metrillm
Health Uyari
- License — License: Apache-2.0
- Description — Repository has a description
- Active repo — Last push 0 days ago
- Low visibility — Only 5 GitHub stars
Code Uyari
- process.env — Environment variable access in mcp/src/setup.ts
Permissions Gecti
- Permissions — No dangerous permissions requested
Bu listing icin henuz AI raporu yok.
Benchmark local LLM models: speed, quality, and hardware fitness scoring. CLI, MCP server, and IDE plugins.
MetriLLM
![]()



Benchmark your local LLM models in one command. Speed, quality, hardware fitness — with a shareable score and public leaderboard.
Think Geekbench, but for local LLMs on your actual hardware.
npm install -g metrillm@latest
metrillm bench
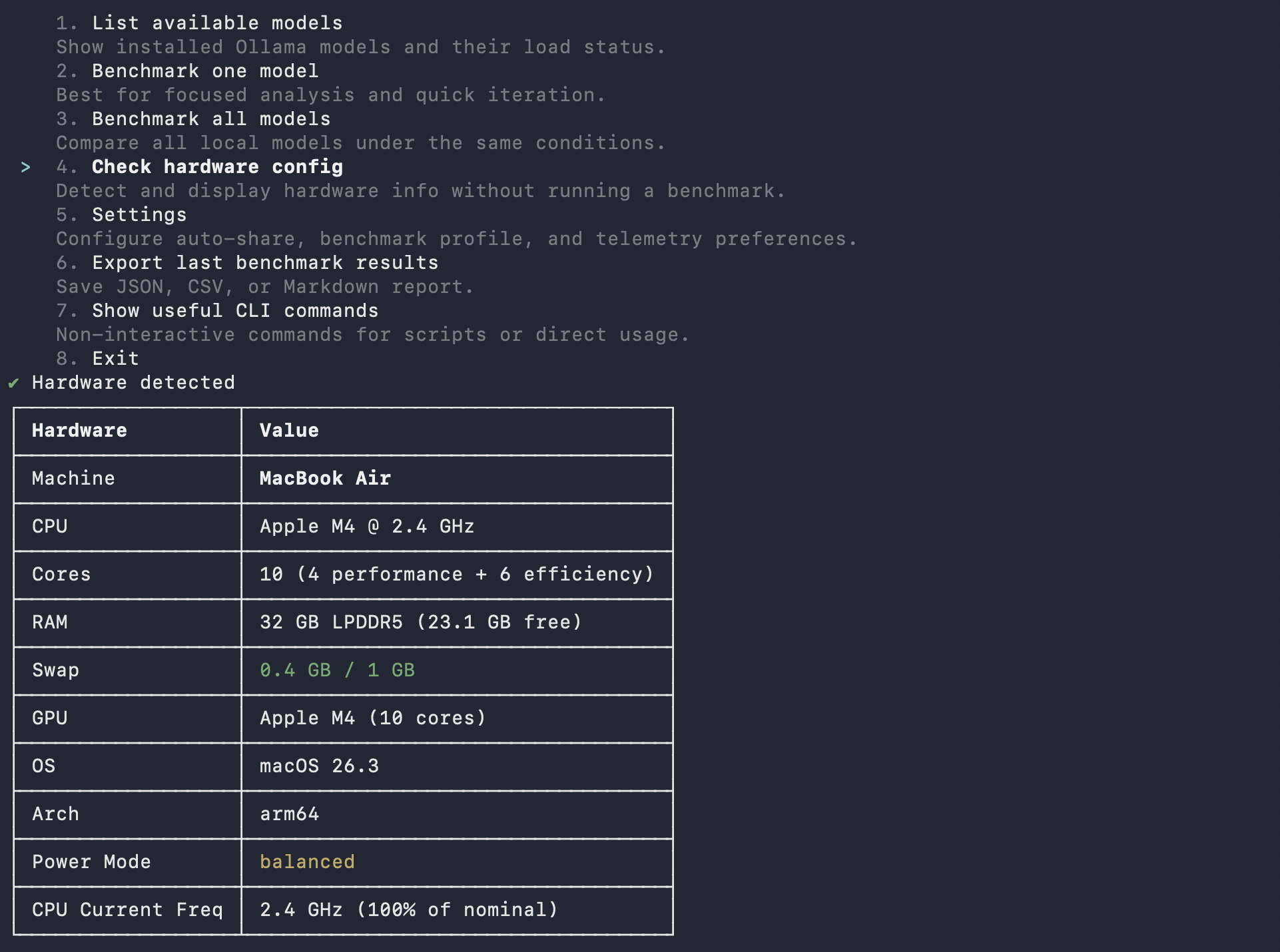
What You Get
- Performance metrics: tokens/sec, time to first token, memory usage, load time
- Quality evaluation: reasoning, coding, math, instruction following, structured output, multilingual (14 prompts, 6 categories)
- Global score (0-100): 30% hardware fit + 70% quality
- Verdict: EXCELLENT / GOOD / MARGINAL / NOT RECOMMENDED
- One-click share:
--shareuploads your result and gives you a public URL + leaderboard rank
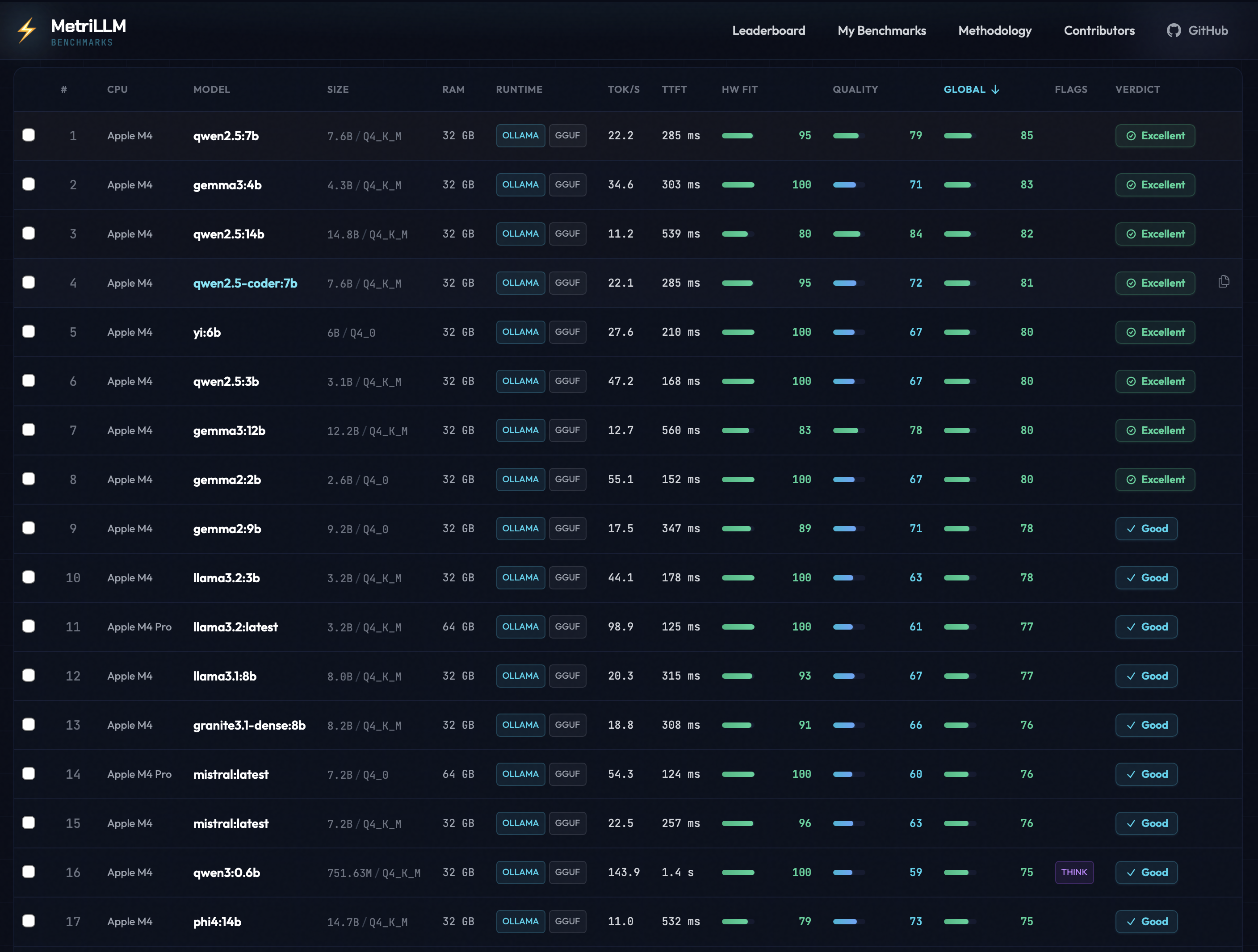
Real Benchmark Results
From the public leaderboard — all results below were submitted with
metrillm bench --share.
| Model | Machine | CPU | RAM | tok/s | TTFT | Global | Verdict |
|---|---|---|---|---|---|---|---|
| llama3.2:latest | Mac Mini | Apple M4 Pro | 64 GB | 98.9 | 125 ms | 77 | GOOD |
| mistral:latest | Mac Mini | Apple M4 Pro | 64 GB | 54.3 | 124 ms | 76 | GOOD |
| gemma3:4b | MacBook Air | Apple M4 | 32 GB | 35.9 | 303 ms | 72 | GOOD |
| gemma3:1b | MacBook Air | Apple M4 | 32 GB | 39.4 | 362 ms | 72 | GOOD |
| qwen3:1.7b | MacBook Air | Apple M4 | 32 GB | 37.9 | 3.1 s | 70 | GOOD |
| llama3.2:3b | MacBook Air | Apple M4 | 32 GB | 27.8 | 285 ms | 69 | GOOD |
| gemma3:12b | MacBook Air | Apple M4 | 32 GB | 12.3 | 656 ms | 67 | GOOD |
| phi4:14b | MacBook Air | Apple M4 | 32 GB | 11.1 | 515 ms | 65 | GOOD |
| mistral:7b | MacBook Air | Apple M4 | 32 GB | 13.6 | 517 ms | 61 | GOOD |
| deepseek-r1:14b | MacBook Air | Apple M4 | 32 GB | 10.8 | 30.0 s | 25 | NOT RECOMMENDED |
Key takeaway: Small models (1-4B) fly on Apple Silicon. Larger models (14B+) with thinking chains can choke even on capable hardware. See full leaderboard →
Install
# Install globally
npm install -g metrillm@latest
metrillm bench
# Alternative package managers
pnpm add -g metrillm@latest
bun add -g metrillm@latest
# Homebrew
brew install MetriLLM/metrillm/metrillm
# Or run without installing
npx metrillm@latest bench
Usage
# Interactive mode — pick models from a menu
metrillm bench
# Benchmark a specific model
metrillm bench --model gemma3:4b
# Benchmark with LM Studio backend
metrillm bench --backend lm-studio --model qwen3-8b
# Benchmark all installed models
metrillm bench --all
# Share your result (upload + public URL + leaderboard rank)
metrillm bench --share
# CI/non-interactive mode
metrillm bench --ci-no-menu --share
# Force unload after each model (useful for memory isolation)
metrillm bench --all --unload-after-bench
# Export results locally
metrillm bench --export json
metrillm bench --export csv
Upload Configuration (CLI + MCP)
By default, production builds upload shared results to the official MetriLLM leaderboard (https://metrillm.dev).
- No CI secret injection is required for standard releases.
- Local/dev runs use the same default behavior.
- Self-hosted or staging deployments can override endpoints with:
METRILLM_SUPABASE_URLMETRILLM_SUPABASE_ANON_KEYMETRILLM_PUBLIC_RESULT_BASE_URL
If these variables are set to placeholder values (from templates), MetriLLM falls back to official defaults.
Windows Users
PowerShell's default execution policy blocks npm global scripts. If you see PSSecurityException or UnauthorizedAccess when running metrillm, run this once:
Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy RemoteSigned
Alternatively, use npx metrillm@latest which bypasses the issue entirely.
Runtime Backends
| Backend | Flag | Default URL | Required env |
|---|---|---|---|
| Ollama | --backend ollama |
http://127.0.0.1:11434 |
OLLAMA_HOST (optional) |
| LM Studio | --backend lm-studio |
http://127.0.0.1:1234 |
LM_STUDIO_BASE_URL (optional), LM_STUDIO_API_KEY (optional) |
Shared runtime env:
METRILLM_STREAM_STALL_TIMEOUT_MS(optional): stream watchdog for all backends, default30000,0disables it
LM Studio benchmark runs now use the native REST inference endpoint (/api/v1/chat) for both streaming and non-streaming generation.
The previous OpenAI-compatible inference path (/v1/chat/completions) has been retired from MetriLLM so tok/s and TTFT can rely on native LM Studio stats when available.
If a LM Studio response omits native token stats, MetriLLM still computes a score and shows the throughput as estimated.
For very large models, tune timeout flags:
--perf-warmup-timeout-ms(default300000)--perf-prompt-timeout-ms(default120000)--quality-timeout-ms(default120000)--coding-timeout-ms(default240000)--stream-stall-timeout-ms(default30000,0disables stall timeout for any backend)
Benchmark Profile v1 (applied to all benchmark prompts):
temperature=0top_p=1seed=42thinkingfollows your benchmark mode (--thinking/--no-thinking)- Context window stays runtime default (
context=runtime-default) and is recorded as such in metadata.
LM Studio non-thinking guard:
- When benchmark mode requests non-thinking (
--no-thinkingor default), MetriLLM now aborts if the model still emits reasoning traces (for result comparability). - To disable it in LM Studio for affected models, put this at the top of the model chat template:
{%- set enable_thinking = false %}then eject/reload the model.
How Scoring Works
Hardware Fit Score (0-100) — how well the model runs on your machine:
- Speed: 50% (tokens/sec relative to your hardware tier)
- TTFT: 20% (time to first token)
- Memory: 30% (RAM efficiency)
Quality Score (0-100) — how well the model answers:
- Reasoning: 20pts | Coding: 20pts | Instruction Following: 20pts
- Structured Output: 15pts | Math: 15pts | Multilingual: 10pts
Global Score = 30% Hardware Fit + 70% Quality
Hardware is auto-detected and scoring adapts to your tier (Entry/Balanced/High-End). A model hitting 10 tok/s on a 8GB machine scores differently than on a 64GB rig.
Share Your Results
Every benchmark you share enriches the public leaderboard. No account needed — pick the method that fits your workflow:
| Method | Command / Action | Best for |
|---|---|---|
| CLI | metrillm bench --share |
Terminal users |
| MCP | Call share_result tool |
AI coding assistants |
| Plugin | /benchmark skill with share option |
Claude Code / Cursor |
All methods produce the same result:
- A public URL for your benchmark
- Your rank: "Top X% globally, Top Y% on [your CPU]"
- A share card for social media
- A challenge link to send to friends
Compare your results on the leaderboard →
MCP Server
Use MetriLLM from Claude Code, Cursor, Windsurf, or any MCP client — no CLI needed.
# Claude Code
claude mcp add metrillm -- npx metrillm-mcp@latest
# Claude Desktop / Cursor / Windsurf — add to MCP config:
# { "command": "npx", "args": ["metrillm-mcp@latest"] }
| Tool | Description |
|---|---|
list_models |
List locally available LLM models |
run_benchmark |
Run full benchmark (performance + quality) on a model |
get_results |
Retrieve previous benchmark results |
share_result |
Upload a result to the public leaderboard |
Skills
Slash commands that work inside AI coding assistants — no server needed, just a Markdown file.
| Skill | Trigger | Description |
|---|---|---|
/benchmark |
User-invoked | Run a full benchmark interactively |
metrillm-guide |
Auto-invoked | Contextual guidance on model selection and results |
Skills are included in the plugins below, or can be installed standalone:
# Claude Code
cp -r plugins/claude-code/skills/* ~/.claude/skills/
# Cursor
cp -r plugins/cursor/skills/* ~/.cursor/skills/
Plugins
Pre-built bundles (MCP + skills + agents) for deeper IDE integration.
| Component | Description |
|---|---|
| MCP config | Auto-connects to metrillm-mcp server |
| Skills | /benchmark + metrillm-guide |
| Agent | benchmark-advisor — analyzes your hardware and recommends models |
Install:
# Claude Code
cp -r plugins/claude-code/.claude/* ~/.claude/
# Cursor
cp -r plugins/cursor/.cursor/* ~/.cursor/
See Claude Code plugin and Cursor plugin for details.
Integrations
| Integration | Package | Status | Docs |
|---|---|---|---|
| CLI | metrillm |
Stable | Usage |
| MCP Server | metrillm-mcp |
Stable | MCP docs |
| Skills | — | Stable | Skills |
| Claude Code plugin | — | Stable | Plugin docs |
| Cursor plugin | — | Stable | Plugin docs |
Development
npm ci
npm run ci:verify # typecheck + tests + build
npm run dev # run from source
npm run test:watch # vitest watch mode
Homebrew Formula Maintenance
The tap formula lives in Formula/metrillm.rb.
# Refresh Formula/metrillm.rb with latest npm tarball + sha256
./scripts/update-homebrew-formula.sh
# Or pin a specific version
./scripts/update-homebrew-formula.sh 0.2.1
After updating the formula, commit and push so users can install/update with:
brew tap MetriLLM/metrillm
brew install metrillm
brew upgrade metrillm
Contributing
Contributions are welcome! Please read the Contributing Guide before submitting a pull request. All commits must include a DCO sign-off.
License
Apache License 2.0 — see NOTICE for trademark information.
Yorumlar (0)
Yorum birakmak icin giris yap.
Yorum birakSonuc bulunamadi