件后端、文件同步、健康检查、向量重建。
- 写入安全护栏:可疑模式拦截、长度限制、置信度阈值。
- 会话生命周期:
add_message -> used -> commit -> archive_summary。 - 统一入口:Python API、
membookCLI、REST API、MCP server。
快速开始
python -m venv .venv
source .venv/bin/activate
pip install -e ".[dev]"
pytest -q
默认配置是文件模式 + token 向量索引,不依赖外部 embedding 服务。
CLI 示例
membook --config configs/default.yaml write \
--id mem_cli_1 \
--name "release note" \
--summary "release checklist" \
--body "run tests before release" \
--tag release
membook --config configs/default.yaml recall \
--query "release checklist" \
--tag release \
--explain
membook --config configs/default.yaml health-check --repair
Python API 示例
from membook import GenericAgentAdapter, create_engine_from_dict
engine = create_engine_from_dict(
{
"storage": {"mode": "in_memory"},
"vector": {"enabled": False},
"graph": {"enabled": False},
"security": {"enable_guard": False},
}
)
adapter = GenericAgentAdapter(engine=engine, source="demo")
adapter.after_llm_call(
user_message="我们下周发版,需要准备什么?",
assistant_message="先跑回归测试并确认回滚方案。",
tags=["release"],
)
records = adapter.before_llm_call("发布前需要确认什么?", tags=["release"])
print([item.header.summary for item in records])
示例脚本
python examples/quickstart_generic.py
python examples/quickstart_file_backend.py
python examples/quickstart_langgraph_adapter.py
python examples/quickstart_consolidation.py
python examples/quickstart_metrics.py
python examples/quickstart_graph_recall.py
python examples/quickstart_security_guard.py
python examples/quickstart_schema_migration.py
python examples/quickstart_api_server.py
python examples/quickstart_mcp_server.py
文档
docs/architecture.md:整体架构docs/cli.md:CLI 用法docs/api.md:REST APIdocs/mcp.md:MCP serverdocs/integration.md:运行时集成方式docs/runtime-embedding.md:运行时 embedding 配置docs/file-sync.md:文件同步docs/observability.md:指标和 explainabilitydocs/schema-versioning.md:索引 schema 迁移docs/security-regression.md:写入安全说明
项目结构
memBook/
├─ configs/
├─ docs/
├─ examples/
├─ memory/
├─ src/
├─ tests/
├─ CHANGELOG.md
└─ LICENSE
Star History
许可证
MIT
Reviews (0)
Sign in to leave a review.
Leave a reviewNo results found